1. 개요
15단계에 걸쳐 ItemReader, ItemProcessor, ItemWriter에 대해 분석해보면서 Spring batch job 실행과정 중 Step을 구성하는 방안, 다양한 실무적 상황에 적용하기 위한 접근방법, 본질 및 개념 등에 대해 알아보았다.
더불어, ItemStream을 통한 자원관리 및 faultTolerance(Retry/Skip)에 대해서도 분석해보면서 기본적인 Step 구성에 이어 Step의 안정성과 신뢰성을 향상하기 위해 Spring batch에서 어떠한 도구, 장치들을 제안하고 있는지 이해하기도 하였다.
지금까지는 주어진 기능, Step에 대해 결과론적인 부분에 대해 살펴보았다면 이제부터는 Step의 세부적인 부분들, 과정론적인 관점에서 살펴보고자 한다.
Step은 Spring batch를 지탱하는 기둥과 같은 개념이고 batch 그 자체이기도 하기 때문에, 완전히 체득하기 위한 단계를 가져보고자 한다.
Spring Security와 같이 Spring batch도 엄연한 프레임워크의 일종이기도 하고, 기본적으로 프레임워크를 적용하기 위한 응용력을 함양하기 위해서는 Spring Security에서 했던 것처럼 단순 "제공도구, api"를 살펴보는 것을 넘어 내부적으로 어떠한 인터페이스, 메서드 호출 등을 거치는지 이해하는 과정이 필요하다.
Spring Batch Step에 대한 최종 분석을 진행하는 과정을 기록하고자 한다.
2. Step에 대한 고찰 1 - Step components
Step에서 제공하는 dsl api(Domain specified language)의 세부요소들에 대해 분석해보고자 하는데, 이제부터는 이를 "step을 구성하는 컴포넌트"로 의미부여를 할 것이다.
말 그대로 Step을 하나하나 파헤치는 과정에서, 결과론적인 접근(api)보다는 구성요소(components)로 이해하는 것이 더 적절하기 때문이다.
그 첫번째 단계는 StepBuilder이다.
- StepBuilder
최종적으로 반환해야 하는 형태인 StepBuilder를 먼저 살펴보면,

public class StepBuilder extends StepBuilderHelper<StepBuilder> {chunk 지향처리 뿐만 아니라, 모든 Step(any Step)에 대해 컴포넌트를 구성하기 위한 출발점(entry point)임을 알 수 있다.
return new StepBuilder("deathNoteWriteStep", jobRepository)
.<DeathNote, DeathNote>chunk(10, transactionManager)
.reader(deathNoteListReader)
.writer(deathNoteWriter)
.build();이에 대한 형태를 반환하기 위해, Step을 구성하기 위해서는 StepBuilder를 통해 Step을 Build하는 과정이 첫번째로 필요하며, 그 시작은 chunk 컴포넌트로 구성을 하는 것에서 비롯한다.
- chunk
public <I, O> SimpleStepBuilder<I, O> chunk(int chunkSize, PlatformTransactionManager transactionManager) {
return new SimpleStepBuilder<I, O>(this).transactionManager(transactionManager).chunk(chunkSize);
}chunk 컴포넌트를 살펴보면 위와 같이 step의 input, output 객체 타입을 지정해주고, SimpleStepBuilder를 반환해주는 것을 알 수 있다.
- SimpleStepBuilder

그 내부를 살펴보면, chunk 컴포넌트를 구성하여 SimpleStepBuilder를 반환하도록 되어있는데, SimpleStepBuilder는 chunk 지향처리 step을 구성하는 빌더이다.
주석에서 볼 수 있듯이 chunk oriented steps를 구성하기 위한 빌더이다.
참고로 tasklet 지향 처리를 한다면, TaskletStepBuilder를 사용하며, 내결함성을 활성화하였다면 SimpleStepBuilder를 상속한 FaultTolerantStepBuilder를 사용하게 된다.
- build
@Override
public TaskletStep build() {
registerStepListenerAsItemListener();
registerAsStreamsAndListeners(reader, processor, writer);
return super.build();
}지금까지 분석해왔던 컴포넌트들을 지나서 build()하는 컴포넌트를 살펴보면, 위와 같이 TaskletStep을 반환하는 형태로 빌더패턴을 종료하는 것을 알 수 있다.
TaskletStepBuilder에서 반환하는 최종 형태는 위와 같이 TaskletStep임을 확인할 수 있는데, 여기서 한가지 반전 사실이 존재한다.
tasklet 지향처리, chunk 지향처리 모두 TaskletStep이다.
다만 내부적으로 StepBuilder 구현체를 무엇을 사용하느냐에 따라, 어떠한 dsl api를 제공하는지가 결정되며, 본질적으로는 TaskletStep안에 주입된 Tasklet 구현체로 실행방식이 최종 결정되어 tasklet 지향방식일 것인지, chunk 지향방식일 것인지를 분기한다.
| 구분 | 역할 |
|---|---|
StepBuilder 구현체 | 설정 과정(DLS) 담당 |
TaskletStep | 실제 Step 실행 엔진 |
Tasklet 구현체 | 실행 전략 결정 (tasklet / chunk) |
이때 tasklet 구현체라 하면 tasklet 인터페이스를 구현한 클래스이며,
public interface Tasklet {
RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception;
}이를 Customized하게 구현한 tasklet 지향 처리의 tasklet인지
public class ZombieProcessCleanupTasklet implements Tasklet {혹은 Spring Batch가 내부적으로 생성해서 주입하는,
SimpleStepBuilder.build()
→ new ChunkOrientedTasklet(...)
→ step.setTasklet(ChunkOrientedTasklet)Reader/Processor/Writer로 구성되어 대규모 데이터 순차처리에 특화되어있는 chunk 지향 처리의 tasklet인지에 따라 해당 처리의 지향점이 결정된다.
참고로 chunk 지향처리 빌더의 구현체인 simpleStepBuilder를 살펴보면
StepBuilder
└─ AbstractTaskletStepBuilder
├─ TaskletStepBuilder
└─ SimpleStepBuilder (chunk 지향)위와 같이, AbstractTaskletStepBuilder를 상속받는 것을 알 수 있는데, tasklet 지향처리이든 chunk 지향처리이든 최종적으로는 TaskletStep을 반환한다.
결론은 청크지향처리, 태스크릿지향처리 모두 TaskletStep으로 같은 형태이다. 다만 내부 tasklet의 구현체가 다르다는 점을 기억하자.
3. Step에 대한 고찰 2 - TaskletStep의 최종 build 과정
태스크릿 지향처리, 청크 지향처리 모두 TaskletStep을 반환한다는 점, 그리고 내부적으로 Step 컴포넌트 구성, tasklet 구현체에 따른 지향점 분기 등에 따라 처리방법이 달라진다는 것을 알 수 있었다.
다음 단계는 taskletStep의 build() 과정이 최종적으로 어떻게 일어나는지에 대한 내용이다.
위에서 taskletStep을 반환하는 build 컴포넌트에 대해 잠깐 살펴보았는데, registerStepListenerAsItemListener();와 registerAsStreamsAndListeners(reader, processor, writer);를 거쳐 return super.build();까지 진행하는 양상이다.
- registerStepListenerAsItemListener();
protected void registerStepListenerAsItemListener() {
for (StepExecutionListener stepExecutionListener : properties.getStepExecutionListeners()) {
checkAndAddItemListener(stepExecutionListener);
}
for (ChunkListener chunkListener : this.chunkListeners) {
checkAndAddItemListener(chunkListener);
}
}StepBuilder가 최종 build()를 할때 가장 먼저, 빌더에 구성한 StepExecutionListener와 ChunkListener 구현체들을 순회하여, ChunkListener, ItemListener 들을 목록에 추가해주는 로직이다.
이 세부적인 과정을 살펴보도록 하자.
먼저, Chunk지향처리에서 사용하는 SimpleStepBuilder를 파헤쳐보면 stepExecutionListener와 ChunkListener를 순회하여 리스너를 등록하는 것을 볼 수 있다.
각각 살펴보자면,
- stepExecutionListener를 순회하는 경우
private void checkAndAddItemListener(StepListener stepListener) {
if (stepListener instanceof ItemReadListener) {
listener((ItemReadListener<I>) stepListener);
}
if (stepListener instanceof ItemProcessListener) {
listener((ItemProcessListener<I, O>) stepListener);
}
if (stepListener instanceof ItemWriteListener) {
listener((ItemWriteListener<O>) stepListener);
}
}위와 같이 StepExecutionListener를 순회하면서, 내부적으로 ItemListener의 타입을 구별하면서 item Listener를 등록해주는 과정을 확인할 수 있다.
- chunkListener를 순회하는 경우
private void checkAndAddItemListener(StepListener stepListener) {
if (stepListener instanceof ItemReadListener) {
listener((ItemReadListener<I>) stepListener);
}
if (stepListener instanceof ItemProcessListener) {
listener((ItemProcessListener<I, O>) stepListener);
}
if (stepListener instanceof ItemWriteListener) {
listener((ItemWriteListener<O>) stepListener);
}
}위와 같이 ChunkListener를 순회하면서, 내부적으로 (마찬가지로) ItemListener의 타입을 구별하면서 item Listener를 등록해주는 과정을 확인할 수 있다.
Tasklet 지향처리에서 사용하는 Tasklet Step 빌더인 AbstractTaskletStepBuilder의 build 로직에서는 아래와 같이 StepExecutionListener를 순회한다.
protected void registerStepListenerAsChunkListener() {
for (StepExecutionListener stepExecutionListener : properties.getStepExecutionListeners()) {
if (stepExecutionListener instanceof ChunkListener) {
listener((ChunkListener) stepExecutionListener);
}
}
}Tasklet 지향처리의 경우 위와 같이 StepExecutionListener을 순회하면서, 최종적으로 chunkListener를 구현, 등록하게 된다.
이 listener는 각각의 처리에서 리스너 api를 통해 등록해줄 수 있으며,
Tasklet 지향처리의 경우,
public B listener(ChunkListener listener) {
chunkListeners.add(listener);
return self();
}@Override
public B listener(Object listener) {
super.listener(listener);
Set<Method> chunkListenerMethods = new HashSet<>();
chunkListenerMethods.addAll(ReflectionUtils.findMethod(listener.getClass(), BeforeChunk.class));
chunkListenerMethods.addAll(ReflectionUtils.findMethod(listener.getClass(), AfterChunk.class));
chunkListenerMethods.addAll(ReflectionUtils.findMethod(listener.getClass(), AfterChunkError.class));
if (!chunkListenerMethods.isEmpty()) {
StepListenerFactoryBean factory = new StepListenerFactoryBean();
factory.setDelegate(listener);
this.listener((ChunkListener) factory.getObject());
}
return self();
}위와 같이 chunkListener 타입을 전달받아 등록해주고, 반대로 chunk 지향처리의 경우,
public SimpleStepBuilder<I, O> listener(ItemReadListener<? super I> listener) {
itemListeners.add(listener);
return this;
}public SimpleStepBuilder<I, O> listener(ItemWriteListener<? super O> listener) {
itemListeners.add(listener);
return this;
}public SimpleStepBuilder<I, O> listener(ItemProcessListener<? super I, ? super O> listener) {
itemListeners.add(listener);
return this;
}위와 같이 StepExecutionListener 및 chunkListener에서 itemListener 구현체를 자동으로 등록해주는 과정을 거치게 된다.
