[개발지식] Web Application의 상호보완적 Eventually Consistency #15 - Spring batch의 실행, 실행 정보의 저장 및 관리까지, Job/Step의 execution 및 context에 대한 고찰
개발지식
1. 개요
Spring batch의 핵심 동작 과정에 대해 살펴본 지난 시간에 누적하여, 이번에는 커맨드라인부터 전달된 명령어를 시작으로, job을 최초 동작하는 Job Launcher/Job Runner 및 job을 동작하면서 실시간 반영하는 상태(메타)데이터들을 구체적으로 어떻게 관리하고, 저장할 것인지에 대해 분석해보고자 한다.
표제를 "고찰"이라고 한 만큼, 이번에도 꽤나 깊숙하게, 구체적으로 그 개념과 본질에 대해 접근하고 파악해보고자 한다.
spring batch는 일전에도 한번 언급하였지만, "프레임워크", 하나의 거대한 체계이다.
이러한 거대한 체계를 유연하고 명확하게 다루기 위해서는, 내부적으로 어떠한 원리, 구조, 메커니즘을 가지고 동작하는지 이해하는 것이 반드시 전제되어야 할 것이며, 온전히 이해하지 못하더라도 그 구조와 사상에 대해 "공감"을 어느 정도는 해야하지 않을까 생각한다.
그 과정 중 하나로, 상태정보에 대한 고찰을 해보고자 한다.
2. Job Squad 컴포넌트 - 상태(메타)데이터 관리
Spring batch는 앞에서 살펴본 step 전역에 대한 stepSquad이외, job상태관리 및 job 실행 등을 관리하는 jobSquad, 그러한 내역을 저장하는 database 영역으로 구분되어있다.
이 중 jobSquad는 말 그대로 job의 상태, 실행을 관리하는 컴포넌트들의 집합이다.
spring job을 아무리 견고하게 꼼꼼하게 설계, 구성하였다 하더라도 외부적 요인(네트워크 오류 등) 및 내부적 요인(예상치 못한 memory leak)에 의해 언제든지 실행 도중에 문제가 발생할 수 있다.
만약 단순 for순회 등을 통한, batch라고 하기에는 곤란한 점이 많은 로직을 작용하였다면 실패지점을 기록하지 않고 단순 동작으로만 진행하기에, 하나라도 문제가 발생하면 전체 데이터에 대한 롤백을 진행, 비효율적일뿐더러 일관성, 정합성 측면에서도 불리할 수 밖에 없다.
이러한 이유로, 대규모 데이터를 다루는 spring batch 작업 특성상 작업추적, 상태저장, 실패지점 기억 및 재시작은 필수적 요소이다.
이러한 작업 추적, 상태저장, 실패지점 기억 및 재시작을 위한 데이터를 메타데이터, 상태데이터라 하며 이를 저장하는 저장소를 메타데이터 저장소라 한다.
이 메타데이터의 "종류", 내부적으로 이러한 메타데이터를 어떻게 저장하고 관리하는지 분석해보고자 한다.
2-1. jobInstance
job의 논리적 실행단위는 jobInstance로 나뉘어 실행되며, job이 "어떤 작업"에 대해 설명한 명세라면, jobInstance는 이 명세를 구체적으로 "어떻게", "언제, 어떤 데이터로 실행하는지"에 대한 설계이다.
job : 일간 이상담보거래내역 추출
- instance for 신용담보 (AM 1 ~ 2)
- instance for 부동산담보 (AM 2 ~ 3)만약 일간 이상담보거래내역을 추출하는 job이 있다고 하면, 신용대출담보/부동산담보 등 담보종류에 따라 각기 다른 job도메인, 실행시간, 로직으로 jobInstance는 분리되어 설계될 수 있다.
그렇다면 이러한 instance를 구분하는 기준은 무엇일까?
new JobBuilder("forCredit", jobRepository);jobBuilder 구성 시 jobName으로 지정해주었던 이름이, job을 구분하는 key값이 되어 각 job을 구분해주는 구분자가 되어주는 것이다. 이제 더 나아가, 동일한 "job" 이름으로 내부 jobInstance를 구분해주는 요인은 바로 jobParameters이다.
2-2. jobParameters
jobParameters는 job을 실행하기 위해 필요한 단순 매개변수의 기능을 넘어, jobInstance를 구분하여 "서로 다른 데이터의 처리", 즉 도메인적 구분을 해주는 중요 요소이다.
job(일간 이상담보거래내역 추출) + jobParameters(time = AM01:00, AM02:00)
job(일간 이상담보거래내역 추출) + jobParameters(time = AM02:00, AM03:00)이처럼 동일한 job이라도, jobParameters가 다르면 jobInstance가 구분되어, 도메인적으로나 논리적으로나 완전히 다른 처리 단위가 되어버리기에, jobInstance의 "정체성"이라 할 수 있다.
2-3. jobExecutions
jobExecution은 jobInstance의 실행시도내역, 실행이력(내역)을 메타데이터 저장소를 기반으로 관리한다.
일전에 "예상치 못한 오류로 인한 실행 중단" 상황이 발생한다고 하였는데, 이 의미는 "jobInstance"의 오류라 할 수 있겠다. 만약 이 상태에서 jobInstance의 실행중단이 발생한다면, JobExecution이 해당 jobInstance에 대한 실행상태 및 재시도 내역 등에 대한 메타데이터를 꼼꼼하게 기록, 저장한다.
Job(일간 이상담보거래내역 추출)
JobInstance(time = AM0100, AM0200)
JobExecution(id = 1)
status FALIED
startTime AM 01:00
endTime AM 01:20
exitCode 01
failureExceptions RuntimeException
JobExecution(id = 2)
status FALIED
startTime AM 01:20
endTime AM 01:40
exitCode 00
failureExceptions null이처럼, jobExecution은 현재상태(status)/시작시간/종료시간/종료코드(최종결과)/실패 시 실패원인 등으로 프로퍼티를 나누어 실행내역을 저장한다.
참고로, 현재상태(실행상태)의 경우, batchStatus 프로퍼티로 관리하며,
- COMPLETED : 작업완료
- STARTING : 실행직전
- STARTED : 실행중
- STOPPING : 중지요청으로 인한 중지 중
- STOPPED : 작업 중지됨
- FAILED : 실패
- ABANDONED : 비정상 종료로 인한 재시작 불가 상태
- UNKNOWN : 상태확인불가 상태
위 8가지 작동상태에 대한 상태값으로 관리하며, 이러한 상태를 통해 배치실행내역 및 상태값을 추적 관리가 가능해진다.
