💡Seq2seq 모델의 한계점
Transformer 모델에 대해 공부하기 전에 Seq2seq 모델의 한계점에 대해 알아보자!
Seq2seq 모델에 대한 자세한 설명은 Sequence to sequence Learning with Neural Networks 논문 리뷰를 참고하길 바란다.
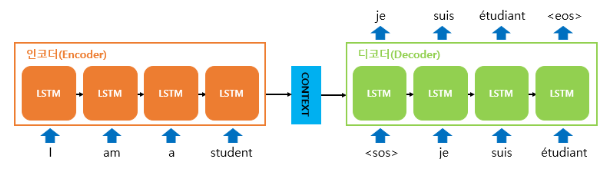
Seq2seq 모델의 한계점에 대해 알아보자.
Seq2seq 모델은 context vector 에 소스 문장의 정보를 압축하는 특징을 가지고 있다.
→ 병목(bottleneck) 현상이 발생하여 성능 하락의 원인이 된다.
🔍 병목 현상
병목현상이란 말 그대로 병의 목처럼 좁아지는 구간 때문에 발생하는 성능하락을 말한다.
- Seq2seq처럼 context vector의 크기가 정해져 있어 모델이 추출한 정보를 압축하는 경우 발생
- 정보를 압축하다보면, 세부정보의 손실이 있기 때문에 성능이 하락한다.
- 디코더로 전달하는 정보의 양 제한 or 손실이 일어난다.
Seq2seq 모델은 단어가 입력될 때마다 이전 정보가 모두 들어있는 hidden 값을 받아서 갱신된다. 마지막 단어의 hidden state 값을 소스 문제 전체를 대표하는 하나의 context vector로 넣는다.
context vector에 정보를 압축하려고 하면 위와 같은 병목 현상이 나타나는 것이다.
물론 디코더가 context vector를 매번 참고하게 할 수 있지만, 여전히 소스 문장을 하나의 벡터에 압축해야 하므로 한계가 있다.
🔹Abstract
기존의 주요 시퀀스 변환(sequence transduction) 모델들은 복잡한 순환 신경망(RNN) 또는 합성곱 신경망(CNN) 기반으로, 인코더와 디코더 구조를 포함하고 있다. 최고 성능을 보이는 모델들은 일반적으로 어텐션 메커니즘을 통해 인코더와 디코더를 연결한다.
저자는 Transformer라는 새로운 네트워크 아키텍처를 제안한다.
이 아키텍처는 오직 어텐션 기반으로 하며, 순환과 합성곱 구조를 완전히 제거한다.
두 가지 기계 번역 과제에 대한 실험 결과, 이 모델은 품질 면에서 더 우수하며, 병렬처리에 더 적합하고 학습 시간도 현저히 적게 소요된다.
실험 결과
- WMT 2014 영어-독일어 번역 과제: 28.4 BLEU
- WMT 2014 영어-프랑스어 번역 과제: 42.8 BLEU
- 8개의 GPU를 사용해 3.5일 동안 학습한 결과로, 기존 최고 모델 대비 비용이 매우 낮다.
→ 큰 데이터셋과 제한된 데이터셋 모두 성공적으로 적용했다.
🔹 Introduction
RNN, 특히 LSTM과 GRU는 언어 모델링과 기계 번역과 같은 시퀀스 모델링과 변환 문제에서 SOTA로 확고히 자리 잡았다.
이후로도 수많은 연구들이 순환 기반 언어 모델과 인코더-디코더 아키텍처의 한계를 넘어서는 데 주력했다.
순환 모델은 일반적으로 입력 및 출력 시퀀스의 symbol positions에 따라 연산을 수행한다. 이때, 각 위치를 시간 축의 연산 단계에 맞춰 정렬하며, 현재 위치 의 은닉 상태 는 이전 은닉 상태 와 해당 위치의 입력을 함수로 하여 생성된다.
⚠️ 문제점
1. 본질적으로 순차적인 처리 방식은 병렬 처리를 불가능하게 만든다.
