1 Introduction
Background
- 시간이 지남에 따라 lexical meaning(사전적 의미)이 바뀌는 단어를 알아차리는 것은 NLP에서 주요한 연구 분야임
- 언어의 발전으로 'semantic change detection' task는 시간에 대해서 cultural evolution에 유용한 인사이트를 제공하는 것이 가능해짐
- lingustic 변화를 측정하는 것은 1) 온라인 커뮤니티의 역동성을 이해하는 것과 2) 개인의 evolution에도 관련이 있음.
- 최근 이 분야에서 연구자들은 디지털 형태의 historical corpora를 활용해서 시간에 따른 단어의 변화를 탐지하는 모델을 활용하는 것이 가능해짐(이는 급격한 변화임)
- lingustic shift: changes in the patterns, structures, and usage of language over time
- Human language changes over time. This change occurs on several linguistic levels such as grammar, sound or meaning. The study of meaning changes on the word level is often called Lexical Semantic Change (LSC)
기존 연구 한계점
- 하지만 여전히 두 가지 문제가 있음
- 1 모델 비교에 대한 literature 관련 연구가 적음
- 라벨링된 longitudinal 데이터의 부족으로 -> 이전 연구들은 모델 성능을 qualitative한 방법으로 평가(quantitative한 비교 없이)
- 그러므로 어떤 것이 semantic change detection에 대한 적절한 접근법을 구성하는지를 평가하는 것이 어려워짐
- 2 방법론적 관점에서 관련 연구의 large body는 semantically shifted words를 고유한 시간에서 representation을 공정한 비교를 통해서 pairwise로 탐지
- task의 sequential modeling 부분은 무시하면서(기존 연구의 문제점)
- semantic change가 time-sensitive한 과정이기에 시간을 나타내는 consecutive vector를 고려하는 것은 모델 성능을 향상하는데 중요할 수 있음
- 1 모델 비교에 대한 literature 관련 연구가 적음
- longitudinal 데이터: data collected over time from the same individuals or entities.
본 연구의 해결책
- semantic change detection을 anomaly identification task로 접근하여 두 챌린지를 해결
- 영어 단어의 embedding representations에서 작업해서,
- encoder-decoder 아키텍처를 통해 evolution을 time 별로 학습
- 이 때 다음을 가정
- 모델이 temporally sensitive sequences of word representations에서 잘 훈련되면,
- 그것은 시간에 걸쳐 어떠한 semantic rerpresentation의 evolution도 잘 예측할 것
- semantic chagne를 겪은 단어들은 예측 모델에서 highest errors를 가져온 애들일 것임
semantic change detection을 어떻게 anomaly identification task로 접근한거지..
- semantic change detection focuses on identifying words or phrases that have undergone significant shifts in meaning compared to their historical or expected usage.
Contribution
- LSTM 기반 아키텍처에서 3가지 변형을 개발
- 단어의 semantic change의 level을 측정하기 위해서
- sequential한 방법으로 time 별로 evolution을 tracking함
- (a) word representation autoencoder,
- (b) future word representation decoder
- (c) (a), (b)를 결합한 하이브리드한 방법
- synthetic data에서 실험해서 모델의 효율성 입증
- 실제 데이터를 사용해서 베이스라인에서 경쟁력을 비교
- 성능 향상을 입증
- 시간 별로의 word vectors의 sequential modelling의 중요성을 강조함
- 코드 공개
2 Related Work
semantic change detection 관련해서는 두 가지 방법이 있음
1 시간에 따라서 jointly하게 word representations 학습
2 word representations를 discrete한 시간 간격(bins)에 대해서 학습하고 결과 vector를 비교
-> 두 방법 모두 다양한 접근방식에서 생성 가능(topic, graph, 뉴럴기반모델(word2vec))
- 본 연구에서는 매우 큰 말뭉치에서 diachronic(통시적) representations를 학습할 때의 scalability issues 때문에 2) 방식 사용
- generality의 loss 없이
- pre-trained, neural-based representations를 이용
- word representations: the process of representing words as numerical vectors or embeddings.
- disachronic representations: word representations that capture the temporal or historical aspects of language.
- 2) 관련 연구들의 word representations은 ( ∈ )에서 유래
- time intervals에 걸친
- 의 다양한 값에 대해서 쌍 별 비교 수행
- 이전 연구들은 frequency나 co-occurrence 기반의 방법 사용
- 하지만 word2vec-based representations를 활용하는 것이 최근에 당연한 일이 되어버림
- word2vec이 가진 확률론적 본성 때문에,
- Orthogonal Procrustes (OP)가 resulting vectors에 자주 적용
- pairwise representations를 aligning하는 것을 목표로 하면서
- 두 개의 word matrices , 가 times k와 j 때 각각 주어지면
- OP는 최적의 transformation 행렬인 1) R = argmin ||Ω − |와 2) word 의 semantic shift level을 찾음
- 이 때에, time interval은 두 배열된 행렬의 cosine distance로 정의
- linear pairwise fashion을 활용하는 과정에서 -> 이런 방법들은 time-sensitive를 무시하고, -> semantic change가 비선형적인 특성을 가지게 됨(?)