실제로,
SELECT * FROM BATCH_JOB_EXECUTION의 내역을 조회해보면,
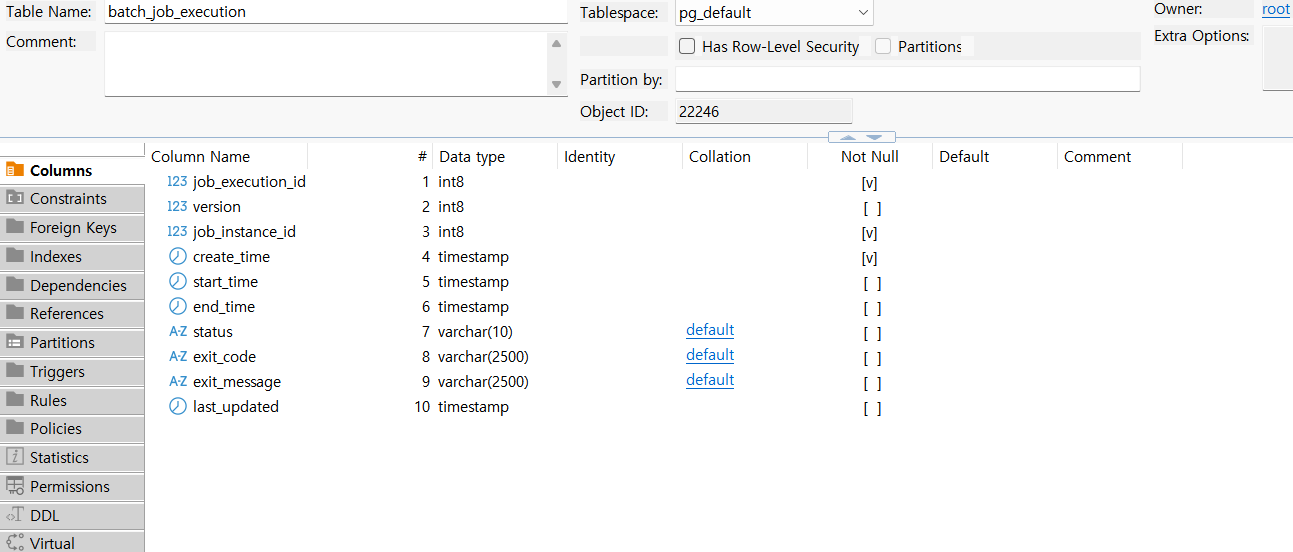
위와 같이 상태내역을 관리하는 것을 확인할 수 있다.
2-4. COMPLETED jobInstance 재실행 불가 원칙
Spring batch job을 실행할때 중요한 원칙은 한번 "완료한" "jobInstance"의 "재시작"을 차단한다는 것이다.
즉, jobInstance(job + jobParameters)의 실행 이력(jobExecution)을 조회하여, 해당 jobExecution의 batchStatus가 COMPLETED라면 해당 jobInstance의 재시작은 불가능하다.
이때 jobExecution은 H2, Postgresql과 같은 RDB에 저장, 기록한다. 이러한 상태내역을 저장하기 위한 RDB가 연결되어있지 않거나, 저장 불가능한 상태라면 job 실행자체를 하지 못하는 근거가 바로 여기에 있다.
참고로 일전에 작성하였던 job의 경우 application.yml에 drop schema를 설정해두었고, batch설정 역시 initialize-schema 설정을 always로 해두었기때문에 application, batch 실행 시 마다 job 실행내역(jobExecution)을 최소화할 수 있었다(쉽게 말해 jobExecution이 남지 않았기때문에 재실행 가능).

initialize-schema 설정의 경우, batch 실행할 때 DB가 없으면 만들어주는 설정이기에 가만히 두고, drop schema 설정만 주석처리해보자.
그러면, 최초 실행 시 아래와 같이 정상적으로 상태내역을 저장한다.

이후 동일한 job을 동일한 jobParameter로 재실행하면,

위와 같이 IllegalStatmentException이 발생하고,

동일한 job instance를 재실행할 수 없는 오류메시지와 함께 job 실행을 막아버린다.

job 실행을 막아버리기에, 당연히 BATCH_JOB_EXECUTION에 저장된 상태내역은 그대로이다.
2-5. jobInstance 중복 실행 허용 - JobParamteresIncrementer
이러한 spring batch의 엄격한 재실행 방지 원칙 환경에서, 중복실행해도 멱등성이 보장되거나 덮어씌우기를 통해 batch job 보완이 가능한 상황일경우, 유연하게 동일한 spring job을 여러번 중복 실행할 수 있게 하는 특수 컴포넌트이다.
@FunctionalInterface
public interface JobParametersIncrementer {
/**
* Increments the provided parameters. If the input is empty, this method should
* return a bootstrap or initial value to be used on the first instance of a job.
* @param parameters the last value used
* @return the next value to use (never {@code null})
*/
JobParameters getNext(@Nullable JobParameters parameters);
}jobParametersIncrementer는 위와 같이 funcutionalInterface(전략인터페이스) 이며, jobParameters를 전달받아 마치 시스템이 새로 전달받은 매개변수인 마냥 변형된 동작을 취하게 된다. 이로 인해 spring batch 측에서는 매번 새로운 job으로 인식, jobInstance의 중복 실행이 가능하게 된다.
구현체인 RunIdIncrementer를 살펴보자.
@Override
public JobParameters getNext(@Nullable JobParameters parameters) {
JobParameters params = (parameters == null) ? new JobParameters() : parameters;
JobParameter<?> runIdParameter = params.getParameters().get(this.key);
long id = 1;
if (runIdParameter != null) {
try {
id = Long.parseLong(runIdParameter.getValue().toString()) + 1;
}
catch (NumberFormatException exception) {
throw new IllegalArgumentException("Invalid value for parameter " + this.key, exception);
}
}
return new JobParametersBuilder(params).addLong(this.key, id).toJobParameters();
}jobparameters의 매개변수인 parameter를 받아, 이전의 id값을 +1 해주는 로직을 살펴볼 수 있다.
jobInstance의 상태정보를 관리하기 위한 또 하나의 핵심 테이블은 BATCH_JOB_INSTANCE인데, 이를 조회해보면 아래와 같이 job_instance_id, job_name, job_key를 관리하는 테이블이다.

이 중 job_instance 실행 시, jobParameter의 run.id값이 달라져 최종적으로 job key의 hash값이 달라지게 된다. 이 경우, JOB_KEY가 달라져 batch 시스템은 이를 다른 jobInstance로 인식, 동일한 job parameter라 할지라도 중복실행이 가능하게 되는 것이다.
RunIdIncrementer를 적용하기 위해서는,
return new JobBuilder("brutalizedSystemJob", jobRepository)
.incrementer(new RunIdIncrementer())위와 같이 incrementer를 적용하면 된다.

위 설정을 적용한 후 재실행 시, 정상적으로 재실행하는 것을 확인할 수 있으며 job key hash값은 예상대로 일전의 값과 다른 값으로 변형되어, 새로운 job으로 누적 관리되었음을 확인할 수 있다(위 그림).
또한 더불어, job parameter를 살펴보면 run_id가 추가되어있는 것을 확인할 수 있다.


job parameter를 유심히 살펴보면 run id가 추가되었고, 해당 값이 이전의 1에서 현재의 2로 increment되었음을 확인할 수 있다.
다만, 이 방법은 위와 같이 어떻게 보면 "트릭"과 같은 속임수, 사실상 정상적인 재실행 방지를 다소 억지스럽게 차단하는 컴포넌트이기에 무분별한 사용은 권장되지 않고, 기본적인 재실행 금지 원칙을 따라가는 것이 좋겠다(batch 설계나, 실제 처리에 있어서 데이터 정합성 등의 위험요소를 제거하기위해).
2-6. jobParameter의 구분자로써의 기능 - identifying
그런데, 위 job parameter를 유심히 살펴보면 끝에 identifying=true라는 요소가 붙어있음을 확인할 수 있다.
이 설정은 job parameter가 jobInstance를 식별하는데 사용한다는 의미로, 기본적으로 true로 설정을 해야 해당 jobParameter를 jobInstance의 구분자로 활용을 하겠다는 의미이다.
identifying 요소는 특정 매개변수에 대해 설정할 수 있으며, 이는(parameterName=value,type,identifying) 형태로 parameter를 전달하면서 구분자에 대한 옵션을 지정해줄 수 있다.