이때 여기서 의문점이 하나 발생할 수 있는데, 왜 Tasklet 지향처리는 StepExecutionListener는 차치하고, TaskletListener가 아닌 ChunkListener를 등록하는지 궁금해질 수 있다.
일전에 Chunk 기반 Step, Taskelt 기반 Step은 모두 TaskletStep에서 비롯된다고 하였고, StepBuilder에 따라 구현체 구현 과정을 다르게 선택한다고 하였는데, 리스너의 경우도 원리상 비슷하다.
Step
└─ TaskletStep
└─ RepeatTemplate
└─ execute(Tasklet)TaskletStep은 기본적으로 repeatTemplate을 사용하는데, 이는 Chunk 반복엔진이다. Chunk 지향 Step의 경우, RepeatTemplate가 여러 번 반복하지만, Tasklet 지향 Step의 경우 RepeatTemplate가 딱 1번만 반복된다.
Tasklet 기반의 Step 구성대로 구현이 진행되더라도, 실질적으로 처리할때 item과 같은 chunk 구성이 없지만, 실행설계적으로 보았을때 Chunk 실행 단위로 엔진이 실행하기 때문에 Tasklet 기반 처리라도 ChunkListener라는 컴포넌트를 재활용하는 구조로 진행이 되는 것이다.
따라서,
beforeStep
└─ beforeChunk
└─ tasklet.execute()
└─ afterChunk
afterStep위와 같이, tasklet을 실행하면 1개의 chunk에 대해서 실행하는 구조로 되어있기에, TaskletListener가 아닌 ChunkListener를 등록하는 구조로 되어있는 것이다. 좀 더 자세하게 말하면, Chunk 지향처리든 Tasklet 지향처리든 설계적으로 ChunkListener로 통합하여 사용하기 위한 재사용성, 재활용성의 관점으로 이해하면 좋을 것이다.
더불어, Customized Listener를 구현할때 StepExecutionListener, ItemListener와 같은 인터페이스를 굳이 여러번 구현하지 않고도, StepExecutionListener만 구현하여 사용해도 자동적으로 ItemListener 등록이 가능하다.
내부적으로 StepExecutionListener가 ItemListener를 구현하는 형태이기 떄문인데, 실제로 두 리스너 인터페이스를 모두 구현할 경우 리스너를 하나만 구현하라는 Exception이 발생하게 된다.
Spring batch의 이러한 설계사상 덕분에, StepExecutionListener만 구현하여 사용하면 되고, listener를 등록할때도 ItemListener를 따로 구성하지 않고 StepExecutionListener 하나만 등록하여도 정상적인 등록이 완료된다(listener 구성 시, 소비하는 입장에서 상위 타입을 소비할 수 있도록 더 상위 타입의 인터페이스 및 클래스를 사용하도록 하자).
당연히, ItemListener들에 대해서는 따로 구성해야 하고, 보통 실무에서도 관리차원에서 따로 구성하는 방향을 권장하고 있다.
- registerAsStreamsAndListeners(reader, processor, writer);
protected void registerAsStreamsAndListeners(ItemReader<? extends I> itemReader,
ItemProcessor<? super I, ? extends O> itemProcessor, ItemWriter<? super O> itemWriter)그 다음 단계는 매개변수를 보면 짐작할 수 있는데,
for (Object itemHandler : new Object[] { itemReader, itemWriter, itemProcessor }) {
if (itemHandler instanceof ItemStream) {
stream((ItemStream) itemHandler);
}
if (StepListenerFactoryBean.isListener(itemHandler)) {
StepListener listener = StepListenerFactoryBean.getListener(itemHandler);
if (listener instanceof StepExecutionListener) {
listener((StepExecutionListener) listener);
}
if (listener instanceof ChunkListener) {
listener((ChunkListener) listener);
}
if (listener instanceof ItemReadListener<?> || listener instanceof ItemProcessListener<?, ?>
|| listener instanceof ItemWriteListener<?>) {
itemListeners.add(listener);
}
}
}ItemReader, ItemProcessor, ItemWriter를 전달받고 이에 대한 itemStream을 자동 등록하고, 나아가 StepListener/ChunkListener/ItemListener까지 자동 등록까지 해주는 역할을 한다.
여기서 중요한 점은 ItemStream의 메커니즘이 바로 이 build(), 이 메소드를 호출하는 시점에서 이루어진다는 것이다.
ItemStream이 자동으로 등록이 된다는 것은, 결국 ItemReader/ItemProcessor/ItemWriter가 계층적으로 ItemStream을 구현하는 구현체이기 때문에 가능한 것이고, 만약 Customized한 컴포넌트가 이를 구현하고 있지 않다면 NPE가 발생하게 되는 것이다.
참고로 StepListener는 JobExecutionListener를 제외한, 모든 리스너를 포괄하는 최상위 리스너 인터페이스이다.
- return super.build();
그리고 이러한 최종적인 build()를 드디어 진행한다.
일전에 chunk 지향처리의 빌더 구현체의 최상위 부모는 AbstractTaskletStepBuilder, 즉 tasklet Step Builder라 하였다.
StepBuilder
└─ AbstractTaskletStepBuilder
├─ TaskletStepBuilder
└─ SimpleStepBuilder (chunk 지향)super는 AbstractTaskletStepBuilder를 지칭한다.
public TaskletStep build() {
registerStepListenerAsChunkListener();
TaskletStep step = new TaskletStep(getName());
super.enhance(step);super.build()를 통해 최종적으로 TaskletStep 구현체를 전달해주는 것을 살펴볼 수 있다(chunk 지향처리이지만, taskletStep 형태).
protected void registerStepListenerAsChunkListener() {
for (StepExecutionListener stepExecutionListener : properties.getStepExecutionListeners()) {
if (stepExecutionListener instanceof ChunkListener) {
listener((ChunkListener) stepExecutionListener);
}
}
}첫번째 로직을 통해, taskletStepBuilder에서 확인할 수 있었던 listener 처리를 이곳에서도 동일하게 진행한다. 즉, StepListener가 아닌 ChunkListener 형태라면 바로 이 시점에서 Listener가 등록이 되는 것이다(Chunk 지향처리라 하더라도, ChunkListener 형태로 등록).
TaskletStep step = new TaskletStep(getName());그리고 TaskletStep 구현체가 드디어 생성이 되며,
이후
super.enhance(step);부모 클래스인 StepBuilderHelper의 enhance를 호출하면서
protected void enhance(AbstractStep step) {
step.setJobRepository(properties.getJobRepository());
...
List<StepExecutionListener> listeners = properties.stepExecutionListeners;
if (!listeners.isEmpty()) {
step.setStepExecutionListeners(listeners.toArray(new StepExecutionListener[0]));
}
...jobRepositry를 이 시점에 저장하고, 전달받은 StepExecutionListener가 들어있는 listener 리스트를 StepExecutionListener 형태 배열로 변환하면서 step에 등록해준다.
그리고 다시, AbstractTaskletStepBuilder로 돌아와서
step.setChunkListeners(chunkListeners.toArray(new ChunkListener[0]));이번엔 ChunkListener 배열, 즉 chunkListener들을 step에 등록해준다.
if (this.transactionManager != null) {
step.setTransactionManager(this.transactionManager);
}이 과정 이후에는 위와 같이, transactionManager를 전달받아 등록해준다.
if (transactionAttribute != null) {
step.setTransactionAttribute(transactionAttribute);
}청크 트랜잭션의 속성을 입력해주었다면, transactionAttribute api를 통해 구성해줄 수 있는데, 해당 속성을 이 시점에서 등록해준다.
그리고, 위에서 Tasklet 지향처리에서 ChunkListener를 등록하면서, Tasklet 지향처리도 Repeat Template 기반의 chunk 처리(단, 이 경우 덩어리가 1개)라는 것을 잠깐 살펴보았는데, 이 "엔진"과 같은 구현체가 이 시점에 등록이 된다.
if (stepOperations == null) {
stepOperations = new RepeatTemplate();
if (taskExecutor != null) {
TaskExecutorRepeatTemplate repeatTemplate = new TaskExecutorRepeatTemplate();
repeatTemplate.setTaskExecutor(taskExecutor);
repeatTemplate.setThrottleLimit(throttleLimit);
stepOperations = repeatTemplate;
}
((RepeatTemplate) stepOperations).setExceptionHandler(exceptionHandler);
}
step.setStepOperations(stepOperations);여기서는 step에 stepOperation라는, RepeatOperations라는 Spring batch의 "반복엔진" 구현체를 주입하는 매우 중요한 과정을 진행한다.
참고로, 위에서 기술하였듯이 Tasklet도 chunk 1덩어리에 대한 작업이며, 크게 보았을때 각 read, process, write가 입력받는 데이터가 없을때까지, read는 더이상의 입력 데이터를 전달받지 못할때까지 반복한다.
RepeatStatus iterate(RepeatCallback callback) throws RepeatException;실제로도 인터페이스 모양이 위와 같다.
iterate라는 반복적인 작업을 진행하면서, RepeatStatus에 따라서 callback을 진행하게 되는 것이다.
이 반복작업의 엔진 구현체가 바로 RepeatTemplate이며, tasklet.execute()를 반복호출하여 생명주기에 맞춘 반복 batch step 작업이 가능하게 해준다.
그리고 특이한 부분이 바로 execeptionHandler를 등록하는 과정인데,
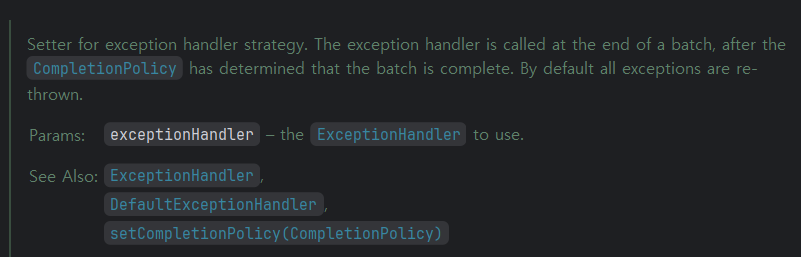
이 설명에서 유추할 수 있듯, 앞 단계에서 분석하였던 내결함성 기능(Retry/Skip)에 대한 ExceptionHandler, 나아가 BatchCompletionPolicy를 등록하여 Step이 Exception을 던졌을때 이 Exception을 어떻게 처리할 것인지 그 정책 정보를 저장한다.
참고로, setOperations에 저장하는 exceptionHandler 구현체 중, 청크지향처리의 내결함성 기능에 대한 것은 SimpleRetryExceptionHandler이다.
