이미지 출처: https://mr-waguwagu.tistory.com/30
https://junseong.oopy.io/paper-review/cbert-augmentation
https://www.researchgate.net/figure/The-Transformer-based-BERT-base-architecture-with-twelve-encoder-blocks_fig2_349546860
0. ABSTRACT
BERT
(=Bidirectional Encoder Representations from Transformers)
1. deep bidirectional representations를 unlabeled text로부터 pretrain하고자 고안
-> 모든 레이어에서 왼, 오른쪽 문맥에 jointly하게 conditioning함
2. pre-trained BERT는 one additional output layer만으로도 fine-tuned될 수 있음
-> question answering, language inference 같은 여러 업무에서 state-of-the-art models 달성 가능
3. 11개 NLP task에서 new state-of-the art 결과 거둠
-> GLUE score를 80.5%, MultiNLI accuracy를 86.7%, SQuAD v1.1 question answering Test F1을 93.2, SQuAD v2.0 Test F1을 83.1
1. Introduction
1.1 language model pre-training은 많은 NLP분야에서 효율적임.
- sentence-level task: natural language inference에 해당
- paraphrasing: 문장 사이들을 전체적으로 분석해서 관계를 예측하고자 함
- token-level task: named entity recognition(개체명 인식)
- question answering: 모델은 token-level에서 fine-grained output을 생성하도록 요구됨
개체명 인식 출처
: 이름을 가진 개체(named entity)를 인식하겠다는 것(= 어떤 이름을 의미하는 단어를 보고 그 단어가 어떤 유형인지를 인식하는 것)
예) '유정이는 2018년에 골드만삭스에 입사했다.'
사람(person), 조직(organization), 시간(time)에 대해 개체명 인식을 수행하는 모델
-> [결과] 유정 - 사람 / 2018년 - 시간 / 골드만삭스 - 조직
1.2 pre-trained language representation을 down-stream tasks에 적용하는 두 방법
down-stream tasks: 분류, 군집화 등 우리가 풀고 싶은 구체적인 문제들
출처
피처베이스(feature-based): 임베딩은 그대로 두고 그 위에 레이어만 학습 하는 방법
파인튜닝(fine-tuning): 임베딩까지 모두 업데이트하는 기법
a. feature-based
- 특정 task를 해결하고자 architectures를 구성해 pre-trained representations를 부가적인 feautures로서 사용하는 것
- 예) ELMo

ELMO 출처
- task에 따라 weigth를 곱함
- weight는 task가 달라지면 다시 곱해야 함
- 전방향/후방향을 독립적으로 구한 후, 그 결과를 결합해서 사용(양방향X)
b. fine-tuning
- 모든 pre-trained parameters를 downstream task에서 학습시키고 최소한의 task-specific parameters를 도입
- 예) Generative Pre-trainde Transformer(OpenAI GPT)

GPT 출처
- task에 따라 embedding 구조가 pre-train할 때와 다름
- 트랜스포머의 디코더만 사용해 -> autoregressive한 모델
- sequence를 왼->오로 진행하며 문맥 파악
Autoregressive Language Model
: 자기 자신의 입력을 예측하는 모델, (=자기회귀언어모델)
: 입력 문장으로 예측할 라벨로 사용할수 있어, 특별한 라벨링이 필요하지 않음
: 입력 문장을 토큰으로 나누고 주어진 토큰들이 자기 자신의 입력의 다음 토큰을 예측하는 방식으로 학습
예) 단순, ##함, ##을, 얻기란, ... 과 같은 입력에서 단순 -> ##함을 예측하고, ##함->##을을 예측, ##을 -> 얻기, 순으로 예측 잔행

c. 두 접근 방식
- pre-training하는 동안 같은 objective function을 공유함
-> unidirectional language models를 사용해서 general language representaions를 학습하도록 함
(A.4에 BERT, ELMo, OpenAIGPT 관련 추가 설명)
1.3 이전 기술들의 한계점
- 특히 fine-tuning approaches에 대해 pre-trained representations의 힘이 제한
-> standard language models은 unidirectional이기 때문
-> 이로 인해, pre-training 동안에 사용될 수 있는 arhcitecture의 선택이 제한됨 - 예) OpenAI GPT는 left-to-right architecture를 사용
-> 각 토큰은 트랜스포머의 self-attention layers 안에서 이전 토큰에만 attend 가능 - (결론적으로) sentence-level taks에서 sub-optimal하다 + token-level tasks에 적용 시 안좋다
- 예) question answering의 경우, both directions로부터 context를 포함하는 것이 중요하기 때문
1.4 해당 논문에서 BERT 제시
특징
- BERT(= Bidirectional Encoder Representations from Transformers)
- fine-tuning based approahes
-> (이를 통해) uniditectionality constraint를 완화함
-> (어떻게) masked language model(=MLM) pre-training objective로 사용!
(A.4 Comparison of BERT, ELMO and OpenAI GPT에 부가 설명)
1. MLM
- 인풋으로부터 몇 개의 토큰을 랜덤으로 mask함
- 목표는 masked word로부터 original vocabulary id를 문맥에만 의존해 예측하는 것이다
- MLM objective는 왼, 오른쪽 문맥을 융합하도록 해줌
-> 이를 통해 deep bidirectional Transformer를 pretrain하는 것이 가능해짐
2. NSP(next sentence prediction)
- text-pair representations를 jointly하게 pretrain함
1.5 해당 논문이 기여한 바
- launguage representations에 있어 bidirectional pre-training의 중요성을 입증함
- unidirectional language models를 pre-training을 위해 사용한 Radford et al.(2018)과 달리 masked language models로 pre-trained deep bidirectional representations를 가능하게 함
- 이는 shallow concatenations(left-to-right와 right-to-left LMs를 독립적으로 훈련함)를 사용한 Peters et al.(2018a)와도 상반됨
- pre-trained representations가 많은 heavily-engineered task-specific architectures의 필요성을 감소함을 입증함
- BERT는 large suite of sentence-level과 token-level tasks에서 많은 architectures를 능가한, state-of-the art performance를 달성한 첫번째 fine-tuning 기반 representation 모델임
- 11개의 NLP tasks에서 state-of-the-art를 향상시킴
2. Related Work
pre-training general language representations와 관련되어 널리 쓰이는 접근법에 대해서 알아보겠다.