만약 이를 false로 설정한다면, 해당 jobParameter 매개변수는 jobInstance 식별에 사용하지 않으며, 동일한 jobInstance로 간주하여 재실행을 방지할 수 있다.
예를 들어, chunk size(성능튜닝) 및 출력 경로와 같은 파라미터를 조정하더라도 이에 대한 jobInstance는 굳이 구분하여 재실행할 필요가 없어진다. 이 역시 단순한 옵션에 대해 false로 설정한다면 불필요한 재실행을 방지할 수 있겠지만, 핵심 옵션에 대해서는 신중한 고려를 통해 매개변수 설정이 이루어져야겠다.
2-7. 재실행 불가설정 및 최초지점부터 다시 시작해야 하는 경우 - restartable
위와 같이 jobInstance의 구분자 요소 중 구분자로써의 기능을 막고 의도적으로 재실행을 불가능하도록 구성해줄 수 있다면, 이번엔 더 나아가 실패하였을때 재시작이 아닌, 다시 실행을 하지 못하도록 재시작 불가 처리를 할 수 있다.
.preventRestart()이는 preventRestart() 설정을 해주면 되는데, 이 역시도 웬만해서는 사용하지 않는 것을 권장한다.
2-8. StepExecution
jobExecution 세부적으로는 여러 step의 실행내역을 관리하는 stepExecution이 존재한다.

위와 같이, 어떠한 job에 속한 어떠한 step을, 어떻게 실행하였는지 BATCH_STEP_EXECUTION을 통해 상태내역을 저장하며, 해당 step이 실행할 경우에만 생성된다. step이 오류로 인해 실행불가하였다면, step execution은 생성되지 않는다.
step execution 프로퍼티는 아래와 같이 관리된다.
- step exection id : stepExecution 구분자
- step name : 실행한 step명
- status : step의 현재 상태
그리고, stepExecution을 운용하는 목적이자 step 상태관리의 핵심 내용으로,
- commit_count : 커밋 개수
- read_count : 읽은 개수
- filter_count : 정상적인 batch 실행 중 해당 데이터를 처리하지 않고, 그냥 넘어간 횟수(proess의 특정 로직으로 인해 null을 반환하였다면, 정상적인 처리로 간주하며 이를 filter count로 증가)
- write_count : write 개수
- read_skip_count : 읽음 건너뛴 개수
- write_skip_count : write 건너뛴 개수
- process_skip_count : process 건너뛴 개수(skip 정책 적용 시, process에서 이를 발생한 횟수)
- rollback_count : rollback 횟수
이외 프로퍼티는 job execution과 유사하다.
- exit_code : step 실행결과
- exit_message : 예외발생시 발생한 예외에 대한 내용
이처럼, stepExecution만이 관리하는 자세한 step 상태내역과 함께, jobExecution과 함께 exit status(batch status)까지 관리한다.
StepExecution에서 관리하는 batch status가 중요한 이유는, job execution에서 해당 job의 최종 성공여부를 가장 마지막에 실행한 step의 stepExecution.batchStatus로 판단하기 때문이다.
만약, stepExecution에서 exit status가 "FAILED"라면, 그 이후의 step은 아예 실행하지 않기에 가장 마지막 step에 대한 exit status는 "FAILED"로 최종 기록(다음 stepExecution은 남아있지도 않음), 해당 job은 최종 실패처리로 기억되는 것이다.
이를 job의 step까지의 상태전파라고 하는데, 이에 대해 더 자세히 알아보도록 해보자.
2-9. 실패/재시작 시 StepExecution 동작
job이 실패하여 job을 재실행한다면, jobExecution은 새로운 상태데이터가 누적되어 쌓인다. 이때 job이 새롭게 시작된다면, step 입장에서도 종속된 상태로 재시작되므로 새로운 데이터가 같이 따라서 생성이 되는 것이다.
step 개별적으로 살펴본다면, step도 마찬가지로, retry정책을 활성화하여 실패 시 재시도하였다면 stepExecution은 새로운 stepExecution 데이터를 누적하여 쌓는다.
step은 chunk size 단위로 처리되기에, 일전에 성공한 step은 다시 실행하지 않는다. 이로 인해 당연히 DB에 해당 내역(StepExecution)을 재기록하지도 않는다. 실패하였을 경우에만 step을 다시 실행하는 것이고, 이를 DB에 재기록하는 것이다.
stepExecution은 단순히 상태내역을 기록하는 저장소의 의미를 넘어, 이를 활용하여 Step의 처리시간(end_time) 및 어떠한 데이터에 대해 process의 filter 혹은 skip이 많이 발생하였는지, 어떠한 부분에서 rollback이 많이 발생하였으며, 어떠한 부분에서 대규모 데이터 처리(commit count)가 많이 발생하였는지 모니터링 지표로 활용할 수 있다는 점에서 중요하다.
2-10. ExecutionContext
ExecutionContext는 배치 작업의 상태(state)를 저장하고 복원하기 위해 key-value의 Map 자료구조 형태로 보관하는, 개발자가 직접 지정해준 값 혹은 프레임워크 측에서 자동적으로 관리, 저장하는 값으로 되어있다.
ExecutionContext는 job 전체를 관리하거나,
stepExecution.getJobExecution().getExecutionContext();step 단위를 관리하거나,
stepExecution.getExecutionContext();위와 같이 두 계층에서 관리가 가능하고, 개발자가 해당 context에 저장한 특정 변수 혹은 프레임워크 측에서 관리해주는 변수를 저장한다.
executionContext.putInt("currentPage", 5);
executionContext.putLong("lastProcessedId", 10342L);
executionContext.put("fileOffset", 2048L);개발자 측에서 관리하는 변수의 경우, page나 이전에 처리한 last index 혹은 last id 등과 같은 중간집계성 데이터를 그 예로 들 수 있겠다.
| 컴포넌트 | 저장 내용 |
|---|---|
| ItemReader | 현재 read 위치 |
| ItemWriter | flush/commit 관련 상태 |
| FlatFileItemReader | 현재 라인 번호 |
| JdbcPagingItemReader | 마지막 페이지 정보 |
| Chunk 기반 Step | commit 시점 정보 |
프레임워크 측에서 관리해주는 변수라면, 위와 같이 itemReader, itemWriter 등 각 컴포넌트 별로 비즈니스 로직 중에 실시간으로 발생하는 데이터에 대해 저장, 관리하는 방안을 제공한다.
이를 영속화하면, 각각 BATCH_JOB_EXECUTION
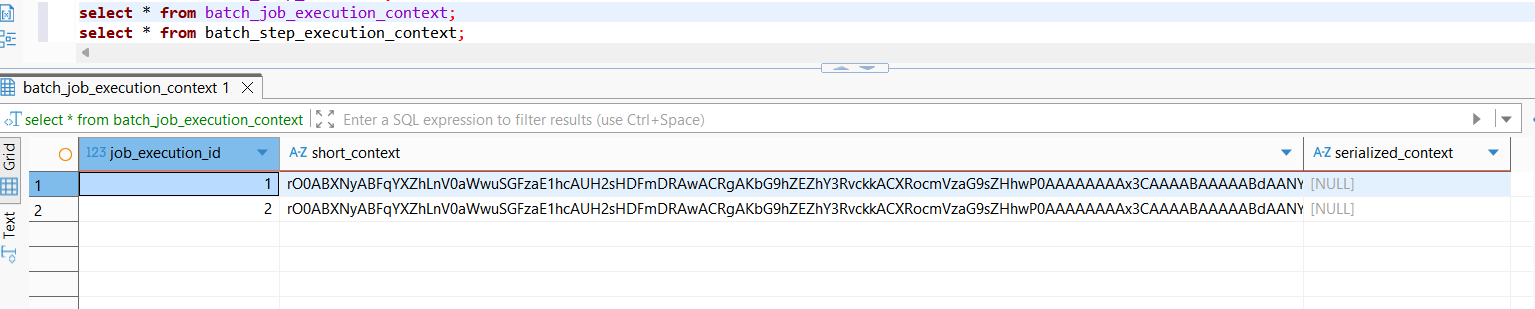
그리고 STEP_JOB_EXECUTION이다.