이제 반복 작업을 위한 구현체와 내결함성을 위한 Exception Handler를 stepOperations에 저장하는 단계까지 온 것이다.
다음 단계는
step.setTasklet(createTasklet());TaskletStep에 tasklet, 즉 tasklet 지향처리와 chunk 지향처리를 가장 명확하게 구분하는 결정적인 지점이자, Tasklet 구현체를 지정해주는 단계이다.
이는 StepBuilder의 구현체 로직을 그대로 따르는 템플릿메서드 패턴을 적용하고 있는데,
- chunk 지향처리의 빌더구현체인 SimpleStepBuilder에서는,
아래와 같이 createChunkOperations을 통한 RepeatOperations를 구성하고, chunkProvider, chunkProcessor를 거쳐 tasklet 구현체를 전달하는 것을 살펴볼 수 있다.
@Override
protected Tasklet createTasklet() {
..
RepeatOperations repeatOperations = createChunkOperations();
SimpleChunkProvider<I> chunkProvider = new SimpleChunkProvider<>(getReader(), repeatOperations);
SimpleChunkProcessor<I, O> chunkProcessor = new SimpleChunkProcessor<>(getProcessor(), getWriter());
chunkProvider.setListeners(new ArrayList<>(itemListeners));
chunkProvider.setMeterRegistry(this.meterRegistry);
chunkProcessor.setListeners(new ArrayList<>(itemListeners));
chunkProcessor.setMeterRegistry(this.meterRegistry);
ChunkOrientedTasklet<I> tasklet = new ChunkOrientedTasklet<>(chunkProvider, chunkProcessor);
tasklet.setBuffering(!readerTransactionalQueue);
return tasklet;
}이 과정도 중요해서 각 단계별로 분석해보고자 한다.
먼저 첫번째 단계는 chunkOperations를 구성하는 단계이다.
일전에 repeatTemplate을 구성하여 "Step 자체에 대한" 반복엔진을 장착하였다면, 이 과정을 통해서는 Chunk 읽기에 대한 반복엔진, 즉 ItemReader.read()를 반복해서 동작하게 해주는 기능을 제공한다.
protected RepeatOperations createChunkOperations() {
RepeatOperations repeatOperations = chunkOperations;
if (repeatOperations == null) {
RepeatTemplate repeatTemplate = new RepeatTemplate();
repeatTemplate.setCompletionPolicy(getChunkCompletionPolicy());
repeatOperations = repeatTemplate;
}
return repeatOperations;
}참고로 위 분기에서 볼 수 있듯이, repeatOperations이 별도로 구성되어있지 않다면 RepeatTemplate을 기본 구현체로 사용한다.
그리고, getChunkCompletionPolicy를 통해 이 "반복작업"의 종료 시점을 어떻게 판단할 수 있을 것인가, 그 기준을 설정해주어야 한다.
이 완료정책이 설정된다면,
protected boolean isComplete(RepeatContext context, RepeatStatus result) {
boolean complete = completionPolicy.isComplete(context, result);
if (complete) {
logger.debug("Repeat is complete according to policy and result value.");
}
return complete;
}RepeatTemplate 구현체가 isComplete 메소드를 호출하여, completionPolicy.isComplete(context, result)를 통해 작업이 최종적으로 완료되었는지 판단하고, 완료정책에 부합한다면 반복작업을 종료한다.
AbstractTaskletStepBuilder를 살펴보면, 별도 completionPolicy 구현체를 지정해주지 않는다.
이는 곧, completionPolicy를 따로 지정해주지 않는다면 기본 완료정책 구현체를 사용한다는 의미이며,
private CompletionPolicy completionPolicy = new DefaultResultCompletionPolicy();RepeatTemplate에서는 기본 정책으로 DefaultResultCompletionPolicy 구현체를 사용한다.
이 역시 템플릿 메서드 패턴을 적용하고 있는데, 해당 기본 구현체의 isComplete 로직을 살펴보면,
public class DefaultResultCompletionPolicy extends CompletionPolicySupport {
/**
* True if the result is null, or a {@link RepeatStatus} indicating completion.
*
* @see org.springframework.batch.repeat.CompletionPolicy#isComplete(org.springframework.batch.repeat.RepeatContext,
* RepeatStatus)
*/
@Override
public boolean isComplete(RepeatContext context, RepeatStatus result) {
return (result == null || !result.isContinuable());
}위와 같이 RepeatStatus를 전달받아 null이거나, continuable 상태값이 아니라면 종료기준으로 간주하고 있음을 알 수 있다.
참고로, RepeatStatus라는 상태값에서 알 수 있듯이, 해당 stepOperations의 반복작업은 tasklet.execute()의 반환값을 기준으로 Step 종료 혹은 지속에 대한 결정을 내린다.
chunk 지향처리의 SimpleStepBuilder에서 createTasklet하였을때의 "chunkOperations"는 task 전역이 아닌 item Reader의 read 기능에 대한 반복엔진 구현체를 설정해주는 것으로 이어지는데,
repeatTemplate.setCompletionPolicy(getChunkCompletionPolicy());위 과정에서의 chunkCompletionPolicy의 구현체가 바로
return new SimpleCompletionPolicy(chunkSize);에서 확인할 수 있듯이, SimpleCompletionPolicy이다.
이 "ChunkOperations"에 등록하는, ItemReader의 작업완료 조건은 해당 구현체의 isComplete를 통해 확인할 수 있고,
@Override
public boolean isComplete(RepeatContext context, RepeatStatus result) {
return super.isComplete(context, result) || ((SimpleTerminationContext) context).isComplete();
}이에 대한 기준은 위와 같이, 부모클래스(DefaultResultCompletionPolicy)의 판단 기준인 RepeatStatus를 그대로 활용하거나,
public boolean isComplete() {
return getStartedCount() >= chunkSize;
}RepeatStatus의 상태가 continuable이라도, chunk 지향처리의 핵심 기준인, chunk size만큼 데이터를 읽어 온 상태라면 즉 반복작업의 대상이 chunkSize 이상 호출이 되었다면 일단 읽기 작업을 완료로 처리한다.
바로 이 시점에서 우리가 알고있는 청크지향처리의 반복/작업완료 로직이 "등록"되는 것이다.
이 단계 이후에 비로소 ChunkProvider 등록 및 ChunkProcessor 등록이 이어지는데,
chunkProvider.setListeners(new ArrayList<>(itemListeners));
chunkProvider.setMeterRegistry(this.meterRegistry);
chunkProcessor.setListeners(new ArrayList<>(itemListeners));
chunkProcessor.setMeterRegistry(this.meterRegistry);chunk지향처리의 step빌더 구현체에서 본인에게 알맞은 ItemReader를 chunkProvider를 통해 등록하고, ItemProcessor와 ItemWriter를 chunkProcessor를 통해 등록한다.
SimpleChunkProvider<I> chunkProvider = new SimpleChunkProvider<>(getReader(), repeatOperations);
SimpleChunkProcessor<I, O> chunkProcessor = new SimpleChunkProcessor<>(getProcessor(), getWriter());각각의 컴포넌트가 어떠한 매개변수를 생성자 인자로 전달받고 있는지 확인하면 그 의미를 더욱 명확히 이해할 수 있다.
참고로, 내결함성 기능을 활성화한다면 SimpleChunkProvider, SimpleChunkProcessor가 아닌 FaultTolerantChunkProvider, FaultTolerantChunkProcessor 구현체를 활용하여 등록한다.
각설하고, chunkProvider를 통해, 드디어, ItemReader의 반복작업엔진과 종료조건(chunkOperations)이 등록이 되는 것이고, ItemReader의 반복작업은 결국 chunkProvider를 통해 최종 등록이 되는 것을 확인할 수 있다.
그리고 이후에,
chunkProvider.setListeners(new ArrayList<>(itemListeners));
chunkProcessor.setListeners(new ArrayList<>(itemListeners));itemListener를 등록하여, 모든 리스너 등록을 마치게 된다.
최종적으로
ChunkOrientedTasklet<I> tasklet = new ChunkOrientedTasklet<>(chunkProvider, chunkProcessor);
tasklet.setBuffering(!readerTransactionalQueue);
return tasklet;chunkOrientedTasklet 구현체를 전달하여, 이 tasklet은 "청크지향처리"임을 명확히 하게 된다.
/**
* @param tasklet the tasklet to use
* @return this for fluent chaining
* @since 5.0
*/
public TaskletStepBuilder tasklet(Tasklet tasklet, PlatformTransactionManager transactionManager) {
this.tasklet = tasklet;
super.transactionManager(transactionManager);
return this;
}chunk 지향처리의 tasklet 구현체 전달 과정은 위와 같이 상당히 복잡하고, 반면 tasklet 지향처리의 tasklet 구현체 전달 과정은 꽤나 간단명료하다.
애초에 반복엔진의 구현체를 제외하고는, 반복작업의 종료조건이나 구체적인 로직은 tasklet을 customized한 우리 책임하에 있기에 우리가 지정해준 tasklet을 하나만 반환해주는 것으로 족하다.
다만, 모든 tasklet은 기본적인 설계가 "chunk" 지향처리로 되어있기에, chunk 반복수행인지, chunk 1개(=tasklet) 수행인지에 대한 구분일뿐 전체적으로 원리가 하나로 귀결된다는 점은 기억하도록 하자.
결론적으로는 각각의 구현체를 createTasklet()을 통해 전달받는 시점이 되어서야, Tasklet의 정체가 드러나게 되는 것이다.
그 후, 다시 abstractTaskletStepBuilder에서
step.setStreams(streams.toArray(new ItemStream[0]));itemStream 구현체들을 등록하여, stream 등록까지 마친다.
이 과정을 거쳐,
- Tasklet Step
[by AbstractTaskletStepBuilder]
- chunkListener
- stepExecutionListener
- jobRepository
- transactionManager
- stepOperations (tasklet.execute)
- stream
[Chunk 구현체]
- ChunkOrientedTasklet
ㄴ ChunkProvider - itemReader/ItemReaderListener/chunkOperations
ㄴ ChunkProcessor - itemProcessor/itemWriter/itemProcessorListener/itemWriterListener
[Tasklet 구현체]
- Tasklet
Tasklet 구현체를 전달받아 TaskletStep을 완성한다.
자, 다시 정리한다.
지금까지 abstractTaskletStepBuilder를 통해 stepOperations(Step 작업 반복작업정책) 및 tasklet 구현체를 설정해주었고, tasklet 구현체를 설정 시점에 chunkOperations 추가 등록(to RepeatOperations), chunkProvider, chunkProcessor를 등록해주었다.
그리고 구현체 builder를 통해 tasklet 구현체 혹은 내부 chunk tasklet 구현체(chunkProvider/chunkProvessor)를 전달하여 tasklet의 정체를 명확히 하고, 마지막으로 stream을 등록하여 build 과정을 마무리한다.
build() 하나를 보는데 꽤 긴 여정을 지나왔는데, 결론은 다음과 같다.
- Tasklet 지향처리와 chunk 지향처리의 본질은 모두 TaskletStep이고, 빌더구현체를 어떤 것을 선택하고 이에 따른 tasklet구현체를 어떤 것을 전달하느냐에 따라 처리 방안이 달라진다.
