Paper Link: https://aclanthology.org/2023.emnlp-main.85.pdf
Abstract
- zero-shot learning ability of ChatGPT를 분석하기
- 20개의 데이터 + 7개의 Task
- 결과
- favoring reasoning capabilities (e.g., arithmetic reasoning)에 챗지피티가 유능함
- sequence tagging 같은 특정한 태스크는 어려워함
시작 전, 이것만은 꼭
ChatGPT와 GPT-3.5(Instruct GPT)의 차이점
- 참고 - GPT-3 vs GPT-3.5 vs ChatGPT
- 기본 용어
- Pre-training은 모델을 사전에 학습하는 것
- Transfer Learning은 Pre-trained 모델을 사용하여 다시 학습하는 것
- Fine-Tuning은 Transfer Learning 방식 중 하나
- 학습 과정의 레이어 중 가장 끝단의 레이어를 변형하여 학습하는 것인데, 기존의 레이어가 새로운 용도에도 유용한 역할을 지닐 때 사용
- GPT-3 모델 시리즈
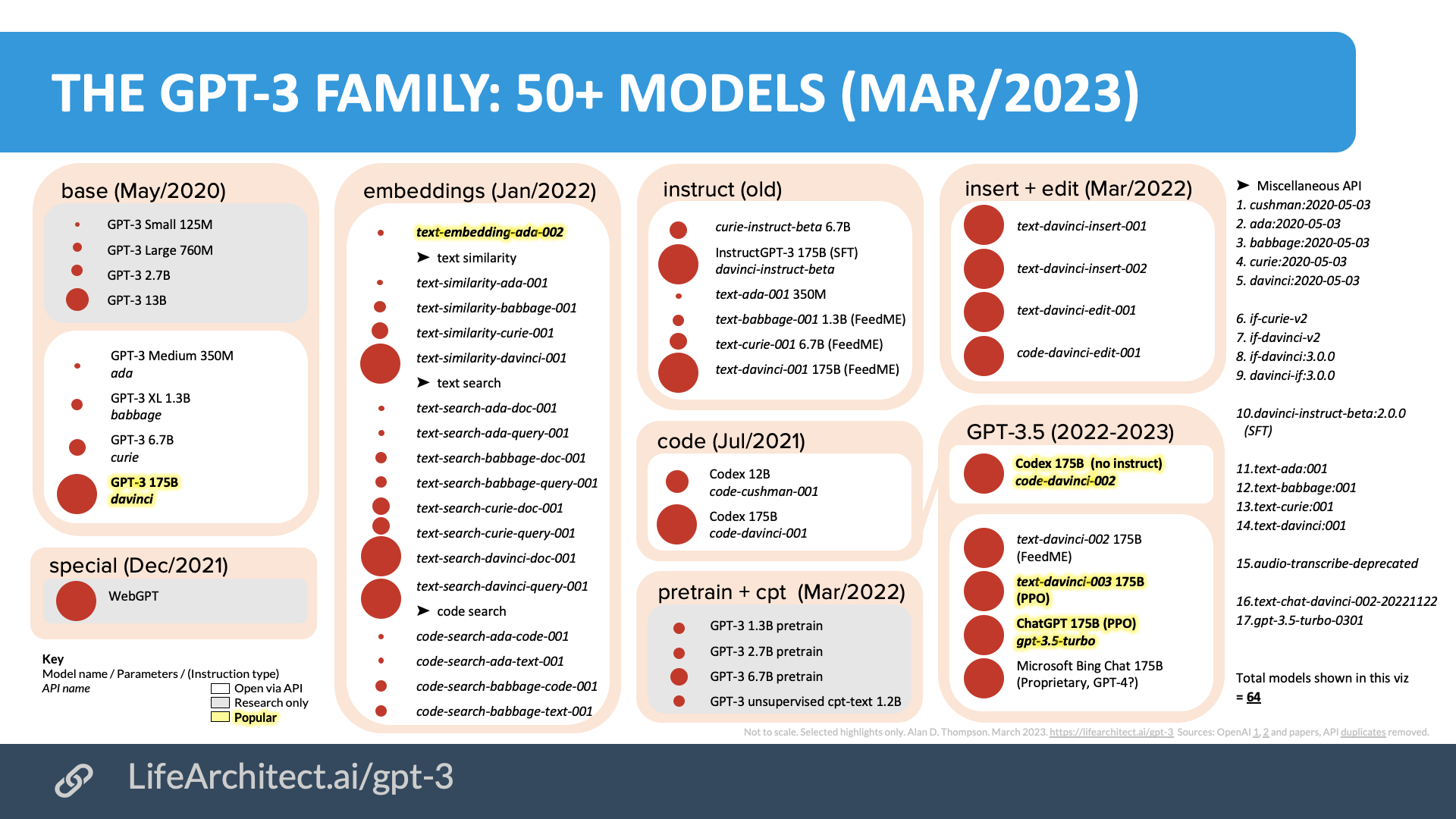
=> 서로 포함관계이고 base, embeddings, instruct(GPT-3.5), code 등으로 나누어서 상황, 목적에 따라 fine-tuning한 모델들임- ChatGPT는 GPT-3.5의 Fine-Tuned 버전 (챗봇에 특화, 실생활 적용에 가장 적합)
- GPT-3.5는 GPT-3의 Fine-Tuned 모델
- InstructGPT라는 이름으로 2022년 1월 공개 후 -> 추가 기능이 확장되어 GPT3.5가 됨
- RLHF를 사용하여 학습
Zero-shot, Few-shot 의 차이점
- 최신 LLM이 Zero-shot, Few-shot 을 어떻게 적용해서 해결해가고 있는지?