2.1에서는 ELMO의 등장 배경을 2.2에서는 GPT의 배경을 언급
2.1 Unsupervised Feature-based approaches
(1)
- 단어에 대한 널리 적용 가능한 representations를 학습하는 것은 non-neural과 neural 모두 활발한 연구였다.
- 사전 훈련된 워드 임베딩은 현대 NLP에서 중요한 부분이다.
(scratch(Turian et al., 2010)에서 학습된 embeddings에도 중요한 improvements를 제공했다) - 단어 임베딩 벡터를 사전훈련 하기 위해서 left-to-right language modeling objectives가 사용되며, 왼오른쪽 문맥의 적절한 단어로부터 부적절한 단어를 차별화하고자 objectives가 사용된다.
(2)
- 이러한 접근법들은 coarser granularities(sentence embeddings, paragraph embeddings)로 generalized되었다.
- sentence representaions를 훈련하고자 이전 연구들은, 다음 objecitves를 사용했다
(다음 후보 문장들 순위 매기기, 이전 문장의 representation이 주어진 다음에 left-to-right 생성하기, auto-encoder에서 파생된 objectives를 denoising하기)
(3) ELMo와 선행 연구
- 전통적인 워드 임베딩 연구를 different dimension을 따라서 일반화
- context-sensitive features를 left-to-right 그리고 right-to-left represenations로부터 추출한다
- 각 토큰의 contextual representation은 left-to-right와 right-to-left의 concatenation이다
- contextual word embeddings를 existing task-specific architectures와 통합할 때, ELMo는 몇개의 NLP benchmarks의 주요 분야에서 state-of-the art를 달성했다
(question answering, sentiment analysis, named entity recognition) - Melamud et al.(2016)은 왼, 오른쪽 문맥으로부터 한 단어를 예측하고자 LSTMs를 사용해서 contextual representations를 학습하는 것을 제안했다
(ELMo와 유사하게 이 모델은 feature-based이고 deeply bidirectional하지 않다.) - Fedus et al.(2018)은 cloz task가 text generation models를 강건하게 향상시키는데 사용될 수 있음을 입증했다.
2.2 Unsupervised Fine-tuning Approaches
(1)
- unlabeled text로부터 오로지 워드 임베딩 파라미터를 사전훈련하는 것이었다.
(2) GPT의 등장
- contextual token representations를 생성하는 sentence, document encoders는 unlabeled text에 의해서 pre-trained 되거나, supervised downstream task를 위해 fine-tuned되었다.
-> 이점은 적은 파라미터가 scratch로부터 학습되어도 괜찮다는 것이다. - 이 덕에 OpenAI GPT 는 GLUE benchmark의 많은 sentence-level tasks에서 state-of-the-art를 달성했다.
- left-to-right language modeling과 auto-encoder objectives가 그런 모델들을 pre-training하는데 사용되어왔다.
2.3 Transfer Learning from Supervised Data
- natural language inference와 machine translation에서 큰 데이터셋으로 supervised task, transfer의 효율성이 입증되는 여러 연구들이 있었다.
- computer vision 연구는 또한 large pre-trained models에서의 transfer learning의 중요성을 입증했다
(효율적인 방법은 모델을 ImageNet으로 사전훈련된 것으로 fine-tune하는 것이다)
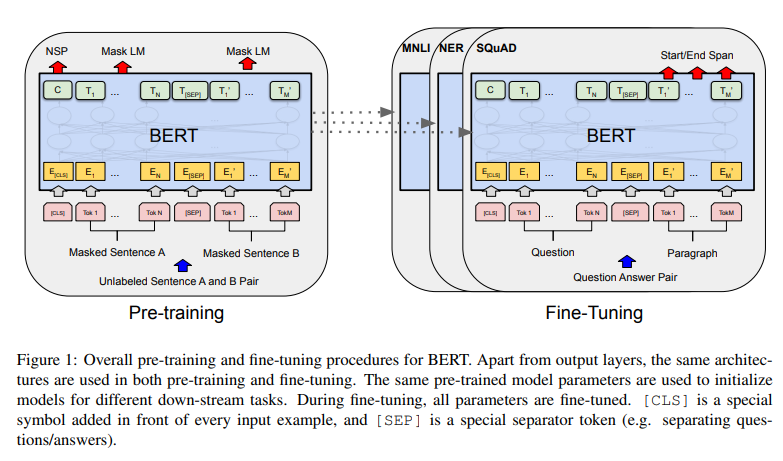
3. Methodology
3.1 BERT
특징
- 다양한 task에 대해서 'unified(통일된)' architecture.
- 두 단계가 있음
1. pre-traing
- 모델은 다양한 pre-training tasks에 대해서 unlabeled data로 훈련된다.
2. fine-tuning
- 처음에는 pre-trained parameters로 초기화된다.
- 모든 파라미터들은 downstream tasks에서 labeled data로 fine-tuned된다.