- build의 첫번째 단계에서는 StepExecutionListener 및 ItemListener와 같은 리스너 단독 등록을 진행하며, 이때 상위 인터페이스가 하위 인터페이스를 구현한 구현체이므로 한번만 리스너를 등록해주면 된다.
- build의 두번째 단계에서는 ItemStep 컴포넌트에서 Stream 구현체와 StepListener 구현체를 자동으로 등록해주며, ItemStream의 자동 등록이 이 단계에서 완료된다.
- 최종 빌드단계에서 위에서의 등록한 리스너, jobRepository, transactionManager, tasklet(chunk oriented or tasklet) 모두 조립하여, "최종 구성 및 빌드"를 완료한다.
4. Step에 대한 고찰 3 - TaskletStep의 동작
기나긴 여정을 통해 TaskletStep을 구성하였고, 이제부터는 이 Step을 실행하는 단계에 접어들었다.
Spring batch의 최초 실행에 대해 기억이 나는가?
Spring framework의 경우 JobLauncher.run(job, jobParameters), Spiring boot의 경우 JobLauncherApplicationRunner가 JobLauncher.run를 실행하여 "spring batch job"을 실행하게 된다.
그 이후는 우리가 알고있듯이,
JobLauncher
→ Job
→ JobExecution
→ Job.execute()
→ Step 실행 반복
→ StepHandler
→ Step.execute()
→ TaskletStep.execute()job.execute()를 최초 실행하여, 내부적으로 Step의 실행을 반복하면서 Step.execute() 및 TaskletStep.execute()를 반복진행한다.
이때, JobLauncher는 job의 구현체인 SimpleJob을 execute(JobExecution)하고, 이 구현체가 내부적으로 아래와 같이,
for (Step step : steps) {
stepHandler.handleStep(step, jobExecution);
}구체적으로는, stepHandler 구현체가 각각의 step의 정보에 따라 반복실행하면서, 이 시점에서 Step을 실행하게 되는 것이다.
이 stepHandler의 구현체는 SimpleStepHandler가 기본 구현체이며, 해당 구현체가 Step을 진행하는 실질적인 주체임에 유의하자. 나아가, SimpleStepHandler가 Step 실행을 위임받으면서 StepExecution 및 ExecutionContext을 생성하며 재시작 여부 판단 등의 부가적인 역할도 담당하게 된다.
이때 전달받는 Step 정보는 위 과정을 통해 구성한 TaskletStep이며, 위에서 많이 살펴보았듯 chunk, tasklet지향처리 모두 TaskletStep을 반환하게 된다.
그리고,
doExecute()
→ beforeStep()
→ repeatTemplate.iterate(...)
→ Tasklet.execute(...)
→ afterStep()Tasklet 실행 및 repeatTemplate을 통해 반복실행하고, 이 부분은 위에서 기술한 내용이다.
[Application / Scheduler / Boot Runner]
|
v
JobLauncher.run(job, params)
|
v
JobExecution 생성
|
v
SimpleJob.execute()
|
v
┌─ Step 반복 처리 ──────────────────┐
| |
v |
SimpleStepHandler.handleStep() |
| |
v |
StepExecution 생성 |
| |
v |
Step.execute(stepExecution) (*createStepExecution) |
v |
TaskletStep.execute() |
| |
v |
doExecute() |
| |
v |
RepeatTemplate.iterate() |
| |
v |
Tasklet.execute() ← 실제 비즈니스 로직 |
| |
v |
Step 종료 및 상태 저장 |
| |
└─────────────────────────────────────┘
간단하게 Step 실행과정을 기술해보았는데, 전체적인 Step 실행 도식도는 위와 같다. 이 흐름을 이제 세부적으로 살펴보도록 하겠다.
4-1. SimpleStepHandler의 고찰 - stepScope
SimpleStepHandler 구현체를 살펴보면 기본적으로 jobRepository 혹은 executionContext를 전달받아 생성자를 구성하며,
public SimpleStepHandler(JobRepository jobRepository) {
this(jobRepository, new ExecutionContext());
}
public SimpleStepHandler(JobRepository jobRepository, ExecutionContext executionContext) {
this.jobRepository = jobRepository;
this.executionContext = executionContext;
}위 전달받은 실행에 필요한 구성요소를 바탕으로 stepExecution을 생성하는 것부터 시작하는데, 이는 jobRepository로부터 가장 최근에 실행하였던 stepExecution 정보를 통해 추출해오고 있음을 확인할 수 있다.
StepExecution lastStepExecution = jobRepository.getLastStepExecution(jobInstance, step.getName());
if (stepExecutionPartOfExistingJobExecution(execution, lastStepExecution)) {
// If the last execution of this step was in the same job, it's
// probably intentional so we want to run it again...
if (logger.isInfoEnabled()) {
logger.info(String.format(
"Duplicate step [%s] detected in execution of job=[%s]. "
+ "If either step fails, both will be executed again on restart.",
step.getName(), jobInstance.getJobName()));
}
lastStepExecution = null;
}
StepExecution currentStepExecution = lastStepExecution;위와 같이 일단은 lastStepExecution 실행정보를 저장해두었다가, 이후 현재 실행정보를 추출해오기 위한 과정을 진행한다.
if (shouldStart(lastStepExecution, execution, step)) {
currentStepExecution = execution.createStepExecution(step.getName());먼저 해당 stepExecution이 시작해야는지에 대한 여부를 판단하여, 시작이 필요하다면 creationStepExecution을 통해 현재 실행해야하는 execution 정보를 추출한다.
if (isRestart) {
currentStepExecution.setExecutionContext(lastStepExecution.getExecutionContext());
if (lastStepExecution.getExecutionContext().containsKey("batch.executed")) {
currentStepExecution.getExecutionContext().remove("batch.executed");
}
}
else {
currentStepExecution.setExecutionContext(new ExecutionContext(executionContext));
}이후 재시작 여부를 판단하여, 재시작이 필요하면 lastStepExecution 정보를 등록하고, 그럴 필요가 없다면 currentStepExecution 정보를 새롭게 생성한다.
try {
step.execute(currentStepExecution);
currentStepExecution.getExecutionContext().put("batch.executed", true);
}그 후 최종적으로 해당 stepExecution을 execute하여, step을 실행한다.
여기서 중요한 것은, Step을 실행하기 위해 StepExecution과 ExecutionContext를 생성하고, 최종적으로 step을 execute(실행)한다는 점이다.
이때 생성하는 stepExecution 정보는 최초,
currentStepExecution = execution.createStepExecution(step.getName());과정을 통해 생성이 되고, 이후,
currentStepExecution.setExecutionContext(lastStepExecution.getExecutionContext());
...
currentStepExecution.getExecutionContext().put("batch.executed", true);executionContext를 이전의 작업으로 진행할지, 신규 작업으로 진행할지 판단하여 executionContext 정보가지 등록한다.
또한 중요한 점이 있는데, 지금 살펴보고 있는 과정들은 "Step 정보를 생성하는 시점, 즉 Step을 실행하기 이전"이다.
따라서 StepScope 어노테이션을 Step에 설정하여 사용시도할 경우, stepscope 프록시객체의 명세에 따라, 해당 step이 스코프 적용(객체생성지연)하여 해당 step 객체의 생성이 지연되는 것이다.
자 다시 살펴보면, StepScope가 적용된 빈은 Step 생명주기에 맞춰 프록시로 등록되며, 실제 객체 생성은 Step 실행 시점까지 지연된다.
이때, 지연된 실행 지점이, 실제로 실행 및 stepExecution 정보를 등록하는 시점보다도 더 나중이기에 step.getName()이 불가능해져 step 실행자체가 막혀버린다.
이를 위해 앞단계의 이해과정이 필요했던 것이고, 본격적으로 step의 실행(execute) 과정에 대해 알아보도록 하자.
step.execute()를 하게되면, 전달받은 step(TaskletStep)의 부모클래스인 AbstractStep의 execute를 템플릿메서드 패턴을 통해 실행한다.
doExecutionRegistration(stepExecution);
...
getCompositeListener().beforeStep(stepExecution);
open(stepExecution.getExecutionContext());
...이때 doExecutionRegistration을 최초로 실행하는데,
protected void doExecutionRegistration(StepExecution stepExecution) {
StepSynchronizationManager.register(stepExecution);
}내부적으로 stepExecution 정보를 StepSynchronizationManager에게 전달하여 등록한다.
이를 들어가보면,
getCurrent().push(execution);실행정보(execution)를 getCurrent()에 등록하는 것을 확인할 수 있는데,
public Stack<E> getCurrent() {
if (executionHolder.get() == null) {
executionHolder.set(new Stack<>());
}
return executionHolder.get();
}getCurrent()는 좀 더 파헤쳐보면 그 정체가 명확히 들어난다.
public T get() {
Thread t = Thread.currentThread();즉, ThreadLocal에 현재 실행중인 StepExecution 및 이 Execution의 context 객체(StepContext)를 등록한다.
이 threadLocal에 step 정보를 바인딩 해주는 시점이, step 객체가 모두 생성되었다고 간주해도 무방한 시점인 것이고, stepScope에서 말하는 "객체생성하기까지 스코프 대상객체의 생성을 지연"은 바로 이 시점까지, 모든 정보를 바인딩할 수 있는 지점까지 지연한다는 것이다.
이는 다르게 말하면, scope 대상 객체의 생성을 지연하기 위해선 threadLocal에 step 명 및 execution 정보 등, step 정보가 threadLocal에 바인딩되어 있어야 한다는 의미이기도 하다.
쉽게 정리하면,
StepHandler.handleStep()
↓
AbstractStep.execute()
↓
doExecutionRegistration(stepExecution)
→ StepSynchronizationManager.register(stepExecution)
→ ThreadLocal에 StepExecution / StepContext 바인딩
↓
beforeStep()
↓
open()
↓
doExecute() ← 여기서 Tasklet / Reader / Processor 접근StepScope 프록시가 실제 객체를 생성(resolve)할 수 있는 최초 시점은,
StepSynchronizationManager.register() 이후, Step객체를 바인딩한 시점 이후에만 가능하다. 그 이전에 step객체 생성을 막아버리거나(Stepscope 범위를 Step에 설정하여), 혹은 이에 준하여 step 객체생성이 지연된다면, 예외상황이 발생한다.
반드시 tasklet 객체와 같은 step 하위의 객체에 대해 객체생성을 지연해주어야, step 객체생성을 온전하게 보장할 수 있다.
StepContext context = StepSynchronizationManager.getContext();실제로도 바인딩되어있는 step 객체를 불러와야, 지연을 하든 할텐데 step객체가 애초에 없다면 NPE가 발생한다.
이것마저 이해가 힘들다면, 더욱 쉽게 요약해보겠다.
그런데 알다시피 @StepScope를 붙이면 stepScope라는 명세에 의해 Step 객체가 프록시로 등록이 되긴 하지만, 해당 실제 인스턴스의 해석 및 실체화(=바인딩)을 지연시킨다.