2022 NEURIPS, Large Language Models are Zero-Shot Reasoners
- prompting : 매번 모델을 특정 task에 특화시키는 대신, 약간의 예시를 주거나(few-shot), 예시를 주지 않아도 문제를 설명하고 답을 구하도록 지시를 주는(zero-shot) 행위
- 구체적인 문제 풀이 과정의 예시를 제공하는 것을 few-shot prompt,
- Chain of thought prompting: few shot prompting의 일종으로, 한 개의 답을 단계별로 차근차근 나눠 예시를 제공하는 것
- 문제와 해답 템플릿만을 제공하는 것을 zero-shot prompt 라고 합

- 구체적인 문제 풀이 과정의 예시를 제공하는 것을 few-shot prompt,
- 본 논문에서는 Let's think step by step이라는 문장을 사용하면, 기존 방식(b)처럼 문제마다 설명을 따로 할 필요가 없다는 것을 발견
- Zero shot Chain of Thought 제시
문제별로 구체적인 예시를 제공이 필요 없음
한 개의 템플릿만으로 광범위하게 응용 가능
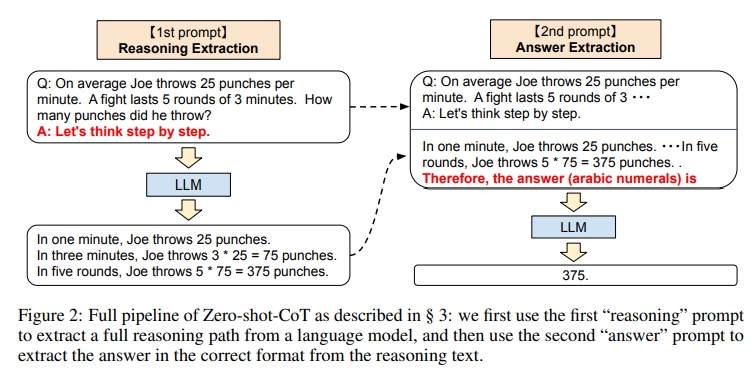
- Two-stage Prompting
- 1st prompt: reasoning extraction
- 2nd prompt: answer extraction
- Zero shot Chain of Thought 제시
1. Introduction
- LLM은 NLP task를 zero-shot으로 해결한다고 널리 알려짐
- 다운스트림태스크에 주어진 훈련 데이터에 의존하지 않고!
- 적절한 프롬팅에 의존해서만 !
- 지시문에 기반해서 새로운 태스크를 수행하는 능력은
- artificial general intelligence에서 중요한 단계로 보여짐
- LLM은 몇몇 수행에 합리적인 결과를 보여주었지만,
- 현대 LLM은 zero-shot learning에서 실수를 잘하는 경향이 있음
- 더 나아가, prompt의 형태는 상당한 영향력을 가질 수 있음
- 예) “Let’s think step by step” 을 넣어주었더니 → InstructGPT에서 엄청난 성능 향상 (reasoning task에서)
- 이런 한계들은 현대 LLM이 진정한 general-purpose language systems이 아님을 입증
- 최근, ChatGPT LLM은 NLP에서 많은 관심 받음
- GPT-3.5를 reinforcement learning from human feedback (RLHF)로 훈련하여 ChatGPT가 만들어짐 (InstructGPT와 유사하게)
- RLHF의 주요 세 단계
- 지도학습으로 언어모델 훈련하기
- human preferences에 기반하여 comparison data를 수집하고, reward model을 훈련하기
- reinforcement learning을 사용하여 언어모델을 reward model에 대해 최적화 하기
- RLHF 훈련을 통해 ChatGPT는 여러 aspect에서 영향력 있는 능력을 가지고 있다고 밝혀짐
- 예시로 - generating high-quality responses to human input, rejecting
inappropriate questions, and self-correcting previous errors based on subsequent conversations
- 예시로 - generating high-quality responses to human input, rejecting
- ChatGPT가 강한 dialogic capability를 보여주지만, NLP 커뮤니티에서는 여전히 의문점이 있음
- ChatGPT가 기존 LLM에 비해 더 나은 제로샷 일반화를 달성하는지 여부
- 이 research gap을 채우고자, 본 연구에서는
- ChatGPT의 zeroshot 능력을 평가함
- 7가지 태스크에서 - reasoning, natural language inference, question answering (reading comprehension), dialogue, summarization, named entity recognition, and sentiment analysis.
- 여기서 reasoning은 linguistic tasks의 의미로 평가될 수 있음 (prompt templates나 아니면 chains of thought in the text format과 함께)
- 7가지 태스크에서 - reasoning, natural language inference, question answering (reading comprehension), dialogue, summarization, named entity recognition, and sentiment analysis.
- 다음 research question에 대답하기
- Is ChatGPT a general-purpose NLP task solver? On what types of tasks does ChatGPT perform well?
- If ChatGPT fell behind other models on certain tasks, why?
- 이에 대답하고자, ChatGPT (gpt-3.5-turbo)와 이전 모델인 GPT-3.5 model (text-davinci003)에서 실험
- 더 나아가 최근 연구에서의 zero-shot, fine-tuned, or few-shot fine-tuned에서의 결과도 보고함
- FLAN (Wei et al., 2021), T0 (Sanh et al.,2021b), and PaLM (Chowdhery et al., 2022b).