2. 시퀀스 길이가 길어질수록 메모리 제약으로 인해 다수의 예제를 한 번에 처리하는 데 한계가 생긴다.
저자는 Transformer라는 새로운 모델 아키텍처를 제안한다.
이 모델은 순환 구조를 완전히 배제하고, 입력과 출력 간의 전역적 의존성을 Attention Mechanism만으로 처리한다.
Transformer는 병렬 처리를 훨씬 더 효율적으로 수행할 수 있으며, 8개의 GPU에서 12시간만 학습해도 SOTA를 달성할 수 있다.
🔹Model architecture
- Transformer는 RNN이나 CNN을 전혀 사용하지 않는다. → Positional Encoding을 사용한다.
- 인코더와 디코더로 구성된다. → Attention 과정을 여러 레이어에서 반복한다.
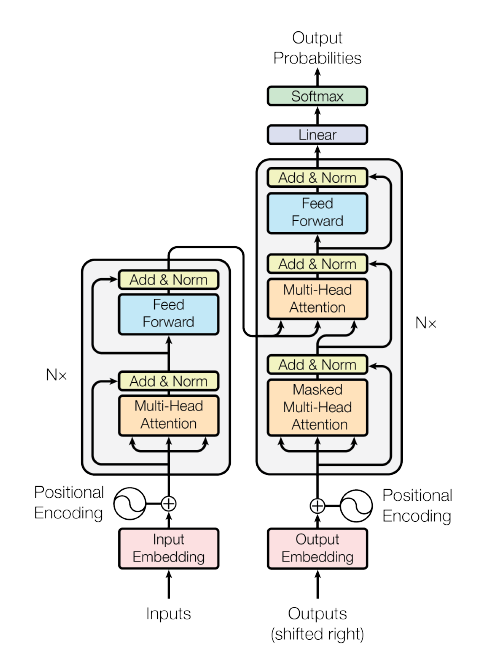
Transformer의 구조는 다음과 같고 하나씩 자세히 살펴보도록 하겠다.
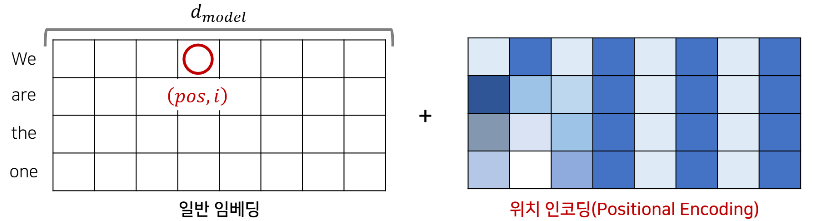
🔻입력 값 임베딩(Embedding)
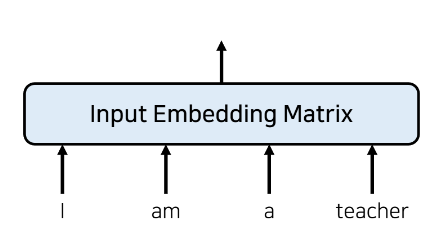
Transforemr 이전에는 해당 그림과 같은 전통적인 임베딩을 사용했다. 하지만 Transformer 모델은 RNN을 사용하지 않기 때문에 위치 정보를 포함하고 있는 임베딩을 사용해야 한다.
(RNN을 사용하면 들어갈 때 이미 순서 정보를 가지고 있기 때문이다.)
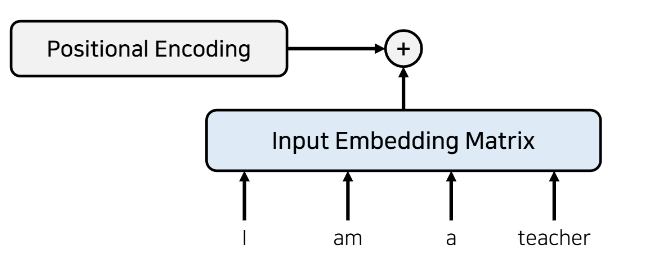
Transformer에서는 해당 그림처럼 Input embedding matrix와 같은 크기를 가지는 정보로, 위치 정보를 포함하고 있는 임베딩을 사용해야 한다.