이는 두가지 모순을 발생시킨다.
1) Step을 구성해야하는데, step 객체생성 및 바인딩 작업이 지연되어 구성자체를 못한다.
Step 구성 시 ThreadLocal에 해당 정보를 register(바인딩)을 하지 못하였기에, step 객체를 생성하기 위한 step.getName() 정보를 비롯한 객체정보를 추출해올 수 없고 결과적으로는 step 구성이 불가능해진다.
StepExecution 생성
→ step.getName() 필요
→ StepScope 프록시 해석 시도
→ StepContext 필요
→ StepExecution 아직 없음2) scope 해석 자체가, 대상을 프록시화하면서, 실제 인스턴스화를 위해 stepContext의 정보를 필요로 하는데, step에 적용할 경우 step 정보 자체가 없는 모순이 발생한다.
즉, threadLocal에 Step 정보가 완전 구성되어있어야 기본적인 StepScope "명세", "해석"이 허용(부합)되는 것이고, StepScope 대상 객체의 생성이 허용되는 시점이 Step인스턴스의 ThreadLocal 바인딩 이후이라는 것이 핵심이다(Step정보를 등록하고 이 전제를 기반으로 scope를 해석함, step에 적용 시 논리적/시점 모두 모순).
4-2. SimpleStepHandler의 고찰 - stepScope활성화(step객체 정보 바인딩) 이후 과정
getCompositeListener().beforeStep(stepExecution);
open(stepExecution.getExecutionContext());Step객체정보를 바인딩하여 인스턴스 정보를 만들었으니, 이제부터는 spring batch step 실행의 생명주기를 기반으로 진행한다.
step 실행 직전에 stepListener(beforeStep)을 탐색하고, 이후(step 실행 직직전에) itemStream을 open하여 stepExecution 정보를 추출, 자원 초기화 및 상태 복원 등을 시작한다.
step.execute(currentStepExecution);그리고 드디어 AbstractStep의 execute를 템플릿메서드 패턴에 의해 호출, step을 "실행"한다.
getJobRepository().update(stepExecution);
..
doExecutionRegistration(stepExecution);
..
doExecute(stepExecution);내부적으로는 stepExcetuion 정보를 통해 jobRepository 상태내역을 최신화하면서 threadLocal에 등록한다(doExecutionRegistration).
그리고 최종적으로 doExecute메서드를 호출하여 최종 실행한다.
protected abstract void doExecute(StepExecution stepExecution) throws Exception;doExecute를 호출하는 구현체는 AbstractStep의 자식인 TaskletStep이다.
@Override
protected void doExecute(StepExecution stepExecution) throws Exception {
....
stream.update(stepExecution.getExecutionContext());
getJobRepository().updateExecutionContext(stepExecution);
...TaskletStep에서 doExecute를 실행하게 되면, itemStream의 update를 호출하여 자원상태를 최신화하는데, 여기서 중요한 점은 단순 청크재시작을 위한 체크포인트가 아닌 청크 이전 "자원 상태" 그자체를 남기는, 파일의 위치 및 재시작 시 헤더중복 등을 방지하기 위한 기본적인 체크포인트라는 것이다.
쉽게 말하면, "최소한 이 Step은 target resource를 open한 상황이자, 그러한 객체이다"라는 것을 보장하기 위한 작업이다.
우리가 생각하는 "보통의" Step흐름에서는 itemStream의 자원상태 최신화(update)는 청크 처리를 모두 완료하여 트랜잭션을 커밋하기 직전에 발생한다.
stepOperations.iterate(new StepContextRepeatCallback(stepExecution) {
...(chunk step 반복처리)그리고, stepOperaions.iterate를 호출하여, 구현체인 repeatTemplate의 iterate를 작동하게 된다.
@Override
public RepeatStatus iterate(RepeatCallback callback) {이때 전달받는 RepeatCallback의 구현체는, TaskletStep으로부터 stepOperaions.iterate를 실행하면서 전달되는
stepOperations.iterate(new StepContextRepeatCallback(stepExecution) {StepContextRepeatCallback이다. 참고로 callback 구현체는 내부적으로 doInIteration를 호출하여 실제 작업을 "처리한다." 이에 대한 내용은 후술한다.
다시 돌아와서, 이 구현체를 전달받아서, RepeatTemplate의 iterate를 호출하는 것이며,
try {
result = executeInternal(callback);
}내부적으로 executeInternal를 호출(callback의 doInternal를 실행하기에 executeInternal),
while (running) {
result = getNextResult(context, callback, state);
}위와 같이 while loop를 통해 getNextReulst를 반복호출하게 된다.
protected RepeatStatus getNextResult(RepeatContext context, RepeatCallback callback, RepeatInternalState state)
throws Throwable {
update(context);
if (logger.isDebugEnabled()) {
logger.debug("Repeat operation about to start at count=" + context.getStartedCount());
}
return callback.doInIteration(context);
}반복호출대상인 getNextResult는 callback을 전달받아 doInInternal을 호출, step 처리로직을 이 시점에서 진행하게 된다.
callback 구현체인 doIteration을 살펴보면, 반복실행환경(stepContext 등록 등)을 구성해주고 바로
return doInChunkContext(context, chunkContext);doInChunkcontext라는 메서드를 호출하여 stepcontext의 실행을 최종 위임한다(메서드명에서도 추측할 수 있듯이, chunkContext를 "실행"하는 역할을 하는 최종 지점이며, callback 측에서는 실행환경을 구성하여 실행을 위임하는 역할을 담당한다).
즉, 최종 실행은 하위 클래스 구현체에게 위임하며, 하위클래스인 TaskletStep.doExecute()에서 이를 위임받아 실행한다.
stepOperations.iterate(new StepContextRepeatCallback(stepExecution) {
@Override
public RepeatStatus doInChunkContext(RepeatContext repeatContext, ChunkContext chunkContext)
throws Exception {
StepExecution stepExecution = chunkContext.getStepContext().getStepExecution();
// Before starting a new transaction, check for
// interruption.
interruptionPolicy.checkInterrupted(stepExecution);
RepeatStatus result;
try {
result = new TransactionTemplate(transactionManager, transactionAttribute)
.execute(new ChunkTransactionCallback(chunkContext, semaphore));
}
catch (UncheckedTransactionException e) {
// Allow checked exceptions to be thrown inside callback
throw (Exception) e.getCause();
}
chunkListener.afterChunk(chunkContext);
// Check for interruption after transaction as well, so that
// the interrupted exception is correctly propagated up to
// caller
interruptionPolicy.checkInterrupted(stepExecution);
return result == null ? RepeatStatus.FINISHED : result;
}
});doInChunkContext가 바로 최종적인 실행 담당인 것이고, 이를 살펴보면
try {
result = new TransactionTemplate(transactionManager, transactionAttribute)
.execute(new ChunkTransactionCallback(chunkContext, semaphore));
}다시 내부적으로 ChunkTransactionCallback을 호출하면서 transactionTemplate을 execute하는 양상을 볼 수 있다.
result = (T)action.doInTransaction(status);거의 다왔다. 해당 execute를 살펴보면 doInTransaction을 호출하는 것을 확인할 수 있고, 이는 Tasklet의 doInTransaction을 통해 진행한다.
result = tasklet.execute(contribution, chunkContext);doInTransaction은 tasklet.execute를 해서 chunk처리를 진행하고, 해당 결과를 받아 return 한다.
결론, taskletStep.execute 진행 시, RepetTemplate.iterate를 통해 내부적으로 callback.doInternal(실질 처리)를 while loop를 통해 반복호출, 이는 내부적으로 taskletStep의 doInTransaction을 반복 호출하는 것과 동일, 여기서 tasklet.execute를 반복호출하여 step을 반복진행하는 것이다.
처음 살펴보는 내용이기에, 논리적 흐름만 살펴보았다. 좀 더 구체적으로 살펴보면서 완전히 체득하도록 하자.
4-3. SimpleStepHandler의 고찰 - taskletStep.execute()
한번 훑어보았으니 이제는 이해가 좀 더 쉬울 것이다.
첫 시작점은 TaskletStep의 doExecute, stepOperations(RepeatTemplate)의 iterate를 호출하는 지점이다.
이때 전달한 매개변수 StepContextRepeatCallback의 doInIteration을 while loop 기반으로 반복 호출하면서, 내부적으로 doInChunkContext를 반복호출하게 된다.
그리고, 최종적으로 doInTransaction을 통해 tasklet.execute()를 호출하게 되면서 chunk/tasklet oriendted step을 실행, 이 역시 크게는 callback의 iteration 내부의 로직이기에 크게 보았을때 tasklet.execute()를 반복호출한 결과를 얻게 된다.
doInChunkContext()의 경우, new TransactionTemplate(transactionManager, transactionAttribute)을 통해 transactionTemplate을 생성하고 있는데, 매 chunk마다 새로운 transaction context을 구성하여 진행한다는 의미가 바로 여기서 비롯되는 것이다.
최종적으로는, 이러한 트랜잭션 컨텍스트를 구성하여 tasklet/chunk oriented tasklet을 execute()하여 step을 실행하는 과정을 완성한다.
개념적으로 구분하는게 편하여 tasklet/chunk oriented tasklet을 구분하였지만, 둘은 어찌되었든 taskletStep을 동일하게 반환하여 tasklet.execute()를 공통적으로 진행한다(chunk의 경우 chunk oriented tasklet을 구성하는 복잡한 과정을 거치지만, tasklet은 customized한 tasklet 그 자체이다).
더불어, tasklet 지향처리든 chunk 지향처리든 어찌되었든 트랜잭션이 1번 되느냐, 그 이상 되느냐의 차이일 뿐이다. 즉 tasklet 지향처리는 chunk 1덩어리, 트랜잭션이 1번만 일어나고 RepeatStatus를 finished를 반환하는 chunk 지향처리의 확장형태라는 것이다.
TransactionTemplate.execute()는 어떠한 로직을 가지고 있을까?
@Override
@Nullable
public <T> T execute(TransactionCallback<T> action) throws TransactionException {
Assert.state(this.transactionManager != null, "No PlatformTransactionManager set");
if (this.transactionManager instanceof CallbackPreferringPlatformTransactionManager cpptm) {
return cpptm.execute(this, action);
}
else {
TransactionStatus status = this.transactionManager.getTransaction(this);
T result;
try {
result = action.doInTransaction(status);
}
..catch..
this.transactionManager.commit(status);
return result;
}
}catch 부분을 제외하고 나타낸 TransactionTemplate.execute()의 로직은 위와 같이, transactionManager로부터 transaction 컨텍스트를 가져오고, doInTransaction을 하여 트랜잭션을 진행한다.
TransactionTemplate은 트랜잭션의 시작, 커밋, 롤백만 담당하며, 실제 로직 처리는 전달된 TransactionCallback의 doInTransaction을 호출, 여기에 위임한다.