- 하지만 word2vec-based representations를 활용하는 것이 최근에 당연한 일이 되어버림
- word2vec: that learns continuous vector representations, also known as word embeddings, from large amounts of text data. It aims to capture the semantic relationships between words by considering their contextual usage.
The underlying idea of Word2Vec is that words appearing in similar contexts often have similar meanings. It operates on the assumption that words with similar meanings tend to occur in similar contexts or are surrounded by similar sets of words.- Orthogonal Procrustes (OP): 선형 대수학과 다변량 분석에서 두 개의 벡터 집합을 정렬하거나 비교하는 문제를 해결하는 수학적인 기법
- pairwise representations를 aligning하는 것: the process of establishing correspondences or mappings between two sets of representations. It involves finding a consistent alignment between the elements in each set, typically based on their similarity or relatedness.
-
이와 달리 몇 연구는 의미론적으로 변화된 단어들을 탐지하고자,
- 단어 level의 time series를 사용함(semantic change에 있어)
- 이 방법이 temporal modelling을 포함하지만,
- linear transformation 에 너무 의존하고
- temporally-sensitive representation의 생성에 원초적으로 초점을 둠
- semantic chagne의 의미를 포착하는데 있어
-
본 연구의 주요한 contribution은
- pre-defined transformations에 method가 기초를 두지 않은 것
- 그 대신, pre-trained word representations가 시간에 따라서 어떻게 다르게 학습하는지 제시
- 단어의 evolution의 full sequence를 이용하면서
-
semantic change detection 모델의 comparative한 evaluation은 여전히 초창기임
- 대다수의 관련 연구들은
- artificial task에 의존해서 모델 성능을 평가하거나,
- 몇 개의 hand-picked examples에서(cross-model 비교 없이)
- 최근에 소개된 shared task인 SemEval Task1과 DIACR-Ita는 이 격차를 이어주는데 초점
- 하지만 각 데이터셋은 두 개의 고유한 시간으로 나누어지는 문서로 구성
- 그렇기에 semantic change의 sequential nature의 연구를 이용하지 않음
- 하지만 각 데이터셋은 두 개의 고유한 시간으로 나누어지는 문서로 구성
- 대다수의 관련 연구들은
-
해당 분야의 경우 1) 실제 데이터와 2) sequential word representation에 대한 model 비교를 위한 benchmark 설정이 중요
3 Methods
- 본 연구에서 semantic change detection은 anomaly detection task임
- pre-trained word embeddings에서의 evolution인
- pre-trained word vectors( ∈ [, ..., ])를 가정
- 다음에서 가정: ∈
- : vocabulary size
- : word represention size
- historical corpus에서 time periods에 대해서
- non-linear function 로 evolve하면서
- 를 근사하는 과정에서 단어 의 semantic shift의 time 에 대해서 level을 얻음
- word representation 를 에 대해서 유사도를 측정하면서
- 주어진 단어의 낮은 유사도 점수는
- 부정확한 모델 예측(anomaly)를 암시 -> semantic change의 level이 높음
- 그러므로 semantic shift level에 기반해서 단어의 ranking을 얻을 수 있음
- 와 사이의 유사도를 ascending 한 순서로 나열해서
- 를 temporally sensitive deep neural model에 대해서 approximate함
- (a) autoencoder
- 시간 에서 주어진 지점까지 단어의 trajectory를 reconstruct하는 것이 목표
- (b) future predictor
- 단어 의 future representions를 예측하는 것이 목표
- 두 모델은 각각 훈련되거나, (c) joint multi-task setting에서 훈련될 수 있음
- 해당 모델들은 time 에 대해서 sequential word represenations를 accounting할 때 이점을 얻음
- 이는 semantically shifted words를 탐지하는데 더 잘 적합되어 있음
- 첫번째와 마지막 것() 만을 비교하는 흔한 방법과 비교했을 때
- 이는 semantically shifted words를 탐지하는데 더 잘 적합되어 있음
- (a) autoencoder
- 다음에서 가정: ∈
시간을 보는게 앞뒤 끝에만 보는 것보다 좋다는 말..인것같은데
3.1 Reconstructing Word Representations
