Abstract
확률에 기반한 언어 생성 모델은 perplexity 같은 모델의 표준 metric에서는 잘 작동하는데, 텍스트 생성에 있어서는 크게 유창하지는 않다. 이 차이는 몇 년동안 언어 생성에 혼란을 주었다
본 논문에서는 자연어 생성의 abstraction을 discrete stochastic process로 posit한다(이를 통해 확률 기반의 언어 생성에 새로운 시야를 제공해줄 수 있다)
인간은 언어를 소통의 정보로서 사용한다, 사실 인간은 각 단어를 마음에 잠재의식적인 목표를 가지고 말한다고 사회적으로 알려져있다
우리는 기준에 부합하는 set of strings를 정의한다
- those for which each word has an information content close to the expected information content
* i.e., the conditional entropy of our model.
locally typical sampling 제시
1 Intro
One of the largest determinants of the generated text’s quality is the choice of decoding strategy—
1. we contend that language generators, in some cases,
can be thought of as discrete stochastic processes.
2 We argue, however, that due to discrepancies between the model behind these generators and the true distribution over natural language strings, directly sampling from the typical set is not a good idea.
논문에서 가정하는 것
- hypothesize that for text to be perceived as natural, each word should have an information content close to its expected information content given prior context
제시 방법의 이점
(i) locally typical sampling reduces the number of degenerate repetitions, giving a REP value (Welleck et al., 2020) on par with human text,
(ii) text generated using typical sampling is generally closer in quality to that of human text
2 Two Views of Language Modeling
1 re-frame their presentation
- Concretely, we put forth that there are actually
two lenses through which we can view language
modeling productively
2.1 A Single String-Valued Random Variable

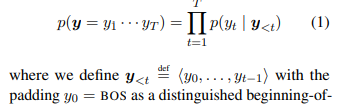
- chain rule of probability를 통해, 모델을 항상 Eq(1)에 있는대로 factorize할 수 있다
- 그런 factorization을 만드는 방법을 'local normalization'이라한다
- 하지만 local normalization으로, 미묘한 문제가 생긴다
- each conditional probability p를 V에가 아니라, augmented set에서 정의해야 한다
- 해당 부분에 distinguished end-of-string symbol EOS가 추가된다
- EOS가 없으면 언어모델을 normalize하는 것이 불가능하기 때문(합해서 1로 해줘야 함)
- each conditional probability p를 V에가 아니라, augmented set에서 정의해야 한다
2.2 A Discrete Stochastic Process
Eq(1)의 factorization은 언어모델을 single string-valued random variable이 아니라 collection of random variables(즉, a discrete stochastic process)로 볼 것을 제안한다
해당 관점에서 우리는 'language process'라고 말하는 것이 위에서 말한 언어 모델의 정의와는 어떻게 다른지를 구별하는 것에 대해서 다음 정의에 도달한다

정의2.2에서는 language process(샘플링된 단어에서 새로운 단어를 생성하는 것)가 any discrete(별개의) process라고 말한다.
자연스럽게 드는 첫번째 의문은 언어모델과 language process가 충돌할 떄인데, 여기 간단한 답이 있다.

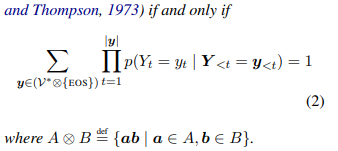
a language process가 infinite strings로 probability mass를 leak 해서는 안된다. 왜냐하면 언어모델이 (valid) probability distribution이어야 하기 때문에 tight해야 하기 때문이다

두 경우 모두 증명을 만족한다

우리는 language process가 language models보다 약간 더 엄격하다는 것을 알 수 있다
- Eq(1)은 any language model도 language process로 써질 수 있음을 보여준다
- 하지만 proposition 2.4는 반대가 필수적으로 참이 아니라는 것을 보여준다
- 2.4는 간단한 language process를 만드는 것을 쉽게 해준다
- 이는 language model로 변환될 수 없다
- Example 2.5 참고

Life after EOS?
Proposition 2.4 는 language models와 language process간의 더 직관적인 차이에 힌트를 준다. EOS 후에 어떠한 일이 발생하는가? language model의 전통적인 정의에서(Def 2.1) life는 EOS에서 끝난다
- 그 말은 즉, EOS 후에 any string with symbols는 언어모델에서 유효한 샘플이 아니라는 것이다(왜냐하면 그러한 strings가 model's support 안에 없기 때문이다)
반면에, language process는 더 chipper한 시야를 제공한다
- once we hit EOS, we can just generate another symbol
- A language process is better thought of as an infinite babbler than a distribution over any sort of strings.
어떠한 레벨에서 이것은 함축적인 시야이다
- 언어모델에 의해서 채택되는
- when language modeling, as many language models do not have EOS in the traditional sense.
해당 논문의 뒤에서는 이를 보고, language process를 고려해본다
- for which we can continue generating after sampling an EOS symbol
2.3 Other Useful Properties