다시 TaskletStep으로 돌아와서, TransactionTemplate에 제공하는 매개변수를 살펴보면 new ChunkTransactionCallback(chunkContext, semaphore)임을 확인할 수 있는데, TaskletStep의 이너클래스 내부에서 해당 doInTransaction을 살펴보면,
@Override
public RepeatStatus doInTransaction(TransactionStatus status) {
TransactionSynchronizationManager.registerSynchronization(this);
RepeatStatus result = RepeatStatus.CONTINUABLE;
StepContribution contribution = stepExecution.createStepContribution();먼저 step을 threadLcoal에 바인딩하여 step을 요리하기 위한 사전준비작업을 진행한다.
이후 repeatStatus와 StepContribution을 생성한다.
chunkListener.beforeChunk(chunkContext);
// In case we need to push it back to its old value
// after a commit fails...
oldVersion = new StepExecution(stepExecution.getStepName(), stepExecution.getJobExecution());
copy(stepExecution, oldVersion);
try {
try {
try {
result = tasklet.execute(contribution, chunkContext);
if (result == null) {
result = RepeatStatus.FINISHED;
}
}
...catch...
}
finally {
// If the step operations are asynchronous then we need
// to synchronize changes to the step execution (at a
// minimum). Take the lock *before* changing the step
// execution.
try {
semaphore.acquire();
locked = true;
}
...catch...
// Apply the contribution to the step
// even if unsuccessful
if (logger.isDebugEnabled()) {
logger.debug("Applying contribution: " + contribution);
}
stepExecution.apply(contribution);
}
stepExecutionUpdated = true;
stream.update(stepExecution.getExecutionContext());
try {
// Going to attempt a commit. If it fails this flag will
// stay false and we can use that later.
if (stepExecution.getExecutionContext().isDirty()) {
getJobRepository().updateExecutionContext(stepExecution);
}
stepExecution.incrementCommitCount();
if (logger.isDebugEnabled()) {
logger.debug("Saving step execution before commit: " + stepExecution);
}
getJobRepository().update(stepExecution);
}
...catch...
return result;
}중간중간에 익숙한 로직들이 보인다.
가장 눈에 들어오는 것은 taskletStep.execute를 진행하는 것이고, 해당 진행 후 결과가 null이라면 taskletStep의 반환값(RepeatStatus)은 null, step을 종료하기 위한 준비를 한다.
이후 해당 step 상태관리를 위해 stepExecution에 step contribution을 반영하며, stream에 해당 executionContext를 update한다.
jobRepository까지 상태최신화를 하고, 최종적으로 해당 결과값(RepeatStatus)을 반환, 반복엔진(RepeatTemplate)의 반복수행을 지속할 것인지, 종료할 것인지에 대한 판단 기준을 세우게 된다.
그런데, tasklet.execute()를 하는데 전달되는 contribution의 경우 tasklet진행 후 , stepExecution.apply를 통해 먼저 stepExecution에 반영이 되는 것을 확인할 수 있다.
이 stepExecution.apply를 살펴보면, stepContribution이 어떤 역할을 하는지 알 수 있는데,
public synchronized void apply(StepContribution contribution) {
readSkipCount += contribution.getReadSkipCount();
writeSkipCount += contribution.getWriteSkipCount();
processSkipCount += contribution.getProcessSkipCount();
filterCount += contribution.getFilterCount();
readCount += contribution.getReadCount();
writeCount += contribution.getWriteCount();
exitStatus = exitStatus.and(contribution.getExitStatus());
}변수명에서 바로 파악할 수 있듯이, chunk처리를 위한 기본적인 상태정보(readCount/writerCount) 등과 함께 내결함성 동작을 위한 최대 허용 횟수(skip/filter)를 담고 있는 기록실로써의 역할을 하고 있다.
stepExecution은 이러한 기록실 정보를 담고 있는 저장원의 역할을 담당하는 것이다.
참고로, tasklet을 execute()에 대해 기술해보자면,
공통적으로 tasklet.execute()을 진행하지만 chunk의 경우 chunk oriented tasklet, tasklet의 경우 customized하게 작성한 tasklet 그 자체인 것 까지는 기억할 것이다.
다만, tasklet 그 자체이라면 chunk가 1개이므로 그걸로 끝, chunk tasklet이라면 세부적으로 chunkOperations을 통한 itemReader 반복호출 및 chunkProcessor로 이를 전달하여 itemProcessor, itemWriter가 chunk를 순차적으로 처리하게 된다.
ChunkOrientedTasklet
- chunkProvider
ㄴ itemReader
ㄴ chunkOperations
ㄴ itemReadListener
- chunkProcessor
ㄴ itemProcessor
ㄴ itemProcessListener
ㄴ itemWriter
ㄴ itemWriteListenerChunkOrientedTasklet의 경우, 내부적으로 ChunkProvider와 ChunkProcessor가 구성되어 단계적인 처리를 하는 과정을 기억하는가?
tasklet.execute할때, 위의 tasklet 구현체가 그대로 반영되어 우리가 알고있는 chunk 지향처리의 과정을 그대로 수행하게 되는 것이다.
참고. SimpleStepHandler가 step을 실행하여 tasklet.execute를 진행하기까지의 여정
쉽게 말하면 step의 실행 및 처리과정에 대한 내용을 핵심 컴포넌트 위주로 정리해보았다.
정리를 위해 텍스트 도식화, 머메이드 코드는 gpt의 도움을 받았다.
- in 1 Line summarize :
JobLauncher → Job → SimpleStepHandler → TaskletStep →
RepeatTemplate → StepContextRepeatCallback → TransactionTemplate →
ChunkTransactionCallback → Tasklet.execute()이때 반복은 RepeatTemplate을 통해 진행, 실제 처리는 chunkTransactionCallback 구현체의 doInTransaction에서 tasklet.execute()를 실행하면서 진행한다.
| 컴포넌트 | 책임 |
|---|---|
| JobLauncher | Job 실행 트리거 |
| Job | Step 흐름 관리 |
| SimpleStepHandler | Step 실행 담당 |
| TaskletStep | Step의 실제 구현체 |
| RepeatTemplate | 반복 제어 |
| StepContextRepeatCallback | Step/Chunk 컨텍스트 유지 |
| TransactionTemplate | 트랜잭션 경계 |
| ChunkTransactionCallback | 트랜잭션 내부 실행 |
| Tasklet | 사용자 로직 (execute) |
위 컴포넌트는 아래와 같이 단계적 호출, chunk 처리를 진행한다.
JobLauncher
└─ Job
└─ SimpleStepHandler
└─ TaskletStep.execute()
└─ AbstractStep.execute()
└─ TaskletStep.doExecute()
└─ RepeatTemplate.iterate()
└─ while (running)
└─ StepContextRepeatCallback.doInIteration()
└─ doInChunkContext()
└─ TransactionTemplate.execute()
└─ ChunkTransactionCallback
└─ tasklet.execute()머메이드 다이어그램을 통해 한눈에 알아보기 쉽도록 정리하였다.
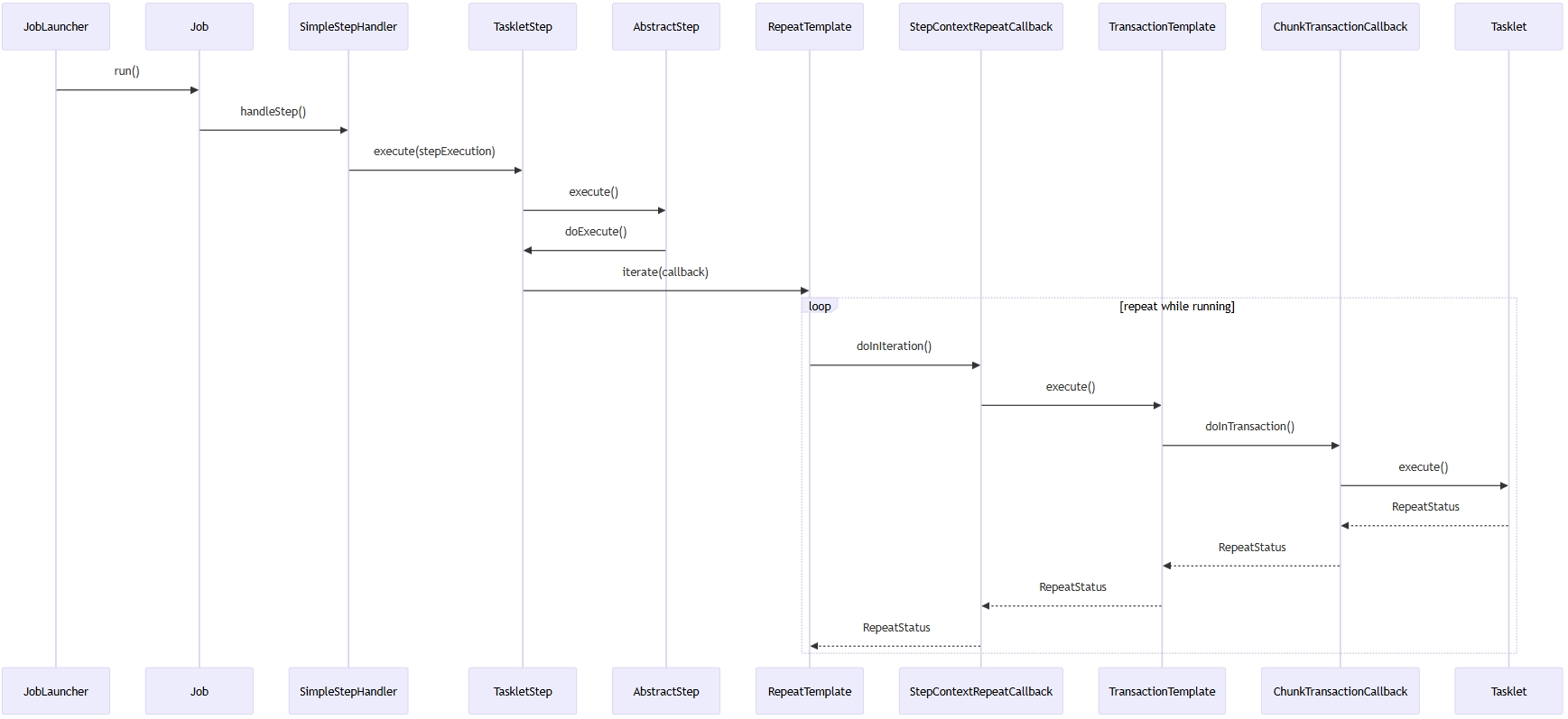
(link : 머메이드 다이어그램 링크)
참고. StepScope를 Step에 적용하면 안되는 이유 정리
너무나도 중요한 부분이기에, 원리적으로 쉽게 이해할 수 있도록 아래와 같이 풀어서 정리해두겠다.
@StepScope는 대상 빈을 프록시로 등록하고,
실제 인스턴스의 실체화는 StepExecution이 활성화된 이후(=ThreadLocal에 StepExcecution 정보를 등록하여, Step객체를 활성화 및 scope 해석이 가능한 지점)로 지연한다.
그러나 Step에 StepScope를 적용하면 두 가지 구조적 모순이 발생한다.