- 사전에서 단어를 나타내는 input sequence의 vectors가 시간 의 points에 대해서 주어지면
- autoencoder의 목표는 input sequence인 을 reconstruct하는 것
- semantic change task가 natural temporal dimension을 포함하기에
- 연구에서는, autoencoder를 RNN을 통해서 모델링함(Fig1)
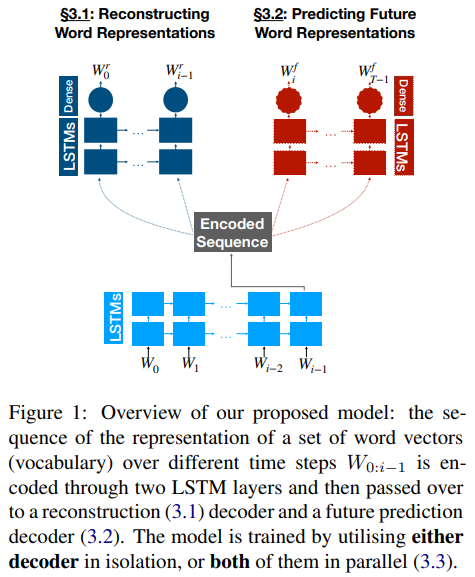
- Fig1 해석
- 제시 모델의 전체 그림
- 다양한 시간 순서에 대해서 단어 벡터(사전)의 set을 나타내는 sequence는 두 LSTM 레이어에 인코딩되고 reconstruction(3.1) 디코더와 future prediction decoder(3.2)에 통과됨
- 모델은 각 디코더를 독립적으로나 혹은 평행하게 함께 이용해서 훈련됨
- 인코더는 two LSTM layers로 구성
- outputs에서 작동하는 dropout layers 없이(regularisation을 위해서)
- 첫번째 레이어는 의 input sequence를 encodes하고, hidden states를 두 번째 레이어에 input으로서 보냄
- 두번째 레이어의 아웃풋은 final encoded state임
- 이는 times copied되며 decoder에 input으로서 넣어짐
- 디코더도 거의 같은 구조임
- 두번째 LSTM layer의 꼭대기에 추가 dense layers가 있음
- final reconstruction 을 time번 만들고자
- 두번째 LSTM layer의 꼭대기에 추가 dense layers가 있음
- 모델은 MSE loss function을 최소화하면서 훈련
- 훈련 후에, test set에서 highest error rates를 가져오는 단어들은 -> 주어진 시간 동안에 semantic이 많이 바뀐 애들임
- 이는 word alignment에 기반을 둔 이전 연구와 호환됨
- 단어의 alignment error가 그것의 semantic change의 level을 나타내는
3.2 Predicting Future Word Representations
- word vectors를 reconstructing하는 것은 어떤 단어가 과거(time i-1까지)에 semantic을 바꾸었는지를 알 수 있음
- 만약 future word representation에서 semantic의 변화(time i-1 이후)를 예측하는데 관심이 있다면
- future word representation prediction task를 고려할 수 있음
- past word represenation의 sequece( = [, , ..., ])가 첫번째 time points에 대해서 주어지면,
- 사전 =[, , ..., ]에서 단어의 future representations를 예측함
- overall length |T|의 sequence에 대해서(Fig1)
- 사전 =[, , ..., ]에서 단어의 future representations를 예측함
- past word represenation의 sequece( = [, , ..., ])가 첫번째 time points에 대해서 주어지면,
- future word representation prediction task를 고려할 수 있음
- #3.1에서와 같은 모델 구조를 따름
- 유일한 차이는 time steps(T-i)의 숫자가 |T-i| prediction을 만들기 위해서 decoder에서 쓰인다는 것
- 모델은 다음 loss function으로 훈련
3.3 Joint Model
- 두 모델은 하나로 결합 가능
- 시간에 대해서 points로 vocabulary 의 input sequence of representations가 주어지면
- 목표는 둘 다
- (a) 인풋 시퀀스를 reconstruct 하기
- (b) future word 의 representations 예측
- 완전한 모델 구조는 Fig1에 제시
- 인코더는 #3.1, #3.2에서 쓰인 것과 동일
- 하지만 장애물은 new copied times로 이는
- reconstruction(times)과 future prediction에 ( times)에 decoder로서 통과됨
- loss function 는 Eq1과 2의 individual loss의 요약
- 이런 multi-task setting에서 semantic chagne를 modelling하는데 두 가지 주요 이유가 있음
- 1 두 디코더의 finer granularity에서 이점을 얻음
- individual task model에서보다
- 더 fine-grained한 방법으로 sequence의 only part를 다루면서
- 2 joint model은 Eq3에 있는 의 값보다 더 둔감함
- Eq1, Eq2 보다 상대적으로(뒤에서 더 다룰 예정)
- 1 두 디코더의 finer granularity에서 이점을 얻음
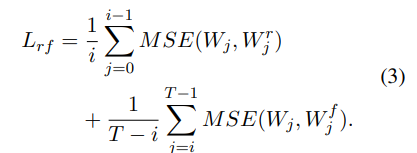
MSE: 오차를 제곱한 값의 평균(작을 수록 성능이 높음)
3.4 Model Equivalence
- 세 모델은 다른 수행을 함
- 하지만 operational time periods를 Eq 1-3에서처럼 적절하게 설정하면 결과가 model equivalence 할 수 있음(같은 task를 수행할 때)
- 구체적으로 때 semantic이 바뀐 단어들을 탐지하기 위해서
- autoencoder(Eq 1)는 fed되어야 하고 에 대해서 full sequence를 재구성해야 함(즉, i=T-1)
- 해당 간격을 줄이는 것은(i를 줄이는 것) operational time period에 limit를 줄 수 있음
- 반면에 future prediction model의 Eq2에서의 i 값의 상승은 time period를 줄이는데
