[논문 리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
NLP
💡NLP에서의 사전 훈련(Pre-training)
"사전 훈련된 단어 임베딩이 모든 NLP 실무자의 도구 상자에서 사전 훈련된 언어 모델로 대체 되는 것은 시간 문제이다."
- 세바스찬 루더
BERT(Bidirectional Encoder Representations from Transformers)와 같은 트랜스포머 계열이 자연어 처리를 지배했던 19년과 20년을 회고하면 이 말은 이미 현실이 되었다.
BERT 논문을 들어가기 전에 ELMo, 그리고 트랜스포머에 이르기까지 자연어 처리가 발전되어온 흐름을 정리해보자.
✔ 사전 훈련된 워드 임베딩
앞서 Word2Vec, Glove와 같은 워드 임베딩 방법론에 대한 논문 리뷰를 진행했다. (논문 리뷰 참조)
어떤 태스크를 수행할 때, 임베딩을 사용하는 방법으로는 크게 두 가지가 있다.
- 임베딩 층(Embedding layer)을 랜덤 초기화하여 처음부터 학습하는 방법
- 방대한 데이터로 Word2Vec 등과 같은 임베딩 알고리즘으로 사전에 학습된 임베딩 벡터들을 가져와 사용하는 방법
-> 태스크에 사용하기 위한 데이터가 적다면, 사전 훈련된 임베딩을 사용하면 성능 향상을 기대
✔ 사전 훈련된 언어 모델
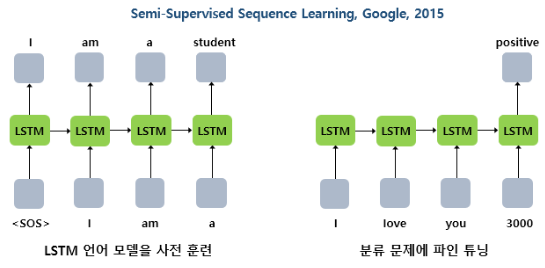
2015년 구글은 'Semi-supervised Sequence Learning' 라는 논문에서 LSTM 언어 모델을 학습하고나서 이렇게 학습한 LSTM을 텍스트 분류에 추가 학습하는 방법을 발표했다.
1. 우선 LSTM 언어 모델 학습
언어 모델은 주어진 텍스트로부터 이전 단어들로부터 다음 단어를 예측하도록 학습하므로 기본적으로 별도의 레이블이 부착되지 않은 텍스트 데이터로도 학습 가능 & 사람이 별도로 레이블 지정 x
2. 레이블이 없는 데이터로 학습된 LSTM과 가중치가 랜덤으로 초기화 된 LSTM 두 가지를 두고, 텍스트 분류와 같은 문제를 학습
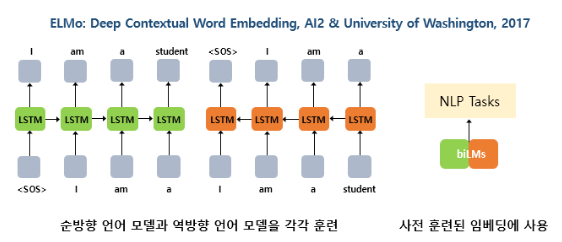
2017년에 발표된 ELMo는 순방향 언어 모델과 역방향 언어 모델을 각각 따로 학습시킨 후에, 이렇게 사전 학습된 언어 모델로부터 임베딩 값을 얻는다는 아이디어이다.
- 임베딩은 문맥에 따라서 임베딩 벡터값이 달라짐
-> Word2Vec이나 GloVe를 사용했을 때, 다의어를 구분할 수 없다는 문제점 해결
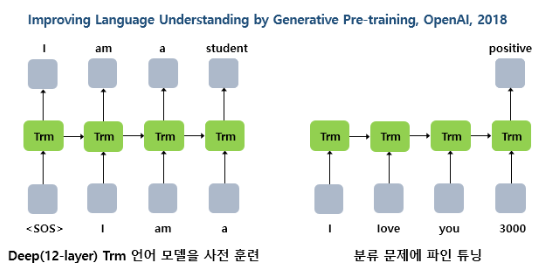
LSTM이 아닌 트랜스포머로 사전 훈련된 언어 모델을 학습하려는 시도가 등장했다.
