Interspeech 2020에 나온 논문 (http://www.interspeech2020.org/uploadfile/pdf/Thu-3-10-9.pdf)이다.
논문에 나와있지 않은데 이해가 어려운 내용은 아래 "블로그 포스팅"을 참고했다.
- https://rimiyeyo.tistory.com/entry/SR-paper-Conformer-Convolution-augmented-Transformer-for-Speech-Recognition-%ED%8C%8C%ED%97%A4%EC%B9%98%EA%B8%B0
- https://velog.io/@jeo0534/Conformer-Convolution-augmented-Transformer-for-Speech-Recognition
- https://arabae.github.io/2021-08-03-Conformer
Abstract
기존 연구 배경
- 최근 Transformer & CNN 기반 모델들이 RNN을 능가하며 ASR에서 엄청난 성과 보임
- Transformer는 content-based global interaction을 잘 포착하며, CNN은 local feature를 효율적으로 이용하는 특징을 가짐
본 논문은??
- CNN이랑 Transformer를 합쳐서, 오디오 sequence에서 parameter-efficient way로 가기 위해, local & global dependencies를 모두 반영하자!
- 이를 위해 speech recognition 분야에서, convolution-augmented transformer를 제시함: "Conformer"
실험 결과
- Conformer는 이전 모델을 능가하며 SOTA 달성
- LibriSpeech benchmark에서 평가
WER 2.1% / 4.3% (language model X) - test/testother
WER 1.9% / 3.9% (language model O)
WER 2.7% / 6.3% (small model, only 10M parameter)
1. Introduction
기존 연구 동향
- neural network에 기반한 End-to-end ASR은 최근 엄청난 성능을 보이고 있음
- [과거 동향] RNNs를 많이 썼음 -> audio sequence에서 temporal dependencies를 모델링할 수 있어서
- [최근 동향]
- self-attention에 기반한 Tansformer가 사용 -> (1) 장거리 interaction을 capture하고, (2) 높은 훈련 효율성에서 이점이 있기 때문
