1. LSTM 등장 배경
- 기존 vanilla RNN은 Time interval이 큰 데이터에 대한 지식을 잘 저장하지 못한다
-> Error back flow(back propagation)과정이 정보를 충분히 전달하지 못해서 + 많은 레이어를 지나면서 weight가 손실되어서
-> 이를 해결하고자 LSTM 제안
1.1 RNN과 그 한계
- Recurrent: 이전에서 어떤 정보가 추가적으로 오는 것
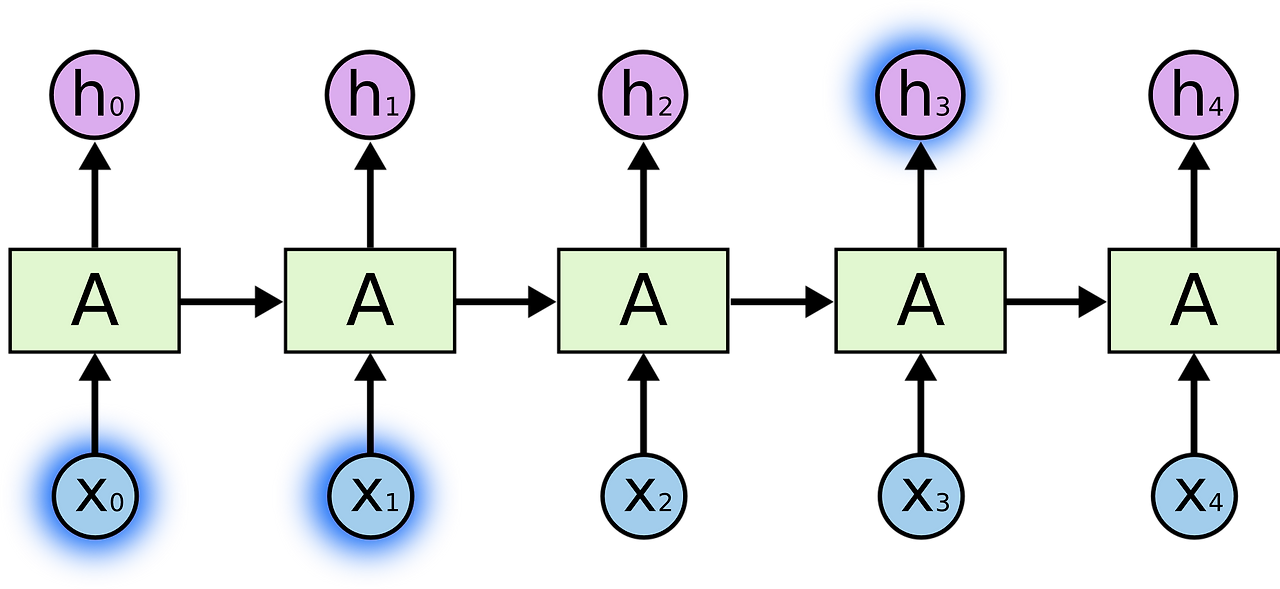
RNN

- 시간적으로 상관관계가 있는 데이터에서 주로 사용
- 스스로 반복하면서 이전 단계에서 얻은 정보가 지속되도록 함
- input xt를 받아서 ht로 내보냄
(A를 둘러싼 반복을 통해 다음 단계에서 network가 이전 단계의 정보를 받음을 알 수 있음) - [짧은 기간] 예) The clouds are in the sky. 'sky'를 예측하는 경우
- 직전 데이터(t-1)과 현재 데이터(t) 간의 상관관계를 고려해, 다음 데이터(t+1)을 예측하고자 함
- 그런데, 시간을 많이 거슬러 올라갈 수록 경사 소실 문제가 발생
(초기값에 따라서 과거 데이터를 계속 곱하면 작아지는 문제)
Vanilla RNN
- 이전 정보(xt-1)와 현재 정보(xt)를 취합(tanh)한 정보를 신경망에 넣어 아웃풋(ht) 만듦
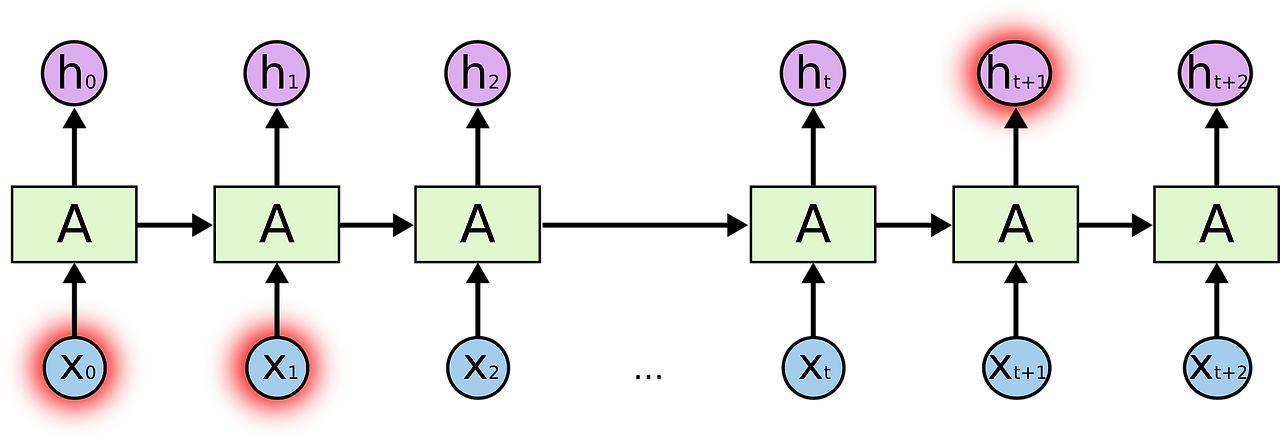
- 장기 의존성 문제: 직전 정보 뿐 아니라, 그 전 정보를 고려해야 하는 경우(longer term) 多
- [긴 기간] 예) I grew up in France... I speak fluent French. 'French'를 예측하는 경우
- 시퀀스가 있는 문장에서 문장 간의 간격이 커질 수록, 두 정보 맥락 파악이 어려워짐
- 이 전 데이터도 함께 고려해 출력을 만들자 : LSTM의 등장 배경
RNN의 반복 모듈