- 그동안에 semantics가 가장 많이 바뀐 단어들을 탐지할 수 있음
- full sequence [1, T-1]에서 semantics가 바뀐 단어들을 찾으려면
- 첫번째 interval에서의 word represenations인 W0를 필요로 함
- 그러므로 파라미터 i를 설정하는 것은 개인 모델의 성능에 중요
- 대조로 #3.3의 joint model은 i 값에 상관없이(Eq3) semantic change를 경험한 단어들을 탐지하는 것이 가능
- 여전히 full sequence에서 작동하는 것이 가능해서
- 이런 효과들 #5.2에서 보일 예정
- 여전히 full sequence에서 작동하는 것이 가능해서
4 Experiments with Synthetic Data
- artificial data에서 쓰이는 task들이 관련 연구에서 evaluation을 목적으로 쓰임
- #4에서는 artificial data를 제시하는 모델의 proof-of-concept로서 사용
- SOTA와 다른 베이스라인과 비교(실제 데이터에서의) -> 다음 섹션
- 여기서는 word representations(4.1)의 longitudinal dataset을 이용
- 시간에 따라서(4.2) small set of words를 artificially하게 바꿈
- 모델을 훈련(4.3), 평가해서
- 그들의 ability에 기반해서 -> (artificial) semantic change를 경험한 단어들을 찾고자 함
4.1 Dataset
- UK Web Archive dataset 이용
- 47.8K 단어에 대해서 100차원 -> 2000-2013년도 각 년도에 대해서 있음
- 각 연도에 출판된 문서에 대해서 독립적으로 word2vec sampling 사용해서 얻음(negative sampling을 사용한 skip gram)
- 본 모델은 어떠한 유형의 pre-trained 임베딩에 적용 가능
- 각 연도는 모델링에서의 time step에 상응함
- 데이터는 65개의 단어 포함
- 단어의 뜻은 2001-13 사이에 바뀜 -> 이는 Oxford English Dictionary에 명시
- 이들은 해당 섹션에서는 일부러 삭제함
- artificial data modeling에서 interference를 피하고자
- longitudinal word representation의 80%를 모델 훈련에 쓰고 나머지를 evaluation에 씀
4.2 Artificial Examples of Semantic Change
- changing semantics에 따라 artificial examples를 생성
- Rosenfeld and Erk (2018)의 패러다임 따르면서
- semantics를 바꾸고자 랜덤하게 test set 단어의 5%를 획일적으로 사용(-> 일부러 바꾼건가?????)
- 각각의 선정된 'source' word에 대해서
- 'target' word β를 뽑음( β를 뽑은 과정은 다음에 설명)
- source word α의 representation 를 각 시간 t에 대해서 바꿈
- target word가 time에서 representation 에 대해서 shift할 수 있도록
- target word가 time에서 representation 에 대해서 shift할 수 있도록
- Rosenfeld and Erk (2018)를 따라서 를 sigmoid function으로 model함
- 는 [0,1] 안의 값을 받고,
- decay function으로서 작동
- source word의 semantics의 속도의 변화를 target에 대해서 통제함
- 그러므로 semantic representation α는 첫번째 시간 지점 때 바뀌지 않으며, representation of β(t의 중간값)로 서서히 shift 함
- 그 지점에서 last time points로 stabilize함
- 단어의 semantic shift의 duration이 다를 수 있기에, 다양한 시나리오에서 실험("Conditioning on Duration of Change" 참고)
- artificial semantic change의 alternative modelling approaches는 Shoemark et al. (2019)에서 제시
- 예) 단어가 새로운 sense를 얻도록 강요하는 동안에 그것의 원본 뜻을 유지할 수 있도록
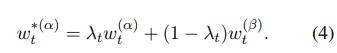
- 논문에서는 semantic shift(Eq4)의 "stronger shift"의 경우를 작용함 -> 모델의 proof-of-concept로서
- artificial semantic change의 alternative modelling approaches는 Shoemark et al. (2019)에서 제시
- 각각의 선정된 'source' word에 대해서
- #5에서 real-world data로 실험
- semantic change 때 있는 어떠한 형태의 가정 없이
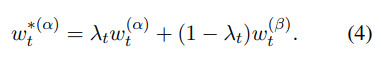
Conditioning on Target Words
- target words를 선정하는 것은 -> 그들이 source word의 representation이 시간이 지남에 따라 바뀌는 것을 허용하는가 임
- 이는 만약 {α, β}{source, target} words를 선정한다면 case가 아닐 것임
- 이 때 representations는 매우 유사함(예. synonyms)
- 그러므로 각 source word α에 대해서
- target word β를 random하게 선택함
- 그들의 첫 시간에서의 representation의 코사인 유사도는 certain range (c-0.1, c]로 떨어짐
- c 값이 높다는 것은 α에 대해서 시간 동안 lower semantic change level을 강요함