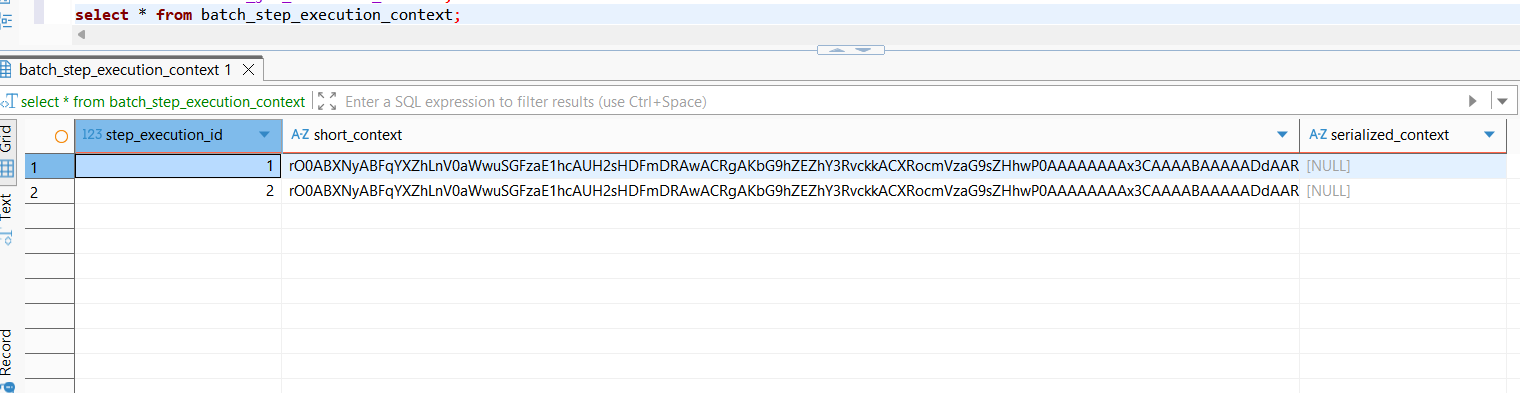
이때 1개의 step은 1개의 step execution에 매핑이 되며, 트랜잭션 커밋직전에, chunk 커밋 직전에 영속화하여 저장한다.
지금은 테스트를 위한 간단한 step만 진행하였기에 serialized context가 null인 상태인데, 체계적인 구성을 통해 step의 데이터를 직렬화한 내용을 이 항목에 저장한다.
일전에 분석하였던 itemStream의 자원관리를 위한 open, update api를 기억하는가?
이때 open은 위의 영속화한 데이터를 executionContext로 다시 추출해오고, 이전의 실행상태를 복원하며, update는 현재의 실행상태를 executionContext에 반영하고 저장하는 역할을 한다.
이러한 메커니즘이 동작하기 때문에, DB가 무조건 필요한 것이고 재시작/복원이 가능하며, itemStream의 open, update를 통한 상태복원 및 추출이 진행되는 것이다.
그리고, jobExecution에 대한 내용이 step으로 까지는 상태전파 및 공유가 가능하지만, step의 execution 내용은 step 내에서만 유효하며 job에서 접근 불가능하다는 것을 기억하는가?
위에서 살펴볼 수 있듯이, stepExecution은 jobExecution과 아예 물리적으로 데이터가 구분되어 저장이 된다. 진행하는 step 하나하나에 대해 철저하게 구분하겠다는 spring batch의 설계사상이 담겨져 있다.
2-11. 메타데이터 테이블
위와 같이, job 실행, step 실행 및 실행 중간의 execution 내역 저장 시 이루어지는 상태관리 및 이에 대한 테이블 구조를 잠깐 살펴보았다.
사실 위에서 살펴본 5가지 테이블 이외,
BATCH_JOB_EXECUTION
BATCH_JOB_INSTNACE
BATCH_STEP_EXECUTION
BATCH_JOB_EXECUTION_CONTEXT
BATCH_STEP_EXECUTION_CONTEXT한가지 더 있긴 하다.
BATCH_JOB_EXECUTION_PARAMS하지만 위에서 살펴보았듯이 테이블명에서부터 어떠한 역할을 하는지 어느 정도 추론이 가능하기도 하고, 실제로 테이블을 살펴보면 어떠한 메타데이터를 저장하는지 한눈에 보이기 때문에 간략하게 살펴보고 넘어가보도록 하겠다.
- jobInstance
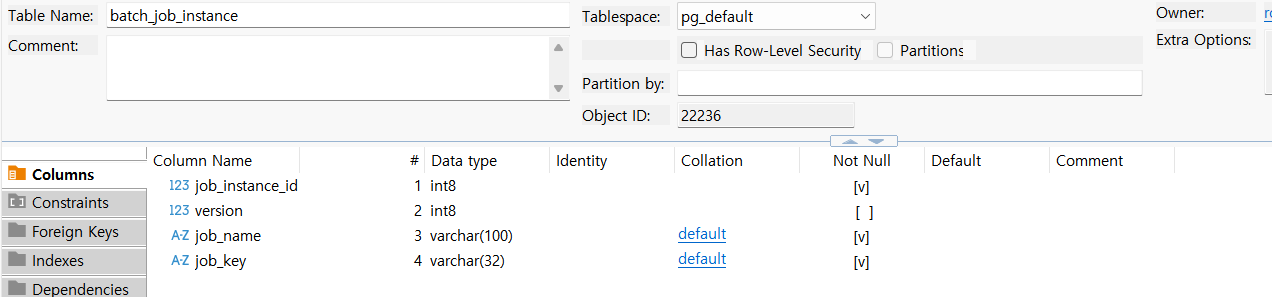
job instance는 말 그대로 spring batch의 논리적인 최소 실행 단위인 job에 대한 상태내역으로, job의 이름 등에 대한 저장소이다.

위와 같이, PK는 job instance id이지만 job name, job key 모두 유니크 제약 조건을 걸어 job name과 job parameter가 중복실행되지 않도록 방지해주었다. version id는 낙관락 사용을 위한 컬럼으로, jobInstance는 동시성 문제가 발생할 이유가 없으므로 항상 0이다.
public class JobInstance extends Entity {
private final String jobName;
/**
* Constructor for {@link JobInstance}.
* @param id The instance ID.
* @param jobName The name associated with the {@link JobInstance}.
*/
public JobInstance(Long id, String jobName) {
super(id);
Assert.hasLength(jobName, "A jobName is required");
this.jobName = jobName;
}
/**
* @return the job name. (Equivalent to {@code getJob().getName()}).
*/
public String getJobName() {
return jobName;
}
/**
* Adds the job name to the string representation of the super class ({@link Entity}).
