https://arxiv.org/pdf/1904.03670.pdf
Abstract
기존의 spoken language understanding (SLU) 시스템은 speech를 map해서 text로 만들고 text를 intent로 만들지만 end-to-end SLU 시스템은 speech를 바로 intent로 변환함 (single trainable 모델로)
intent?? 밑에커피머신 예시 (fig 1d예시)
end-to-end model로 많은 양의 훈련 데이터없이 높은 정확도 얻기는 어렵다
그래서 end-to-end SLU에서 data requirements를 줄일 방법을 제시함
이 모델은 words/음소를 예측하는 첫번째 pre-trained 모델이고 SLU를 위해 좋은 피쳐를 학습한다
새로운 SLU 데이터, Fluent Speech Commands를 제시하고 본 논문에서 제시한 방법이 성능을 올림을 입증
-> 두 가지 경우에서; 전체 데이터셋이 훈련에 쓰였을 때 / 일부만 쓰였을 때
모델의 능력을 일반화하고자 추가 실험 진행함
1 Introduction
Spoken language understanding (SLU) 시스템은 "meaning or intent of a spoken utterance" 을 뜻함
이는 voice user interfaces에 중요하다 -> 이 때 화자의 발언은 action/query로 변환되어야 하기 때문
예를 들어서 voice-controlled coffee machine의 경우, “make me a
large coffee with two milks and a sugar, please” 같은 발화는 다음의 의미를 가진다
=> {drink: "coffee", size: "large", additions: [{type: "milk", count: 2}, {type: "sugar", count: 1}]}.
conventional SLU pipeline은 두 모듈로 구성
(1) automatic speech recognition (ASR) module : speech를 text transcript로 map
(2) natural language understanding (NLU) module: text transcript를 speaker's intent로 map
이에 대안적인 방법은 end-to-end SLU암
이는 single trainable model 로서 speech audio를 직접적으로 speaker's intent로 map한다 (text transcript를 명백히 생성하지 않고)
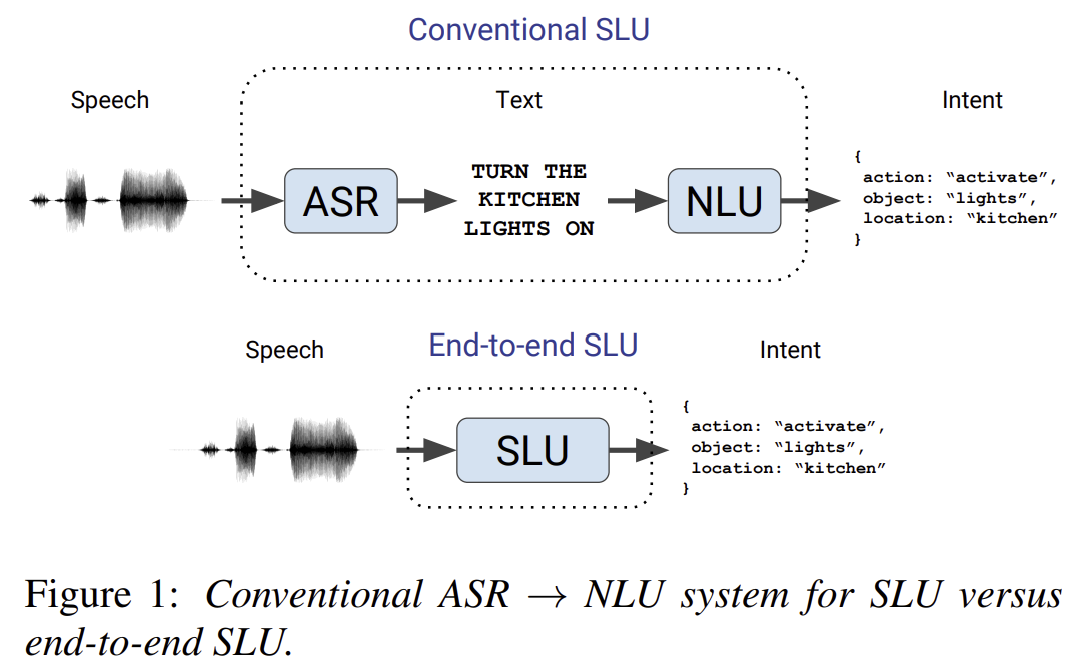
End-to-End SLU의 특징
(1) directly optimizes the metric of interest (intent recognition accuracy),
(2) text 예측에 모델링 노력 필요 X, 그래서 더 compact model을 만들고 error-prone intermidate step(search alogrithm, 언어모델, finite state transducers등..)을 피하게 됨
(3) and enables harnessing aspects of the utterance that may
be relevant for inferring the intent, but are not present in
the text transcript, such as prosody(운율학).
End-to-end models은 딥러닝으로 만들어져서, 인풋 시그널의 계층적인 representation을 자동으로 학습함
Speech는 hierarchical way로 represent되는 natural 한 방법: waveform → phonemes → morphemes → words → concepts → meaning.
하지만 speech signals는 single speaker에 대해서도, 고차원이고 highly variable해서 -> 딥러닝 모델을 훈련하고 이런 hierarchical representations를 큰 훈련데이터 없이 학습하는 것은 어렵다
CV, NLP, ASR은 지도학습의 방법에 대해서 훈련 데이터 부족의 문제를 지적했다
이러한 흐름을 따라 본 연구에서는 효율적인 ASR-based의 pre-training 방법론을 제시함 -> 그리고 특히 훈련 데이터의 양이 적을 때 이 end-to-end SLU model의 성능이 좋다는 것을 입증함
Contribution
(1) a dataset for realistic SLU experiments.
(2) this dataset to demonstrate effective speech model pre-training techniques for low-resource SLU
(3) code & data 공개
발표 청강
end-to-end로 contribution 제시
음성에서 json 바로 가기 어려우니까 그 중간에 방법을 넣자 !!
라벨링이 되어져 있는 형태로 output을 반환함
음성이해시스템에 대한 논문 -> 시리, 네이버 클로바 => 이런 찐 시스템에 쓰이는 거가 대표적인 예시군 !!!!
데이터셋 구축에 초점을 많이 둠 (Fluent speech라는 어떤 회사에서)
서버에 쓰일 데이터를 만들 때는 대체로 json 포맷으로 만듦
궁금증
-
데이터 구축 관련
(1) Intent는 어떻게 만들어지는 걸까 -> 오잉 라벨링을 한건가?? (훈련 데이터는 한거고 테스트도 한건가?? ground truth는 어떻게) : 데이터는 다 라벨링함 !
(5) 각 녹음을 두 번씩 녹음해서 말하면 -> 다 2개 씩 데이터셋으로 중복으로 들어가고 traiin/test 분리만 잘하는건가?? : 중복으로 쓴건 아니고 잘 된거 하나만 써서 최종 데이터 구축 -
실험 결과 어떻게 나오는거지??
(4) Intent에 대한 accuracyㄴ은 어떻게 측정???? : -> 모든 라벨에 대한 ground truth가 맞을때만 !
(2) Fig2는 어떻게 작동하는거지>???? 무슨 그링인거지?? => A. 모델 전체 구조.
(3) Table2는 No unfreezing? Freezing이 제일 좋으건가?