- CNN 또한, local receptive layer를 통해서 local context를 레이어별로 잘 포착하여 ASR에서 성공적인 경향을 보임
=> 하지만 self-attention 또는 convolution 기반의 모델은 한계점이 있음
한계점
- Transformers:
- 장거리 global context에 효과적
- 세분화된 local feature pattern을 추출하는 것은 상대적으로 못함
- CNN:
- local 정보를 이용하고 vision에서 사실상 계산 블록(computationbal block)으로 쓰임
- local window에 대해서 shared position-based kernel을 학습하여 => 이를 통해 edges/shape 같은 feauture를 포착하는 것이 가능해짐
- 그러나 local connectivity를 사용하는 것은 global information을 포착하기 위해서 더 많은 레이어/파라미터가 필요하다는 제한이 존재
이러한 사실에 기반해 ContextNet는 "squeeze-and-excitation module"을 각 residual block에 써서 더 긴 context를 포착하고자 했음
=> 하지만 전체 시퀀스에 대해 global averaging만 적용하여, dynamic한 global context를 포착하기에 여전히 한계가 있음
- CNN 모델의 global context를 강화하기 위해 [12]에서 소개된 sequeeze-and-excitation (SE) layer에서 영감을 얻어, ContextNet 제안
- sequeeze-and-excitation (SE) layer: local feature vector sequence를 single global context로 압축하고, 이 context를 다시 각 local feature vector로 broadcast 후 곱셈을 통해 둘을 병합
- average 등을 통해 하나의 global feature를 생성하고, 다시 차원을 local feature로 broadcast한 뒤 둘을 곱함으로써 하나의 결과를 얻음
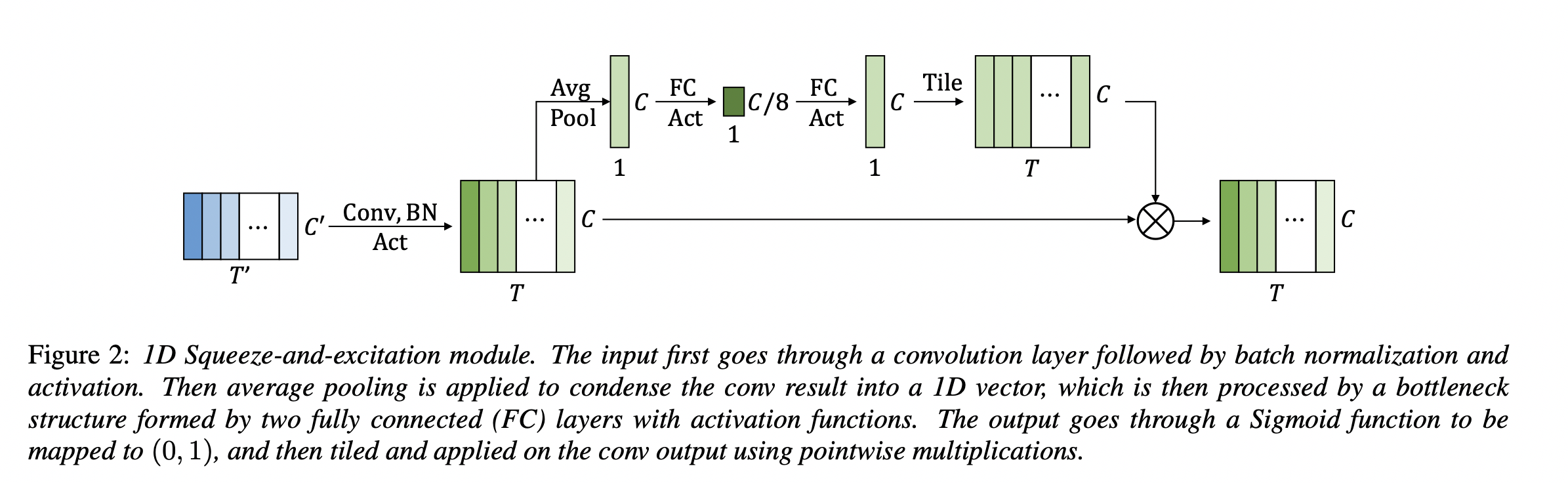
최근 연구 동향
-
최근에는 CNN과 self-attention을 결합하면 개별적으로 사용하는 것보다 좋음이 밝혀짐
- 함께 쓰이면 position-wise local feature를 둘 다 학습하는 것이 가능하고 content-based global interactions를 사용하는 것이 가능해지기 때문
-
이 흐름을 따라 몇 논문들은 self-attention을 relative position 기반 정보로 강화함
-