- 그것의 representation이 similar word β에 대해서 반대로 shifted할 것이기 때문
- target word β를 random하게 선택함
- model performance를 semantic change의 다양한 수준에서 평가하기 위해서 -> c 값을 다르게 하는 시도 진행
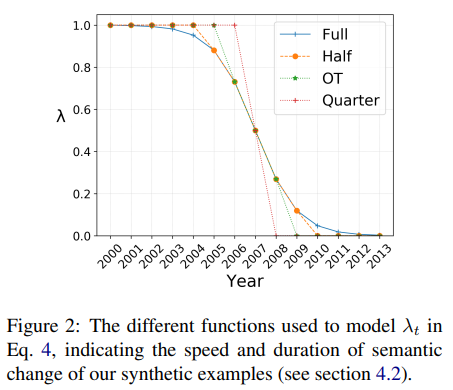
Conditioning on Duration of Change
- semantic change의 duration은 Eq4에서 의 값에 영향을 줌
- 관습적으로 = 0.5로 설정
- 2007년도의 source word a의 artificial word representation 는 0.5( + )과 동일
- 4가지 다른 [시작, 끝] 범위로 실험
- (a) "Full" [2001-13]
- (b) "Half [2005-10]
- (c) "OT" (One-Third) [2006-09]
- (d) "Quarter" [2007-08]
- semantic change duration이 길다는 것은 단어 α의 단어 β의 뜻에 대한 smoother transition을 암시(반대 또한)
4.3 Artificial Data Experiment
- task는 test set에 있는 단어들을 semantic change의 level의 means로 rank하는 것
- 먼저 세 모델을 training set에서 훈련하고 test set에 적용
- 마침내 단어의 semantic change의 level을
- 디코더의 각 타임 스텝에 대해서 예측과 실제 값 사이의 코사인 유사도의 평균을 구함
- 모델 성능은 rank-based metrics로 평가
Model Training
- seq2seqr: autoencoder(#3.1)는 training set의 word representations의 전체 시퀀스를 받고 재구성함
- [W00, ..., W13] → [Wr00, ..., Wr13].
- seq2seqf: future prediction model(#3.2)은 2000년의 training set의 representation을 받고 sequence의 나머지를 예측하고자 학습함
- [W00] → [Wf01, ..., Wf13]
- seq2seqrf : multi-task model(#3.3)은 training set에서 word representations의 sequence word의 첫 절반으로 fed되고, 결합하면서 학습
- (a) 인풋 시퀀스를 reconstruct
- (b) future의 word representations를 예측
- [W00, ..., W06] → {[Wr00, ..., Wr06], [Wf07, ..., Wf13]}.
- 인풋에서 seq2seqr과 seq2seqf의 timesteps는 다른 수를 가짐
- 그래서 각 모델에서의 디코더가 가능한 최대의 output sequence에서 작동하도록
- 전체 시간에 대해서 단어의 semantic change를 이용하면서
- 그래서 각 모델에서의 디코더가 가능한 최대의 output sequence에서 작동하도록
- seq2seqrf는 input time steps의 수에 덜 민감하다고 기대됨
- 그래서 관습적으로 그것을 전체 시퀀스의 반으로 설정
- 훈련 셋의 25%는 validation을 목적으로 두고, Adam 옵티마이저 사용
- Tree of Parzen Estimators algorithm 사용해서 25번 시도후에 최고의 파라미터 얻음
- by means of the maximum average (i.e., per time step) cosine similarity in the validation set
Testing and Evaluation
- 훈련 후에 각 모델은 test set에 적용됨 -> 각 단어에 대해서 시간 당 결과를 내보냄
- 단어의 semantic change의 level은 average cosine similarity를 통해 계산됨
- 시간 별로 actual과 predicted word representations에 대해서
- 높은 값은 더 나은 모델 예측을 암시함(즉, semantic change의 level이 낮다)
- words는 average cosine similarity의 오름차순 순서로 rank됨
- 첫번째 rank는 representations가 가장 많이(낮은 코사인 유사도) 바뀐 단어들을 암시함
- evalutation의 경우 average rank를 모든 semantically changed words(µr)에 대해서 이용
- lower scores는 더 나은 모델을 암시
- µr를 mean reciprocal rank에 대해서 선호함
- 후자가 first rankings를 강조해서
- semantic change detection이 quantitative terms에서 under-explored task이기에 모델 성능을 averaging metric을 이용해서 더 좋은 결과를 얻는 것을 목표로 함
- 같은 이유로 classification-based metric을 피함(cut-off point에 기반을 둔)
- 실제 데이터와 함께 cross-model comparison에서 그러한 metric을 사용함
4.4 Results
Model Comparison
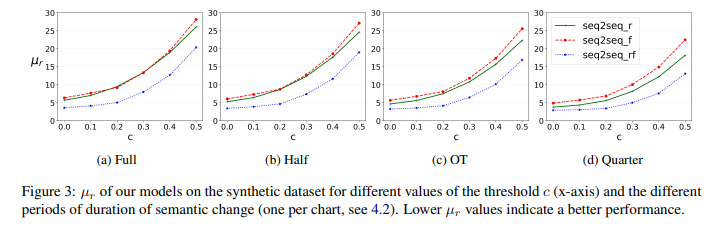
- Fig3: synthetic data에서 세 모델의 결과 모든 (c,λ) combinations에 대한
- seq2seqrf가 개별(seq2seq, seq2seqf)보다 지속적으로 좋음
- multi-task 환경에서 두 모델을 결합하는 것이 joint와 finer-grained parameter tuning에 이점을 줌을 입증
- seq2seqr이 seq2seqf보다 조금 더 좋음