(각 downstream task는 separate fine-tuned models를 가진다, 그들이 비록 같은 사전 훈련된 파라미터들로 초기화될지라도)
Model Architecture/Size
-
multi-layer bidirectional + 트랜스포머 인코더 기반
(기존 Transformers와 거의 동일해서, 해당 부문 생략) -
L: number of layers, H: hidden size, A: number of self-attention heads
-
BERTBASE (L=12, H=768, A=12, Total Parameters=110M)
-> OpenAI GPT와 비교하고자 같은 모델 크기로 설정 -
BERTLARGE (L=24, H=1024, A=16, Total Parameters=340M)
-
BERT Transformer는 bidirectional self-attention 사용하는 반면, GPT Transformer는 constrained self-attention 사용(각 토큰은 왼쪽에 있는 문맥에만 attend 가능)
BERT에서 쓰이는 특별한 토큰
1. [CLS]: 문장의 시작을 알림
2. [SEP]: 문장 종결을 의미
3. [MASK]: 마스크 토큰
4. [PAD]: 배치 데이터의 길이를 맞춤
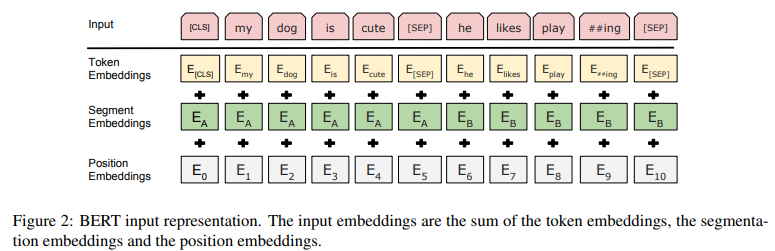
Input/Output Representations
-
(다양한 down-stream tasks를 다루게 하고자,) 인풋은 (1) single senetence와 (2) 한 토큰 시퀀스에서의 pair of sentence 둘 다 가능.
-> sentence는 실제 linguistic sentence보다는 arbitrary span of contiguous text가 될 수 있다. (=우리가 알고 있는 문장이 아니라 연속적인 text span이어도 된다는 뜻)
-> (결론적으로) BERT에 대한 인풋 토큰 시퀀스로 (1) single sentence이거나 (2) 함께 packed된 two sentence일 수 있다. -
30,000 token vocabulary가진 WordPiece embeddings 사용
-
각 시퀀스의 첫번째 토큰은 항상 특별한 classification 토큰인 [cls]다.
-> 이 토큰에 상응하는 final hidden state는 classification에서 aggregate(종합) sequence representation으로서 쓰인다 -
sentence pairs는 single sequence로 함께 packed된다
-
두 방법으로 sentence pairs은 차별화된다
- 특별한 토큰 [sep]로 분류한다
- 학습된 임베딩을 모든 토큰에 추가한다(그것이 문장 A에 속하는지 문장 B에 속하는지 알고자)
-
E: input embeddings, C: final hidden vector of the special [cls] token, Ti: final hidden vecotr for the ith input token
-
토큰에 대해서, input representation은 corresponding token, segment 그리고 position embeddings을 합하면서 구조화된다
과정
1. 입력 토큰에 해당하는 토큰 벡터를 참고해 토큰 임베딩 만들기
2. 세그먼트 임베딩(첫 번쨰 문장인지, 두 번째 문장인지)를 참조해 더하기
3. 입력 토큰의 문장 내 절대적인 위치에 해당하는 포지션 임베딩 더하기
4. 세 임베딩을 더한 각각의 벡터에 레이어 정규화, 드롭아웃 시행하기
3.2 Pre-training BERT
- 두 개의 unsupervised tasks로 BERT를 pre-train함
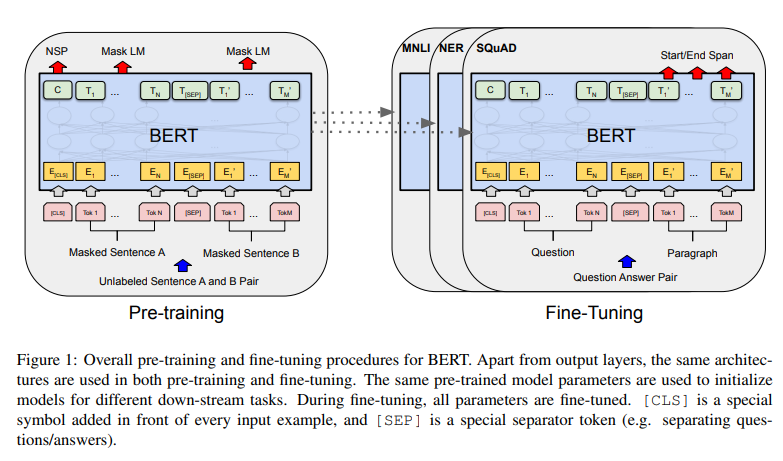
Task #1. Masked LM
(등장 배경)
- deep bidirectional model이 left-to-right model이나 shallow concatenation of a left-to-right, right-to-left model보다 더 powerful하다.
- standard conditional language models은 left-to-right나 right-to-left에만 훈련될 수 있다
-> 왜냐하면 bidirectional conditioning이 각 단어를 간접적으로 보게('see itself') 허용하고, 모델이 target-word를 multi-layered context에서 예측하게 하기 때문.
(특징)
- (deep bidirectional representation을 훈련하고자,) 인풋 토큰을 랜덤으로 몇 퍼센트를 mask하고 그 masked tokens(=Cloze task)를 예측
- encoder의 self-attention을 사용해, 모든 위치에서의 단어들이 고려 -> bidirectional 함
- standard LM에서처럼 mask tokens에 상응하는 마지막 히든 벡터가 모든 vocabulary에 대해서 아웃풋 소프트맥스로 반영된다.
- 실험에서 랜덤으로 각 시퀀스, WordPiece tokens의 15%를 mask한다
- denoising autoencoder와 달리 전체 인풋을 reconstructing하기 보다는 masked words를 예측만 한다.
denoising autoencoder 출처
: 데이터에 Noise 가 추가되었을 때, 이러한 Noise를 제거하여 원래의 데이터를 Extraction하는 모델
(문제점)
- 결국 bidirectional pre-trained model을 얻었다
- 문제점은 pre-training과 fine-tuning 사이에 불일치(mismatch)가 생긴다는 것이다
-> 왜? [MASK] 토큰이 fine-tuning과정에 쓰이지 않아서
-> 이를 완화하고자, 'masked' words를 actual [MASK] token과 항상 대체하지는 않는다.