- 더 나아가 최근 연구에서의 zero-shot, fine-tuned, or few-shot fine-tuned에서의 결과도 보고함
- ChatGPT의 zeroshot 능력을 평가함
- Key takeaways (contribution 같은 느낌이네)
- To the best of our knowledge, this is the first study of the ChatGPT’s zero-shot capabilities on a diverse range of NLP tasks, aiming to provide a profile of ChatGPT. The key findings and insights are summarized as follows:
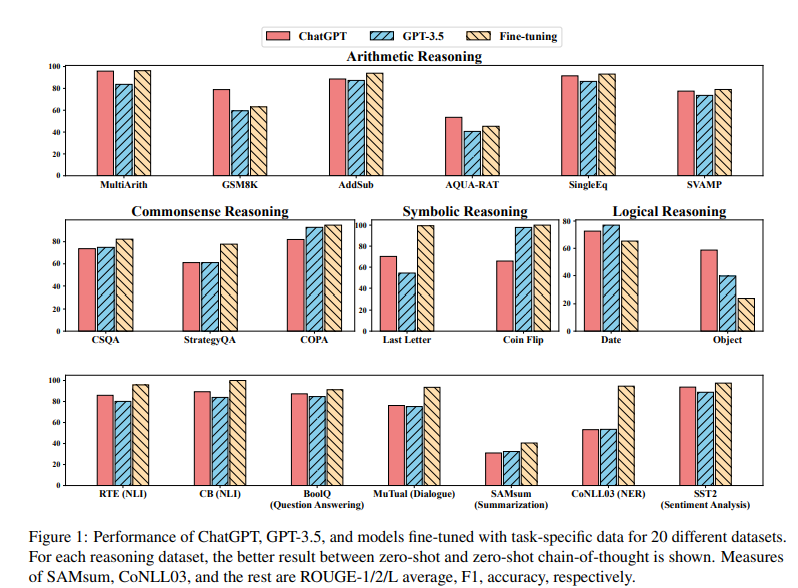
- ChatGPT가 여러 작업이 수행가능한 generalist 모델로서 일부 기능을 보여주지만 -> 특정한 작업에 대해서는 fine-tuned 된 모델보다 성능이 낮은 경우 있음 (#4.3, Fig 1)
- ChatGPT의 우수한 reasoning capability는 arithmetic reasoning tasks(산술 추론 작업)에서 경험적으로 입증됨 (# 4.2.1) -> 그러나, GPT3.5보다 commonsense, symbolic, and logical reasoning tasks는 못하는 경우도 있음
- ChatGPT는 GPT-3.5보다 (1) NLP task (# 4.2.3), (2) Question answering (reading comprehension) tasks 에서 유능함 (텍스트 쌍 내, 논리적 관계를 결정하는 것 같이 추론 능력을 선호하는 task들)
- 특히 ChatGPT는 사실적으로 일관된 텍스트 처리에 유능함 (entailment를 non-entailment보다 잘 분류함)
- dialogue tasks에서 ChatGPT가 GPT-3.5보다 유능함 (#4.2.5)
- ChatGPT는 GPT-3.5보다 요약문을 더 길게하는데 성능은 더 낮음
- 하지만, zero-shot instruction에서 요약 길이를 명시적으로 제한하면 요약 품질이 손상되어 성능이 더욱 저하됨(#4.2.6).
- generalist models로서 가능성을 보여주었지만, ChatGPT와 GPT3.5는 sequence tagging 같은 특정 작업에 대한 challenge가 있음 (#4.2.7)
- ChatGPT의 sentiment analysis 능력은 GPT-3.5보다 나음 (#4.2.8)
- To the best of our knowledge, this is the first study of the ChatGPT’s zero-shot capabilities on a diverse range of NLP tasks, aiming to provide a profile of ChatGPT. The key findings and insights are summarized as follows:
2 Related Work
- 본 연구는 ChatGPT의 zero-shot learning의 능력을 주요하게 평가함
- 여러 본질적인 NLP task 에서
- 그래서 , 이 연구에서 필요한 3가지 관련 연구들을 리뷰함
2.1 Large Language Models
- Brown et al. (2020); Radford et al.(2019) 이 언어모델이 여러 task를 gradient updates없이 수행할 수 있음을 입증한 이후,
- 모델에 textual instruction(zero-shot)을 포함하여 + 아니면 예시들(few-shot)
- 많은 연구들이 더 나은 LLM을 만들고자 노력함
- 그에 대한 연구 가닥 중 하나는, LLM을 scaling up하는데 초점을 두었음
- 다음을 포함함
- 530 billion parameter를 가진, Megatron-turing NLG (Smith et al., 2022)
- 280 billion parameters를 가진, Gopher (Rae et al., 2021)
- 540 billion parameters를 가진, PaLM Chowdhery et al. (2022b)
- 이러한 scale의 이점은 -> 어려운 태스크에서 더 나은 성능을 보임
- 예) PaLM이 outperformed average humans on the challenging BIGbench benchmark (Srivastava et al., 2022)
- 이런 LLM은 또한 더 나은 모델의 basis를 구성함 (Minerva (Lewkowycz et al., 2022) 같은)
- Minerva는 여러 기술 benchmark에서 SOTA 달성
- 모델 사이즈를 키우는 것 대신에 다른 연구가닥은, (1) longer training (Hoffmann et al., 2022)이나 (2) alternative objectives Tay et al. (2022)을 사용하여 작은 모델로 더 나은 성능 보이기
- 특히 유익한 방법 중 하나는 supervision (Sanh et al., 2021b; Wei et al.,
2021; Mishra et al., 2022; Chung et al., 2022)
이나 human feedback (Ouyang et al., 2022)이었음.
- LLM의 강한 성능은 -> 엄청난 양의 연구로 감
- abilities나 LLM의 행동을 분석하는 (Webson and Pavlick, 2022;
Min et al., 2022; Liang et al., 2022).
- abilities나 LLM의 행동을 분석하는 (Webson and Pavlick, 2022;
2.2 Zero-Shot Learning
- Zero-shot learning은 labeled training examples 없이, unseen task를 해결하고자 함
- 그것은 모델에게 큰 어려움을 남기는데 -> training data의 큰 양에 주로 의존하기 때문
- Zero-Shot Learning을 해결하려는 이전 방법들은 주로 두 방법으로 진행
- (i) model-based methods
- unseen samples에서 어떻게 바로 모델 학습시킬지 연구 (Fu et al., 2017; Wang et al., 2018)
- (ii) instance-based methods
- 모델 학습을 향상 시키고자 -> unseen task에 대해서 labeled instances 얻기 (Zhang et al., 2017; Ye and Guo, 2017).