🔻 Encoder
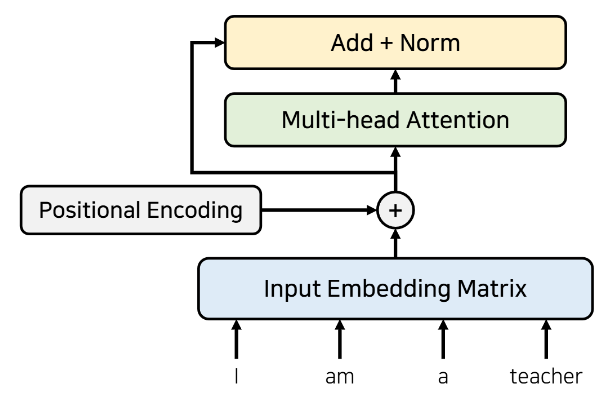
임베딩이 끝난 이후 Attention을 진행한다.
- 각각의 단어가 서로에게 어떤 연관성을 가지고 있는지 구하기 위해 사용 → Self Attention
- 문맥에 대한 정보를 잘 학습하는 역할로 사용 → Multi-head Attention
- 성능 향상을 위해 잔여 학습(Residual Learning)을 사용한다.
- 추가적으로 잔여된 부분만 학습하도록 만들기 때문에 학습 난이도가 낮고, 초기 모델 수렴 속도가 빠르다.
→ 이로 인해, 더욱 더 global optimal을 찾을 확률이 높아진다.
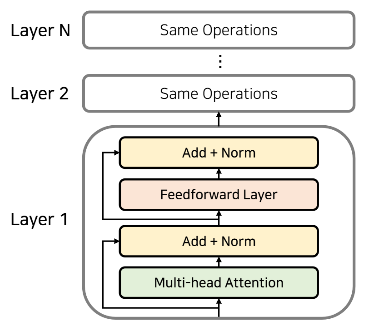
- 인코더는 Attention을 수행하여 나온 값과 residual connection을 이용하여 더해진 값을 받아서 normalization을 수행한다.
- 어텐션(Attention)과 정규화(Normalization) 과정을 다음 그림과 같이 반복한다.
- 각 레이어는 서로 다른 파라미터를 가진다.
🔻 Decoder
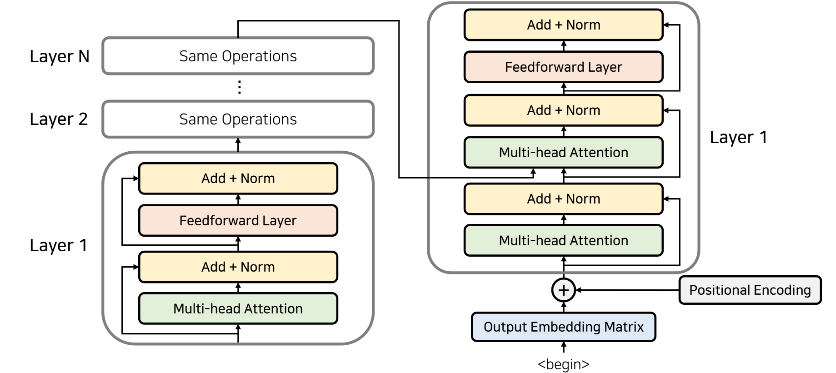
Encoder의 마지막 Layer에서 나오게 된 출력값을 매번 Decoder Layer에 넣어주는 방식이다.
- Decoder의 경우 Encoder와 마찬가지로 positional Encoding 진행
- Decoder Layer에서는 두 개의 Attention을 사용한다.
- self attention: Self attention이 진행되고 Encoder와 마찬가지로 각각의 단어들이 서로가 서로에게 어떠한 가중치를 가지는지 구하도록 하여 전반적인 표현 학습 진행
- Multi-head Attention: Encoder-Decoder Attention이 진행되고 encoder에 대한 정보를 attention 할 수 있도록 한다.