(그렇다면 어떻게?는 작동과정에서 추가 설명)

(작동 과정)
- 훈련 데이터를 생성할 때, 예측을 위해 랜덤으로 토큰 position의 15%를 선택한다.
- 실제로 fine-tuning 과정에서 mask 토큰이 쓰이지 않아, mismatch(불일치)를 줄이고자,
- 만일 i번째 토큰이 뽑히면, 그를
(1) 80%는 [MASK] 토큰으로 교체
(2) 10%는 다른 토큰으로 교체
(3) 10%는 변경되지 않은 i 번쨰 토큰으로 교체 - Ti가 original token을 cross entropy loss로 예측하고자 쓰인다
(A.1에 MLM 관련 추가 설명)
Task #2. Next Sentence Prediction(NSP)
(등장배경)
- 많은 주요한 downstream tasks는 두 문장 사이의 관계(language modeling에 의해 직접적으로 포착되지 않는)를 이해하는데 기반을 둔다
- 문장 관계를 이해하는 모델을 훈련하고자, binarized next sentence prediction task(단일 언어 코퍼스에서 생성될 수 있는)를 사전훈련한다
NSP 특징
- 다음 문장이 맞는지, 아닌지 판단하는 classification 해당 문제
- [SEP] 토큰 사용: 각 문장이 다른 문장임을 보여주고자, 문장 사이에 넣음
- 가장 앞에 있는 [CLS] 토큰에 이 문장이 이어지는 문장인지에 대한 예측 진행

(작동 과정)
1. 학습과정에서 모델은 두 문장 A, B를 입력으로 받는다
2. 50%의 경우는 두 번째 문장인 B는 'A의 실제 다음 문장(labeled as IsNext)'이고,
나머지 50%는 코퍼스로 '랜덤 문장(관계가 없는 임의의 문장, labeled as NotNext)'이다.
3. C(Figure1 참고)는 다음 문장 예측을 위해 쓰인다.
- 이는 QA와 NLI 모두에 도움되는 과정이다
* NSP task는 representation-learning objectives와 밀접한 연관이 있다
(A.1에 NSP 관련 추가 설명)
MLM에서는 문장 내, 단어들간의 맥락을
NSP에서는 문장들 간의 관계를 파악!
(A.2에 Pre-trainng procedure 관련 추가 설명)
Pre-training data
- pre-training corpus: BooksCorpus(800M words), English Wikipedia(2,500M words)
- Wikipedia: text passages만 extract하고, lists, tables, headers는 무시
- long contiguous sequences를 추출하기 위해서 document-level corpus를 사용하는 것이 중요함
3.3 Fine-tuning BERT
(특징)
- 트랜스포머의 self-attention mechanism은 BERT에게 많은 downstream tasks를 model하는 것을 허용해서(single text 또는 text pairs에 상관없이) 간단함.
- text-pair의 경우, 일반적으로 bidirectional cross attention을 적용하기 전에 text pairs를 독립적으로 인코딩한다
- BERT는 self-attention mechanism을 사용해서 두 단계(bidirectional cross attention + text pair 인코딩)를 단일화함
-> concatenated text pair를 self-attention으로 인코딩하는 것은 두 문장 사이의 bidirectional cross attention을 포함하기 때문
(과정)
-
각 task에 대해서 알맞는 inputs과 outputs를 입력으로 넣고 해당 파라미터들을 해당 task에 맞게 end-to-end로 fine-tune(업데이트)한다
-
인풋의 경우, pre-training으로부터의 sentenceA와 sentence B는
(1) sentence pairs in paraphrasing,
(2) hypothesis-premise pairs in entailment,
(3) question answering의 question-passage pairs,
(4) text classification이나 sequence tagging의 degenerate text-∅ pair
과 유사하다 -
아웃풋의 경우, token representations는 sequence tagging이나 question answering 같은 token-level tasks를 위해 output layer에 반영된다
-> [CLS] representation은 분류를 위해 output layer에 반영된다(entailment, sentiment analysis를 위해) -
pre-training에 비해 상대적으로 inexpensive
(A.3에 Fine-tuning procedure 관련 추가 설명)
4. Experiments
- 11개의 task에 대한 BERT의 fine-tuning 결과
4.1 GLUE
GLUE
: 자연어 이해 모델에서 범용적으로 사용되는 성능지표로, 인간의 언어 능력을 인공지능이 얼마나 따라왔는지 알아보고자 만들어졌다.
(GLUE 소개)
- General Language Understanding Evalutation
- GLUE benchmark는 다양한 NLP tasks의 collection이다
(GLUE fine-tune하기)
- 인풋 시퀀스(for single sentence or sentence pairs) represent함
- final hidden vector C를 첫 인풋 토큰([CLS])에 상응하도록 사용(aggregate representation으로서)
(실험 과정)
- fine-tuning 때 새롭게 제시된 파라미터
(W: classification layer weights, K: the number of labels) - standard classification loss를 C, W와 compute한다
- batch size(32), epoch(3)
- 각 task에 대해, Dev set에서의 best fine-tuning learning rate는 5e-5, 4e-5, 3e-5, 2e-5 사이였다
- BERTLARGE의 경우 작은 데이터셋에 대해 fine-tuning이 불안정한 경우가 있어, 랜덤하게 재시작을 했고 Dev set에서 최고 모델을 선정했다
(random restarts와 함께, same pre-trained checkpoint를 썼지만 다른 fine-tuning data shuffling과 classifier layer initialization을 수행했다)
(실험 결과)
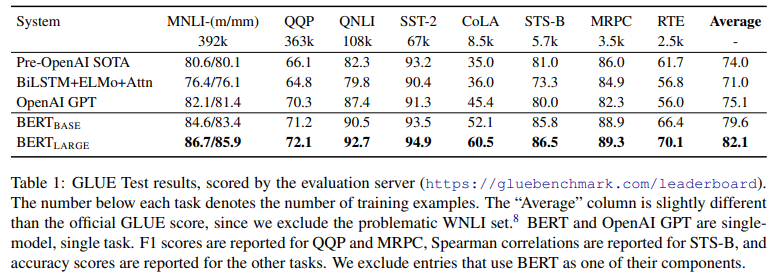
- BERTBASE와 BERTLARGE 둘다 모든 task의 systems에 대해서 outperform했다(이전 최고치에서 각각 평균 정확도가 4.5%, 7.0% 상승)
- BERTBASE와 OpenAI GPT는 모델 구조에서 거의 동일하다(attention masking과는 별개로)
- 가장 크고 자주 사용되는 GLUE task인 MNLI BERT는 절대적인 정확도 상승에서 4.6%를 얻었다.