- 더 최근 연구들은 LLM에서 zero-shot learning의 우수성을 입증함
- 가장 최근 LLM의 혁신은 -> 대화와 관련된 여러 측면에서 놀라운 성능을 보인 ChatGPT의 등장
- 한 단계를 더 나아가 -> 본 논문에서는 대화를 넘어 여러 다양한 작업에서 ChatGPT의 제로샷 학습 기능을 살펴봄
2.3 Chain-of-Thought Prompting
- Chain-of-Thought Prompting은 llm이 답변하기 전에 중간 추론 단계(intermediate reasoning steps )를 생성하도록 유도함
- manual demonstrations(수동 시연) 여부에 따라 현재 CoT prompting 방법은, 크게 두 가지 범부로 나누어짐
- (1) manual-CoT
- LLMs은 CoT reasoning를 manually designed demonstrations 로 수행(Wei et al.,
2022). - Least-to-most prompting (Zhou et al., 2022)은 복잡한 문제를 하위 문제로 분해한 다음 -> 하위 문제를 순차적으로 해결함
- Wang et al. (2022b)는 multiple reasoning paths(여러 추론 경로)를 샘플링하기 위해 slef-consistency(자기 일관성)을 도입한 후 다수결 투표를 실시하여 최종 답변을 결정
- 더 다양한 답변 얻기 위해, Li et al. (2022a) and Wang et al. (2022a) 는 => input space에 randomness를 적용하는 것을 구성
- LLMs은 CoT reasoning를 manually designed demonstrations 로 수행(Wei et al.,
- (2) zero-Shot-CoT
- Kojima et al. (2022)는 LLM이 decent zero-shot reasoners임을 입증함 (self-generated rationales를 사용하여)
- self-generated rationales의 효율성은 또한 STaR (Zelikman et al., 2022)에서 입증 => own generated rationales로 모델이 self-improve하는 것을 가능하게 함
- Kojima et al. (2022)는 LLM이 decent zero-shot reasoners임을 입증함 (self-generated rationales를 사용하여)
- 최근 연구 동향
- Zhang et al. (2023a)는 Auto-CoT 제시
* test questions에서 자동으로 rationales를 생성하기 위해서 - 대다수의 최근 연구들은 주로 어떻게 manual-CoT를 향상시킬지에 초점
- 예) demonstration selection을 최적화하기, reasoning chains의 quality를 최적화하기 등
- 더 나아가 연구자들은 다국어 시나리오(Shi et al., 2022)와 소규모 언어 모델(Magister et al., 2022; Ho et al., 2022)에서 CoT 채택의 타당성을 연구
- Zhang et al. (2023b)는 CoT reasoning에 비전 기능을 통합한 Multimodal-CoT를 제안
- 10억 개 매개변수 미만의 모델은 GPT-3.5를 16% 능가하고, + ScienceQA 벤치마크에서 인간 성능을 능가함(Lu et al., 2022a).
- Zhang et al. (2023a)는 Auto-CoT 제시
3 Methodology
- 본 연구에서는 다양한 task에서 ChatGPT (gpt-3.5-turbo) 와 GPT-3.5 (text-davinci-003)의 zero-shot learning performance 을 비교함
- task instruction P와 text problem X가 주어졌을 때, (input으로 concatenate 된)
- model f는 target text Y = f(P, X) 를 생성할 것으로 기대 됨 (test problem을 다루기 위해서)
- Fig 2, Fig 3

- Fig 2 - 6가지

-
Fig 3
-
예시로, 모델이 sentiment analysis task를 수행할 때
- task instruction P는 “For each snippet of text, label the
sentiment of the text as positive or negative. The
answer should be exact ‘positive’ or ‘negative’.”.
* 해당 instruction P를 읽은 후 - input X “it’s a stunning lyrical work of considerable force and
truth.”, - 모델이 output Y를 "positive"로 생성할 것을 기대하게 됨
- task instruction P는 “For each snippet of text, label the
-
single-stage prompting 방법과 달리 -> 본 연구에서는 zero-shot-CoT를 위해 two-stage prompting를 사용 (Kojima et al. (2022) 와 동일)
- 구체적으로,
- 첫 단계에서 => “Let’s think step by step.”를 채택
- as the instruction P1 to induce the model to generate the rationale R.
- 두 번째 단계에서 => selfgenerated rationale R 을 original input
X 그리고 the instruction P1과 사용 (새로운 input으로서)
* 모델에게 final answer를 생성하도록 가이드를 제시함 - 새로운 instruction인 P2 => e.g., “Therefore, among A through E,
the answer is”는 정답을 추출하는데 있어서 trigger sentence의 역할을 함
-
모든 task instruction은 다음 선행 연구 참고 (y Brown et al. (2020), Ouyang
et al. (2022), Zhang et al. (2023a) and Ding et al. (2022).)
4 Experiments
4.1 Tasks and Datasets
evaluate ChatGPT and GPT-3.5 with 20 different datasets covering 7 representative task categories:
- 1] reasoning (MultiArith (Roy and Roth,2015), GSM8K (Cobbe et al., 2021), AddSub (Hosseini et al., 2014), AQUA-RAT (Ling et al.,2017), SingleEq (Koncel-Kedziorski et al., 2015),SVAMP (Patel et al., 2021), CSQA (Talmor et al., 2019), StrategyQA (Geva et al., 2021), COPA (Roemmele et al., 2011), Last Letter Concatenation (Wei et al., 2022), Coin Flip (Wei et al., 2022), Date Understanding, and Tracking Shuffled Objects (Srivastava et al., 2022)),
- 2] natural language inference (RTE (Dagan et al., 2006) and CB (De Marneffe et al., 2019)),
- 3] question answering (BoolQ (Clark et al., 2019)),
- 4] dialogue (MuTual (Cui et al., 2020)),
- 5] summarization (SAMSum (Gliwa et al., 2019)),
- 6] named entity recognition (CoNLL03 (Sang and De Meulder, 2003)),
- 7] and sentiment analysis (SST2 (Socher et al., 2013))
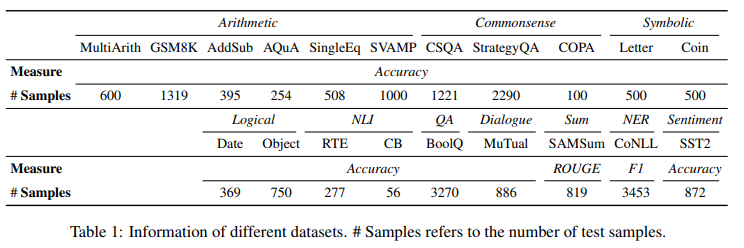
- => 7가지 태스크에서 쓰인 20개의 데이터
- reasoning task에서 4가지 카테고리
- arithmetic, commonsense, symbolic, and logical reasoning.