- longer sequence를 결과로 가져오는 autoencoder 때문
- 이는 단어의 temporal variation을 더 잘 찾도록 도와줌
- longer sequence를 결과로 가져오는 autoencoder 때문
- seq2seqrf가 개별(seq2seq, seq2seqf)보다 지속적으로 좋음

- Fig4: 예측갑과 actual representation 간의 코사인 유사도를 입증(각 synthetic 단어에 대해서 "Full" case의 단계마다(c=0.0)(change의 highest level of change를 뜻함)
- seq2seqr은 synthetic exmaples의 input sequence를 future prediction component(average cosine similarity per year (avg cos): .65 vs .50)보다 정확하게 잘 reconstruct함
- 그것은 특히 synthetic word represenations를 2006-2008(avg cos06:08=.75) 동안에 잘 reconstruct 하는데 이는 λt가 가장 급격하게 변동하는 시점(Fig2)
- 하지만 전 (avg cos00:05= .65)과 후 (avg cos09:13= .59)에는 이 급격한 변동을 균등하게 reconstruct하는 것을 실패
- 그것은 특히 synthetic word represenations를 2006-2008(avg cos06:08=.75) 동안에 잘 reconstruct 하는데 이는 λt가 가장 급격하게 변동하는 시점(Fig2)
- 반대로 seq2seqf는 first year (avg cos01:05 = .74)때 synthetic word representations의 변화를 더 잘 감지
- semantic에서의 변화가 minor일 때
- 하지만 semantic change가 거의 완전할 때는 실패(λt ≤ .25, avg cos09:13= .24일때)
- seq2seqrf는 각각 구성요소의 이점에서 이점을 얻음
- first years (avg cos00:05 = .85) 때 거의 artifical examples를 reconstruct해서
- semantic shift가 동안(avg cos06:08= .62)에 그리고 과정 후에 완전히(avg cos09:13= .26) 되도록 강조함
- first years (avg cos00:05 = .85) 때 거의 artifical examples를 reconstruct해서
- 마침내 seq2seqrf에 있는 avg-cos는 λt (ρ=.987)와 높은 상관관계인데
- 단어의 semantic change의 속도를 어떻게 측정하는가에 대한 시야를 제공
- seq2seqr은 synthetic exmaples의 input sequence를 future prediction component(average cosine similarity per year (avg cos): .65 vs .50)보다 정확하게 잘 reconstruct함
Effect of Conditioning Parameters
- semantic change process의 duration에도 불구하고
- c 값의 증가는 모델 성능 degradation에서 하락을 가져옴
- 이는 예상된 결과임: c의 증가가 source words의 semantic change의 level이 낮다는 것을 을 암시하므로(#4.2)
- 그러므로 detecting task를 더 어렵게 만듦
- 그럼에도 불구하고 가장 challenging한 setting (c=0.5, Full, seq2seqf )에서 가장 나쁜 모델 성능은 µr=28.17임
- 이는 random baseline (µr=50.00)에서 예측된 µr보다 명백히 좋음
- semantic change의 duration의 감소는 본 모델에서 이점이 있음(Fig3)
- 이는 c가 높은 값일 때 더 명백함
- seq2seqr (µr: 26.09-18.21 in the Full-to-Quarter cases), seq2seqf (µr: 28.17-22.48), seq2seqrf (µr:20.38-13.09) 일때
- 성능에서의 명백한 향상을 보여줌
- 이는 본 모델이 semantic change를 time-series의 small subsequences에서 포착할 수 있음을 나타냄
- 이는 c가 높은 값일 때 더 명백함
- longer duration의 dataset의 효과를 연구하는 것은 미래 과정에서 중요할 것
5 Model Comparison with Real Data
5.1 Experimental Setting
- task를 rank-based 방법으로 진행(#4와 마찬가지)
- 그러나 해당 파트에서는 단어의 semantic change의 실제 단어 예제들을 탐지하는 것과 모델을 베이스라인과 비교하는 것에 초점
Data and Task
- UK Web Archive dataset(#4.1) 사용
- 80/20으로 train/test split을 설정하고,
- test set에서 change했다고 알려진 65 단어를 Oxford English Dictionart로 통합함
- 모델을 # 4.3에서와 같이 훈련
- test set에 있는 65 단어를 탐지하는테 목표를 두면서
- µr(#4)와 k (Rec@k, k=5%,10%, 50%)에서의 recall을 evaluation metric으로서 사용
- precision을 k에서 쓰면서 refrain함
- Oxford English Dictionary가 semantically shifted words의 full coverage를 가지고 있지 않다고 기대 되어서
- 낮은 µr과 높은 Rec@k 점수는 더 나은 모델을 암시
Models
-
three variants를 #3의 4가지 유형의 베이스라인과 비교
-
A random word rank generator (RAND).