다음은 일 때의 예시이다.
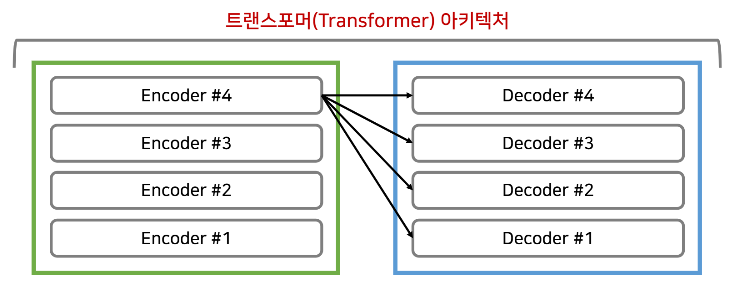
- 일반적으로 인코더와 디코더의 개수는 동일하다.
🔻 Attention
인코더와 디코더는 Multi-Head Attention 레이어를 사용한다.
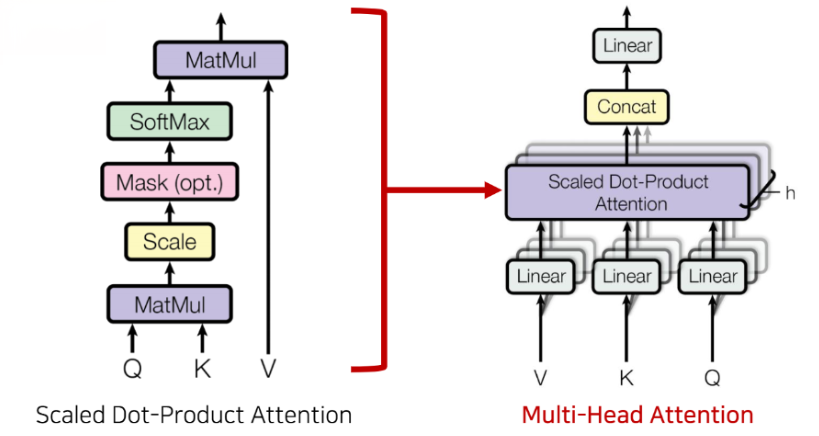
<어텐션을 위한 세 가지 입력 요소>
- 쿼리(Query) - 물어보는 주체
- 키(Key) - 물어보는 대상
- 값(Value)
ex) I am a teacher → I가 각각의 단어에 미치는 영향을 알아보려 하면 I: 쿼리(Query) / I, am, a, teacher: 키(key)
해당 그림에서 Q는 주체 = 대상이다.
- 우선, Scaled Dot-Product Attention 행렬곱을 진행한다.
- 그 다음, Scale을 진행한다.
- 필요시 Mask을 진행한다.
- 상대적 가중치/비율을 알 수 있는 SoftMax를 사용한다.
- 상대값 x value를 통해 Attention value를 구한다.

해당 수식을 간단히 설명해보자면, 는 Attention value이다.
- Query와 Key를 곱해서 각 Query에 대해서 Key에 대한 에너지 값을 구할 수 있다.
- scale factor인 로 나누는 이유는 softmax 함수가 가지는 특성상 0근처에서 gradient가 높게 형성되지만 값이 들쭉날쭉 하므로 기울기 값이 많이 줄어들기 때문에 gradient Vanishing 문제를 피하기 위해서다.
- 입력으로 들어오는 각각의 값에 대해서 서로 다른 linear layer를 가지도록 만들어서 h개의 서로 다른 key, query, value 값을 만들도록 한다.
🔻Query, Key, Value
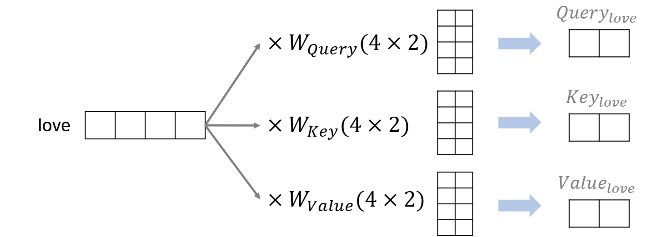
어텐션을 위해 Query, Key, Value가 필요하다. 각 단어의 임베딩을 이용해 생성할 수 있다.