- 트랜스포머의 디코더는 LSTM 언어 모델처럼 순차적으로 이전 단어들로부터 다음 단어를 예측
- Open AI는 GPT-1에 여러 다양한 태스크를 위해 추가 학습을 진행하였을 때, 다양한 태스크에서 높은 성능을 얻을 수 있음을 입증
사전 훈련된 언어 모델을 만들고 이를 특정 태스크에 추가 학습시켜 해당 태스크에서 높은 성능을 얻는 것으로 접어들었고, 언어 모델의 학습 방법에 변화를 주는 모델들이 등장
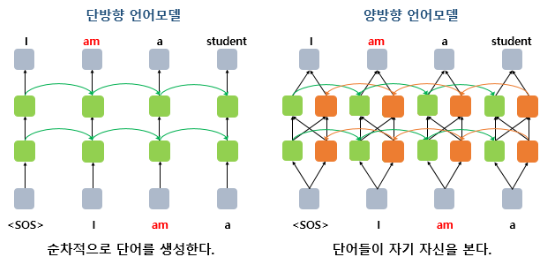
좌측은 전형적인 언어 모델, 우측에 있는 양방향 언어 모델은 지금까지 본 적 없던 형태의 언어 모델
- 실제로 우측과 같이 구현하는 경우는 거의 없다.
-> 이미 예측해야하는 단어를 역방향 언어 모델을 통해 미리 관측하게 됨- 하지만 언어의 문맥은 실제로 양방향
✔ Masked Language Model
양방향 구조를 도입하기 위해 생긴 언어 모델
- 입력 텍스트의 단어 집합의 15%의 단어를 랜덤으로 마스킹(Masking)
- 인공 신경망에게 이렇게 마스킹 된 단어들을 예측하도록 함.
✅ BERT는 Word2Vec, GloVe 등의 정적인 워드 임베딩과 LSTM 기반 언어 모델의 한계를 극복하기 위해 개발
✅ BERT는 트랜스포머 구조를 활용하여 양방향 문맥 정보를 학습하며, Masked Language Model(MLM)과 Next Sentence Prediction(NSP)을 통한 사전 훈련을 거쳐 다양한 NLP 태스크에서 뛰어난 성능을 보이는 모델
📖 논문으로
🔹Abstract
저자는 BERT(Bidirectional Encoder Representations from Transformers)라는 새로운 언어 표현 모델을 소개한다.
최근의 언어 표현 모델과 달리, BERT는 모든 계층에서 좌우 문맥을 동시에 고려하도록 설계되어, 레이블이 없는 텍스트로부터 깊은 양방향 표현을 사전 훈련 할 수 있다.
<사전 훈련된 BERT 모델>
- 하나의 추가 출력 계층만으로도 미세 조정(finetuning) 할 수 있다.
- 질문 응답(question answering) 및 언어 추론(language inference)과 같은 NLP의 다양한 주요 task(총 11개)에서 SOTA
🔹Introduction
✔ 언어 모델 사전 훈련은 다양한 자연어 처리 작업의 성능 향상에 효과적이라는 것이 입증되었다.
-
문장을 전체적으로 분석하여 문장 간 관계를 예측하는 자연어 추론 및 패러프레이징 (문장 수준 태스크)
-
개체명 인식 및 질문 응답 (토큰 수준 태스크)
🔍 사전 훈련된 언어 표현
- 특징 기반(feature-based) 접근법
- ELMo는 사전 훈련된 표현을 추가적인 특징으로 포함하는 태스크별 아키텍처 활용
- 미세 조정(fine-tuning) 접근법
- Generative Pre-trained Transformer(OpenAI GPT)는 최소한의 태스크별 매개변수를 추가하며, 모든 사전 훈련된 매개변수를 단순히 미세 조정하는 방식으로 downstream task에 학습
- 두 접근법은 사전 훈련 과정에서 일반적인 언어 표현을 학습하기 위해 단방향(unidirectional) 언어 모델을 사용한다는 동일한 목적 함수를 공유한다.
⚠️ 한계점: 표준 언어 모델이 단방향이라는 점
현재 기술이 특히 미세 조정 접근법에서 사전 훈련된 표현의 활용 가능성을 제한한다고 주장
-> 이로 인해 사전 훈련 과정에서 사용할 수 있는 아키텍처의 선택이 제한
<OpenAI - GPT>
트랜스포머의 self-attention 계층에서 각 토큰이 이전 토큰들만을 참조할 수 있는 좌에서 우(left-to-right) 아키텍처를 사용
-> 질문 응답과 같은 토큰 수준 태스크에서는 양방향 문맥을 포함하는 것이 필수적이므로 성능 저하로 이어짐
⭐ BERT
미세 조정 기반 접근법을 개선하기 위해 BERT를 제안한다.