- test set에서 1K runs 후 average metrics를 보고
-
Variants of Procrustes Alignment(예전 연구에서 흔히 쓰던 방법)
- 두 개의 다른 연도에 대해서 word representations가 주어지면
- [W0, Wi]는 원래의 것과 s.t. tr(WkWTk) = 1을 centered around하고
- Wi를 W*i s.t.으로 변경
- W0과 W*i의 squared differences는 최소화 됨
- 또한 PROCRk, PROCRkt variants를 사용해서
- aignment를 학습하고, Wi를 W*i로 바꿈
- 단어들은 cosine distance에 기반해서 [W0, W∗i] 사이에 rank됨
- 두 개의 다른 연도에 대해서 word representations가 주어지면
-
첫번쨰와 마지막의 representations 만을 학습하는 모델
- Random Foreset 회귀 모델 사용
- W0이 주어졌을 때 Wi를 예측함
- 또한 #3.1-3.2에서([W0, Wi]) 훈련된 것과 같은 아키텍처 사용
- full sequence를 무시하면서
- LSTMr은 sequence [W0, Wi]를 reconstructs함
- LSTMf는 W0이 주어지면 Wi를 예측함
- 단어들은 예측값과 실제 값 사이의 코사인 유사도를 오름차순한 순서로 rank됨
- Random Foreset 회귀 모델 사용
-
distances의 time series로 작동하는 모델
- vectors [W0, ..., Wi]의 시퀀스가 주어지면
- PROCR의 결과인 cosine distances의 time series를 구성
- 그러고나서 two global trend models를 사용
- GTc는 time series의 Pearson correlation의 절대값의 평균 단어를 rank함
- GTB는 linear regression model을 모든 각 단어에 대해서 fit함
- 그러고나서 단어를 slope의 absolute value로 rank함
- 마침내 PROCR∗을 사용해서 단어들을 average cosine distance에 기반해서 [0,i]에 단어를 rank함
- 이는 "Mean Distances" 모델과 유사함
- time point i 때 distance에서 차이가 있음
- 이는 "Mean Distances" 모델과 유사함
- vectors [W0, ..., Wi]의 시퀀스가 주어지면
-
모델의 성능 보고
- (a) full interval[2000-13]에서 작동할 때
- (b) 본 모델은 additional(future) information을 사용
- seq2seqf가 [2000,2001] word sequence로 fed되면 [2002,...2013]에 대한 예측을 수행
- 그런 정보들은 베이스라인에 의해서 활용되지 않을 수 있음
- 그러므로 (b)의 경우 intra-model(and intra-baseline) comparisons만 수행
- seq2seqf가 [2000,2001] word sequence로 fed되면 [2002,...2013]에 대한 예측을 수행
5.2 Results
Our models vs baselines
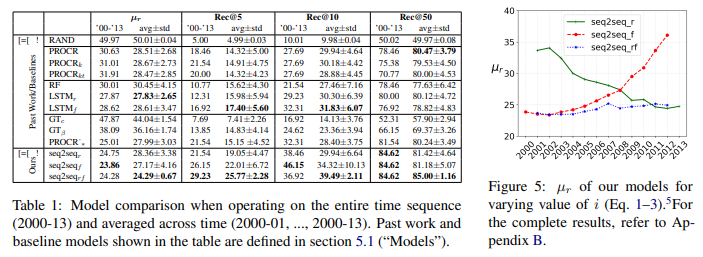
- 세 제시 모델은 지속적으로 가장 낮은 µr를 얻고, 가장 높은 Rec@k를 얻음
- whole time sequence에서 작동할 때(’00-’13 columns)
- 2000-13년도 사이의 {seq2seqr,LSTMr} 과 {seq2seqf , LSTMf } 사이의 비교는 시간에 따라서 word representation의 full sequence를 modelling하는 것의 이점을 입증
- first, last representation을 사용했을 때와 비교해보면
- 본 모델은 µr에서 Rec@k(k=[5,10,50])가 [35.7%, 42.8%, 5.8%]에서 이전 베이스라인 최고 모델보다 4.6% 높은 성과 제공
- seq2seqf, seq2seqrf 모델은 autoencoder(seq2seqr)을 우세함(대다수의 metric에서)
- seq2seqrf가 가장 안정적인 결과
- 해당 차이들을 섹션 마지막 문단에서 자세히 다룸
Intra-baseline comparison
- first and last word representations에서 작동하는 모델들은 Procrustes-based baselines를 outperform하는 것을 완전 실패
- non-sequential한 방법으로 작동할 때의 약점을 입증
- LSTM model은 2000-13실험에서 낮은 µr를 얻음
- 반면, 모든 해의 µr에 걸쳐서 나머지 베이스라인에서의 차이는 엄청 작음