- reasoning task에서 4가지 카테고리
- 데이터 사용 방법
- By default we use the test split for all datasets if the labels are available for evaluation.
- For COPA and CommonsenseQA, we use the validation split. For StrategyQA, we
use the open-domain setting (question-only set) from BIG-bench collaboration (2021) following Wei et al. (2022); Zhang et al. (2023a); Kojima et al. (2022).
4.2 Experimental Results
4.2.1 Arithmetic Reasoning
-
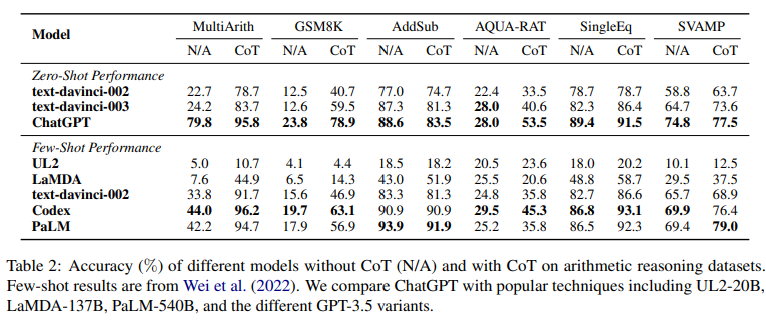
6가지의 arithmetic reasoning datasets에서 CoT 하고 안하고의 결과 => Table2
-
결과 ] ChatGPT outperforms GPT-3.5 on five out of six datasets without CoT, demonstrating its strong arithmetic reasoning ability.

-
GPT-3.5가 틀린 답을 준 경우
- On the left part of the figure, ChatGPT accurately understands “lost
8 lives” and “got 39 more lives”, resulting in the correct answer “74 lives”. - However, GPT-3.5 generates a wrong answer “120 lives” that is irrelevant
to the information provided, indicating that GPT3.5 does not understand the input question.
- On the left part of the figure, ChatGPT accurately understands “lost
-
결과] ChatGPT achieves much better performance than GPT-3.5 when using CoT in all cases.
4.2.2 Commonsense, Symbolic, and Logical Reasoning
-
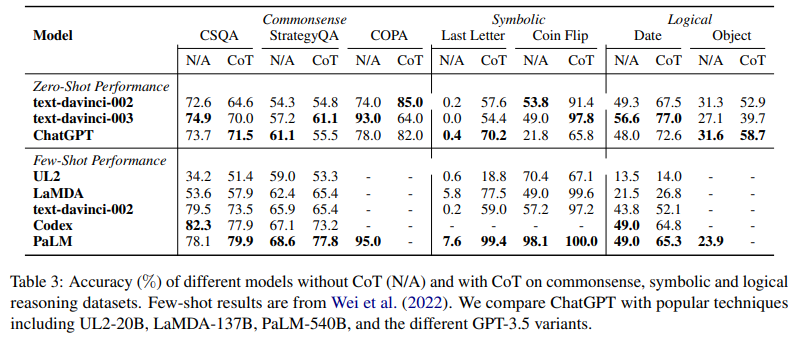
Table 3 reports the accuracy of ChatGPT compared with popular LLMs on seven commonsense, symbolic and logical reasoning datasets.
-
결과
-
- CoT를 사용하는 것이 commonsense reasoning tasks에서 항상 좋은 결과 주는 것은 아님
- Kojima et al. (2022)의 분석에 따르면 CoT methods는 flexible and reasonable rationales를 만드는 경우가 있음 => 그러나 final prediction은 commonsense reasoning tasks에서 적합하지 않음
- 해당 결과는 => commonsense reasoning tasks가 더 많은 fine-grained background knowledge를 필요로 할 수 있음을 암시하며, 해당 이슈는 (1) 모델 사이즈를 스케일링하여, (2) mixture of denoisers, (3) majority voting on multiple predictions (selfconsistency) 를 통해 => 완화될 수 있음
-
- arithmetic reasoning과 달리, ChatGPT는 GPT-3.5보다 성능이 안좋음 (많은 경우에서) => 이는 GPT-3.5의 capabilities가 더 강함을 암시함
-
4.2.3 Natural Language Inference
- sentiment analysis tasks (Section 4.2.8)와 달리, 작업 지침에서 자연어 추론의 원하는 출력 형식(“entail” or “not entail”)를 명시하면 -> ChatGPT/GPT-3.5는 요구 사항을 정확히 따르는 응답을 생성 가능
-
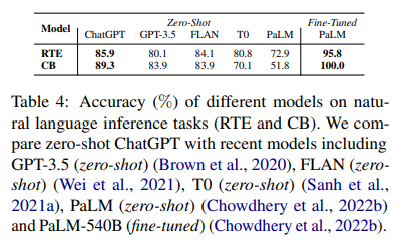
Table 4는 두 NLI task(RTE and CB)에서의 다양한 모델의 결과
-
결과
- ChatGPT can achieve much better performance than GPT-3.5, FLAN, T0, and PaLM under the zero-shot setting.
- 이는 문장 관계를 추론하는 ChatGPT의 우수한 제로샷 기능을 보여줌
-
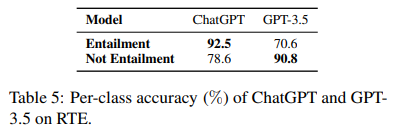
왜 ChatGPT가 GPT-3.5보다 large margin으로 능세하는지 알아보기 위해서
- Table 5에서 per-class accuracy를 보고
- Table 5에서 per-class accuracy를 보고
-
결과
- ChatGPT performs much better than GPT-3.5 when the premise does entail the hypothesis (+21.9%).
- However, it underperforms GPT-3.5 on the class “Not Entailment” (-12.2%).