*/
@Override
public String toString() {
return super.toString() + ", Job=[" + jobName + "]";
}
/**
* @return The current instance ID.
*/
public long getInstanceId() {
return super.getId();
}
}이에 대한 도메인 객체 역시, 위 4개의 프로퍼티로 관리하고 있으며 jobName과 jobParameter가 hash화되어 job_key로 영속화하여 관리한다. (상위 부모클래스인 entity에서 id와 version id를 관리)
- jobExecution
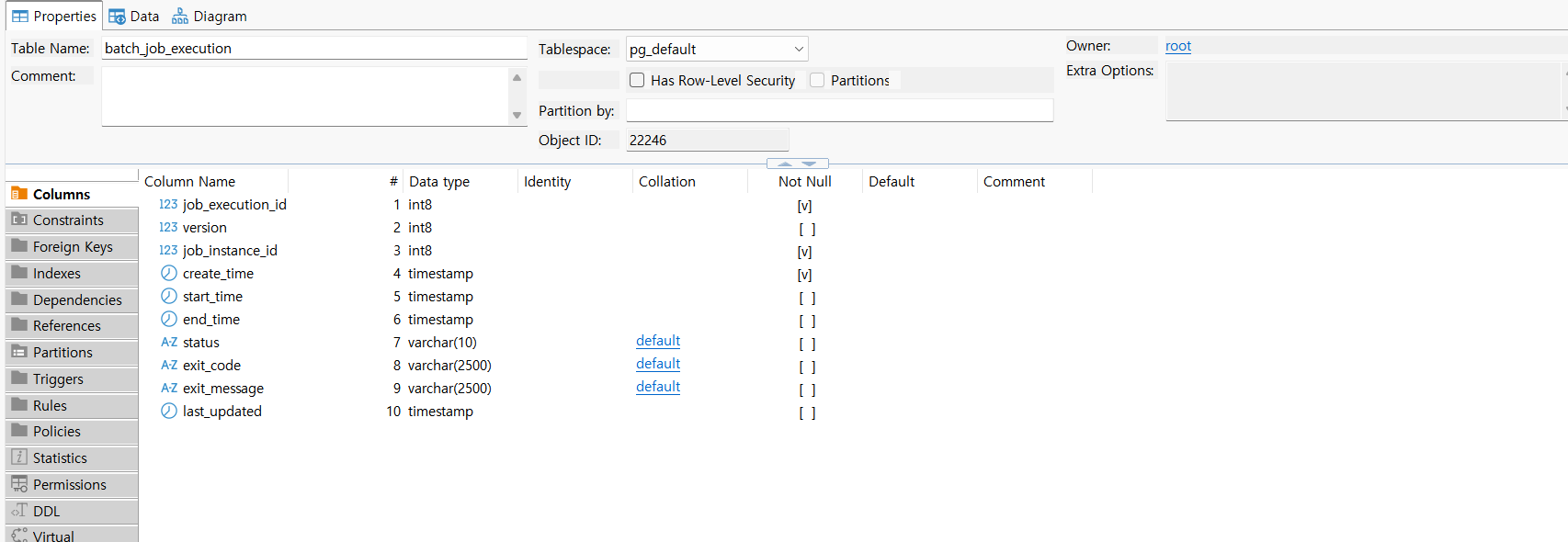
job의 명세를 나타낸 테이블이 job instance라면, 이에 대한 실제 실행 및 구체적인 내역은 job execution으로 관리한다.
job의 고유 식별자와 함께, job instance id, 시작 및 종료시간, jobExecution 종료코드 등으로 이루어져 있다.

job execution은 job에 종속되기에, job execution id를 PK로 구성하되 job instance id는 foreign key로 구성하여 1개의 job에 여러 execution 실행이 가능한 1:N 연결관계를 형성한다.
version은 job instance와 같이 낙관적 락, 동시성 제어를 위한 요소로 흔히 알고있는 낙관적 락의 진행방향과 일치한다. 즉, 다른 스레드가 이미 동일한 레코드를 업데이트하였다면, 해당 업데이트 시 낙관락 예외를 발생시킨다.
public class JobExecution extends Entity {
private final JobParameters jobParameters;
private JobInstance jobInstance;
private volatile Collection<StepExecution> stepExecutions = Collections.synchronizedSet(new LinkedHashSet<>());
private volatile BatchStatus status = BatchStatus.STARTING;
private volatile LocalDateTime startTime = null;
private volatile LocalDateTime createTime = LocalDateTime.now();
private volatile LocalDateTime endTime = null;
private volatile LocalDateTime lastUpdated = null;
private volatile ExitStatus exitStatus = ExitStatus.UNKNOWN;
private volatile ExecutionContext executionContext = new ExecutionContext();
private transient volatile List<Throwable> failureExceptions = new CopyOnWriteArrayList<>();도메인 객체도 테이블과 유사한 배치이다. 다만, jobParameters, jobInstance 객체를 포함하는 관계이며 다양한 stepExecution 정보를 담기 위해 이를 collection화하여 포함하는 것을 확인할 수 있다.
- jobParameters
job parameter의 데이터는 batch_job_execution_params 테이블에 저장된다.

위와 같이 parameter name, parameter type, parameter value, identifying 요소를 모두 저장 관리하는 것을 살펴볼 수 있다. 즉, job instance를 구별하는 구분요소를 저장하며, identifying에 대해 구별되는 job instance에 따라 job execution이 새롭게 생성, 실행되기에 job_execution_id를 foreign key로 설정되어 있다.
public class JobParameters implements Serializable {
private final Map<String, JobParameter<?>> parameters;jobParameters 도메인 객체는 위와 같이 parameter에 대한 내용을 Map형태로 저장하여 관리하고, 영속화할때는 각각의 프로퍼티를 구분하여 저장한다.
- StepExecution
stepExecution에 대한 내용은 step 실행의 상태 데이터이며, job execution id에 종속되기에 이를 FK로 설정하여 관리한다.
jobExecution은 stepExecution 컬렉션 정보를 포함하는 관계인데,
public class StepExecution extends Entity {
private final JobExecution jobExecution;stepExecution 역시 jobExecution 정보를 포함하는 양방향 참조 관계를 형성하고 있으며, 최종적으로 해당 메타데이터를 재실행할때 해당 데이터를 활용한다.
- ExecutionContext
executionContext는 batch_job_execution_context, batch_step_execution_context에 각각 저장되며, spring batch 설계 사상에 따라 step execution context은 job execution context을 구분하여 메타데이터를 저장하고 있다. 일전에 살펴보았듯이, SHORT_CONTEXT에 해당 상태내역을 직렬화하여 저장하되, 다만 이 길이가 2500자가 기준이기에 이보다 길 경우 잘라져서 진행된다.
다만 잘린 경우, serialized context에 clob 형태로 저장된다.
3. Job Squad 메커니즘 분석
이제 본격적으로 해당 컴포넌트들이 어떻게 활용이 되고, job이 실행되고 상태데이터가 저장되는지 살펴보고자 한다.
기본적인 출발점은 JobLauncher이다.
JobLauncher를 통해 job, jobParameter를 전달받아 실행하여 jobExecution을 반환, 특히 JobLauncher 구현체인 TaskExecutorJobLauncher의 run 메서드를 실행하여 job은 시작된다.
run 메서드는 아래와 같다.