Many language processes are explicitly defined to be Markov
- e.g., ones based on n-gram language models.
하지만 recurrent neural networks에 기반을 둔 현대의 많은 방법들은 non-Markov. 다 - Yet despite being capable of learning non-Markov distributions, researchers have found that recurrent neural language models tend to learn Markov distributions.
For instance, Khandelwal et al. (2018) show that a recurrent neural language model’s memory is empirically bounded at roughly
200 words.
Thus, we can still generally assume this property when working with language processes parameterized by such models.1

While not theoretically Markovian, human language is generally considered stationary, i.e., the probability distribution over the next word should not depend on absolute position, but rather the history.

2.4 Estimating a Language Model from Data
3 Information-Theoretic Properties of Language Processes
3.1 Typicality

entropy rate는 limit에서 how spread out의 관점에서 유용하다
다른 해석은 그것이 Y의 complexity를 quantifies한다는 것이다



What’s wrong with the typical set?
3.2 Local Typicality
해당 연구에서 기여한 바는 to define a more restrictive notion of typicality

- locally typical set further restricts the set of samples to those
for which each individual symbol yt has probability near the local conditional entropy - In general, there is no strong theoretical relationship between the typical set and the locally typical set.

4 Local Typicality in Natural Language
two distribution
1. pe, the distribution that a speaker of the language is assumed to generate strings from,
2. pb our language process that approximates pe—albeit, perhaps not perfectly.
- y as a means of communicating some information,
- where each word yt is a symbol via which we construct our message.
4.1 Properties of Human Communication
what are the information-theoretic characteristics of natural language typically produced by humans.
- 다시 말해서, what do strings sampled from pe look like, from the perspective of pb, our trained language process?
1 a language user’s objective
- When using natural language, humans aim to transmit information efficiently while also minimizing the risk of miscommunication
- speakers avoid producing words with either very high or very low information content
2 not using words in a context where they have very high or low information content avoids characteristics that appear to negatively impact traditional grammaticality judgments:
4.2 An Information-Theoretic Formalization
5 Sampling from a Language Process
how to decode from p
가장 intuitive strategy는 ancestral sampling
- sample yt ∼ p(· | y<t)로 작동
- for each history y< t successively until some chosen criterion
- , e.g., the EOS symbol is sampled or a maximum length is reached
해당 방법은 앞서 설명한 to sampling entire strings according to the distribution p와 동일함
* 그는 주로, truncated sampling라 불림(where the vocabulary at
a time step is truncated to a core subset of words)
본 논문에서는 general treatment of truncated sampling를 줌
- 이 때, truncated distribution은 다음과 같이 정의됨(normalizer와 함께)


5.1 Shortcomings of Existing Algorithms
First, the connection between probability and information content may explain why high-probability text is often dull or generic (Holtzman et al., 2020; Eikema and Aziz, 2020);its low information content likely makes for boring, i.e., uninformative, text
A further implication of this framing is the equivalence between decoding strings from a probabilistic language generator and sampling messages from the natural language communication channel.
5.2 Locally Typical Sampling

- negative log probability 인 단어들에 대해서 한계가 있다
- within a certain absolute range from the conditional entropy (expected information content) of the model at that time step
- top-p sampling 방법에 따르면, 이 범위는 hyperparameter인 τ에 의해 결정
- 우리가 고려하고자 했던 원래 분포로부터의 probability mass의 양
- 흥미롭게도 5.3은 'high-probability words should not be chosen'를 함축X
- 실제로, where conditional entropy is low일때다
- 즉, 모델이 작은 단어의 집합의 probability mass에 위치할 때(when the model places most of the probability mass on a small subset of words)
- it is likely the case that only high-probability words fall into
the locally typical set.
Computational Complexity
nucleus or top-k sampling와 실질적으로 비슷한 효용을 보일 수 있다
1 conditional entropy 계산
2 sort words by their absolute distance
3 greedily take words from this list until their cumulative probability exceeds the threshold τ
Relationship to Other Decoding Strategies.
우리 방법도 다른 방법들과 유사하다
- —to match the tendencies in information content exhibited by human-generated text
- albeit without requiring the computational overhead of a look-ahead strategy
사전 계산이 필요하지 않다는 장점이 있는데도 이전 방법들과 유사하게 human-generated text에서 exhibit된 내용과 유사한 경향을 보임
6 Experiments
6.1 Setup
Hyperparameters.
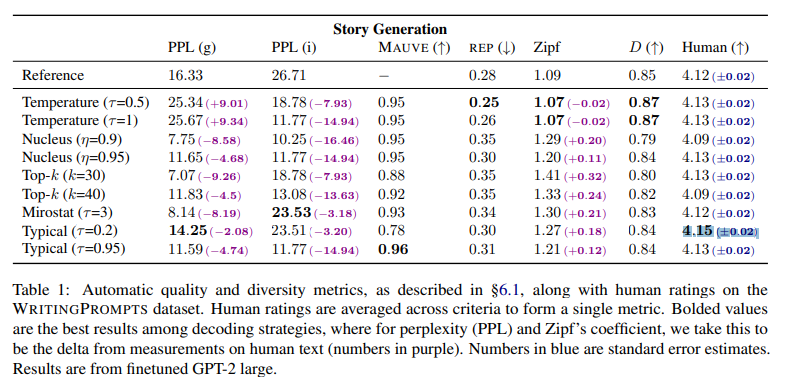
For locally typical sampling, we found τ = 0.2, τ = 0.95 to provide the best results for story generation and abstractive summarization, respectively