- 결론 -> ChatGPT는 model training 중 자체 RLHF design에서 human feedback의 선호도와 관련될 수 있는 factual input(사실적 입력)(일반적으로 인간이 선호함)을 더 잘 처리
4.2.4 Question Answering
-
BoolQ dataset (reading comprehension)에서의 결과

-
결과
- ChatGPT outperforms GPT-3.5 by over 2%.
-
해석
- This is consistent with the results on natural language inference
- 이유 - As illustrated in Clark et al. (2019), the questions in BoolQ require difficult entailment-like inference to solve. Therefore, ChatGPT can better
handle tasks favoring reasoning capabilities.
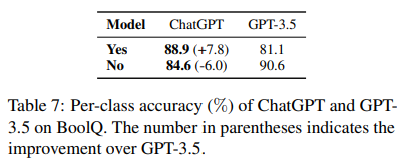
- Table 7 - the per-class accuracy of ChatGPT and GPT-3.5.
- 결과
- ChatGPT significantly outperforms GPT-3.5 on the class “Yes”,
- indicating that ChatGPT prefers handling factual input.
- ChatGPT에게 지시문에서 output으로 “Yes” or “No” 로 답하라그 랬는데 다른 결과도 같이 보여줌 ( e.g., “It is unclear”,) -> 이 사실은 ChatGPT 가 PaLM보다 더 성능 좋은 이유라고 할 수 있음
- ChatGPT significantly outperforms GPT-3.5 on the class “Yes”,
4.2.5 Dialogue
-
Table 8 - MuTual dataset (multi-turn dialogue reasoning)에서 ChatGPT and GPT-3.5의 정확도
-
결과] 예상한대로 ChatGPT achieves better performance than GPT-3.5
- 커뮤니티에서 이미 관찰된 ChatGPT의 인상적인 대화 능력과 일치하는 결과임
-
구체적인 예시로 Fig 5는 사례 보여줌
- ChatGPT는 완벽하게 답변하는데 GPT-3.5는 그렇지 않은

- 결과 => ChatGPT 는 관련 없는 정보를 추가하지 않고도 주어진 문맥에서 더 효율적인 답변을 주는 것이 가능함 (ChatGPT의 우수한 추론 기능!! 으로 볼 수 있음)
- ChatGPT는 완벽하게 답변하는데 GPT-3.5는 그렇지 않은
4.2.6 Summarization
-
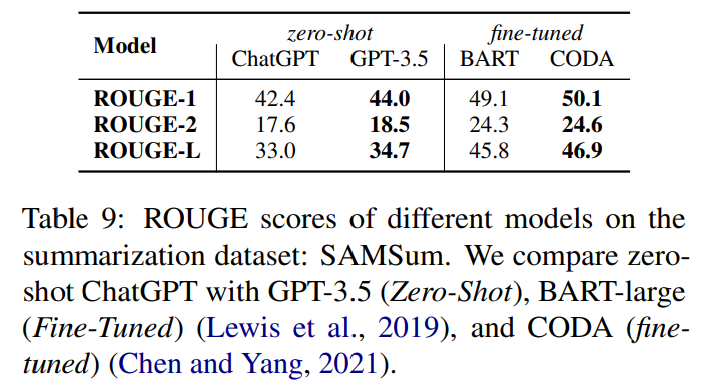
SAMSum dataset에서의 ROUGE 점수 - Table 9
-
결과
- ChatGPT underperforms GPT-3.5 across all measures.
- 본 연구자들은 -> 이를 ChatGPT의 output length를 명백히 통제하지 않아서라 판단
- ChatGPT의 답변은 주로 더 장황함 -> 낮은 점수
-
이 가설을 확인하고자 -> ground truth (20.0), GPT-3.5’s
responses (23.3), ChatGPT’s responses (36.6)에서 평균 단어수를 계산함- 명백히 -> ChatGPT의 답변이 더 길었음 -> 이는 RLHF 디자인 떄문에 나온 결과일 것임

-
Fig6은 ChatGPT가 GPT-3.5보다 긴 결과를 생성한 경우임
- 이를 통해 -> ChatGPT의 결과에 더 불필요한 정보가 있음을 확인 가능
-
더 나아가, 출력 길이를 명시적으로 제한하는 "새로운 명령을 사용하여" 통제된 실험을 수행
- “Please summarize the given conversation in no more than 25 words.”
- ChatGPT’s의 답변의 단어수가 22.8로 줄었지만 ROUGE1/2/L의 평균 점수는 31.0에서 30.6으로 떨어짐
- 그래서 -> zero-shot instruction을 통해 summaries의 결과를 통제하는 것이 ChatGPT의 요약 능력에 해를 끼칠 수 있다고 본 연구에서 결과 내림
4.2.7 Named Entity Recognition
-
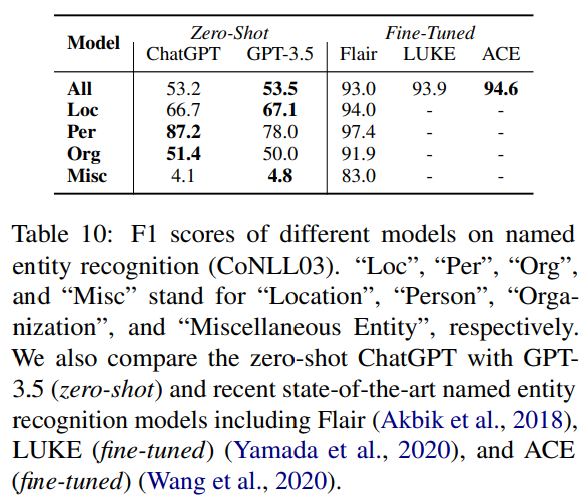
Table 10 reports the zero-shot performance of ChatGPT and GPT-3.5 on CoNLL03, a widely-used named entity recognition dataset.
-
결과
- the overall performance of ChatGPT and GPT-3.5 is quite similar.
- Unfortunately, they fail to achieve satisfactory results on each named entity type compared to previous fine-tuning methods.