- intra-Procrustes model 비교는 더 나은 alignment (PROCRk, PROCRkt)를 학습하기 위해서 few anchor word를 선택하는 것의 이점을 입증한 선행 연구는 두 연속적인 해에 대해서 semantic change를 조사하는 것이 더 긴 시간을 조사할 때는 적용되지 않을 것임을 입증함
- 마침내 이전 선행 연구와 대비하여, 본 논문은 time(GTc, GTβ)에 대해서 word distnace에서 time sensitive 한 모델이 baseline(처음과 마지막 단어 representations만 활용)보다 악화됨을 발견
- 이런 차이는 데이터셋에서 low number of time steps에 기여함
- 이는 GT model이 long-term correlations을 활용하는 것을 허락하지 않음
- 하지만 시간에 대해서 full word sequence를 활용하는 것의 중요성을 강조함
- 이는 GT model이 long-term correlations을 활용하는 것을 허락하지 않음
Effect of input/output lengths
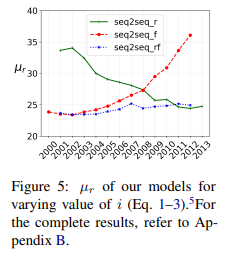
-
Fig5는 three variants의 µr을 보여줌
- 인풒ㅅ과 아웃풋의 길이를 바꾸었을 때(#3.4)
-
seq2seqr의 성능은 인풋 사이즈에 따라서 올라감
- decoder가 semantics가 더 긴 시간에 대해서 바뀐 단어들을 탐지하는 것이 가능해서
- 또한 word’s representation의 더 긴 시퀀스를 모델링하는 동안
- decoder가 semantics가 더 긴 시간에 대해서 바뀐 단어들을 탐지하는 것이 가능해서
-
반면에 seq2seqf의 선응은 인풋 time steps의 수가 감소하면 증가
- 이는 예상한 결과.
- i가 감소하면, seq2seqf는 더 짧은 인풋 시퀀스를 인코딩하고
- 디코딩은 time steps가 [i+1, 2013] 일 때 나머지(증가한 수)의 것에 적용
-
이런 결과는 경험적인 증거를 제공
- 모델 둘 다가 time steps가 더 긴 시퀀스에서 훈련되면 좋은 성과를 얻을 수 있음
- 마침내 seq2seqrf의 안정ㅅ성은 input 길이의 자연스러운 불균형성을 입증
이는 또한 모든 averaged resulst(standard deviation in avg±std columns)에서 명백한 증거임
Tab1에서 처럼
가장 안좋은 setting에서 seq2seqrf는
여전히 best performing model에 유사한 결과를 얻고자 함(µr=25.17, Rec@k=[21.54, 36.92, 83.08] for the three thresholds)
* 또한 Tab1의 Rec@k에 나와있듯이 좋은 performing baseline을 입증
- 이는 모델의 attractive 한 aspect임
- 그것이 인코더에 넣어질 time steps의 수를 정의하기 위한 need를 지우기 때문
Words with shifted meaning
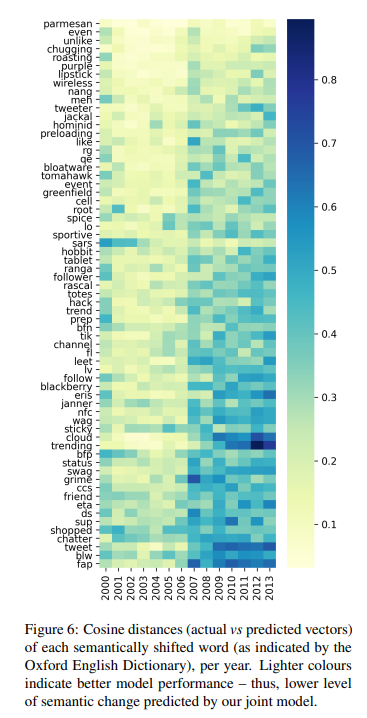
- Fig6은 65 단어(2001-2013 사이에 새로운 의미를 얻음)의 actual와 predited vectors간의 cosine distance를 보임
- distance는 test set에서 seq2seqrf model을 적용해서 계산됨
- 단어들은 year 동안, average cosine distance에 기반해서 rank됨
- 첫번째 행에 있는 단어들이 semantic shift를 탐지하는데
- 이 몇 개의 단어들이 social networks(e.g., “like”, “unlike”)의 context에서 additional meaning을 얻었음에도 불구하고
- 이는 그들의 vector에 의해서 effectively captured되지 않음
- contextual representations를 우리 모델에서 이용하는 것은 후속 연구에서 그런 경우들을 포착하는데 효율적일 수 있음
6 Conclusion and Future Work
- semnatic change detection에 대한 세 sequential model을 소개
- 이는 시간에 대해서 단어의 full sequence를 효율적으로 이용(semantic change의 level을 결정하기 위해서)
- synthetic과 real data에 광범위한 실험 + UK Web Archive dataset의 SOTA와의 비교를 통해 -> 다양한 환경에서 제시한 모델의 효율성을 입증
- 특히 time period가 증가하면 성능이 증가함을 입증
- competitive models와 common practices를 semantic change에서 앞도