- 공식적인 GLUE leaderboard에서 BERTlarge의 점수는 80.5이다(OpenAI GPT의 경우 72.8)
- BERTLARGE가 BERTBASE를 모든 task에서 능가했다(특히 적은 훈련 데이터를 가진 경우)
4.2 SQuAD v1.1
(SQuAD v1.1 소개)
- Stanford Question Answering Dataset
- 100k crowd sourced question/answer pairs의 collection이다
- 정답을 포함하고 있는 Wikipedia가 question과 passage를 주면, task는 passage에서 answer text span을 예측하는 것이다
(실험 과정)
- question answering task의 경우
-> 인풋 question과 passage를 single packed sequence로 represent했다
(question은 A embedding을, passage는 B embedding을 사용했다)
-> start vector S와 end vector E는 fine-tuning에만 썼다 - word i가 start of the answer span이 될 확률은 dot product로 계산된다(paragraph에서 모든 단어에 대해 소프트맥스 취한 Ti와 S 사이에서)

-> 유사한 공식이 answer span의 끝에서 쓰인다
-> candidate span의 score(position i부터 position j까지)는 S·Ti + E·Tj로 정의된다
-> maximum scoring span(j>=i)가 예측에서 쓰인다 - training objective는 정확한 시작과 끝 위치의 log-likelihoods의 합이다
- learning rate(5e-5), batchsize(32), epoch(3)으로 fine-tune했다
(실험 결과)
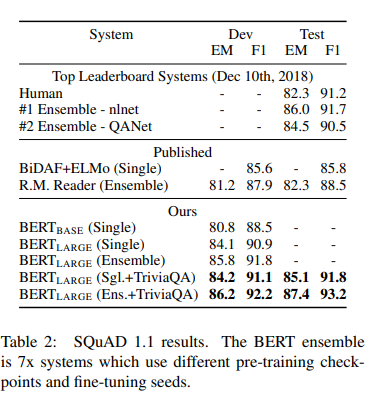
- top leaderboard entries와 top published systems로부터의 결과가 나와있다
- top leaderboard system에서 최고 결과는 +1.5 F1 in ensembling와 single system에서 +1.3 F1이다.
- single BERT는 F1 score에서 top ensemble system을 능가했다
- TriviaQA fine tuning data없이 0.1-0.4 F1를 잃었고 여전히 다른 이전 결과를 능가한다.
4.3 SQuAD v2.0
(SQuAD 2.0 task 소개)
- SQuAD 1.1을 extends한 것으로, possibility가 가능해진다(no short answer는 제공된 paragraph에서 존재하지 않는다)
(실험 과정)
- 정답이 없는 질문은 [CLS] 토큰에서 시작과 끝이 있는 정답 span을 가진 것으로 처리.
- start and end answer span positions of the [cls] token에 대한 probability space는 [cls] token의 position을 포함하고자 확장된다
- 예측을 위해 score of the no-answer span: snull=SC+EC를 score of the best non-null span sˆi,j = maxj≥iS·Ti + E·Tj 와 비교함.
- non null answer를 sˆi,j > snull + τ일 때, threshold τ가 dev set에서 F1을 최대화하고자 set되었을 때 선정함
- 이 모델에서는 TriviaQA data 사용X
- epoch(2), learning rate(5e-5), batch size(48)로 fine-tuned함
(실험 결과)

- 이전 최고 system보다 +5.1 F1 improvement임을 발견
4.4 SWAG
(SWAG 소개)
- Situations With Adversarial Generations
- 113k sentence-pair completion examples 포함(grounded commonsense inference를 평가한다)
- 문장이 주어졌을 때 task는 네 선택 중에 가장 plausible continuation을 뽑는 것이다
(실험 과정)
- 네 개 인풋 시퀀스 생성(각각은 주어진 sentence(sentence A)와 possible continuation(senetence B)에 대해 concatenation을 포함)
- task-specific parameters는 vector([CLS] token representation C와 dot product되며, 소프트맥스 레이어에 의해 normalized되는 각 선택에 대한 점수를 표시한다)
(실험 결과)

- epochs(3), learning rate(2e-5), batch size(16)으로 모델 fine-tune함
- BERTLARGE는 저자의 기본 ESLM+ELMo system을 +27.1%로, OpenAI GPT를 8.3%로 능가함.
5. Ablation studies
5.1 Effect of Pre-training Tasks
- BERT의 deep bidirectionality의 중요성 입증
-> 두 개의 pre-training objectives를 평가해서
(같은 pre-training data, fine-tuning scheme, hyperparameters를 BERTBASE로 사용)
No NSP
- masked LM(MLM)을 사용해 훈련되지만 next sentence prediction(NSP) task는 없는채로 되는 bidirectional model.