- 15%의 단어를 마스킹하고, 모델은 이 마스킹된 단어를 문맥을 기반으로 예측하는 방식으로 학습
- 좌에서 우로만 학습되는 기존 언어 모델과 달리, MLM은 좌우 문맥을 모두 활용한 표현 학습을 가능하게 함
- Next sentence prediction(NSP) 태스크를 추가하여 텍스트 쌍 표현을 함께 사전 훈련
🔹Related Work
일반적인 언어 표현을 사전 훈련하는 연구는 오랜 역사를 가지고 있으며, 해당 절에서는 가장 널리 사용되는 접근법들을 검토한다.
🔻Unsupervised Feature-based Approaches
보편적으로 활용할 수 있는 단어 표현을 학습하는 것은 수십 년간 활발히 연구되어 온 주제이며, 비신경망(non-neural)방법과 신경망(neural) 방법을 포함한다.
사전 훈련된 단어 임베딩은 현대 NLP 시스템에서 중요한 구성 요소이며, 초기화된 상태에서 학습한 임베딩보다 뛰어난 성능을 제공한다.
- 좌에서 우로 예측하는 언어 모델링 목표
- 좌우 문맥에서 올바른 단어와 잘못된 단어를 구별하는 목표가 사용
-> 이러한 접근법은 문장 임베딩 및 문단 임베딩으로 확장되었다.- 문장 표현 학습
-> 이전 문장의 표현을 이용해 다음 문장의 단어들을 생성하는 좌에서 우 방식의 목표 or denoising autoencoder 기반 목표를 사용했다.
ELMo와 그 전신은 기존 단어 임베딩 연구를 다른 차원에서 일반화한 모델
- 좌에서 우로 학습된 언어 모델과 우에서 좌로 학습된 언어 모델에서 문맥에 따라 변화하는 특징을 추출
- ELMo를 기존의 태스크별 아키텍처와 결합
-> 질문 응답, 감성 분석, 개체명 인식과 같은 여러 주요 NLP 벤치마크에서 최고 성능 달성
🔻Unsupervised Fine-tuning Approaches
특징 기반 접근법과 마찬가지로, 초기 연구들은 레이블이 없는 텍스트에서 단어 임베딩 매개변수만 사전 훈련하는 방식 사용
-> 최근에 문장 또는 문서 인코더 등장
- 레이블이 없는 텍스트에서 문맥적 토큰 표현을 사전 훈련한 후, supervised 다운스트림 태스크를 위해 미세 조정하는 방식
-> 처음부터 학습해야 할 매개변수의 수가 적다는 장점- 사전 훈련을 위해 좌에서 우로 예측하는 언어 모델링 목표와 auto-encoder 목표가 사용
🔻Transfer Learning from Supervised Data
대규모 데이터셋을 활용한 지도 학습 태스크에서 효과적인 전이 학습이 가능
(ex. 자연어 추론, 기계 번역)
또한, 컴퓨터 비전 연구에서도 대규모 사전 훈련된 모델로부터 전이 학습이 중요함이 입증
(ex. ImageNet에서 사전 훈련된 모델을 fine-tuning하는 방식)
🔹BERT
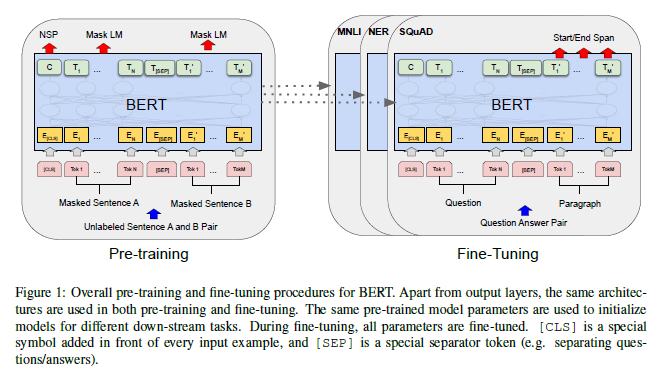
BERT의 프레임워크는 두 단계로 구성된다.