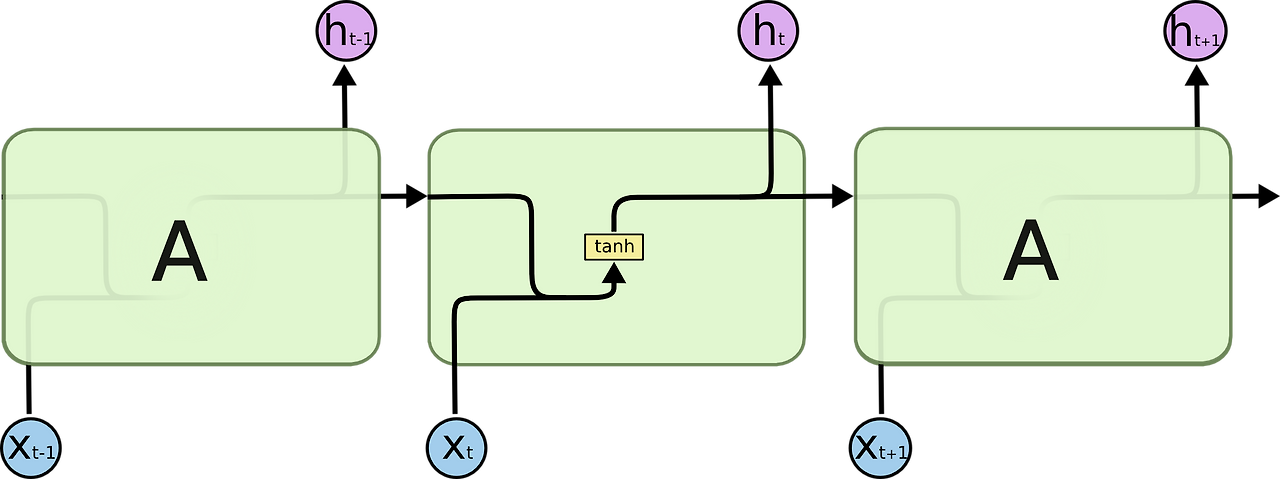
- RNN은 neural network 모듈을 반복시키는 체인 형태
- RNN의 반복 모듈이 tanh layer(하나의 layer)를 갖는 표준적인 모습(예시 사진)
(LSTM의 경우 4개의 layer가 특별한 방식으로 서로 정보를 주고 받음)
2. LSTM
2.1 LSTM의 구조
- 직전 데이터 뿐만 아니라, 더 과거의 데이터까지도 고려해, 미래 데이터를 예측하자
- Input(xt)
- Cell state: 새로운 Flow 도입, 컨베이어 벨트처럼, 이전에 입력됐던 정보들을 전달해줌
- Hidden state: 이전 출력(previous output)
- Forget Gate: 이전 Cell에서 넘어온 hidden state에 대해서, 과거의 정보 중 어느 것을 Cell state에 반영할 것인지 결정
- Input Gate: 현재 입력된 정보를 얼마나 Cell state에 반영할 것인지를 결정
- Output Gate: 다음 Cell에 전달할 hidden state 값에 Cell state를 얼마나 반영할 것인지를 결정
- Output(ht): output state는 다음 hidden state와 항상 동일


- Neural Network layer: weight, bias 둘 다 포함
- Pointwise Operation: 각 차원에 맞게 곱하거나 더해주는 연산
2.2 LSTM의 핵심 아이디어
Cell state
- 모듈 그림에서 수평으로 그어진 윗 선
- 컨베이어 벨트 같이, 작은 linear interaction만을 적용시키면서 전체 체인을 구동시킴
- cell state에서 추가하거나 삭제하는 능력은 gate에 의해서 제어 됨

Gate
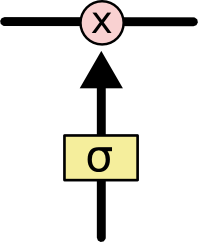
- 정보가 전달될 수 있는 추가적인 방법
- sigmoid layer와 pointwise 곱셈으로 이루어짐