@Override
public JobExecution run(final Job job, final JobParameters jobParameters)
throws JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException,
JobParametersInvalidException {
Assert.notNull(job, "The Job must not be null.");
Assert.notNull(jobParameters, "The JobParameters must not be null.");
if (this.jobLaunchCount != null) {
this.jobLaunchCount.increment();
}
final JobExecution jobExecution;
JobExecution lastExecution = jobRepository.getLastJobExecution(job.getName(), jobParameters);
if (lastExecution != null) {
if (!job.isRestartable()) {
throw new JobRestartException("JobInstance already exists and is not restartable");
}
/*
* validate here if it has stepExecutions that are UNKNOWN, STARTING, STARTED
* and STOPPING retrieve the previous execution and check
*/
for (StepExecution execution : lastExecution.getStepExecutions()) {
BatchStatus status = execution.getStatus();
if (status.isRunning()) {
throw new JobExecutionAlreadyRunningException(
"A job execution for this job is already running: " + lastExecution);
}
else if (status == BatchStatus.UNKNOWN) {
throw new JobRestartException(
"Cannot restart step [" + execution.getStepName() + "] from UNKNOWN status. "
+ "The last execution ended with a failure that could not be rolled back, "
+ "so it may be dangerous to proceed. Manual intervention is probably necessary.");
}
}
}
// Check the validity of the parameters before doing creating anything
// in the repository...
job.getJobParametersValidator().validate(jobParameters);
/*
* There is a very small probability that a non-restartable job can be restarted,
* but only if another process or thread manages to launch <i>and</i> fail a job
* execution for this instance between the last assertion and the next method
* returning successfully.
*/
jobExecution = jobRepository.createJobExecution(job.getName(), jobParameters);
try {
taskExecutor.execute(new Runnable() {
@Override
public void run() {
try {
if (logger.isInfoEnabled()) {
logger.info("Job: [" + job + "] launched with the following parameters: [" + jobParameters
+ "]");
}
job.execute(jobExecution);
if (logger.isInfoEnabled()) {
Duration jobExecutionDuration = BatchMetrics.calculateDuration(jobExecution.getStartTime(),
jobExecution.getEndTime());
logger.info("Job: [" + job + "] completed with the following parameters: [" + jobParameters
+ "] and the following status: [" + jobExecution.getStatus() + "]"
+ (jobExecutionDuration == null ? ""
: " in " + BatchMetrics.formatDuration(jobExecutionDuration)));
}
}
catch (Throwable t) {
if (logger.isInfoEnabled()) {
logger.info("Job: [" + job
+ "] failed unexpectedly and fatally with the following parameters: ["
+ jobParameters + "]", t);
}
rethrow(t);
}
}
private void rethrow(Throwable t) {
if (t instanceof RuntimeException) {
throw (RuntimeException) t;
}
else if (t instanceof Error) {
throw (Error) t;
}
throw new IllegalStateException(t);
}
});
}
catch (TaskRejectedException e) {
jobExecution.upgradeStatus(BatchStatus.FAILED);
if (jobExecution.getExitStatus().equals(ExitStatus.UNKNOWN)) {
jobExecution.setExitStatus(ExitStatus.FAILED.addExitDescription(e));
}
jobRepository.update(jobExecution);
}
return jobExecution;
}첫번째 단계는 jobExecution을 생성하는 것이다.
JobExecution lastExecution = jobRepository.getLastJobExecution(job.getName(), jobParameters);우리가 job을 구성할때, jobBuilder/stepBuilder 구성 시 job 매개변수를 전달할때 jobRepository를 사용하는 것을 확인할 수 있었다.


jobRepository는 run 실행 시 즉시 활용하게 되며, JobExecution은 jobRepository을 기반으로 생성하게 된다.
SimpleJobRepository 구현체에서 이를 구현하고 있는데,
@Override
@Nullable
public JobExecution getLastJobExecution(String jobName, JobParameters jobParameters) {
JobInstance jobInstance = jobInstanceDao.getJobInstance(jobName, jobParameters);
if (jobInstance == null) {
return null;
}
JobExecution jobExecution = jobExecutionDao.getLastJobExecution(jobInstance);
if (jobExecution != null) {
jobExecution.setExecutionContext(ecDao.getExecutionContext(jobExecution));
stepExecutionDao.addStepExecutions(jobExecution);
}
return jobExecution;
}lastJobExecution은 메서드 명에서 살펴볼 수 있듯이, 가장 최근에 실행한 job 실행내역에 대해 추출하는 기능을 제공한다. 따라서 이에 맞게, jobInstanceDao를 통해 jobName, jobParameter 기반의 jobInstance 컨텍스트를 먼저 조회해오고, 이후 해당 instance 정보를 바탕으로 jobExecution 정보를 추출해오는 것을 확인할 수 있다.
일전에 jobName, jobPaameter가 jobInstance의 구분자로 사용하며, 실제 테이블에서도 이를 unique 인자로 구성해주었다고 하였는데, jobInstance를 구성할때도 이러한 요소를 그대로 활용한다.
참고로 가장 최근의 jobExecution 정보를 추출할 것이고, 최종적인 exit status 값(BatchStatus.COMPLETED, ..)을 가질 것이다.
if (jobExecution != null) {
jobExecution.setExecutionContext(ecDao.getExecutionContext(jobExecution));
stepExecutionDao.addStepExecutions(jobExecution);
}이후, jobExecution 정보를 기반으로 jobExecutionContext 및 stepExecution 정보를 다시 생성하는 것을 확인할 수 있는데, jobExecution id값을 활용하여 job execution context, step execution 정보를 DB로부터 조회해온다.
이후, null 여부를 검사한다.
if (lastExecution != null) {null이 아니라면, jobExecution 내역이 이미 존재한다는 의미로 retry에 대한 경우이다.
if (!job.isRestartable()) {
throw new JobRestartException("JobInstance already exists and is not restartable");
}jobBuilder에서 preventRestart() 설정 시, restartable이 false로 설정되어, 재시작 불가 예외를 바로 throw하고 실패처리해버린다.
이후 로직은 해당 step의 상태값에 따라, 이미 진행중이라면 해당 스레드에서는 중복실행을 방지하기 위해 진행예외를 throw하여 진행을 종료한다.
job.getJobParametersValidator().validate(jobParameters);이후, "현재 실행예정인 jobExecution"을 생성하는데, 그 전에 먼저 전달된 jobParameter 매개변수의 파라미터를 검증한다.
@Component
public class SystemDestructionValidator implements JobParametersValidator {
@Override
public void validate(JobParameters parameters) throws JobParametersInvalidException {
if (parameters == null)
throw new JobParametersInvalidException("Parameters cannot be null");
Long destructionPower = parameters.getLong("destructionPower");
if (destructionPower == null)
throw new JobParametersInvalidException("Parameter destructionPower cannot be null");
if(destructionPower < 0)
throw new JobParametersInvalidException("Parameter destructionPower cannot be negative");
}
}참고로, 해당 validator의 구현체(SystemDestructorValidator)를 살펴보면 null 여부 등과 같은 유효성 검증을 진행한다.
jobExecution = jobRepository.createJobExecution(job.getName(), jobParameters);이후, creationJobExecution을 통해 현재 실행할 jobExecution 객체를 생성한다.
재시작이든 신규 생성이든 jobExecution 객체를 새로 생성하기에, 해당 정보가 테이블에 update가 아닌 새로운 record로 insert 된다는 것을 일전에 확인하였다. 이러한 객체 생성도 그러한 이유로 볼 수 있다.