✅ 사전 훈련(pre-training)
unlabeled data를 활용하여 다양한 사전 훈련 태스크를 수행하며 학습
✅ 미세 조정(fine-tuning)
pre-trained parameters를 이용하여 BERT 모델을 초기화한 후, 다운스트림 태스크에서 제공되는 labeled data를 사용하여 모든 매개변수를 미세 조정
BERT의 특징 중 하나는 사전 훈련된 모델과 최종 다운스트림 태스크 모델 간의 차이가 최소화 된다는 점이다.
🔻Model Architecture
⭐ BERT 아키텍처: multi-layer bidirectional Transformer encoder
✔ 모델 하이퍼 파라미터
- L: 레이어(layer, 즉 트랜스포머 블록)의 개수
- H: 히든(Hidden) 크기
- A: 자기 주의(self-attention) 헤드 개수
✔ BERT 사용 모델
- BERTBASE: L = 12, H = 768, A = 12
-> 총 매개변수 수 = 110M - BERTLARGE: L = 24, H = 1024, A = 16
-> 총 매개변수 수 = 340M
BERTBASE vs GPT(동일한 모델 크기를 갖도록 설정)
- BERT의 트랜스포머는 양방향(self-attention) 사용
- GPT의 트랜스포머는 제한된(self-attentino) 기법을 사용하여 각 토큰이 왼쪽(이전) 문맥만을 참고할 수 있도록 설계
🔻Input/Output Representation
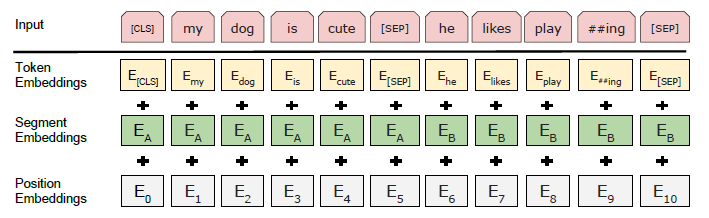
BERT는 다양한 다운스트림 태스크를 처리할 수 있도록 설계되었으며, 입력 표현 방식에서 단일 문장(single sentence)과 문장 쌍(sentence pair, 예: (질문, 답변))을 명확하게 표현할 수 있도록 구성
- 본 논문에서 "문장(sentence)"은 실제 언어적 의미의 문장이 아니라, 연속된 텍스트를 의미
- "시퀀스(sequence)"는 BERT의 입력 토큰 시퀀스를 의미하며, 단일 문장 또는 두개의 문장이 함께 포함
BERT는 WordPiece 임베딩 방식을 사용하며, 30,000개의 토큰으로 구성된 어휘(vocabulary)를 갖는다.
- 모든 입력 시퀀스의 첫 번째 토큰은 [CLS] (분류토큰, classification token)로 설정
- 최종 은닉 상태(hidden state) 중 [CLS] 토큰에 해당하는 벡터는 문맥을 포함한 전체 시퀀스 표현으로 활용되며, 분류 태스크에서 사용
- 문장 쌍(sentence pair)은 하나의 시퀀스로 결합하여 입력된다.
-> 이를 구별하기 위해 두 가지 방법 적용- [SEP] (분리토큰, separator token)을 추가하여 문장 경계를 구분
- 각 토큰에 학습된 segment 임베딩을 추가하여 해당 토큰이 문장 A 또는 문장 B에 속하는지 표시
<입력 임베딩>
- E: 입력 임베딩(input embedding)
- C: 특수 토큰 [CLS]의 최종 은닉 벡터, 크기는
- Tᵢ: 입력 토큰 의 최종 은닉 벡터, 크기는
특정 토큰의 입력 표현은 해당 토큰 임베딩(token embedding), 세그먼트 임베딩(segment embedding), 위치 임베딩(position embedding)을 합하여 구성된다.
🔹Pre-training BERT
전통적인 left-to-right/right-to-left LM을 사용해서 pre-train하는 ELMo, GPT와는 다르게, BERT는 2개의 unsupervised task 이용해서 학습
🔻Task #1: Masked LM
직관적으로, 깊은 양방향 모델이 좌에서 우 모델 또는 좌우 모델을 단순 연결한 얕은 모델보다 더 강력할 것이라고 보는 것이 합리적이다.