LTR & No NSP
- left-context-only model은 MLM보다는 standard Left-to-Right(LTR) LM으로 훈련
- left-only constraint는 fine-tuning에도 적용되었다
-> 그것을 제거하면 downstream performance를 degrade하는 pre-train/fine-tune 불일치가 일어나서 - NSP task 없이 pre-trained 되었다
-> OpenAI GPT와 직접적으로 비교된다
(실험 과정)

- NSP task로 인한 효과 연구
- NSP 제거하면 QNLI, MNLI, SQuAD 1.1에서 성능 저하
- training bidirectional representations의 효과 평가
- 'No NSP'를 'LTR & No NSP'와 비교해서 평가
- LTR이 MLM보다 모든 task에서 성능 나쁨(MRPC와 SQuAD에서 큰 하락)
- SQuAD의 경우
- LTR 모델이 token 예측에서 성능 나쁠 것임은 직관적으로 명백함
-> token-level hidden states가 right-side context가 없기 때문 - LTR system을 강화하고자, 랜덤하게 초기화된 BiLSTM을 top에 추가
-> SQuAD의 결과는 향상되었지만 다른 pre-trained bidirectional models보다 여전히 결과 나쁨
-> (결론적으로) BiLSTM은 GLUE tasks에서 결과에 해가 됨
- separate LTR과 RTL을 훈련하고 각 토큰을 두 모델의 concatenation으로서 represent하기(ELMo와 유사하게)
-> (하지만 다음의 한계점)
- single bidirectional model보다 두 배 비쌈
- QA 같은 task에 대해 non-intuitive
(RTL model이 질문에 대한 답변을 condition하는 것이 불가능해서) - deep bidirectional model보다 less powerful함
(모든 레이어에서 left, right context 둘 다를 쓸 수 있어서)
5.2 Effect of Model Size
- fine-tuning task accuracy에서의 model size의 효과 알아보자!
- BERT models를 레이어, hidden units, attention heads 수를 다르게 하면서 훈련, 같은 하이퍼파라미터 사용
GLUE task 실험 결과

- 5 random restarts of fine-tuning의 Dev Set accuracy 결과
- larger models는 네 dataset에 대해서 strict accuracy improvements를 보임
- BERTBASE는 110M parameters, BERTLARGE 340M parameters
실험 결과
- 모델 크기를 키우는 것이 large-scale task(machine translation, language modeling)에 continual improvements를 보일 것이라고 알려져왔다(이는 LM perplexity에 의해 입증된다)
-> extreme model sizes를 scaling하는 것이 매우 작은 scale task에서는 large improvements를 이끈다는 것을 입증하는 첫 번째 연구라 믿는다 - Peters et al.(2018b)는 downstream task에서 mixed results를 제시(pre-trained bi-LM size를 2에서 4 레이어로 상승)
- Melamud et al.(2016)은 hidden dimension size를 200에서 600으로 올리는 것이 도움됨을 언급
-> 두 연구 모두 feature-based approach 사용
5.3 Feature-based Approach with BERT
- 지금까지의 결과들은 fine-tuning approach이었음
feature-based 특징
- fixed features가 pre-trained model로부터 추출되어 특정한 이점을 가진다.
- 모든 task가 Transformer encoder architecture에 의해 represent되는 것은 아님
-> 그래서, task-specific model architecture가 포함되어야 함 - 주요한 계산 이점: 훈련 데이터의 expensive representation을 pre-compute 한 후, 그 representation 위에 cheaper models로 실험을 실행
실험 과정
-
BERT를 CoNLL-2003 Named Entity Recognition (NER) task, 두 접근법에 적용해서 비교
-
BERT의 input으로 case-preserving WordPiece model 사용하고 데이터에 의해 제공된 maximal document context를 포함함
-
standard practice를 따르면서 tagging task로 형성했지만 CRF layer를 output에서는 사용하지 않음
-
NER label set에서는 representation of the first sub-token을 iput to the token-level classifier으로 사용
-
fine-tuning approach를 없애고자 feature-based approach 사용
-> 이 때, activations를 BERT의 어떠한 파라미터도 fine-tuning하지 않은 채로 하나 또는 그 이상의 레이어에서 추출
-> 이런 contextual embeddings는 분류 레이어 전에 랜덤하게 초기화된 two-layer 768-dimensional BiLSTM에서 사용
실험 결과
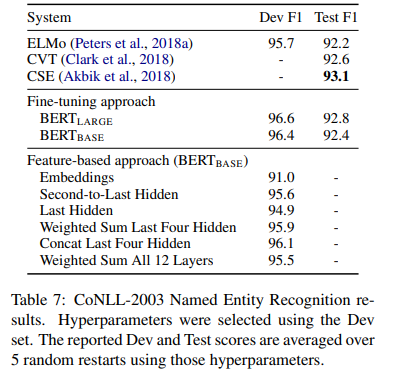
- BERTLARDE는 state-of-the-art와 비등비등함
- 최고의 방법은 token representations를 사전훈련된 Transoformer의 top four hidden layers로부터 concatenate함
- 결과적으로 BERT가 fine-tuning과 feature-based 모두에서 효과적임이 입증
6. Conclusion
- 언어 모델을 사용한 transfer learning(전이학습) 덕분에, 최근 empirical improvements는 풍부하고, unsupervised한 pre-training이 많은 language understanding system에서 효율적임을 보여왔다.
- 특히 이 결과들은 low-resource tasks까지도 deep unidirectional architectures로부터 좋은 결과를 얻는 것을 가능하게 해준다.
- 해당 논문은 이러한 결과들을 deep bidirectional architectures에 일반화하하여 동일한 pre-trained model이 광범위한 NLP 작업에 성공적으로 처리하도록 하는 것이다.