Wu et al.은 input을 두 brach(self-attention과 convolution)로 나눈 후, output을 연결하는 "multi-branch architecture"를 제안
- mobile applications에 초점을 두어서 machine translation task에서 개선을 보여줌
본 연구
- ASR에서 CNN과 self-attention을 유기적으로 결합하는 방법을 연구
- global과 local 상호작용이 매개변수 효율화를 위해 중요하다고 가정하고, 이를 위해, self-attention과 convolution의 새로운 조합을 제시함
- = self-attention은 global 상호작용을 학습하는 반면, convolution은 relative-offset-based local correlation를 효율적으로 포착
- Wu et al.에 영감 받아, 한 쌍의 feed forward modules 사이에 끼어있는 self-attention과 convolution을 결합하는 방법 제시 (Fig 1)
실험 결과
-
Conformer는 LibriSpeech에서 SOTA 보임
-
본 논문은 10M, 30M, 118M 모델 매개 변수 한계 제약 조건을 기반으로 -> 세 가지 모델 제시
(결론적으로 모두 이전 연구보다 우수했음) -
또한 attention-head의 수, convolution kernel의 size, activation function, feed-forward layer의 배치, convolution module을 Transformer 기반 네트워크에 추가하는 다양한 전략을 연구하고 영향력 조사
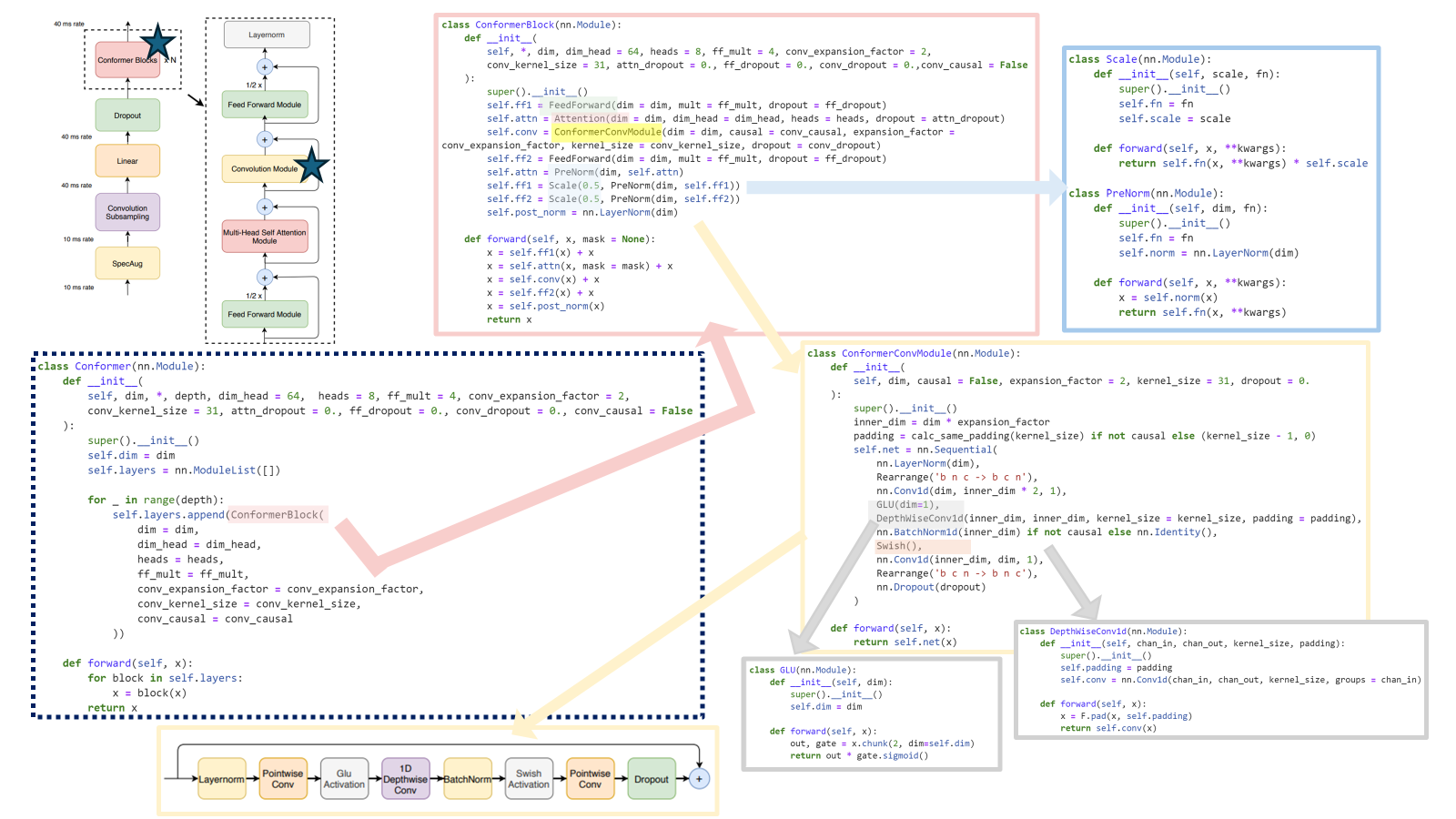
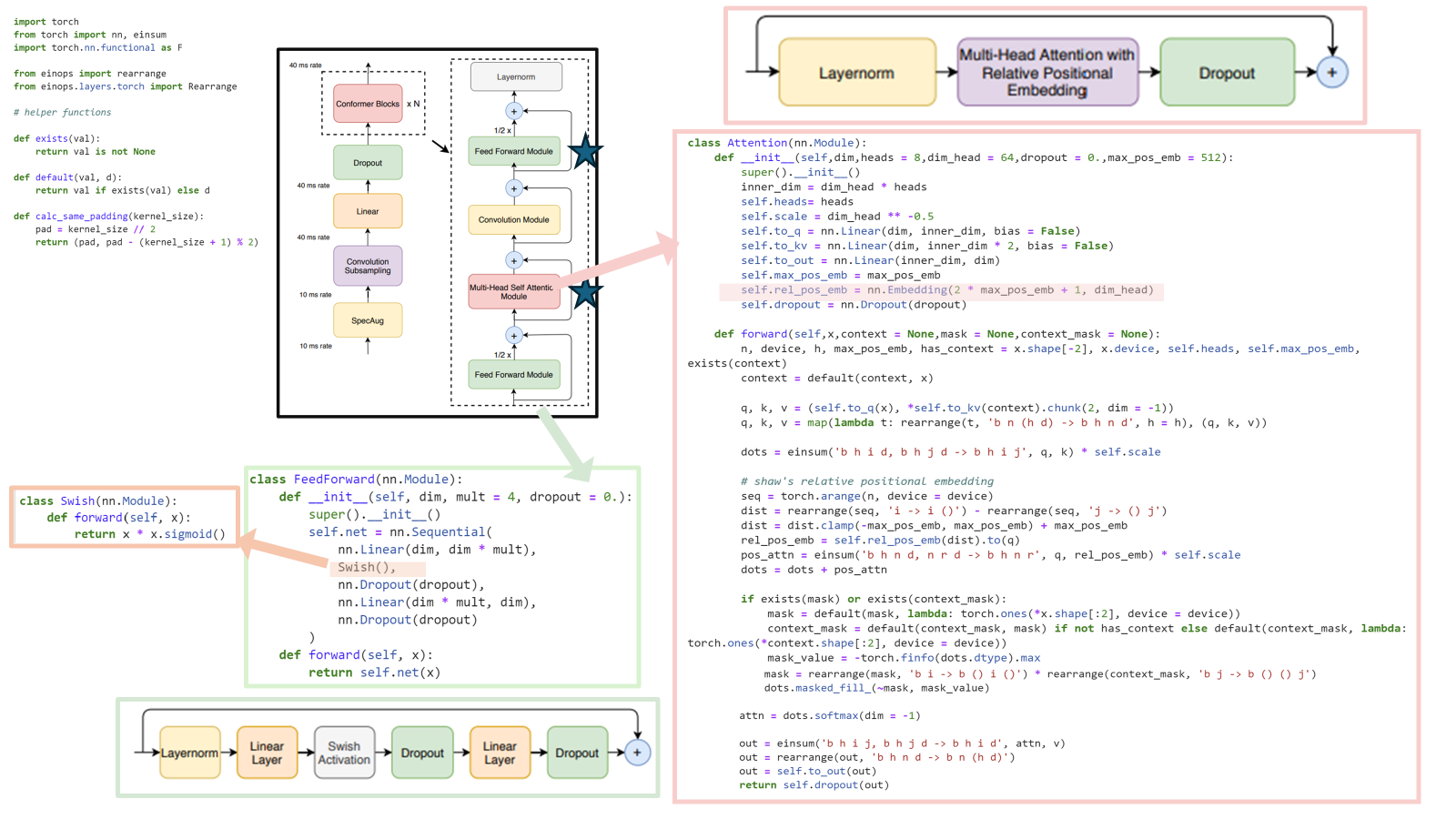
2 Conformer Encoder
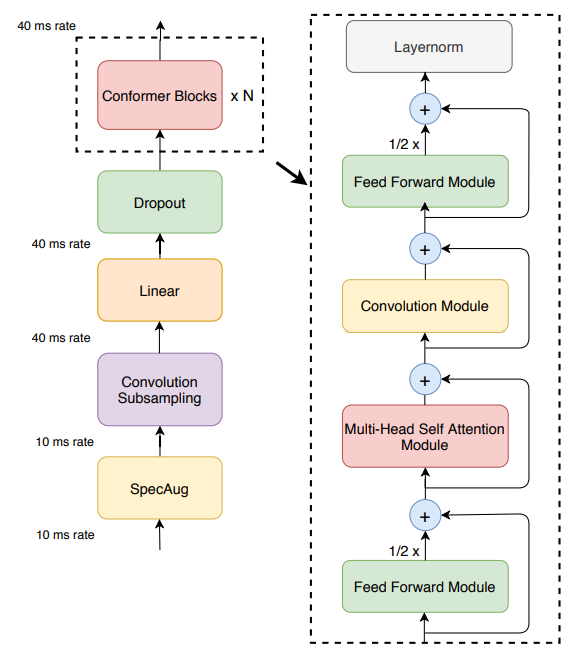
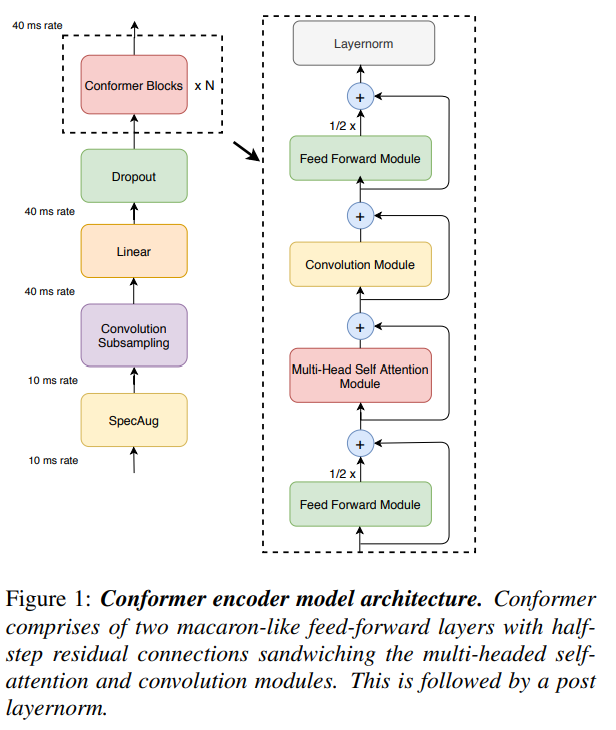
오디오 인코더는 먼저 convolution subsampling layer을 사용해 input을 처리한 후, 다수의 conformer block을 거침 (Fig 1. 좌측)
모델의 특징은 Transformer block 대신에 Conformer block을 사용한 것임
Conformer block은 4개의 모듈로 구성
(Fig1. 우측 -- feed-forward module, a self-attention module, a convolution module, and a second feed-forward module)
convolution subsampling layer?