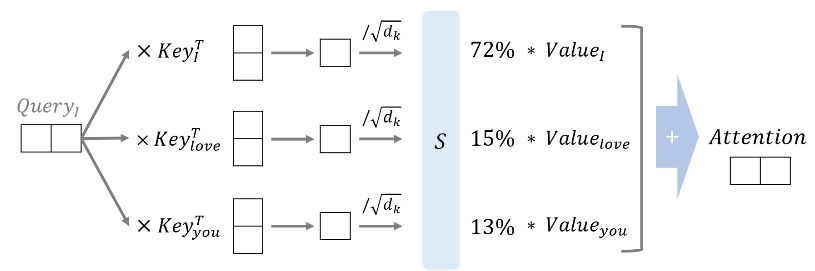
해당 그림처럼 Query와 Key값을 곱한 후, 스케일링을 진행한다. 그 후 softmax 함수로 변환하고 value값을 구해 Attention을 구한다.
실제로는 행렬(matrix) 곱셈 연산을 이용해 한꺼번에 연산이 가능하다.
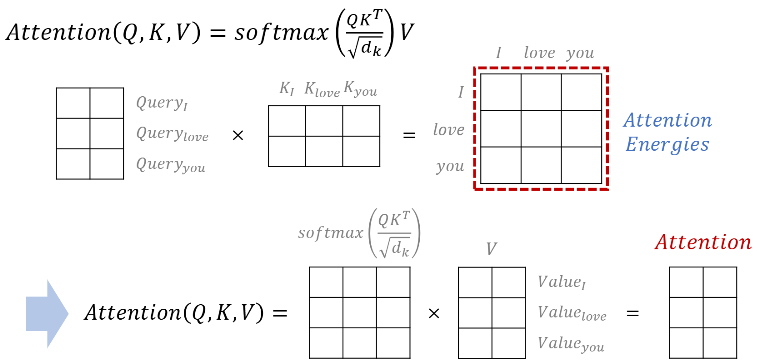
이를 하나의 그림으로 나타내면 다음과 같다.
🔻Scaled Dot - Product Attention
mask matrix를 이용해 특정 단어는 무시할 수 있도록 한다.
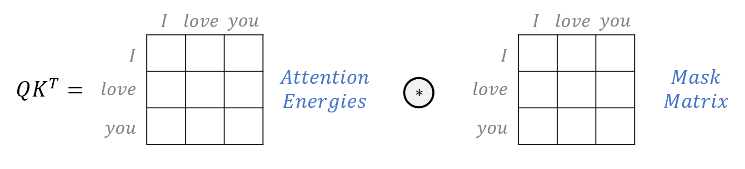
→ 마스크 값으로 음수 무한의 값을 넣어 softmax 함수의 출력이 0%에 가까워지도록 한다.
🔻Multi-Head Attention
수식은 다음과 같다.