- 이는 현대 LLM이 sequence tagging 같은 특정 작업 해결에는 어려움이 있음을 암시
- 특히, ChatGPT outperforms GPT-3.5 for classes “Per” (“Person”) and “Org” (“Organization”) while performing worse than GPT-3.5 on the class “Loc” (“Location”).
- Neither model shows practical value in identifying the “Misc” (“Miscellaneous Entity”) class.

-
Fig 7
- several failure cases of “Misc”.
- On the left part of the figure, LLMs recognize “Bowling” as a miscellaneous
entity while the ground truth is ‘None’. - However, “Bowling” does belong to the entity type “ball”, which can be regarded as a miscellaneous type.
- On the right part, although “AMERICAN FOOTBALL CONFERENCE” is indeed an organization, it is not recognized by the ground truth annotation, indicating that the ground truth annotation might need cleaning (although in rare cases).
-
결론적으로 -> “Miscellaneous Entity” 클래스에서의 낮은 성능은 -> 특정 데이터셋에서 LLM과 ground truth annotation 의 차이 때문일수도 있음
-
또한 본 옅구에서는 GPT-3.5가 다양한 유형의 엔터티를 별도로 생성하도록 안내하는 새로운 지침을 설계하여 F1 점수(34.8)를 훨씬 낮춤
- 이는 sequence tagging tasks을 해결하는 데 LLM이 직면한 과제를 반복해서 보여줌
4.2.8 Sentiment Analysis
-
Table 12 compares the accuracy of different models on the sentiment analysis dataset: SST2.
-
결과] ChatGPT achieves much better performance than GPT-3.5.
-
왜 그랬는지 알고자, per-class accuracy 계산함
- the performance of ChatGPT on different classes is unbalanced를 발견함
- 구체적으로, It outperforms GPT-3.5 by a large margin on negative samples while the performance on positively-labeled data comes close to that of GPT-3.5.
- 본 논문은 이에 대해 -> 이런 차이점은 ChatGPT and GPT-3.5의 다른 training data에 의해서 발생했다고 판단
- 더 나아가, task instructions에서 정답은 “positive” or “negative”이어야 한다고 명시했으나 (Fig2), ChatGPT and GPT-3.5는 다른 답변들도 제공함(, e.g., “neutral” and “mixed”,) => 이를 통해 FLAN보다 성능이 왜 낮았는지를 설명 가능
- the performance of ChatGPT on different classes is unbalanced를 발견함
4.3 ChatGPT v.s. Full-Set or Few-Shot Fine-Tuning
- Table 11 - the performance comparison between ChatGPT and the best previous full-set or few-shot fine-tuning method (among those reported in this work) for each individual task.
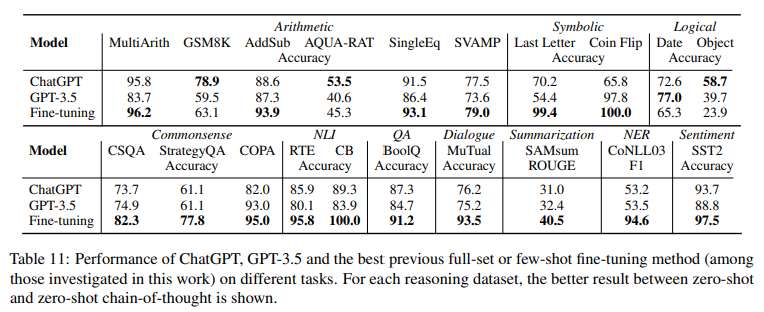
- 결과 - ChatGPT는 대부분의 경우 이전의 fine-tuning methods 보다 성능이 저하되어 ChatGPT가 여전히 완벽한 generalist와는 거리가 멀다는 것을 보여줌
5 Conclusion
- 본 연구는 대표적인 작업 범주를 다루는 대규모의 다양한 데이터에서 ChatGPT의 zero-shot learning 기능을 경험적으로 연구
- 광범위한 실험 결과와 분석을 통해 -> 다양한 유형의 NLP 작업에서 ChatGPT의 효율성과 현재 한계가 입증
- 예), powerful generalist model인 ChatGPT는 추론 및 대화 작업에 능숙함.
- 반면 ChatGPT는 sequence tagging과 같은 특정 작업을 해결할 때 여전히 어려움에 직면함.
- 이 연구가 NLP 작업에서 ChatGPT의 추론 및 대화 기능을 활용하고 현재 어려움을 겪고 있는 작업에서 일반 모델의 한계를 해결하는 등 향후 작업에 영감을 줄 수 있기를 고대함
- 예), powerful generalist model인 ChatGPT는 추론 및 대화 작업에 능숙함.
- 광범위한 실험 결과와 분석을 통해 -> 다양한 유형의 NLP 작업에서 ChatGPT의 효율성과 현재 한계가 입증
Limitations
- 1] ChatGPT 비용으로 인해 이 작업에서는 대규모 데이터 세트와 더 많은 작업이 제외(추가 통찰력이 제한됨)
- 2] 공개적으로 이용 가능하지 않은 모델(예: PaLM)에 대해 본 논문에서 최상의 결과를 보고하고, 이전 연구와 일치하는 공개 모델에 대해 발견된 최상의 프롬프트를 기반으로 결과를 보고 (Wei et al., 2022; Kojima 외, 2022; Tay 외, 2022).
- 그렇기에 -> 더욱 다양한 프롬프트를 탐색하는 것이 추가 개선이 될 수 있음
- 3] ChatGPT의 상황 내 학습 기능이 다양한 작업 전반에 걸친 제로 샷 학습 능력과 어떻게 비교되는지는 여전히 불분명함
우리는 어떻게 나아가야 할까?
- 결론적으로 GPT가 sequence tagging 같은 특정 작업 아니면 잘한다~~
- 특정 domain에 취중되었을 때는 어떨까?