A. Additional Details for BERT
A.1 Illustration of the Pre-training Tasks
Masked LM과 마스킹 절차
-
예) unlabeled sentence "My dog is hairy"
-
random masking procedure로 4번째 토큰 hairy 된 경우
-> 80% of the time: 단어를 [MASK] token으로 교체해라, 예) my dog is hairy -> my dog is [MASK]
-> 10% of the time 단어를 random 단어로 교체해라, 예) my dog is hairy -> my dog is apple
-> 10% of the time: 단어를 바꾸지 않은채로 두자, 예) my dog is hairy
(이 과정을 하는 이유는 representation을 실제 관찰된 단어 쪽으로 편향하기 위함이다) -
해당 작업을 통해, Transformer encoder는 어떤 단어가 예측을 위해 물어볼지나 어떤 것이 랜덤 단어에 의해 교체되었는지를 몰라서, 각 인풋 토큰에 대해 distributed contextual representation을 유지하게 된다
-
추가적으로, random replacement가 모든 토큰에 대해 1.5%로 발생해서 이는 모델의 언어 이해 수용도를 해치지 않는 것으로 보인다.
-
standard language model training과 비교했을 때, masked LM은 각 배치에서 15% 토큰의 예측을 한다 -> 이는 더 많은 pre-training steps이 모델이 수렴하기 위해서 필요함을 제안한다.
-
MLM은 left-to-right model(every token을 예측)보다 marginally slower하게 converge한다(Section C.1에서 증명), 그러나 MLM 모델의 경험적 개선은 증가된 훈련 비용보다 훨씬 크다.
Next Sentence Prediction

절차 (책 '한국어 임베딩' 참고)
1. 학습 데이터는 1건당 문장 두 개로 구성
2. 절반은 동일한 문서에서 실제로 이어지는 문장을 두 개 뽑고, 정답으로 '참' 부여
3. 나머지 절반은 서로 다른 문서에서 문장 하나씩 뽑고, '거짓' 부여
A.2 Pre-training Procedure
(과정)
1. 각 training input sequence를 생성하고자 two spans of text를 corpus에서 샘플한다
(이는 single sentences보다 일반적으로 더 길지만 'sentences'로 불린다)
2. 첫 번째 문장은 A embedding을 받고, 두 번째는 B embedding을 받는다.
3. [NSP Task] 50%는 A를 따르는 actual next sentence이고, 50%는 랜덤 문장이다
4. [LM masking] WordPiece tokenization(uniform masking rate of 15%) 후에 LM masking 적용된다
(실험 과정)
- batch size(256 sequences), steps(1,000,000), epochs(40), 3.3 billion word corpus
- Adam: learning rate(1e-4), β1(0.9), β2(0.999), L2 weight decay(0.01), dropout(0.1)
- gelu activation 사용(relu 아니고, 이는 OpenAI GPT 반영한 것)
GELU: 정규분포의 누적분포함수로 RELU보다 0 주위에서 부드럽게 변화해 학습 성능을 높임
- training loss는 mean masked LM likelihood의 sum이고 next sentence prediction의 mean임.
- 긴 sequence는 disproportionately expensive함(attention이 sequence length에 이차이어서)
A.3 Fine-tuning Procedure
- 모델 하이퍼파라미터는 pre-training과 동일(배치사이즈, learning rate, 훈련 에폭 수 제외)
- dropout probability는 0.1로 유지
- 최적 하이퍼파라미터 값은 task-specific임
- 큰 데이터셋이 작은 데이터셋보다 하이퍼파라미터 선정에 less sensitive.
- Fine-tuning은 일반적으로 매우 빠름 -> 그래서 exhaustive search를 run하고 development set에서 최고를 수행하는 모델을 선정하는 것이 합리적임
A.4 Comparison of BERT, ELMo and OpenAI GPT
세 모델 비교
1. GPT: 단어 시퀀스를 왼->오 한 방향으로 봄
2. ELMo: Bi-LSTM 레이어의 상단은 양방향이지만 중간 레이어는 한 방향
3. BERT: 모든 레이어에서 양방향BERT와 GPT는 모두 트랜스포머 블록 사용
GPT가 양방향이 아닌 이유? '언어모델'이어서
GPT: 주어진 단어 시퀀스를 가지고 그 다음 단어를 예측하는 과정에서 학습(현재 입력 단어 이후의 단어를 모델에게 알려주는 것은 반칙)
BERT: GPT의 문제를 해결하고자 '마스크 언어 모델' 제안!(모델에 문장 전체가 주어져도 됨, 빈칸 채우는 것이 목적이므로)
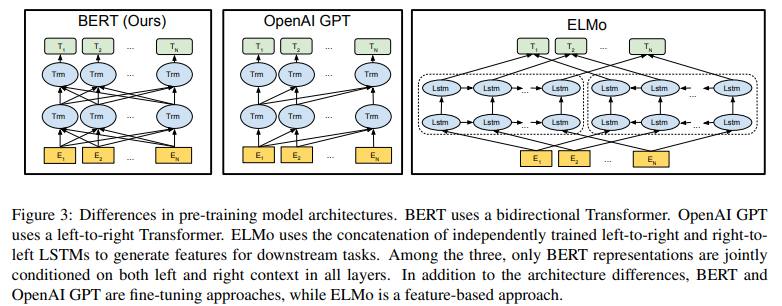
BERT, OpenAI GPT는 fine-tuning approaches 기반, ELMo는 feature-based approaches 기반
-
OpenAI GPT는 left-to-right Transformer LM을 large text corpus로 훈련
(사실 BERT는 GPT랑 유사하게 만들어졋다 둘 사이를 비교하려고) -
둘 사이의 훈련을 비교해보자
- GPT는 BooksCorpus(800M words)에서 훈련, BERT는 BooksCorpus(800M words)와 Wikipedia(2500M words)에서 훈련
- GPT는 fine-tuning time에만 소개되는 sentence seperator([SEP])와 classifier token([CLS]) 사용, BERT는 pre-trainig 동안에 [SEP], [CLS], sentence A/B embeddings를 학습
- GPT는 batch size 32,000 words인 1M steps로 학습, BERT는 batch size 128,000 words인 1M steps로 학습
- GPT는 모든 fine-tuning 실험에서 동일한 learning rate 5e-5 사용, BERT는 task-specific fine-tuning learning rate(development set에서 최고를 수행) 선택