첫째, StepExecution을 생성하기 위해 Step의 메타데이터(step.getName())가
선행적으로 요구되지만, StepScope 프록시는 StepContext 없이는
실제 Step 인스턴스를 해석할 수 없어 Step 구성이 불가능해진다.
둘째, StepScope 해석은 StepExecution을 전제로 하지만,
StepExecution은 Step 없이는 생성될 수 없기 때문에
Scope 해석의 입력과 출력이 동일한 순환 구조가 된다.
결론적으로 StepScope 명세가 허용되는 시점은
StepExecution과 StepContext가 ThreadLocal에 바인딩된 이후이며,
이는 Step 내부 구성 요소(Tasklet, ItemReader 등)에만 적용 가능하다.
5. SimpleStepHandler의 고찰 - Chunk Oriented Tasklet의 실행
위에서 기술하였듯이, SimplStepHandler는 step 실행 그 자체뿐만 아니라, JobRepository와 같은 메타데이터 관리, Step 가능여부 판단, 이전 Step 실행 및 신규 step 실행정보 생성 등 다양한 step 실행관련 역할을 총괄하는 컨트롤 타워의 역할을 한다.
다만 chunk 처리는, tasklet.execute()를 통해 위임하는 것을 위에서 확인하였으며 chunk지향처리의 경우 ChunkOrientedTasklet의 execute()를 호출하여 chunk step을 단계적으로 실행하게 된다.
이에 대해 살펴보자.
@Nullable
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
@SuppressWarnings("unchecked")
Chunk<I> inputs = (Chunk<I>) chunkContext.getAttribute(INPUTS_KEY);
if (inputs == null) {
inputs = chunkProvider.provide(contribution);
if (buffering) {
chunkContext.setAttribute(INPUTS_KEY, inputs);
}
}
chunkProcessor.process(contribution, inputs);
chunkProvider.postProcess(contribution, inputs);
// Allow a message coming back from the processor to say that we
// are not done yet
if (inputs.isBusy()) {
logger.debug("Inputs still busy");
return RepeatStatus.CONTINUABLE;
}
chunkContext.removeAttribute(INPUTS_KEY);
chunkContext.setComplete();
if (logger.isDebugEnabled()) {
logger.debug("Inputs not busy, ended: " + inputs.isEnd());
}
return RepeatStatus.continueIf(!inputs.isEnd());
}이때 가장 먼저
Chunk<I> inputs = (Chunk<I>) chunkContext.getAttribute(INPUTS_KEY);
if (inputs == null) {
inputs = chunkProvider.provide(contribution);
if (buffering) {
chunkContext.setAttribute(INPUTS_KEY, inputs);
}
}inputChunk를 추출하여, 해당 청크를 그대로 chunkProvider에 제공하여 itemReader에 전달, itemReader 측은 이 inputChunk를 받아 반복호출을 시작한다.
여기서 알 수 있는 중요한 사실은 두가지이다.
- datasource로부터 itemReader가 read를 반복호출하여 chunk를 채울 필요가 있을때, input chunk가 비어있는 상태일 경우에만 진행한다.
- chunk가 이미 들어있는 상태라면, 그 input chunk를 그대로 활용한다.
일전에 내결함성 기능 활성화 시, itemProcessor나 itemWriter가 재시도할 경우 inputChunk 단위부터 그대로 재시작을 한다는 것을 알았는데, 바로 이 부분에서 그러한 이유가 발생이 되는 것이다.
즉, chunkContext 자체는 예외상관없이 자체적으로 유지한다. 따라서 해당 chunk가 비어있지 않은, 사용하지 않은 상태라면 해당 데이터를 그대로 활용하여 Processor가 이를 받아 처리를 지속할 수 있는 것이다.
그 후,
chunkProvider.provide(contribution);의 과정을 통해, 해당 구현체인 SimpleChunkProvider의 provide 로직을 진행한다.
이때,
@Override
public Chunk<I> provide(final StepContribution contribution) throws Exception {
final Chunk<I> inputs = new Chunk<>();
repeatOperations.iterate(context -> {내부적으로 chunkOperations(repeatTemplate)의 iterate() 메서드를 호출,
repeatOperations.iterate(context -> {
I item;
Timer.Sample sample = Timer.start(Metrics.globalRegistry);
String status = BatchMetrics.STATUS_SUCCESS;
try {
item = read(contribution, inputs);
}
...catch 생략...
..
inputs.add(item);
return inputs;itemReader의 구현체 read() 메서드를 반복호출하여, 처리할 item을 반환받고 있음을 확인할 수 있다.
이때 input은 최초 변수선언 시, Chunk 단일 객체이다.
그렇다면, iterate 자체가 반복 호출된다는 의미인데, 이 반복호출은 RepeatTemplate의 iterate가 하는 것이다.
SimpleChunkProvider는 멤버변수로
private RepeatOperations repeatOperations = new RepeatTemplate();repeatTemplate 구현체를 선언하여, 해당 repeatOperations.iterate()를 호출하였고, 결국 큰 틀에서는 해당 반복엔진을 기반으로 callback 구현체의 doInIteration을 반복호출하는 과정이 완성되는 것이다.
SimpleChunkProvider
└─ repeatOperations.iterate(람다)
↓
RepeatTemplate.iterate(RepeatCallback)
└─ while-loop
└─ 람다.doInIteration(context) ← 여기서 실행이때 repeatTemplate에서 반복호출하는 과정 중
return callback.doInIteration(context);이렇게 콜백구현체의 doInIteration을 반환하도록 전략패턴을 구성한 지점이 있는데,
이 지점이, Provider에 다시 돌아와서
repeatOperations.iterate(context -> {
I item;
Timer.Sample sample = Timer.start(Metrics.globalRegistry);
String status = BatchMetrics.STATUS_SUCCESS;
try {
item = read(contribution, inputs);
}
catch (SkipOverflowException e) {
// read() tells us about an excess of skips by throwing an
// exception
status = BatchMetrics.STATUS_FAILURE;
return RepeatStatus.FINISHED;
}
finally {
stopTimer(sample, contribution.getStepExecution(), status);
}
if (item == null) {
inputs.setEnd();
return RepeatStatus.FINISHED;
}
inputs.add(item);
contribution.incrementReadCount();
return RepeatStatus.CONTINUABLE;
});
return inputs;이 전략을 구현한 로직을 그대로 적용하여, 반복엔진의 while 기반의 callback read가 반복호출이 되는 것이다.
repeatTemplate이 iterate()를 통해, 반복적으로 callback의 doInIteration을 호출하는 것이 핵심 과정이고, 최종적으로 전략패턴으로 구현한 로직에서 read()를 반복호출하여 Chunk가 찰때까지 item을 읽어온다.
이때, 반복호출대상인 read()를 살펴보면
@Nullable
protected I read(StepContribution contribution, Chunk<I> chunk) throws SkipOverflowException, Exception {
return doRead();
}doRead()를 호출하는 것을 확인할 수 있고,
@Nullable
protected final I doRead() throws Exception {
try {
listener.beforeRead();
I item = itemReader.read();
if (item != null) {
listener.afterRead(item);
}
return item;
}
catch (Exception e) {
if (logger.isDebugEnabled()) {
logger.debug(e.getMessage() + " : " + e.getClass().getName());
}
listener.onReadError(e);
throw e;
}
}ItemListener의 beforeRead() 호출 후, 읽어올 item이 없다면 read() 종료로 판단하여 afterRead()를 호출한다. 그 후 item을 전달하고 있다.
더불어 읽는 도중에 예외가 발생하였다면 itemListener의 onReadError를 호출, 예외 상황에 대한 로직도 구성하였음을 확인할 수 있다.
그 다음은 반복엔진의 지속 혹은 종료, ItemReader의 수행기준인 RepeatStatus에 대한 구성에 대한 내용이다.
if (item == null) {
inputs.setEnd();
return RepeatStatus.FINISHED;
}더이상 읽을 item이 없다면, input은 그대로 종료시켜버리고(setEnd), RepeatStatus도 FINISHED 상태로 구성한다. 즉, dataSource로부터 더이상 읽을 아이템이 없다면 itemReader는 그대로 역할을 다하고 종료되는 것이다.
엥? 그렇다면 chunk처리 시 chunk size가 full하여 input chunk에 대한 read를 종료하고, 다음 chunk로 넘기는 과정은 어디있는걸까?
이에 대한 내용은 chunkOperations의 Policy구현체인, SimpleCompletionPolicy에서 isComplete에서 확인할 수 있다.
repeatTemplate을 자세히 살펴보면,
if (isComplete(context, result) || isMarkedComplete(context) || !deferred.isEmpty()) {
running = false;
}isComplete 정책을 만족하지 못하면 running = false, 반복 read를 중단하는 것을 알 수 있다(chunk size에 의한 다음단계 지속을 위함).
protected boolean isComplete(RepeatContext context, RepeatStatus result) {
boolean complete = completionPolicy.isComplete(context, result);
if (complete) {
logger.debug("Repeat is complete according to policy and result value.");
}
return complete;
}이때 사용하는 isComplete 정책은 SimpleCompletionPolicy의 isComplete 정책과 동일하며, 부모 클래스인 DefualtReulstCompletionPolicy의 isComplete 정책여부를 선제적으로 판단한다.
@Override
public boolean isComplete(RepeatContext context, RepeatStatus result) {
return super.isComplete(context, result) || ((SimpleTerminationContext) context).isComplete();
}이에 따라,
public boolean isComplete() {
return getStartedCount() >= chunkSize;
}위와 같이 chunkSize와 동일한 chunk read를 만족하였다면, 다음 chunk를 읽기 위해 해당 단계에서의 read 반복호출을 중단한다.
참고로, super.isComplete는 부모 클래스인 DefaultResultCompletionPolicy의 isComplete 정책과 같이, 모든 기준에 대해 지속여부를 판단하며,
@Override
public boolean isComplete(RepeatContext context, RepeatStatus result) {
return (result == null || !result.isContinuable());
}이는 RepeatStatus가 Finished일 경우를 말한다(tasklet지향 처리의 상태반환값이 중지일 경우, 혹은 지금처럼 Provider 측에서 더이상 읽을 아이템이 없어 itemReader가 상태반환값을 FINISHED로 반환하였을 경우이다(chunk size를 채우지 못하여도 더이상 읽을 item이 없으면 상태반환값을 FINISHED로 반환하여 읽기를 종료할 수 있다).
즉, 정리하면
- Provider에서 읽을 아이템이 null
-> dataSource에서의 읽을 아이템 없음 : itemReader의 종료
-> chunk size를 모두 못채웠지만 읽을 아이템 없음 : itemReader의 종료 - SimpleCompletionPolicy에 의해 chunk size 이상의 아이템 처리 시
-> policy 조건을 만족하지 않아 running = false, 반복중단
-> RepatStatus 상태값을 FINISHED로 설정하여 반복 중단
의 과정으로 read의 지속여부를 판단하게 된다.