Subsampling layer가 하는 기능적인 역할은 입력 데이터의 크기를 줄이는 것으로, 이는 위치 이동, 회전 및 부분적인 변화와 왜곡에 강인한 인식 능력을 키우는데 있어 중요한 역할을 수행
=> Subsampling layer를 통해 입력 데이터의 크기를 줄이면 비교적 강한 특징만 남고, 자잘한 변화들은 사라지는 효과를 얻게 됨
2.1 Multi-Headed Self-Attention Module (MHSA)
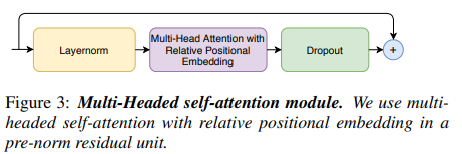
선행연구인 Transformer-XL를 따라, relative sinusoidal(sin 곡선) positional encoding을 사용
relative positional encoding을 통해
=> self-attention 모듈이 다른 입력 길이에 대해 더 잘 일반화할 수 있도록 함
=> 인코딩 된 결과는 발화 길이의 분산에 더 강하게 됨
더 깊은 모델을 훈련하고 정규화하는데 도움이 되는 dropout과 함께 prenorm residual units를 사용
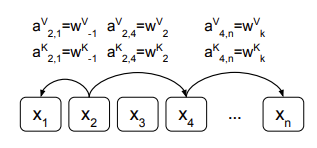
relative positional encoding
- 절대적인 position 정보를 더하는 것이 아니라 상대적인 position 정보를 주는 방식
(절대적인 : 값을 직접 지정해주고 그 차이 계산 / 상대적인: 어떤 값이든지 그 값의 차이만 나타냄)
- 상대적: 각 위치에는 그 위치와 다른 위치들 간의 상대적인 거리나 관계를 나타내는 값이 할당. => 각 위치의 값이 그 위치를 기준으로 다른 위치들과의 상대적인 위치를 나타내어 상대적인 위치 관계에만 집중
(이때 각각의 relative position에 대한 representation은 일정한 거리 k 이내에서 모델이 학습한 벡터)- attention layer에서 수행되는 attention score 계산/아웃풋 벡터 계산 단계에 각각 상대 위치에 대한 representation을 반영해 준 것
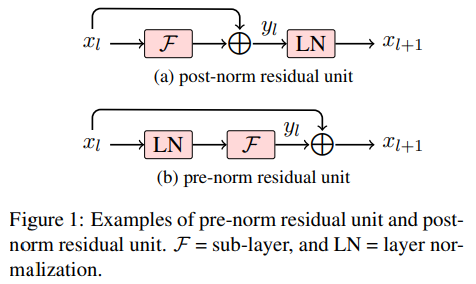
pre-norm(pre-layer normalization)
- 배경: Transformer 모델에서 layer normalization을 위해 예전에는 post-norm을 사용했는데 그 후, pre-norm이 사용
- 정의: Transformer 모델에서 사용되는 레이어 정규화의 한 형태로 각 sub layer(예. self-attention, FFN)의 입력에 적용되며, 이를 통해 각 sub layer의 연산 전에 레이어 정규화가 수행
- 목적: 학습 중 발생할 수 있는 수치적 불안정성을 줄이고, 더 깊은 네트워크의 효율적인 학습을 가능하게 함
- 수식은 아래와 같음
- layer normalization을 sub-layer의 부분으로 인식하고 residual connection에서 후처리때 아무것도 진행 X
- x_l (이전 레이어의 출력), F(해당 레이어의 연산), LN(레이어 정규화), θ(파라미터)
(https://arxiv.org/pdf/1906.01787.pdf)
- transformer 아키텍쳐는 input sequence 사이의 attention을 통해 input 사이의 관계를 모델링하는데 이때 sequence의 순서를 모델링하는데에는 한계가 있어 => "positional encoding"이 제시
- sinusoidal 함수를 사용한 인코딩
- 학습된 absolute representation 위치 정보 input에 대해 projection layer를 학습하여 사용 ~> 학습 중에 보지 않은 더 긴 길이의 인풋으로 확장이 어렵다는 한계
- transformer에서 고정된 길이의 문맥의 한계점을 극복하기 위하여 제안.
- 각 새로운 segment의 hidden state를 처음부터 계산하는 것이 아닌, 이전 segment에서 학습된 hidden state를 재사용하여 segment간의 recurrent connection을 형성.