7 Conclusion

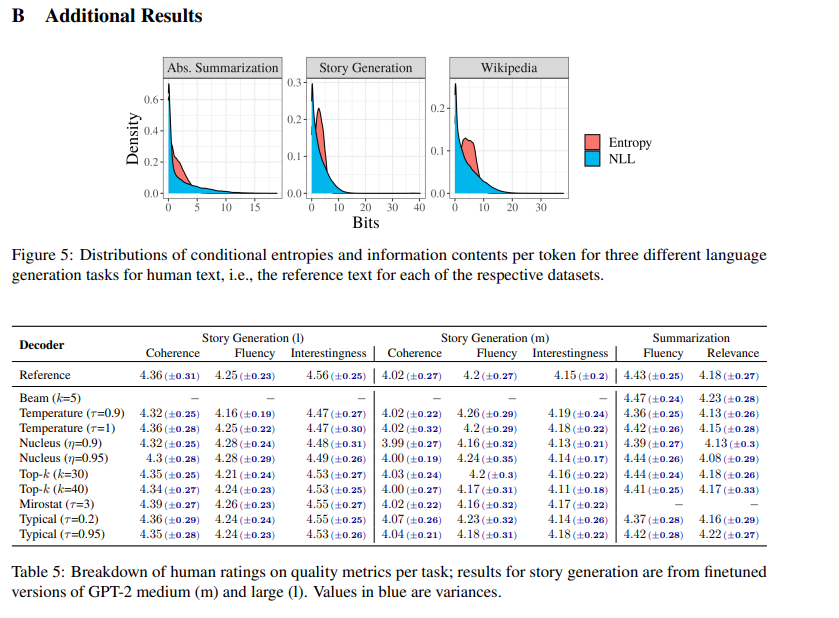
locally typical sampling—leads to text of comparable or better quality than other stochastic decoding strategies according to human ratings

정리
사람이 대화할 때 다음에 무슨 말을 할지 어느정도 생각하면서 그런 잠재의식이 사회심리학적으로 존재해서, 그러한 set of strings를 정의해서, 주어진 정보로부터 가장 근접한 정보를 만들어내고자 하는 새로운 디코딩 방법을 만듦(locally typical sampling)
conditional entropy를 사용.
5.2 top-p sampling과 다른 점은 'high-probability words should not be chosen'를 함축하지 않는 다는 것. 실제로, where conditional entropy is low일때로 즉, 모델이 작은 단어의 집합의 probability mass에 위치할 때다
5.2 사전 계산이 필요하지 않다는 장점이 있는데도 이전 방법들과 유사하게 human-generated text에서 exhibit된 내용과 유사한 경향을 보임
6 실험 표를 확인해보면, 0.2나 0.9를 변수로 두어서 사용
- 스토리 생성에 있어서는 0.2일때가 더 적합
- rep이 줄어들고
- Human과 더 근접해짐
typical_p (float, optional, defaults to 1.0) — The amount of probability mass from the original distribution to be considered in typical decoding. If set to 1.0 it takes no effect
https://huggingface.co/docs/transformers/v4.25.1/en/main_classes/text_generation#transformers.GenerationMixin.generate
1로 두면 효과가 없다 -> 이걸 낮추자는 것이 이 논문의 아이디어 같은데.. 꼭 높다고 좋은게 아니다 !!!

안녕하세요 fla1512님 !
디코딩 방식에 대해서 여러 개 공부해보고 있었는데 이 포스트가 도움이 되었어요 ~.~ 감사합니다 !