논문 전체 리뷰는 https://velog.io/@zvezda/SimCSE-Simple-Contrastive-Learning-of-Sentence-Embeddings-EMNLP-2021 민한님의 벨로그 !
Abstract
- SimCSE: simple contrastive learning framework로서 sentence embedding의 SOTA를 앞섬
- 방법1 => '비지도학습'으로 진행
- input 문장을 받고
- 그 자신을 contrastive objective에서 예측함(noise로 쓰이는 standard dropout만을 사용해서)
- 결과가 너무 좋아서 이전의 지도학습과도 비교할만함
- dropout이 minimal data augmentation으로서 작동하며, 그것을 제거하는 것이 representation collapse로 이어짐을 발견
- 방법2 => '지도학습'
- annotated pairs를 natural language inference datasets로부터 가져와서 contrastive learning으로부터 통합함
- 'entailment' pairs를 positive로 'contradiction' pairs를 hard negatives로 사용
여기까지 읽고 생기는 궁금한 점: 비지도학습을 일반적으로 아는 방식으로 답을 안주고 하고 지도학습은 알려주고 하고 그 차이로 실험이 진행되었을까? 신선한 아이디어...!!!
- 'entailment' pairs를 positive로 'contradiction' pairs를 hard negatives로 사용
- annotated pairs를 natural language inference datasets로부터 가져와서 contrastive learning으로부터 통합함
- evaluation
- standard semantic textual similarity(SST) task에서 진행
- BERTbase 사용
- Spearman's correlation에서 비지도학습과 지도학습 각각 76.3%, 81.6% 달성
- contribution
- the contrastive learning objective regularizes pre-trained embeddings’ anisotropic space to be more uniform, and it better aligns positive pairs when supervised signals are available.
1 Introduction
- universal sentence embeddings를 배우는 것은 NLP에서 근본적인 문제
- 본 논문에서 SOTA인 embedding 방법들을 발전시키고
- 목적: contrastive objective can be extremely effective when coupled with pre-trained language models
- SimCSE 제시
- simple contrastive sentence embedding framework
- unlabeled, labeled 둘 다에서 우세한 sentence embedding을 얻을 수 있음
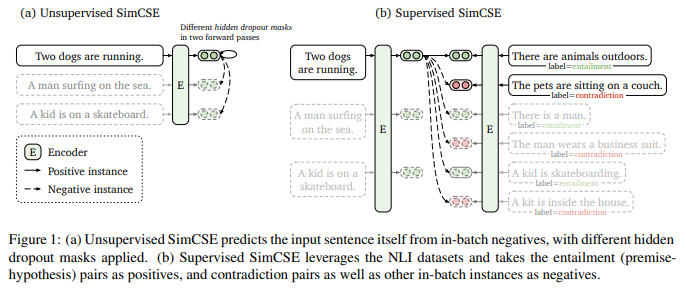
unsupervised SimCSE
- dropout(noise로 쓰임)만으로 input sentence를 예측한다
- = we pass the same sentence to the pre-trained encoder twice:
- “positive pairs”라 불리는 두 개의 다른 임베딩을 얻음
- we take other sentences in the same mini-batch as “negatives"
- 모델이 -> negative들 중에서 positive를 예측함
- 단순해보이지만 좋은 성과 거둠
- dropout이 minimal 'data augmentation'으로서 작동한다 !!
supervised SimCSE
- annotated sentence pairs를 contrastive learning으로 통합한다
- entailment pairs가 positive instances로 쓰일 수 있다는 사실을 활용함
- corresponding contradiction pairs를 hard negatives로서 추가하는 것이 성능향상에 도움줌을 발견