- 이런 차별적인 효과를 분리하고자 ablation experiments를 진행
(대다수의 improvements는 사실 two pre-training tasks와 bidirectionality에서 왔음을 입증함)
A.5 Illustrations of Fine-tuning on Different Tasks

- task-specific models는 BERT를 one additional output layer와 통합시키면서 생성, 그래서 minimal number of parameters가 scratch로부터 학습되어야 함
- (a), (b)는 sequence-level task이고 (c), (d)는 token-level tasks임
- E: input embedding, Ti: token i의 contextual representation
([CLS]가 분류 아웃풋에서, [SEP]는 non-consecutive 토큰 시퀀스를 분리하는 symbol임)
B. Detailed Experimental Setup
B.1 Detailed Descriptions for the GLUE Benchmark Experiments
MNLI
- Multi-Genre Natural Language Inference
- large-scale, crowdsourced entailment 분류 task
- sentece pair가 주어지면, 목표는 두 번째 문장이 첫 문장에 대해서 entailment, contradiction, neutral인지 예측하는 것이다
QQP
- Quora Question Pairs
- 이항 분류 task
- 목표는 Quora에서 물어봐진 두 질문이 의미적으로 동등한지 보는 것이다
QNLI
- Question Natural Language Inference
- 이항 분류 task로 변환된 Stanford Question Answering Dataset의 한 버전이다
- positive examples(question, sentence)는 정확한 답을 포함하는 pairs이고, negative examples(question, sentence)는 정답을 포함하지 않는 같은 paragraph에서 얻는다
SST-2
- Stanford Sentiment Treebank
- binary single-sentence classification task
- movie reviews에서 추출된 문장들 포함
CoLA
- Corpus of Linguistic Acceptability
- binary single-sentence classification task
- 목표는 English sentence가 lingustically 'acceptable'인지 아닌지를 예측하는 것
STS-B
- Semantic Textual Similarity Benchmark
- sentence pairs의 collection(뉴스 헤드라인과 다른 sources에서 이끌어짐)
- score 1-5 사이로 annotate됨(semantic meaning에서 두 문장이 얼마나 유사한지를 표시함)
MRPC
- Microsoft Research Paraphrase Corpus
- 온라인 뉴스에서 자동으로 추출되는 sentence pairs로 구성
RTE
- Recognizing Textual Entailment
- binary entailment task임
- MNLI와 유사하지만 훈련 데이터가 훨씬 적음
WNLI
- Winograd NLI
- 작은 natural language infernece dataset
C. Additional Ablation Studies
C.1 Effect of Number of Training Steps
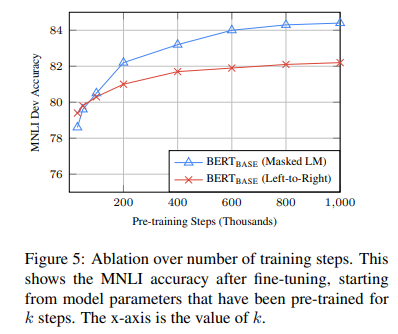
- MNLI Dev accuracy를 제시한다
- 해당 질문에 대한 답을 제시할 수 있게 된다
- Q. BERT는 high fine-tuning accuracy를 달성하기 위해서 많은 양의 pre-training이 필요한가?
A. 그렇다, BERTBASE는 1M steps로 훈련했을 때 500k steps보다 MNLI에서 거의 1.0% 정확도가 높았다. - Q. MLM pre-training은 LTR pre-training보다 더 느리게 수렴하는가?(15%의 단어만이 각 배치에서 예측되기 때문에)
A. MLM이 LTR보다 더 느리게 수렴하는 것은 맞지만, absolute accuracy에서 MLM이 LTR을 즉시 능가하기 시작한다.
C.2 Ablation for Different Masking Procedures
-
BERT는 mixed strategy를 쓴다(target token을 masking할 때, masked language model(MLM) objective로 사전훈련 될 때)
-
masking strategy의 목적은 pre-training과 fine-tuning 사이의 mismatch를 줄이기 위해서다
([MASK] symbol이 fine-tuning stage 동안에 절대 나타나지 않기 때문에) -
우리는 MNLI와 NER 둘 다에 대해 Dev results를 보고했다.
-
NER의 경우, fine-tuning과 feature-based 접근법 모두, 우리가 예상한대로 mismatch가 feature-based approach에 기반해서 증폭될 것이다, 모델이 representation을 조정할 기회가 없을 것이기 때문에
결과
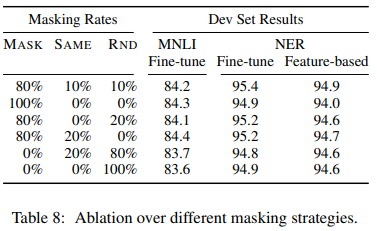
표 의미
- MASK: MLM을 위해 target token을 [MASK] symbol로 대체했음
- SAME: target token을 그냥 유지했음
- RND: target token을 다른 랜덤 token으로 교체했음
표 해석
- 왼쪽 부분은 MLM pre-training 동안에 사용된 특정한 전략의 확률을 나타낸다
(BERT는 80%, 10%, 10%를 썼다) - 오른쪽 부분은 Dev set results다.
- Feature-based approah의 경우, BERT의 마지막 4개 레이어를 features로 concatenate했다
- fine-tuning이 다른 masking 전략보다 더 강건하다
- 하지만 예상한대로, feature-based approach, NER의 경우 MASK strategy만을 사용하는 것은 문제다
- RND strategy만을 적용하면 다른 것보다 결과가 안좋다