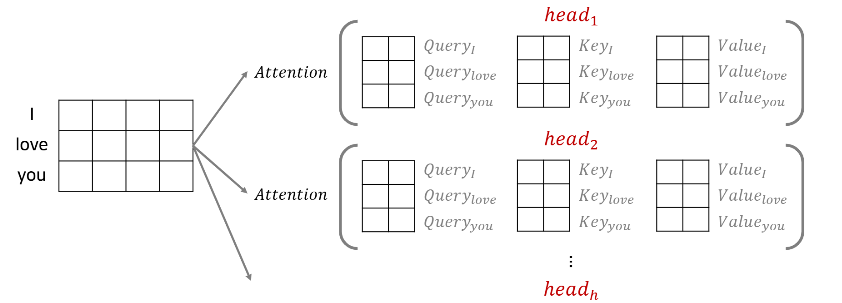
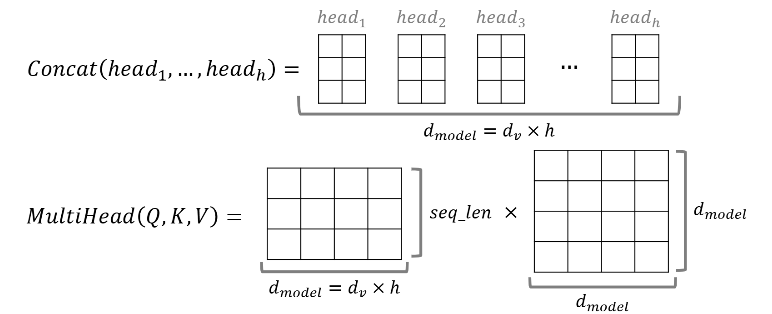
를 수행한 뒤에도 차원은 동일하게 유지
⭐ Transformer - Attention
Transformer에는 세 가지 종류의 Attention 레이어가 사용된다.
1. Encoder Self-Attention → 각각의 단어가 서로에게 어떠한 연관성을 가지는지를 Attention을 통해 구하도록 한다.
2. Masked Decoder Self-Attention → 각각의 출력 단어가 모든 출력 단어를 참고하도록 만들지 않고 앞쪽에 등장했던 단어들만 참고
3. Encoder - Decoder Attention → Query가 디코더에 있고 각각의 key value는 인코더에 있는 상황
※ Multi-Head Attention은 항상 사용된다.
🔻Positional Encoding
Positional Encoding은 다음과 같이 주기 함수를 활용한 공식을 사용한다.
각 단어의 상대적인 위치 정보를 네트워크에게 입력한다.
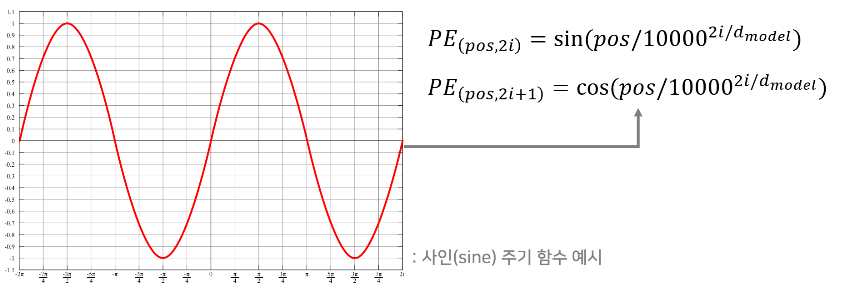
Positional Encoding은 다음과 같이 주기 함수를 활용한 공식을 사용한다.
🔹 Training
해당 부분에서는 논문의 모델을 학습시킬 때 사용한 방식에 대해 설명한다.
🔻Training Data and Batching
<WMT 2014 영어-독일어 데이터셋>
- 약 450만 개의 문장 쌍으로 구성
- 문장들은 Byte-Pair Encoding(BPE)를 통해 인코딩
- 소스와 타깃이 공유하는 약 37,000개의 토큰으로 구성된 단어 집합을 사용했다.
<WMT 2014 영어-프랑스어 데이터셋>
- 훨씬 큰 규모의 데이터셋을 사용
- 32,000개의 word-piece 토큰으로 분할했다.
문장 쌍들은 시퀀스 길이가 비슷한 것끼리 묶어 batch를 구성했다.
각 학습 배치는 약 25,000개의 소스 토큰과 25,000개의 타깃 토큰을 포함했다.
🔻Hardware and Schedule
모델은 NVIDIA P100 GPU 8개가 장착된 하나의 머신에서 학습되었다.
- 기본(base) 모델
→ 각 학습 스텝은 약 0.4초 소요, 총 100,000 스텝 또는 12시간 동안 학습을 진행- 대형(big) 모델
→ 각 학습 스텝은 1.0초가 소요, 총 300,000 스텝 또는 3.5일 동안 학습을 진행
🔻Optimizer
저자는 Adam 옵티마이저를 사용했으며, 의 값을 설정하였다.