이후,
inputs.add(item);
contribution.incrementReadCount();
return RepeatStatus.CONTINUABLE;읽은 chunk 객체를 넣고(Chunk객체는 내부적으로 list 자료구조를 담고 있고, 이 list에 데이터를 넣는다), contribution의 readCount를 증가하여 상태내역을 관리하고(StepExecution에 저장) 상태반환값을 CONTINUABLE로 반환하여 read를 지속한다.
단일 chunk객체를 반환하여 buffer에 담는 것이고, 이 담는 과정을 반복호출하여 buffer에 chunk size만큼 차게 되면 read는 종료, ChunkProcessor에게 넘겨 chunk에 대한 itemReader 과정을 마치는 것이다.
다시 ChunkOrientedTasklet의 execute 시점으로 돌아와보자.
inputs = chunkProvider.provide(contribution);이처럼 ChunkProvider.provider를 호출하여 받아온 Chunk(내부적으로 list) 객체는 inputs 변수에 담겨져,
chunkProcessor.process(contribution, inputs);위와 같이 ChunkProcerssor에게 전달된다.
ChunkProcessor의 구현체인 SimpleChunkProcessor를 살펴보도록 하자.
@Override
public final void process(StepContribution contribution, Chunk<I> inputs) throws Exception {
// Allow temporary state to be stored in the user data field
initializeUserData(inputs);최초 initializeUserData 메서드를 호출하는 것부터 시작하는데,
protected void initializeUserData(Chunk<I> inputs) {
inputs.setUserData(inputs.size());
}위와 같이 입력받은 chunk list의 크기를 설정해준다.
이후,
if (isComplete(inputs)) {
return;
}input chunk에 대한 process 처리여부를 결정하는데,
protected boolean isComplete(Chunk<I> inputs) {
return inputs.isEmpty();
}위와 같이 inputChunk가 비어있다면 process를 진행하지 않는다. 당연한 것이다. ItemReader로부터 전달받은 처리내역이 없다면 process는 진행할 이유가 없다.
이후,
Chunk<O> outputs = transform(contribution, inputs);transform()을 통해 input chunk를 ouput chunk 형태로 변환하는 것을 확인할 수 있다.
어디서 많이 본 형태인데, Chunk<I,O> 바로 줄기차게 봐왔던 Input, Output 형변환이 바로 이 시점에서 발생하는 것이다.
자세히 살펴보자.
protected Chunk<O> transform(StepContribution contribution, Chunk<I> inputs) throws Exception {
Chunk<O> outputs = new Chunk<>();먼저 output으로 변환할 chunk(리스트) 객체를 생성한다.
for (Chunk<I>.ChunkIterator iterator = inputs.iterator(); iterator.hasNext();) {
final I item = iterator.next();
O output;
Timer.Sample sample = BatchMetrics.createTimerSample(this.meterRegistry);
String status = BatchMetrics.STATUS_SUCCESS;
try {
output = doProcess(item);
}이후, 리스트를 iterator 순회를 하면서 output 객체(O type 선언 후, 이 output 변수로 사용)에 doProcess를 통해 변환한 형태를 그대로 넣는다.
ItemProcessor에서 정의한 process는 바로 이 doProcess를 통해 진행이 되는 것이고, 이 과정을 통해 Writer에게 전달될 Output 객체가 탄생하는 것이다.
doProcess에 대해 더 자세히 살펴보자.
if (itemProcessor == null) {
@SuppressWarnings("unchecked")
O result = (O) item;
return result;
}Processor는 기본적으로 생략 가능한 컴포넌트로, 만약 직접 구성하지 않으면 위와 같이 null 분기를 거쳐서 item 객체를 바로 Output객체형태로 형변환(O)하여 return한다.
try {
listener.beforeProcess(item);
O result = itemProcessor.process(item);
listener.afterProcess(item, result);
return result;
}
catch (Exception e) {
listener.onProcessError(item, e);
throw e;
}만약 Processor를 구성하였다면, 위와 같이 ProcessListener의 befroeProcess를 호출한 후 itemProcess를 진행하며, 이후 afterProcess까지 거치게 된다.
process를 진행한 후에, writer에게 넘길 output 객체를 리스트에 담는다.
만약 처리 과정에서 예외가 발생하면, Listener.onProcessError를 통해 후처리를 진행한다.
그리고, 다시 SimpleChunkProcessor의 다음 단계인 incrementFilterCount 메서드를 호출하여 진행한다.
contribution.incrementFilterCount(getFilterCount(inputs, outputs));이 메서드는 별다른 과정 없이, 넘겨받은 count를 그대로 filterCount에 저장하고 있다.
public void incrementFilterCount(long count) {
filterCount += count;
}그렇다면, 이 getFilterCount는 어떠한 count를 넘기는지 보았더니
protected int getFilterCount(Chunk<I> inputs, Chunk<O> outputs) {
return (Integer) inputs.getUserData() - outputs.size();
}이와 같이 넘겨받은 input chunk의 크기에서 담겨진 output chunk의 크기를 뺀값, 즉 process된 item의 갯수를 의미한다.
process를 처리할때마다 contribution에 반영되어, StepContribution 내부적으로 stepExecution에 반영하는 것이다. 이 과정으로 인해 chunk 지향처리의 chunk size 확인이 매 process 처리마다 가능한 것이다.
그리고 최종적으로,
write(contribution, inputs, getAdjustedOutputs(inputs, outputs));를 진행하여, write한다.
ChunkProcessor 컴포넌트는 Processor와 Writer가 모두 들어있기에, 읽어온 아이템을 process하고 write하는 과정이 모두 담겨져있다.
write과정은 더 간단하다.
protected void write(StepContribution contribution, Chunk<I> inputs, Chunk<O> outputs) throws Exception {
Timer.Sample sample = BatchMetrics.createTimerSample(this.meterRegistry);
String status = BatchMetrics.STATUS_SUCCESS;
try {
doWrite(outputs);
}
catch (Exception e) {
/*
* For a simple chunk processor (no fault tolerance) we are done here, so
* prevent any more processing of these inputs.
*/
inputs.clear();
status = BatchMetrics.STATUS_FAILURE;
throw e;
}
...
contribution.incrementWriteCount(outputs.size());
}위와 같이, 전달받은 output(chunk list)를 doWrite하여 데이터를 최종적으로 write 하게되며, 만약 내부적으로 예외 상황이 발생하면 (내결함성 기능 동작 시) input을 clear하여 Processor 단계부터 다시 처리를 시작한다.
그리고, 이 모든 과정을 끝마친 후는 모든 데이터를 write완료한 상태이기에 output 리스트의 크기를 그대로 contribution에 반영, stepExecution에서 상태를 최종 저장하게 된다(=데이터 쓰기 완료 판단).
참고로, doWrite는 아래와 같이 진행된다.
protected final void doWrite(Chunk<O> items) throws Exception {
if (itemWriter == null) {
return;
}
try {
listener.beforeWrite(items);
writeItems(items);
doAfterWrite(items);
}
catch (Exception e) {
doOnWriteError(e, items);
throw e;
}
}Output 객체 리스트를 받아서, 쓰기 전에 WriterListener의 beforeWrite를 호출하고, item write 후 afterWrite를 호출한다.
write 과정에서 예외 상황이 발생할 경우, doOnWriteError를 발생시킨다.
ChunkOrientedTasklet은 이러한 write과정까지 마친 후,
return RepeatStatus.continueIf(!inputs.isEnd());위와 같이 상태반환값을 TaskletStep에게 전달하여, TaskletStep은 이 전달받은 값에 따라, 반복엔진(RepeatTemplate)의 반복 호출결과를 저장한다.
result = tasklet.execute(contribution, chunkContext);이러한 상태값은 최종적으로 TaskletStep의 doExecute내부의 iterate 메서드를 따라가게되며, transactionTemplate의 트랜잭션 컨텍스트에 상태를 반영하고 최종적으로 아래와 같은 Chunk에 대한 트랜잭션을 완료한다.
return result == null ? RepeatStatus.FINISHED : result;이때 트랜잭션 완료 시, 상태반환값을 FINISHED하여 반환하고,
마찬가지로 CompletionPolicy가 상태반환값을 보고 Chunk처리가 완료되었다고 판단하여 Chunk 트랜잭션 처리를 완료처리, 다음 Chunk 처리로 넘어가게 되는 것이다.
6. SimpleStepHandler의 고찰 - TaskletStep execute 및 트랜잭션 종료, 그 이후 AbstractStep의 Step 종료과정
이제 AbstractStep의 doExecute를 실행하는 과정을 분석하는 과정을 마치고, 그 다음 Step 인스턴스에 대한 내용을 정리해보도록 하자.
doExecute를 통해 Step 실행과정을 마친 후, stepExecution에 상태를 반영하고 jobRepository에도 상태를 최신화한다.
그 후,
doExecutionRelease();과정을 진행하게 되는데,
protected void doExecutionRelease() {
StepSynchronizationManager.release();
}threadLocal에 있는 Step 인스턴스 정보를
public void release() {
C context = getContext();
try {
if (context != null) {
close(context);
}
}
finally {
close();
}
}아래와 같이 최종적으로 close하는 과정, 즉 자원 초기화 항목을 모두 닫는 과정을 진행하게 된다(threadLocal의 stepExecution, stepContext 정보를 clear).
이걸로 Step 진행은 완전히 종료되었다.
7. 결론
Step를 진행하기 위해 자원초기화, 그리고 내부적으로 반복엔진을 호출하여, callback 구현체를 반복 진행, 이를 통한 tasklet 반복 진행, 그리고 마지막으로 threadLocal의 자원을 close하면서 완전한 자원해제까지, Step 실행의 전반적인 개념을 살펴보고 분석해보는 매우 긴 과정을 진행해보았다.
사실 이번 1번으로는 절대 완벽하게 이해를 하지 못하였기에, 2~3번 반복하여 읽어보고, 무엇보다 직접 실행하면서 내부 흐름을 디버깅해보는 등 수많은 시행착오와 반복학습을 더 해야 온전히 이해가 갈 수 있을 것이다.
물론, 지금 1번 살펴보면서 대략적인 흐름, spring batch가 지향하는 설계적 사상 및 구조, step 실행과정 등을 파악한 것만으로도 엄청난 수확이라 생각한다(다만 만족하지 말고 더 정진해야한다).
또한 흥미로운 점은 이러한 엄청난 콜백이 있는 와중에, 템플릿 메서드 패턴과 전략 패턴이 무수히 많이 사용되어 boiler plate를 줄이고, OOP의 진가를 다시 한번 느낄 수 있기도 하였다는 점이다.
긴 여정을 거쳐오면서 여러가지 많은 수확, 동시에 숙제를 얻었던 기간이었다.
개인 프로젝트를 진행하면서 주어진 시간이 별로 없기에, 일단 다음 단계로 넘어가도록 하고, spring batch의 전체적인 콜백과정은 시간이 좀 더 여유로울때, 실무적 경험을 하면서 자연스럽게 체득하는 것이 가장 좋겠지만, 추후에 다시 꼭 살펴보도록 하자.