- 이 recurrent connection을 따라서 정보가 전달되어 long-term dependency를 학습할 수 있게 되며, 이전 segment로부터온 정보를 전달함으로써 context fragmentation 문제도 해결할 수 있게 됨
- 또한 relative positional encoding을 사용하여, 시점의 혼란(temporal confusion)이 없이 state를 재사용할 수 있게 됨
2.2. Convolution Module (Conv)

pointwise convolution과 gated linear unit (GLU)인 gating mechanism으로 시작한 후,
그 후에는 single 1-D depthwise convolution layer가 이어지고, batchnorm이 deep module을 훈련하는 것을 돕기 위해 convolution 직후에 위치함
- Pointwise Conv (1X1 Conv): filter의 크기가 1x1으로 고정되어 있어 1 x 1 Conv라 불림. channel들에 대한 연산만 수행하여, channel의 수를 조절 할 수 있는 역할을 하며 보통 dimensional reduction을 위해 쓰임 (channel의 수를 줄이어, 연산량 감소에 도움)
- GLU Activation:
- Depthwise Conv : 각 채널마다 spatial feature를 추출하기 위해 고안된 방법
- Swish activation : regularizing에 도움을 주는 함수
2.3 Feed Forward Module (FFN)
“Attention is all you need” 에서 Transformer는,
- Multi-Headed Self-Attention Module(MHSA) layer 후에 feed forward을 배치하여, 두 개의 linear transformation과 그 사이에 비선형 activation으로 구성
- residual connection이 feed-forward layer 위에 추가 된 후 layer normalization이 이어짐

이는 Transformer ASR model에도 적용.
- feed forward module은 pre-norm residual units를 따르고
- residual unit 내에서 첫번째 linear layer 이전의 입력에 layer normalization을 적용
- Swish activation과 dropout으로 네트워크 정규화를 도움

2.4. Conformer Block
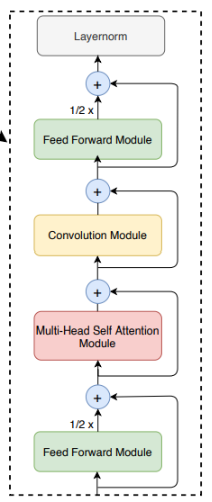 Conformer block은 feed-forward 모듈 사이에, multi-headed self-attention 모듈과 convolution 모듈이 포함
Conformer block은 feed-forward 모듈 사이에, multi-headed self-attention 모듈과 convolution 모듈이 포함
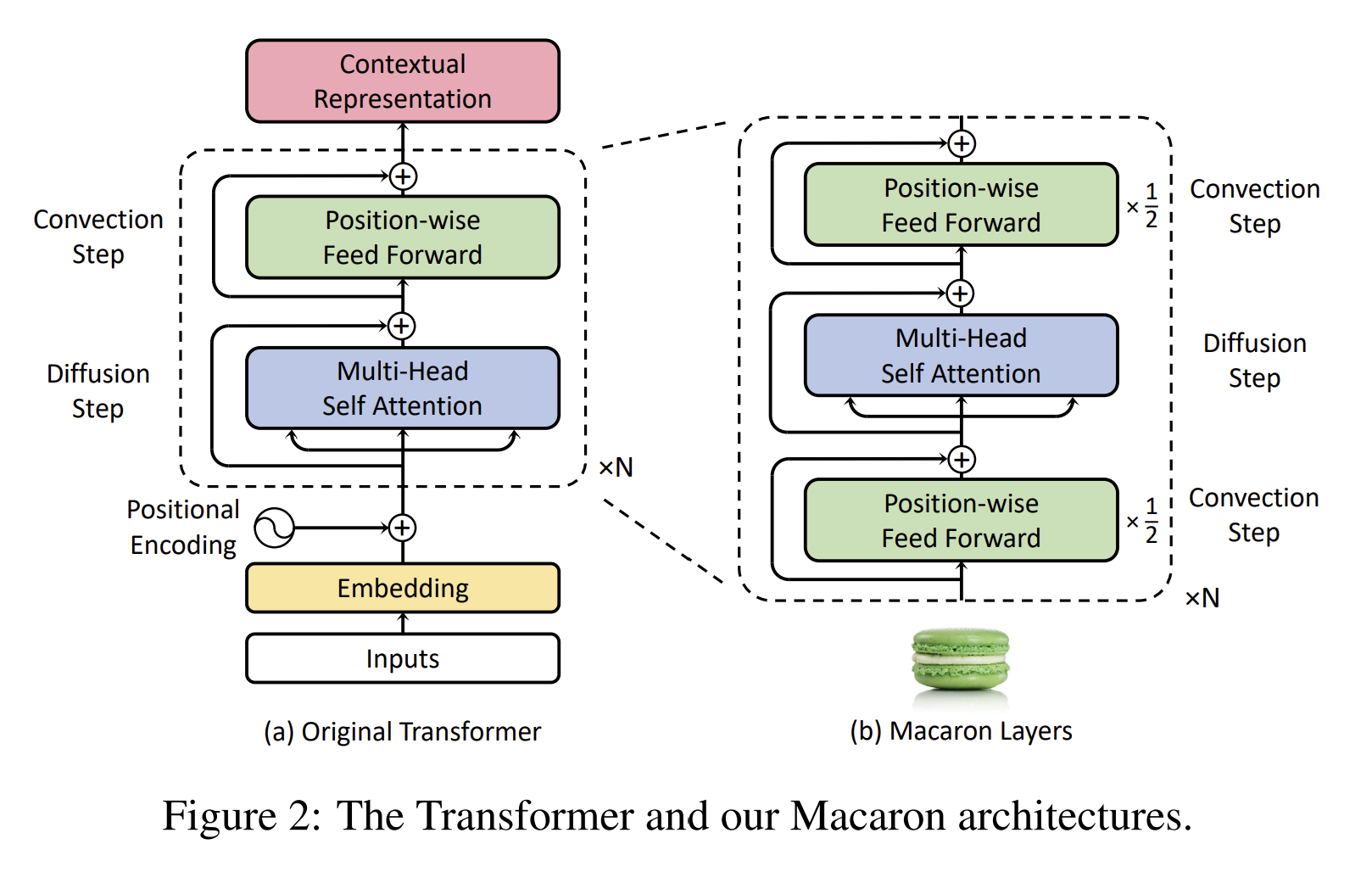
- 이런 구조는 Transformer block의 feed-forward layer를 두 개의 half-step feed-forward(attention 전과 후에 배치)로 대체한 Macaron-Net에서 영감 받음
- Macron-Net과 같이, 본 연구도 FFN module에 half-step residual weight를 사용
두 번째 feed-forwrad 모듈 다음에 최종 layernorm layer가 적용
수학적으로 conformer block i에 대한 입력 x_i에 대한 출력 y_i가 다음과 같음을 의미
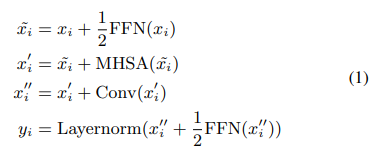
3 Experiments
3.1 Data
LibriSpeech dataset 사용 ( (1) 970 시간의 레이블링된 음성과 (2) 언어모델 구축을 위한 800M word token-only corpus로 구성)
- 25ms window, 10ms stride
- 80-channel filterbank feature
SpecAugment with mask parameter (F=27)와 최대 time-mask ratio(ps=0.05)를 가진 10개 time mask 사용
- time-mask의 최대 size는 발화 길이 * p_s로 설정
3.2 Conformer Transducer
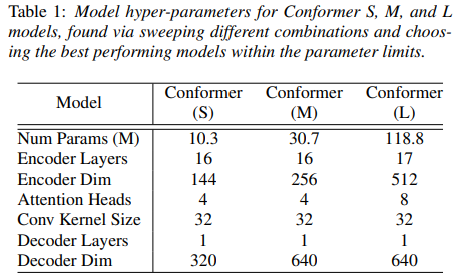