- sigmoid layer는 0~1 사이의 숫자를 출력
-> 각 컴포넌트가 얼마나 정보를 전달해야 하는가에 대한 척도
(0이면 아무 것도 넘기지 말라, 1이면 모든 것을 넘겨라)
2.3 Gates 과정(Forget, Input, Output)
- 세 게이트는 정보들을 어느 시점에서 버리거나, 유지해 선택적으로 흘러가게 할 것인가를 결정
[Step1] Forget Gate: 과거 정보 삭제 여부 결정
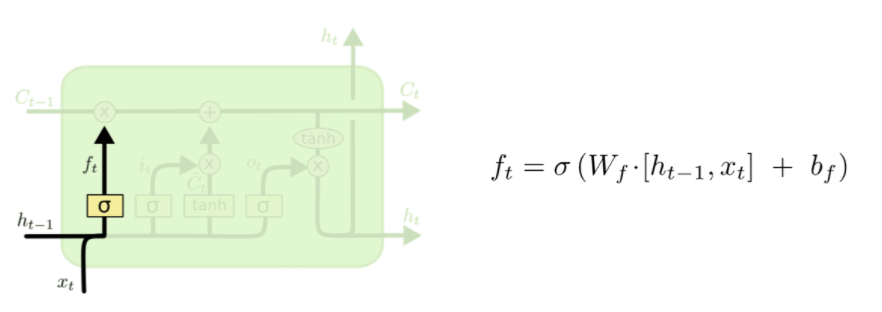
- Decide what information we’re going to throw away from the cell state.
- 과거에서 넘어온 정보 중, 어떤 정보를 버릴지 결정
- 이전 output(ht-1)과 현재 input(xt)를 받아 0~1 사이의 값을 cell sate(Ct-1)에 보냄
- 활성함수로, sigmoid를 사용해 얻은 0~1 사이의 가중치를 곱해, 학습하면서 상대적으로 중요한 정보에는 높은 가중치를 부여하고 좋지 않은 영향 끼치는 정보에는 낮은 가중치를 부여함
- Neural Network를 학습하면서 얻은 W_f(Weight of Forget Gate), B_f(Bias of Forget Gate)를 기반으로,
-> 0에 가까운 값이면 정보를 버리는 효과,
-> 0이면 삭제,
-> 1에 가까운 값으면 정보 보존,
-> 1이면 데이터를 그대로 전달하는 역할을 해,
Cell을 지나면서도 유의미한 정보를 계속해서 Cell state Flow에 보존하도록 함
현재 입력과 이전 출력을 고려해 cell state의 어떤 값을 지워버릴지(0 출력시 지움) 결정
[Step2] Input Gate: 현재 정보 저장 여부 결정
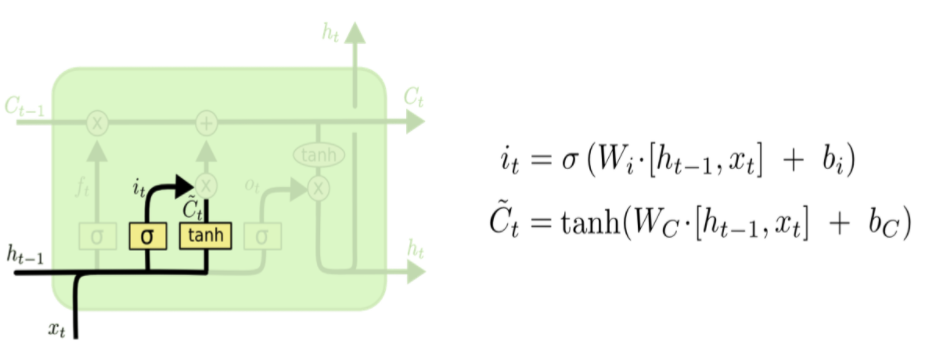
- Decide what new information we’re going to store in the cell state.