SimpleJobRepository의 createJobExecution를 통해 이러한 jobExecution 객체가 생성된다.
JobInstance jobInstance = jobInstanceDao.getJobInstance(jobName, jobParameters);그 시작은 jobName, jobParamters를 통해 jobInstance을 먼저 생성하는 것이고, 이 내역이 있다면 재시작하는 상황이다.
이때 재시작 jobExecution의 상태가 없다면 예외를 발생시키고, jobExection 내역을 순회하면서 batchStatus 상태값을 검사한다.
if (!identifyingJobParameters.isEmpty()
&& (status == BatchStatus.COMPLETED || status == BatchStatus.ABANDONED)) {
throw new JobInstanceAlreadyCompleteException(
"A job instance already exists and is complete for identifying parameters="
+ identifyingJobParameters + ". If you want to run this job again, "
+ "change the parameters.");
}jobExecution의 상태값이 COMPLETED 혹은 ABONDONED, 즉 완료상태 혹은 재실행 불가 상태라면 해당 step은 실행불가 상태로 failed 처리한다.
이때 유의해야할 점은 jobParameters 객체를 검증할때,
public Map<String, JobParameter<?>> getIdentifyingParameters() {
Map<String, JobParameter<?>> identifyingParameters = new HashMap<>();
for (Map.Entry<String, JobParameter<?>> entry : this.parameters.entrySet()) {
if (entry.getValue().isIdentifying()) {
identifyingParameters.put(entry.getKey(), entry.getValue());
}
}
return Collections.unmodifiableMap(identifyingParameters);
}해당 jobParameter가 만약 identifying = false로 설정되어 전달되었다면, 이전 jobExecution의 COMPLETED 상태검사를 건너뛴다. 즉, 파라미터 아예 없이 실행하였다면, jobInstance의 구분자로 취급하지 않기에, 재실행 및 반복실행을 가능하게 만든다.
spring batch 6부터는 이러한 jobExecution 상태정보를 반영하게 되어, 파라미터 없이 실행하게 되더라도 이전의 jobExecution이 COMPLETED 되었다면, 재시작 불가능할 것으로 예상된다.
executionContext = ecDao.getExecutionContext(jobExecutionDao.getLastJobExecution(jobInstance));이후 이전의 jobExecution정보로 부터 ExecutionContext를 추출하여, executionContext 객체에 넘겨준다. 이전 상태 정보를 넘겨주기 위한 과정이다.
jobInstance = jobInstanceDao.createJobInstance(jobName, jobParameters);
executionContext = new ExecutionContext();그 다음의 분기(else)는 재시작이 아닌, job을 최초로 실행하는 경우로 jobInstance 정보를 새로 생성해오고, 나아가 jobExecution 정보를 추출하기 위한 ExecutionContext 객체를 구성해주는 작업을 진행한다.
그 후, 본격적으로 jobExecution을 생성한다.
JobExecution jobExecution = new JobExecution(jobInstance, jobParameters);
jobExecution.setExecutionContext(executionContext);
jobExecution.setLastUpdated(LocalDateTime.now());
// Save the JobExecution so that it picks up an ID (useful for clients
// monitoring asynchronous executions):
jobExecutionDao.saveJobExecution(jobExecution);
ecDao.saveExecutionContext(jobExecution);
return jobExecution;이 시점에서 jobExecution, jobExecutionContext를 영속화하여 저장한다.
다음 단계로 넘어가기 전에, SimpleJobRepository의 createJobExecution을 정리하자면 이미 완료된 jobInstance의 재실행 방지 및 재시작 상황에서 이전 job 실행 상태내역 복원까지의 사전 작업을 완료하는 역할을 한다.
다만, 이 jobExecution은 객체 자체는 매번 새로 생성하되 이전의 실행상태를 그대로 유지하는가, 새로운 상태 정보를 생성하는 지에 대한 차이이다. job이 재시작할 경우, 새로운 id값이 누적 생성되는 것은 기본 상태관리의 원리라는 점을 기억하자.
지금 단계는 JobInstance, JobExecution 객체가 모두 생성완료된 시점이다.
이제는 실제 실행을 하면 된다.
try {
taskExecutor.execute(new Runnable() {
@Override
public void run() {
job.execute(jobExecution);taskExecutor의 구현체의 execute 메서드를 통해 job을 실행하고, 내부적으로는 job.execute을 실행, 이때 jobExecution 정보를 전달하여 상태정보를 그대로 전달하게 된다.
이 실행은 구현체의 전략에 의해 진행되어, abstractJob이 그 실행을 담당한다.
@Override
public final void execute(JobExecution execution) {
JobSynchronizationManager.register(execution);가장 첫번째 단계로, threadLocal에 jobExecution 실행정보를 바인딩하여 job객체의 전역적 해석 기점을 마련하는 것으로 시작한다.
참고로, 일전에 살펴본 AbsractStep에서도 threadLocal에 해당 step객체 정보를 바인딩하는 것에서 부터 시작하였다. 즉, step 객체를 전역적으로 등록하여 StepScope의 해석이 가능해지고, 이에 따른 context 초기화가 가능하도록 해주는 것이 핵심이었다.
job 역시 마찬가지로, jobExecution 실행정보를 threadLocal에 바인딩하여, 현재의 context 초기화가 가능하여 jobScope의 해석이 가능하도록 마련해준다.
jobParametersValidator.validate(execution.getJobParameters());이때 다시 한번 jobParameter의 validator를 동작하여 유효성을 검증하는데, application에 의한 실행 이외 다른 외부적 환경(Jenkins 등)에 의한 실행도 있을 수있으므로 다시 한번 job parameter를 검증한다. 다양한 외부적 상황을 별다른 도메인 객체 생성없이, 일관된 검증을 수행할 수 있도록 하나의 코드로 구성한 방법이라 볼 수 있다.
if (execution.getStatus() != BatchStatus.STOPPING) {만약 job의 실행상태가 중지요청을 받아 중지가 된 것이 아니라면, 바로 jobExecution을 등록하는데, 보통의 경우 해당 시점에서 jobExecution 상태는 BatchStatus.STARTING 상태이다(job 실행을 위한 사전작업중).
execution.setStartTime(LocalDateTime.now());
updateStatus(execution, BatchStatus.STARTED);이 시점에서 생성된 jobExecution 내역은 시작시간과 STARTED 상태정보이다.
listener.beforeJob(execution);그 후, jobListener의 beforeJob을 호출하여 리스너 로직을 수행한다.
try {
doExecute(execution);
if (logger.isDebugEnabled()) {
logger.debug("Job execution complete: " + execution);
}
}다음 로직에서 해당 추상클래스를 구현한 구현체의 doExecute를 실행하여, 탬플릿메서드 패턴 구조로 SimpleJob의 doExecute를 진행한다.
StepExecution stepExecution = null;먼저 stepExecution 객체를 생성하여,
for (Step step : steps) {
stepExecution = handleStep(step, execution);
if (stepExecution.getStatus() != BatchStatus.COMPLETED) {
//
// Terminate the job if a step fails
//
break;
}
}jobBuilder를 통해 구성한 여러개의 step이 존재할 경우, 이 다수의 step을 순차적으로 실행하고, 만약 이전의 stepExecution 상태가 COMPLETED가 아니라면 비정상적인 진행으로 간주하고 step을 더이상 진행하지 않고 break한다.
if (stepExecution != null) {
if (logger.isDebugEnabled()) {
logger.debug("Upgrading JobExecution status: " + stepExecution);
}
execution.upgradeStatus(stepExecution.getStatus());
execution.setExitStatus(stepExecution.getExitStatus());
}그 이후의 분기로 진행할 경우, stepExecution의 상태가 가장 최근의 상태로 변경이되며 이 상태 그대로 jobExecution 상태를 반영한다.