network의 깊이, model의 차원, attention head 수의 여러 가지 조합으로 small / medium / large 세 가지 모델에 대해 파라미터 제약에서 가장 효율적인 모델 선정
디코더는 모두 single-LSTM-layer 사용
(Table1: 그와 관련된 모델 하이퍼파라미터)
- 정규화를 위해 모듈 입력에 추가되기 전 conformer의 각 residual unit에 dropout을 적용
- variational noise가 정규화로 모델에 도입
- l2 정규화는 네트워크의 모든 훈련 가능한 weight에 추가
- Adam optimizer
- 3-layer LSTM 언어 모델 (너비가 4096)
- LibriSpeech 960h에서 구축된 1k Words Per Minute(WPM)으로 tokenized LibriSpeech960h transcript가 추가된 LibriSpeech language model corpus에서 훈련
- LM은 dev-set transcripts에서 word-level perplexity가 63.9
- shallow fusion을 위한 LM weight λ는 grid search을 통해 dev-set에서 조정
=> 모든 모델은 Lingvo toolkit으로 구현
3.3. Results on LibriSpeech
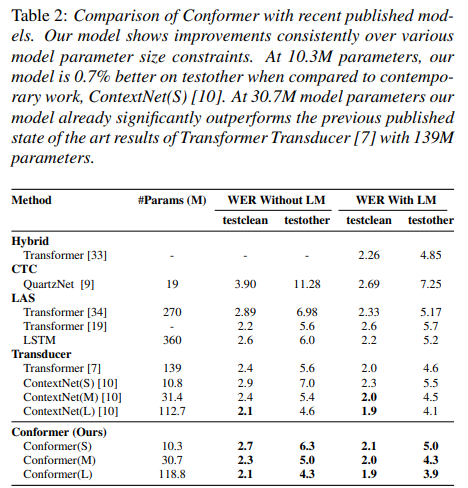
언어모델 x: medium model이 2.3/5.0으로 가장 좋은 성능
언어모델 O: 가장 낮은 word error rate (전체 중에서)
=> convolution과 transformer를 single neural network에 합치는게 좋구나 !
3.4. Ablation Studies
3.4.1. Conformer Block vs. Transformer Block
Conformer block은 Transformer block과 다름
=> 특히 Conformer block은 convolution block을 포함하고 Macaron-style block을 둘러싸는 한 쌍의 FFNs을 가지고 있음!
그래서, 전체 parameter의 수는 유지한채로, conformer block을 transformer block으로 변경해서 차이 비교
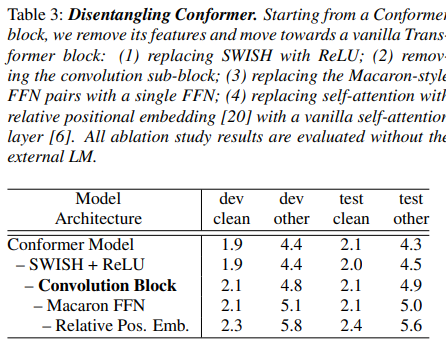
convolution sub-block이 가장 중요한 피쳐임
Macaron-style FFN pair이 single FFN보다 훨씬 효과적임
swish activation이 있으면 conformer model에서는 더 빨리 수렴함
3.4.2. Combinations of Convolution and Transformer Modules
multi-headed self-attention (MHSA) module을 convolution module과 조합하는 것의 다양한 방법 및 효과를 연구
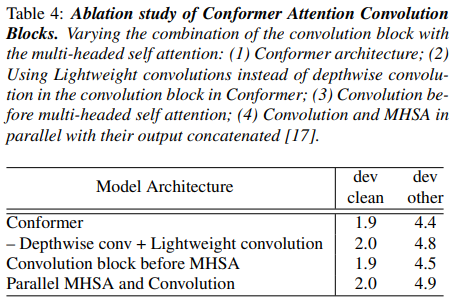
- convolution module에 있는 depthwise convolution를 lightweight convolution으로 변경
=> 성능 하락 ( dev-other에서) - Conformer model에서 MHSA module 전에 convolution module을 위치 시키기
=> 성능 0.1 하락 (dev-other에서) - 입력을 multi-headed self attention module 과 이 출력이 연결된 convolution module의 병렬 지점으로 분할하기
=> 성능 하락
결론: conformer block에서 self-attention module 뒤에 convolution module 두기
self-attention으로 convolution을 증강시키는 다양한 방법에 대한 결과 소개
=> 본 연구에서는 self-attention 모듈 뒤에 쌓인 convolution 모듈이 음성 인식에 대해 가장 잘 작동함을 발견
3.4.3. Macaron Feed Forward Modules
Transformer 모델에서 single feed-forward module (FFN)가 attention block을 두는 대신, Conformer block에는 self-attention 및 convolution modules를 샌드위치화하는 macaron-like 같은 Feed forward module 이 있음
또한 conformer feed forward module은 또한 half-step residuals와 함께 쓰임