- 새로운 정보 중 어떤 것을 현재 cell state에 저장할 지 결정(tanh에서 -1~1 사이의 값을 얻음)
- 현재의 입력값(xt)와 이전 hidden state(ht-1)를 이용해, 현재 cell의 local state를 얻고, 이를 global cell state에 얼마나 반영할지 결정하는 게이트
- sigmoid 함수를 이용해, 현재 시점에서 얻은 정보가 큰 효용가치가 있으면, cell state에 많이 반영하고, 별로 의미가 없는 경우 0에 가까운 가중치를 부여해 반영을 최소화함
- input gate layer인 sigmoid layer가 어떤 값을 업데이트 할지 결정(it)
- tanh layer가 새로운 후보 값들인 ~Ct 벡터를 만들고, cell state에 더할 준비를 함(~ct)
- 1-2 단계에서 나온 정보를 합쳐 state에 업데이트 할 재료 만듦
현재의 입력과 이전 출력으로 얻은 값을 얼마나 cell state에 반영할지 결정
[Step3] update(cell state)
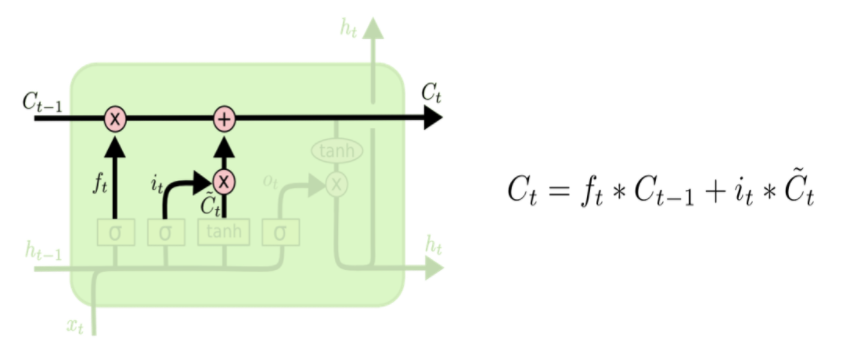
-
Update, scaled by now much we decide to update
-
과거 hidden state에서 forget이 이루어진 cell state와, 현재 cell에서 얻을 수 있는 새로운 데이터를 반영한 cell state를 더해, update한다
-> forget x previous state + input gate x current state -
과거 state인 Ct-1를 업데이트해, 새로운 cell state인 Ct 만들기
- 이전 state에 ft를 곱해, 잊기로 했던 것을 잊는다
- 얼마나 업데이트할지 정한 만큼 값을 scale한다(it*~Ct)
- 1과 2를 더한다
과거 cell state(ct-1)를 새로운 state(ct)로 업데이트 하는 과정
[Step4] Output Gate: 출력값 결정
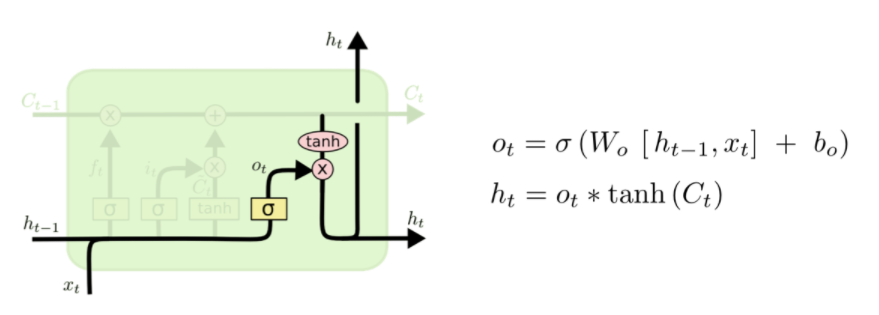
- Output based on the updated state.
- 무엇을 output으로 내보낼 지 결정
- 최종적으로 얻어진 cell state 값에서 어느정도를 취해 hidden state로 전달할 것인지 결정
-> output gate * updated state - 여기서 최종적으로 얻은 ht를 바탕으로 다음 셀에서 Ct+1을 구함
- sigmoid layer에 input 데이터를 가져와 cell state의 어느 부분을 output으로 내보낼지 결정
- cell state를 tanh layer에 적용한 후(-1~1 사이의 값), sigmoid gate의 output과 곱하기
3. Conclusion
- Vanilla RNN의 문제인, Long-term dependencies를 해결하고자 LSTM 제안
- LSTM은 cell state를 통해, 과거의 데이터를 유지하면서, 불필요한 데이터는 Forget Gate로 삭제해 Gradient Update에 최적의 상태를 유지
- 이를 통해 정확도 상승 및 Long time lack task의 경우, 기존 RNN이 해결하지 못한 문제들을 해결할 수 있었음