학습률(learning rate)은 아래 수식에 따라 학습 과정 중 동적으로 조정되었다.
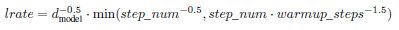
해당 수식의 의미는 다음과 같다.
- 학습 초반 warmup_steps 동안에는 선형적으로 학습률을 증가시킨다.
- 그 이후부터는 스텝 수의 역제곱근에 비례해 학습률을 감소시킨다.
→ warmup_steps = 4000으로 설정
🔻 Regularization
- 잔차 드롭아웃(Residual Dropout)
- 각 sub-layer의 출력에 대해, 해당 출력을 입력에 더하고 정규화하기 전에 드롭아웃(dropout)을 적용한다.
- 인코더와 디코더 스택 모두에서 임베딩과 위치 인코딩의 합에도 드롭아웃 적용
- 레이블 스무딩(Label Smoothing)
- 학습 중, 저자는 레이블 스무딩 값을 로 설정했다.
- 이는 모델이 perplexity(혼란도)를 약화시키긴 하지만, 정확도와 BLEU 점수 향상에 기여한다.
🔹Results
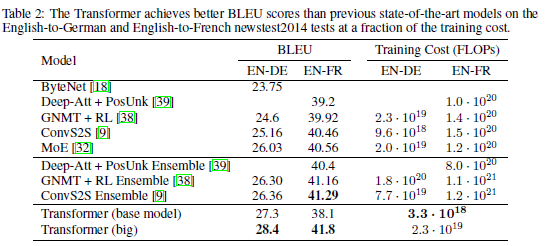
🔻Machine Translation
- WMT 2014 영어 - 독일어 번역
대형 Transformer 모델은 기존에 보고된 최고 성능모델들(앙상블 포함)보다 BLEU 점수 기준 2.0 높은 성능을 기록한다. → SOTA 달성
모델의 구성은 8개의 P100 GPU에서 3.5일 간 학습되었다. → 심지어 기본(base) 모델 조차도 이전에 발표된 모든 단일 모델 및 앙상블보다 뛰어난 성능을 보이며, 경쟁 모델 대비 훨씬 낮은 학습 비용으로 성능을 달성하였다.
- WMT 2014 영어 - 프랑스어 번역
대형 Transformer 모델이 BLEU 점수 41.0을 기록
이전까지 발표된 모든 단일 모델들보다 우수한 성능을 보였다.
🔹Conclusion
Transformer는 Attention만을 기반으로 한 최초의 시퀀스 변환 모델이며, 기존의 인코더-디코더 구조에서 흔히 사용되던 순환 레이어를 Multi-Head Self-Attention으로 대체하였다.
번역 과제에 있어서, Transformer는 순환 또는 합성곱 레이어 기반 아키텍처보다 훨씬 빠르게 학습 가능하고, WMT 2014 영어-독일어 및 영어-프랑스어 번역 과제 모두에서 Transformer는 SOTA를 달성하였다.
👀 My thoughts
- "Attention Is All You Need"는 여러번 공부할수록 전에 이해하지 못했던 부분을 이해하는 것 같아 반복적으로 공부해야겠다는 생각이 들었다.
- Transformer 모델을 어떻게 구상했을까? 라는 의문이 들었다.
참고로, Transformer에 대해 이해하기 위해서 혼자 여러 강의를 찾아보았지만 "나동빈님의 https://www.youtube.com/watch?v=AA621UofTUA 유튜브"가 가장 이해하기 좋았고, 해당 논문 설명과 사진은 나동빈님의 설명을 참고한 것이다.
혹시 Transformer를 처음 배우시거나, 까먹으신 분들은 해당 유튜브를 참고하시는 것을 추천드린다!
자료 출처: https://github.com/ndb796/Deep-Learning-Paper-Review-and-Practice/blob/master/lecture_notes/Transformer.pdf