이런, Conformer block을 single FNN / full-step residual로 변경했을 때의 영향력 (표 5)
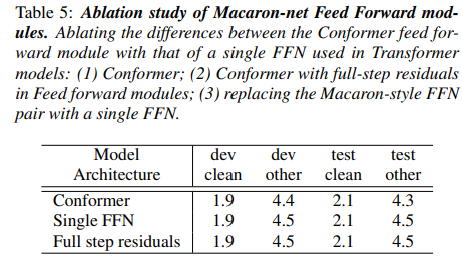
이전 연구에서 사용된 vanilla FFN과 Macaron-style half-step FFNs을 비교
=> 이를 통해 2개의 macaron-net style feed-forward layer 사이에 attention module과 convolution module을 끼워넣는 half-step residual connection이 있는 것이 conformer architecture에서 단일 feed-forward module을 사용하는 것보다 상당히 개선된다는 것을 발견
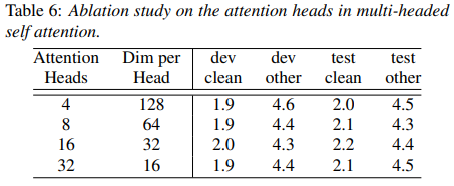
3.4.4. Number of Attention Heads
self-attention에서 각 attention head는 input의 서로 다른 부분을 집중하는 방법을 배워서 예측 개선이 가능함
여기서는 large model에서 attention head의 수를 4~32로 변화시켰을 때의 효과 연구
=> 실험 결과, attention head를 최대 16까지 증가했을 때 devother dataset의 경우 특히 성능 향상
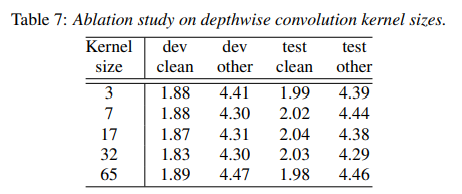
3.4.5. Convolution Kernel Sizes
depthwise convolution에서 kernel size의 효과를 알아보고자, large model에서 {3,7,17,32,65}로 변경 (이때 모든 레이어네는 동일한 kernel size)
=> 17/32 정도로 키우면 성능이 올라가지만 65까지 하면 오히려 줄어듦을 발견 (Table 7)
32 일 때가 제일 우수
4. Conclusion
Conformer는 end-to-end speech recognition을 위해 CNNs와 Transformers의 구성요소를 합친 아키텍처
각 요소의 중요성을 연구했고, convolution module을 포함하는 것의 중요성을 입증함
Code Review
코드는 https://github.com/lucidrains/conformer/blob/master/conformer/conformer.py 여기를 참고했다
-
rearrange?
- 텐서의 차원을 재구성(rearrange)
- 예) "batch, sequence length, channels" 순서의 차원을 "batch, channels, sequence length" 순서로 변경
-
einsum?
- einsum는 문자열로 표현된 표기법을 사용하여 텐서의 연산을 정의. 이 문자열은 입력 텐서의 차원을 식별하고 출력 텐서의 형태를 결정함.
-
clamp?
- clamp는 주어진 범위 내의 값을 갖도록 값을 제한하는 함수. 이는 주어진 텐서의 각 요소에 대해 작동하며, 만약 요소가 주어진 최솟값보다 작으면 최솟값으로, 최댓값보다 크면 최댓값으로 값을 변경
논문 후기
Transformer와 CNN과 관련된 여러가지 내부 요소들을 많이 알아야지 논문을 좀 더 쉽게 이해할 수 있을 것 같다
(4장짜리 논문이어서 그런지, ~~ 썼다. ~~ 썼다. 이런 경우가 많았다.)
ASR에서 CNN과 Transformer를 같이 쓰는 연구 흐름들을 잘 따라가다가 똭! 논문을 낸 그런 느낌이기도 했지만, 역시 흐름을 잘타서 좋은 연구를 내려는 노력이 필요한 것 같다!!
추가 궁금했던 부분들
1. 데이터에서 test-clean/test-other 의 차이점이 뭘까?
=> LibriSpeech 데이터셋의 두 가지 서로 다른 테스트 셋
- test-clean: 더 깨끗하고 명확한 음성 샘플을 포함
- test-otehr: 더 많은 환경 소음이나 다양한 억양 및 발음을 포함한 샘플이 포함
2. relative positional encoding 관련 코드 작동 원리
https://medium.com/@ngiengkianyew/what-is-relative-positional-encoding-7e2fbaa3b510 에서 다루고 있음
-
relative와 absolute의 가장 큰 차이점
- relative positional encoding considers the information between pairwise positions into account, while absolute positional encoding does not.