그러나 기존의 conditional language models는 좌에서 우, 우에서 좌 방향으로만 학습 가능하다. 이는 양방향 조건을 적용할 경우, 각 단어가 간접적으로 "see itself"와 다층 컨텍스트에서 목표 단어를 쉽게 예측할 수 있는 문제 발생한다.
Masked Language Model (MLM) 학습 방식
- 깊은 양방향 표현을 학습하기 위해, 저자는 단순히 입력 토큰 중 일부를 임의로 마스킹(masking)하고, 해당 마스킹된 토큰을 예측하도록 모델을 학습(Masked LM, MLM, Cloze 태스크)
- 마스킹된 토큰에 해당하는 최종 은닉 벡터(hidden vectors)는 소프트맥스 출력을 거쳐 어휘 집합에서 정답을 예측하는 방식으로 학습
(※ 각 시퀀스 내 WordPiece 토큰의 15%를 임의로 마스킹)
⚠️ Pre-training과 Fine-tuning의 불일치
해당 방식을 통해 양방향 사전 훈련 모델을 얻을 수 있지만, 사전 훈련(pre-training)과 미세 조정(fine-tuning) 간의 불일치 문제가 발생할 수 있다.
-> 이는 [MASK] 토큰이 미세 조정 과정에서는 나타나지 않기 때문
✨항상 [MASK] 토큰으로 대체하지 않음
- 학습 데이터 생성 과정에서, 각 시퀀스에서 예측할 15%의 토큰 위치를 무작위로 선택
1. 80% 확률로 [MASK] 토큰으로 대체
2. 10% 확률로 랜덤한 토큰으로 대체
3. 10% 확률로 기존 토큰 사용
-> 그 후, 는 원래의 정답 토큰을 예측하도록 학습되며, 최종적으로 cross-entrophy loss를 사용해서 기존의 토큰을 예측하도록 학습
🔻Task #2: Next sentence Prediction(NSP)
질문 응답(Question Answering, QA) 및 자연어 추론(Natural Language Inference, NLI)과 같은 중요한 다운스트림 태스크는 두 문장 간의 관계를 이해하는 능력을 필요로 한다. 그러나 기존 언어 모델링은 이러한 관계를 직접적으로 학습하지 않는다.
문장 간 관계를 이해하는 모델을 학습하기 위해, 우리는 단일 언어 코퍼스에서 손쉽게 생성할 수 있는 이진화된 다음 문장 예측(NSP) 태스크를 사전 훈련 과정에 포함했다.
<사전 훈련 예제에서 문장 A와 B를 선택>
- 50%의 확률로 B는 실제 문장 A의 다음 문장, 이 경우 "IsNext"로 라벨링
- 50%의 확률로 B는 코퍼스에서 무작위로 선택된 문장, 이 경우 "NotNext"로 라벨링
-> [CLS] 토큰에 해당하는 벡터 C는 NSP 태스크에서 문장 관계를 예측하는 데 사용
이 방법은 단순하지만, QA와 NLI 태스크에서 매우 효과적인 사전 훈련 기법이다.
기존 연구에서는 문장 임베딩(sentence embedding)만을 다운스트림 태스크에 전이하는 방식이었다면, BERT는 모든 모델 매개변수를 전이하여 최종 태스크 모델의 초기화에 활용한다는 점에서 차별화됨
🔻Pre-training Data
BERT의 사전 훈련 절차는 기존 언어 모델 사전 훈련 연구의 방식을 크게 따른다.
텍스트
- BooksCorpus (zhu et al., 2015) - 총 8억(800M) 단어
- 영어 위키백과(English Wikipedia) - 총 25억(2,500M) 단어
- 위키백과에서는 텍스트 본문만 추출하며 목록, 표, 헤더는 제외
- 문서 단위 코퍼스 사용 하는 것이 중요
* Billion Word Benchmark(chelba et al., 2013)와 같이 문장이 섞인 코퍼스는 긴 연속된 시퀀스를 학습하는 데 적합하지 않아 사용 X
🔹 Fine-tuning BERT
Fine-tuning은 비교적 간단하다.