Towards Interpretable Mental Health Analysis with Large Language (EMNLP 2023)
1 Introduction
-
LLM의 등장과 ChatGPT , GPT-4 (OpenAI, 2023)의 엄청난 능력으로 MH에서의 연구 동향
- Lamichhane (2023): evaluated ChatGPT on stress, depression, and suicide detection and glimpsed its strong language understanding ability to mental healthrelated texts
- Amin et al. (2023): compared the zeroshot performance of ChatGPT on suicide and depression detection with previous fine-tuning-based methods. (Will affective computing emerge from foundation models and general ai? a first evaluation on chatgpt. )
-
현재 MH 연구의 한계점
- MH condition detection은 safecritical task 이어서 -> 예측에 있어, careful evaluation 과 high transparency를 필요로 함 => 이런 부분을 반영하지 않고 binary로 함
- 간단한 prompt를 이용한 예측
- 중요한 정보를 무시하게 됨 (emotional cue 같은)
-
Research Question
- RQ 1: How well can LLMs perform in generalized mental health analysis and emotional reasoning with zero-shot/few-shot settings?
- RQ 2: How do different prompting strategies and emotional cues impact the mental health analysis ability of ChatGPT?
- RQ 3: How well can ChatGPT generate explanations for its decisions on mental health analysis?
-
11 datasets across 5 tasks
-
zero-shot prompting, Chain-of-Thought (CoT) prompting (Kojima et al., 2022), emotion-enhanced prompting, and few-shot emotion-enhanced prompting.
-
how LLMs perform for interpretable mental health analysis
-
결과
- ChatGPT가 다른 LLm보다 대체적으로 잘함
- Prompting Strategies
- ChatGPT with unsupervised emotion enhanced CoT prompts 가 가장 좋은 성능 -> MH 분야에서 emotional cues를 활용하는 것의 중요성을 입증함
- 전문가가 쓴 Few-shot learning 또한 성능 향상에 도움
2 Methodology
2.2 In-context Learning as Explainable Mental Health Analyzer
Emotion-enhanced Prompts
1) Emotion-enhanced CoT prompting (얘는 unsupervised 적인 측면)
Post: "[Post]". Consider the emotions expressed from this post to answer the question: Is the poster likely to suffer from very severe
[Condition]? Only return Yes or No, then explain your reasoning step by step.2) Supervised emotion-enhanced prompting
- zero-shot prompt에서
- VADER (Hutto and Gilbert, 2014) and NRC EmoLex (Mohammad and Turney, 2010, 2013) lexicons 사용해서 -> 각 포스트에 sentiment/emotion score 를 주고, 점수 변환하도록 고안
3) Few-shot Emotionenhanced Prompts
- 박사과정 분(전문가)이 예시 만들어서 그것 추가해서 함
You will be presented with a post. Consider
the emotions expressed in this post to identify
whether the poster suffers from [condition].
Only return Yes or No, then explain your
reasoning step by step. Here are N examples:
Post: [example 1]
Response: [response 1]
...
Post: [example N]
Response: [response N]
Post: [Post]
Response:Task-specific Instructions
- 다음 3 태스크를 통해 MH의 능력을 평가하고자 함
- binary mental health condition detection
- yes/no classification
- multi-class mental health condition detection
- one label from multiple mental health conditions
- cause/factor detection of mental health conditions
- recognizing one potential cause of a mental health condition from multiple causes
- binary mental health condition detection
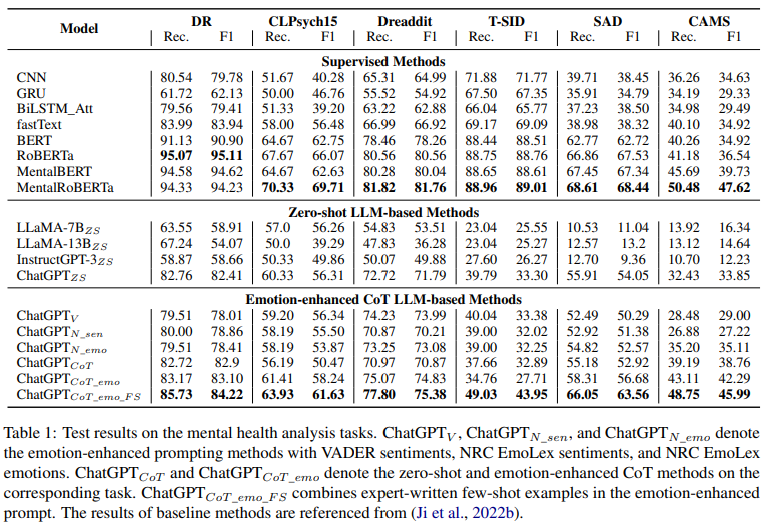
4 Results and Analysis
4.1 Mental Health Analysis
4.3 Error Analysis
- 몇 단어에 변화만 주어도 MH 분석의 성능 차이에 많은 변화가 있다고 판단
- zero-shot prompt에서 단어 수정 (binary MH detection에서)
- adjective 수정 => {any, some, very severe},
...Is the poster likely to suffer from [Adjective
of Degree] [Condition]?...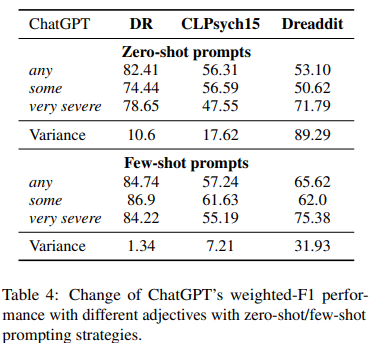
- 이 현상에 대한 본 논문의 해석 - subjective nature of mental health
conditions - human annotations가 각 포스트에 대해 Y/N으로 대답해서 -> ChatGPT가 zero-shot setting일 때 기준을 예측하기 어려움
- 해당 문제를 완화하고자, few-shot prompting에서의 효과를 확인했음 (few-shot의 결과가 zero-shot보다 낮은데, => 이는 전문가가 쓴 예시들이 CHatGPT의 예측에 안정화를 줄 수 있음을 입증함 (전문가의 예시가 다소 주관적인 MH 예측에 정확한 reference 제공이 가능해서)
- few-shot solution 또한 효율적인 이유는, 모델을 in-context learning manner로 instruct하기 때문 (high-cost model fine-tuning을 필요로 하지 않는)