- relative는 각 position embedding에 대해서 값을 랜덤으로 초기화 하지 않음 => 그대신, pair-wise embedding matrix (matrix of size (T, 2 * T — 1)) 를 만들어서, 단어에서 단어로의 positional distance를 파악하고자 함
-
pair-wise distance matrix에서 word_i에 대해 다른 단어 word_i-4 ~ word_i+4까지는 이런식으로 표현이 됨

- 예를 들어서 word A가 position 1에 있고, word B가 position 3에 있으면, word A & B의 positional encoding은 Index 6이 됨 (word B가 word A보다 2 position 앞에 있어서)
- 이런식으로 word B에서 word A까지 상대적인 거리가 반영됨
-
결론적인 "작동 원리"
- 예) [‘’this’, ‘is’, ‘very’, ‘awesome’, ‘too’]
- 'this'에 대한 relative position encoding은 [index_4, index_5, index_6, index_7, index_8]
- ‘is’ 는 [index_3, index_4, index_5, index_6, index_7]
- 'very'는 [index_2, index_3, index_4, index_5, index_6]
=> 이런식으로 단어 개수에 따라서 index에 대한 정의가 세워지면 그에 맞춰서 각 단어별로 index_숫자 값이 나오고 -> 이걸로 matrix가 만들어지게 됨
-
그럼 코드에서는 어떻게 응용할 수 있는가?
batch_size = 2 time_steps = 5 embedding_dim = 11 # 1. (2 * T - 1, D) 형태로 positional embedding tensor를 초기화 (D: embedding dimension/ T: 시간 단계) positional_embedding = torch.nn.Parameter(torch.randn(2 * time_steps - 1, embedding_dim)) print(positional_embedding.shape) # torch.Size([9, 11]) assert positional_embedding.shape == (2 * time_steps - 1, embedding_dim) X = torch.randn(batch_size, time_steps, embedding_dim) # X는 (B, T, D) 형태의 Query vector # 2. 위치 인코딩 행렬을 얻기 위해 행렬 곱을 수행 relative_positional_encoding = torch.matmul(X, positional_embedding.transpose(0,1)) print(relative_positional_encoding.shape) # torch.Size([2, 5, 9]) assert relative_positional_encoding.shape == (batch_size, time_steps, 2 * time_steps - 1) print(relative_positional_encoding[0]) # 첫 번째 배치에 대한 상대적 위치 인코딩 행렬
3. Transformer_XL
- transformer에서 고정된 길이의 문맥의 한계점을 극복하기 위하여 제안.
- 각 새로운 segment의 hidden state를 처음부터 계산하는 것이 아닌, 이전 segment에서 학습된 hidden state를 재사용하여 segment간의 recurrent connection을 형성.
- 이 recurrent connection을 따라서 정보가 전달되어 long-term dependency를 학습할 수 있게 되며, 이전 segment로부터온 정보를 전달함으로써 context fragmentation 문제도 해결할 수 있게 됨
- 또한 relative positional encoding을 사용하여, 시점의 혼란(temporal confusion)이 없이 state를 재사용할 수 있게 됨
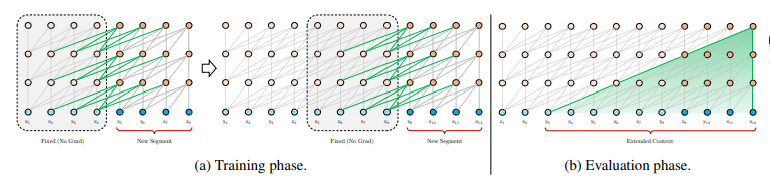
=> 추가 자료 조사
Conformer 논문에서 Transformer_XL을 다룬 이유는, "Relative Positional Encoding"과 관련된 부분을 소개하기 위해서였음
여기 블로그에서 "Relative Positional Encoding"이 가지는 원리와 장점을 잘 소개해주고 있다
4. pre-norm(pre-layer normalization)
- 배경: Transformer 모델에서 layer normalization을 위해 예전에는 post-norm을 사용했는데 그 후, pre-norm이 사용
- 정의: Transformer 모델에서 사용되는 레이어 정규화의 한 형태로 각 sub layer(예. self-attention, FFN)의 입력에 적용되며, 이를 통해 각 sub layer의 연산 전에 레이어 정규화가 수행
- 목적: 학습 중 발생할 수 있는 수치적 불안정성을 줄이고, 더 깊은 네트워크의 효율적인 학습을 가능하게 함
- 수식은 아래와 같음
- layer normalization을 sub-layer의 부분으로 인식하고 residual connection에서 후처리때 아무것도 진행 X
- x_l (이전 레이어의 출력), F(해당 레이어의 연산), LN(레이어 정규화), θ(파라미터)
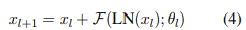
(https://arxiv.org/pdf/1906.01787.pdf)
5. Swish Activation
=> 자료조사를 위해 https://medium.com/@neuralnets/swish-activation-function-by-google-53e1ea86f820 를 참고
-
[한줄 요약] Swish는 매우 깊은 신경망에서 ReLU 보다 높은 정확도를 달성
-
Swish => f(x) = x · sigmoid(x)로 정의
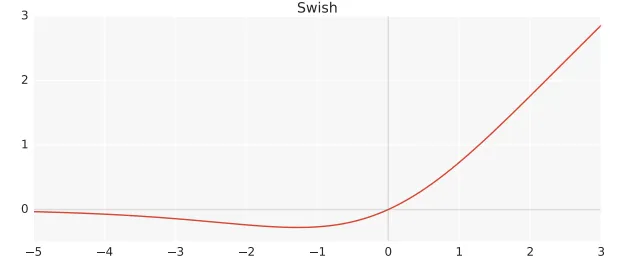
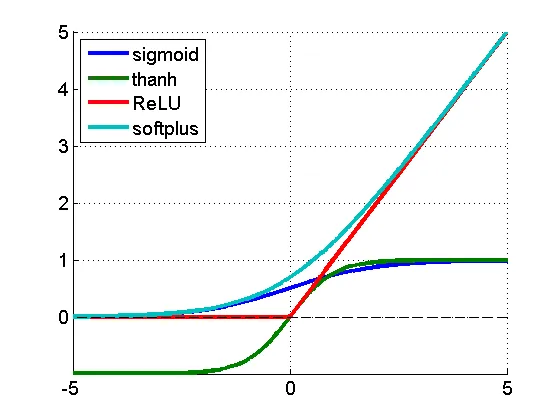
- ReLU(f(x)=max(0,x))의 문제점은, 입력 x의 절반에 대해 미분값이 0인 것
- 그래서 Swish는 이를 극복하기 위해, 등장하였고 깊은 신경망에서 특히 우수한 성능을 보였으며, 최적화가 어려운 층에서도 이를 극복할 수 있게 되었음
