Abstract
- Neural sequence models는 time-series data를 모델하고자 널리 사용된다
- 마찬가지로 보편적인 것은 이러한 모델에서 출력 시퀀스를 디코딩하기 위한 대략적인 추론 알고리즘으로 빔 검색(BS)을 사용하는 것이다.
- BS
- explores the search space in a greedy left-right fashion retaining only the top-B candidates
- resulting in sequences that differ only slightly from each other
- nearly identical sequences의 리스트를 생성하는 것은 계산적으로 낭비일 뿐 아니라 inherent ambiguity of complex AI tasks를 포착하는게 어렵기도 하다
- 이런 단점을 극복하고자, Diverse Beam Search (DBS)제시
- an alternative to BS that decodes a list of diverse outputs by optimizing for a diversity-augmented objective
- 본 방법을 통해
- finds better top-1 solutions by controlling for the exploration and
exploitation of the search space - beam search보다 상대적으로 minimal computational or memory
- image captioning, machine translation and visual
question generation에서 결과 입증
- finds better top-1 solutions by controlling for the exploration and
1 INTRODUCTION
neural sequence models have become the standard choice for modeling
time-series data for a wide range of applications such as speech recognition (Graves et al., 2013),machine translation (Bahdanau et al., 2014), conversation modeling (Vinyals & Le, 2015), image and video captioning (Vinyals et al., 2015; Venugopalan et al., 2015), and visual question answering (Antol et al., 2015).
Inference in RNNs.
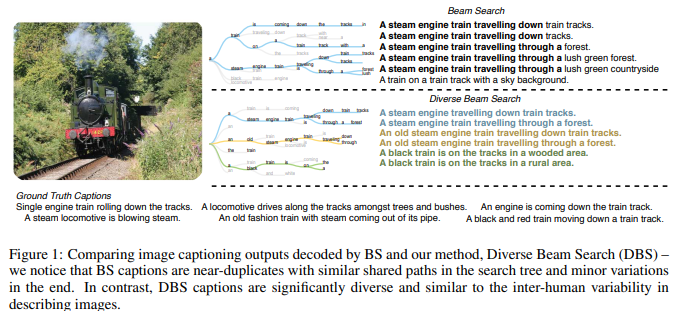
Lack of Diversity in BS.
Overview and Contributions
Diverse Beam Search(DBS)
- a general framework to decode a list of diverse sequences that can be used as an alternative to BS.
- At a high level, DBS decodes diverse lists by dividing the beam budget into groups and enforcing diversity between groups of beams.
요약하자면
- a doubly greedy approximate inference algorithm for decoding diverse sequences.
2 PRELIMINARIES: DECODING RNNS WITH BEAM SEARCH
3 DIVERSE BEAM SEARCH: FORMULATION AND ALGORITHM
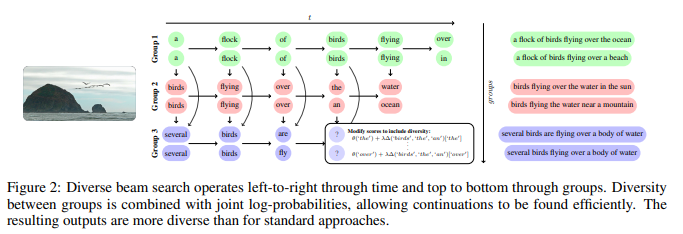
DBS is a task agnostic, doubly greedy algorithm that incorporates diversity in beam search with little memory or computational overhead
4 RELATED WORK
Diverse M-Best Lists
Diverse Decoding for RNNs.
5 EXPERIMENTS
5.1 SENSITIVITY ANALYSIS AND EFFECT OF DIVERSITY FUNCTIONS
- Number of Groups (G)
- G=B allows for the maximum exploration of the space(G=1 reduces our method to BS)
- 수를 키우면 다양하게 볼 수 있게됨
- 경험적으로 maximum exploration 과 oracle accuracy에 상관관계가 있다고 보았고
- 달리 언급되지 않는 한, G=B를 사용
- Diversity Strength (λ)
- joint logprobability와 diversity terms 간의 trade-off
- a higher value of λ -> a more diverse list
- high values of λ는 그러나, overpower model probability할 수도 있고 grammatically incorrect outputs의 결과를 가져올 수도 있음
- grid search on the validation set을 진행함(모든 실험에 대해서)
- wide range of λ values (0.2 to 0.8)가 task와 dataset에서 잘 작동함을 보임
- Choice of Diversity Function (δ)
1 Hamming Diversity
penalizes the selection of tokens used in previous groups
proportional to the number of times it was selected before.
2 Cumulative Diversity
Once two sequences have diverged sufficiently, it seems unnecessary and perhaps harmful to restrict that they cannot use the same words at the same time
3 n-gram Diversity.
4 Neural-embedding Diversity
* can penalize semantically similar words like synonyms
Hugging face
input_ids (torch.LongTensor of shape (batch_size, sequence_length)) — The sequence used as a prompt for the generation.
beam_scorer (BeamScorer) — An derived instance of BeamScorer that defines how beam hypotheses are constructed, stored and sorted during generation. For more information, the documentation of BeamScorer should be read.
logits_processor (LogitsProcessorList, optional) — An instance of LogitsProcessorList. List of instances of class derived from LogitsProcessor used to modify the prediction scores of the language modeling head applied at each generation step.
stopping_criteria (StoppingCriteriaList, optional) — An instance of StoppingCriteriaList. List of instances of class derived from StoppingCriteria used to tell if the generation loop should stop.
max_length (int, optional, defaults to 20) — DEPRECATED. Use logits_processor or stopping_criteria directly to cap the number of generated tokens. The maximum length of the sequence to be generated.
pad_token_id (int, optional) — The id of the padding token.
eos_token_id (int, optional) — The id of the end-of-sequence token.
output_attentions (bool, optional, defaults to False) — Whether or not to return the attentions tensors of all attention layers. See attentions under returned tensors for more details.
output_hidden_states (bool, optional, defaults to False) — Whether or not to return the hidden states of all layers. See hidden_states under returned tensors for more details.
output_scores (bool, optional, defaults to False) — Whether or not to return the prediction scores. See scores under returned tensors for more details.
return_dict_in_generate (bool, optional, defaults to False) — Whether or not to return a ModelOutput instead of a plain tuple.
synced_gpus (bool, optional, defaults to False) — Whether to continue running the while loop until max_length (needed for ZeRO stage 3)
정리
group_beam_search는 말그대로 beam search를 그룹별로 나누어서 하는 것
- 논문에서 입증한 task는 story generation과는 연관이 없음
- 논문에 파라미터에 대한 설명이 있지만 이에 대한 활용이 어려운 이유(특히 중요한 파라미터로 추정되는 Number of Groups (G)를 우리는 어떻게 규정할 것인지가 모호해 보임)
활용한다면 논문에 파라미터 정의가 있어서 어느정도 대입해서 활용 가능