Transformer의 self-attention 매커니즘이 단일 텍스트 또는 텍스트 쌍과 관련된 다양한 다운스트림 태스크를 처리할 수 있도록 설계
일반적으로 텍스트 쌍을 처리하는 방식
- 기존 방법에서 각 문장을 개별적으로 인코딩한 후, 양방향 교차 주의를 적용하는 방식이 흔히 사용
- 두 단계를 통합하여 처리
- self-attention을 이용하여 하나의 인코딩 과정에서 문장 쌍 간의 양방향 교차 주의를 포함
- 즉, self-attention을 통해 결합된 문장을 인코딩하면, 문장 간 교차 정보를 자연스럽게 학습
BERT의 입력과 출력을 태스크별 요구사항에 맞게 연결한 후, 모든 매개변수를 end-to-end 방식으로 미세 조정
<입력(input)>
1. paraphrasing: 문장 쌍(sentence pairs)
2. entailment: 가설-전제 쌍
3. 질문 응답(question answering): 질문-지문 쌍
4. 텍스트 분류 or 시퀀스 태킹: 텍스트-? 형태의 단일 입력
<출력(output)>
- 토큰 수준 태스크(시퀀스 태깅, 질문 응답): 각 토큰의 표현을 출력층에 전달
- 문장 수준 태스크(함의, 감성 분석): [CLS] 토큰의 표현을 출력층에 전달
🔹Experiments
BERT를 11가지 NLP task에서 fine-tuning한 실험 결과
🔻GLUE
GLUE 벤치마크는 다양한 자연어 이해(NLU) 태스크들로 구성된 평가 지표
- 8개 task: MNLI, QQP, QNLI, STS-B, MRPC, RTE, SST-2, CoLA
- classification task에서만 label의 개수에 따른 layer weights 파라미터 추가
- batch size = 32, epochs = 3
- learning rate = [5e-5, 4e-5, 3e-5, 2e-5]
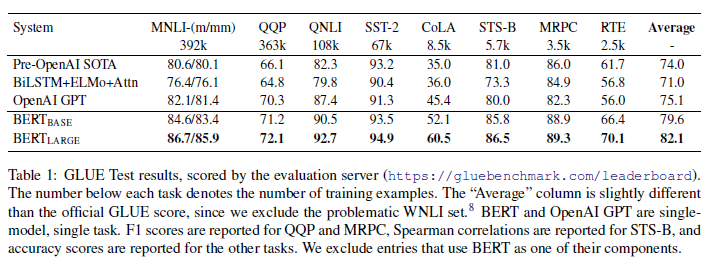
- BERTLARGE와 BERTBASE 모두 GLUE의 모든 task에서 기존 모델보다 좋은 성능을 보이며 SOTA
- BERTLARGE가 BERTBASE에 비해 훨씬 더 좋은 성능(특히 학습 데이터의 크기가 작은 경우 BERTLARGE 성능이 더 좋음)
🔻SQuAD v1.1
SQuAD v1.1은 100,000개의 질문-답변 쌍으로 구성된 데이터셋
- 주어진 질문과 정답을 포함하는 위키백과(Wikipedia) 지문을 입력으로 받음
* 정답 텍스트 스팩(answer text span)을 지문 내에서 정확하게 예측하는 것이 목표
<질문과 지문>
- 질문(question)은 A임베딩 사용
- 지문(passage)은 B 임베딩 사용
- 시작 벡터(start vector):
- 끝 벡터(end vector):
<정답 예측 방식>
각 단어가 정답 span의 시작 또는 끝이 될 확률 예측
- 정답이 시작될 확률:
- 정답이 끝날 확률: 동일한 방식으로 끝 벡터 E를 활용하여 계산
- 정답 span score
시작 위치 i부터 끝 위치 j까지의 후보 span score:
<미세조정 설정>
- epochs: 3
- 학습률(learning rate): 5e-5
- 배치 크기(batch size): 32
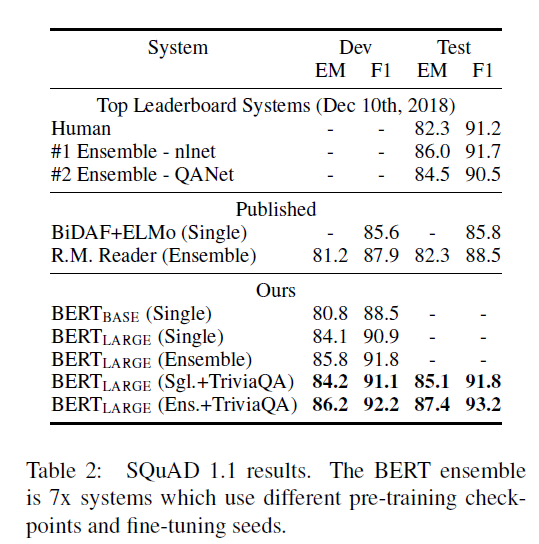
🔻SQuAD 2.0
SQuAD 2.0 태스크는 SQuAD 1.1 문제 정의를 확장하여, 제공된 문단에 짧은 정답이 존재하지 않을 가능성을 포함하도록 함
- 정답이 없는 질문의 경우
-> 해당 질문을 [CLS] 토큰의 시작과 끝 위치가 answer span인 경우로 처리 - 시작 및 끝 위치의 확률 공간을 확장하여 [CLS] 토큰의 위치를 포함하도록 변경
<정답 예측 방식>
- 정답이 없는 경우(No-answer span)의 점수
- 정답이 있는 경우(Best non-null span)의 점수
- 정답 예측 방식:
- 인 경우 정답이 있는 것으로 예측
- 여기서 τ(임계값, threshold)는 개발 세트(dev set)에서 F1 점수를 최대화하도록 설정
<미세조정 설정>
- TriviaQA 데이터는 사용X
- 에포크: 2
- 학습률(learning rate): 5e-5
- 배치 크기(batch size): 48
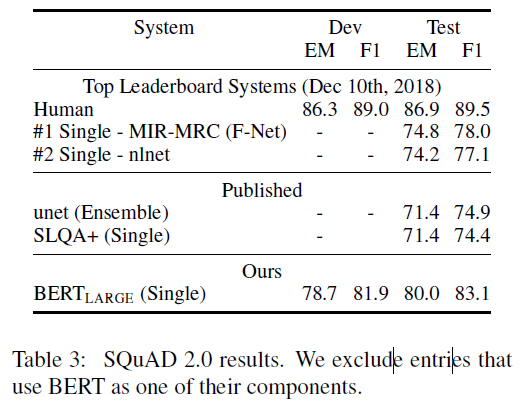
🔻SWAG
SWAG 데이터셋은 113,000개의 문장 쌍 완성(sentence-pair completion) 예제로 구성
- 현실적이고 상식적인 추론 능력을 평가하는 테스크
- 네 개의 선택지 중 가장 개연성이 높은 문장을 선택하는 것이 목표
<BERT 미세 조정>
- SWAG 데이터셋을 학습할 때, 각 문장과 네 개의 선택지를 조합하여 총 4개의 입력 시퀀스 생성
- 입력 시퀀스: 문장 A(주어진 문장) + 문장 B(후속 문장 후보)
- 태스크별로 추가된 유일한 매개변수는 하나의 벡터
- 이 벡터와 [CLS] 토큰의 표현 C간의 내적이 각 선택지의 점수를 나타냄
- 이후, softmax 계층을 적용하여 점수를 정규화
<미세 조정 설정>
- 에포크(epochs): 3
- 학습률(learning rate): 2e-5
- 배치 크기(batch size): 16
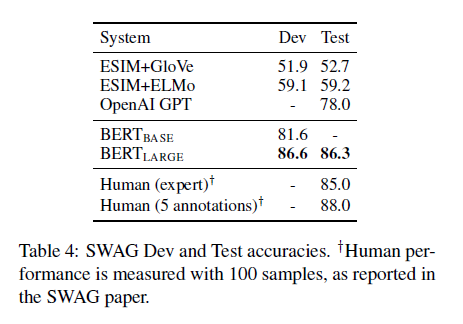
🔹Conclusion
최근 전이 학습(transfer learning)을 활용한 언어 모델이 뛰어난 성능을 보이며, 비지도 사전 훈련(unsupervised pre-training)이 NLP 시스템에서 필수적인 요소로 자리 잡고 있다.
⭐ 기존 연구는 단방향 아키텍처를 활용했지만, 본 논문은 이를 양방향 아키텍처로 확장하여 하나의 사전 훈련된 모델이 다양한 NLP 태스크를 해결할 수 있도록 하였다.
👀 My Thoughts
- 기존 언어 모델들이 단방향으로만 학습하던 한계를 극복하고, 양방향 학습을 통해 문맥을 더 잘 이해할 수 있도록 했다는 점이 인상적이었다.
- BERT 논문을 읽어보니 반복해서 설명해주는 내용이 많아서 이해하는 데 도움이 되었다.