위에서 잠깐 기술하였는데, jobExecution의 최종적인 상태는 가장 최근에 실행한 Step의 최종적인 상태를 그대로 물려받는다고 하였다. jobExecution의 최종상태는 최근 실행한 stepExecution의 상태가 될 것이고, 그 시점의 stepExecution가 COPLETED가 아닌 FAILED라면, step 단계 중 하나가 그대로 실패하여 그 상태 그대로 반영이 되었다는 뜻이다.
참고로, execution의 물리적 데이터는 status와 exit_code(exitStatus) 두개로 관리하는데, status는 위와 같이 각각의 레벨에서(Step/Job) 본인의 최종적인 작업 완료 상태값을 나타내며, exit_code는 abstractStep/SimpleJob을 거쳐 수시적으로 변경하는 실행 중인 job 혹은 step의 상태값으로, 실제 java 로직에서는 이를 exitStatus로 관리하므로 exit_code를 일단 살펴보는 것이 좋겠다.
그리고 최종적으로, AbstractJob에서 job 종료 과정을 진행한다.
execution.setEndTime(LocalDateTime.now());
..
listener.afterJob(execution);
..
jobRepository.update(execution);
..
JobSynchronizationManager.release();즉, 종료시간을 기록하고 job종료 이후의 리스너 동작(listener.afterJob) 및 최종 jobExecution 내용을 테이블에 반영하며, 최종적으로 job객체를 해제(release)하여 job 실행을 완료한다.
이로써 jobSquad에 대한 컴포넌트 및 메커니즘은 종료이다.
다시 한번 정리하자면 다음과 같다.
- jobInstance 생성 및 저장
- 최초 jobLauncer 동작 시 jobInstance 객체를 생성하는데, 기존 객체가 있다면 그대로 활용하고, 없다면 새로운 jobInstace를 생성 및 메타데이터로 기록한다. - jobExecution 생성 및 저장
- 위에서 jobInstance를 생성한 후, createJobExecution을 호출하여 jobExecution 객체를 생성 및 테이블에 이를 반영한다.
- 이후 jobExecution을 실시간으로 반영한다. - ExecutionContext(JobExecution)
- 위에서 jobExecution을 생성하여 최근의 상태정보를 추출해오거나, 아니라면 새로 생성한다.
- executionContext를 바로 테이블에 반영하며, 이후 각 step 실행 시 stepHandler가 step의 executionContext를 수시로 변경, 반영한다.
4. Step Squad 메커니즘 분석
참고. template method pattern의 동작
JobLauncer.run() 실행 후, Template method pattern에 의해 AbstractJob, SimpleJob이 어떤 메커니즘으로 각각의 메서드를 호출하고 로직을 어떻게 진행하는지 잠깐 참고삼아 알아보도록 하겠다.
jobLauncher.run(job, jobParameters);최초 시작은 jobLauncer의 run()을 실행하면서부터이며, 이때 JobLauncher의 구현체인 TaskExecutorJobLauncher의 run을 동작하게 된다.
이때 전달받은 job매개변수는 SimpleJob으로,
public JobExecution run(Job job, JobParameters jobParameters) {
JobExecution execution = jobRepository.createJobExecution(...);
job.execute(execution); // 여기서 execute 호출
}위 execute 기능을 실행할때, simpleJob의 execute가 저 시점에 호출이 되는 것이다.
Job 인터페이스를 구현한 순서는 아래와 같다.
Job (interface)
└─ AbstractJob (implements Job)
└─ SimpleJob (extends AbstractJob)그런데 simpleJob이 아닌, abstractJob의 execute가 먼저 실행되는 이유는 무엇일까?
그 이유는 간단하다. 구현한 순서대로 내려오기 때문이다.
그렇기에, 최초 abstractJob의 execute를 먼저 실행한다.
@Override
public final void execute(JobExecution execution) {그 후, doExecute를 처리하는데,
doExecute(execution);이 doExecute는 abstractJob 내부에서
abstract protected void doExecute(JobExecution execution) throws JobExecutionException;위와 같이 추상클래스로 정의된 명세로 되어있는, 이중 template method pattern으로 구성이 되어있는 것이다.
즉, 필요하면 자식 클래스가 이를 호출하라는 뜻이다.
protected void doExecute(JobExecution execution)
throws JobInterruptedException, JobRestartException, StartLimitExceededException {실제로 자식 클래스이자 구현체인 SimpleJob에는 위와 같이 doExecute에 대한 세부로직을 구성한 상태로, 자연스럽게 해당 로직을 처리하게 된다.
지금까지 살펴본 구조는, 특히 생성자에서 자식클래스를 먼저 호출하여 super 형태로 부모클래스를 호출하고 그 다음에 본인의 로직을 수행하는 구조로 되어있었다.
자 다시, 돌아와서, 최초 job.execute를 실행할때는 simpleJob 구현체를 전달한다고 하였다.
그렇다면, job.execute는 부모에서 구현한 execute를 먼저 호출하는 것이고, 그 다음에 this.doexecute()를 호출하는데, 이 this가 구현체인 자식 클래스(SimpleJob)이기에, simpleJob의 doExecute를 최종 호출하여 전체 실행의 메커니즘이 완성되는 것이다.
본 케이스의 경우 자식 클래스를 호출하는데, 자식 클래스 구현체에서 부모클래스의 메소드를 먼저 호출하고, 그 다음에 다시 this(구현체)의 구현 메서드로 이어지는 동작으로 이루어졌기에 눈에 안보였던 것이다.
이러한 구조를 인지하면서, 특히 batch에서는 이러한 구조가 상당히 많이 포진되어있기에 이를 염두에 두고 이해하도록 하자.
4. Step Squad 메커니즘 분석
Job Squad 메커니즘을 통해 최초 job Launcher 실행부터, jobRepository를 통한 jobInstance, JobExecution, JobExecutionContext 기반의 상태데이터 관리 과정을 분석해보았다.
JobLauncher 인터페이스의 구현체인 TaskExecutorJobLauncher 클래스를 통해 SimpleJob의 execute를 호출하면, AbstractJob의 execute 로직을 진행하면서 SimpleJob의 doExecute를 진행하게 된다.
다음 단계는 이 SimpleJob.doExecute를 진행하는 단계로, AbstractJob의 handleStep을 진행한다.
StepExecution stepExecution = null;
for (Step step : steps) {
stepExecution = handleStep(step, execution);
if (stepExecution.getStatus() != BatchStatus.COMPLETED) {
//
// Terminate the job if a step fails
//
break;
}
}SimpleJob의 doExecute는 위와 같이, step을 순회하면서 stepExecution을 생성하고 이를 반영하는 과정으로 이루어져있다.
내부적으로 살펴보면 handleStep은 AbstractStep에서 구현하였으며,
protected final StepExecution handleStep(Step step, JobExecution execution)
throws JobInterruptedException, JobRestartException, StartLimitExceededException {
return stepHandler.handleStep(step, execution);
}이와 같이 이러한 StepExecution 객체를 생성하는 과정은 stepHandler의 handleStep에서 진행한다.
AbstractStep은 아래와 같이 stepHandler의 구현체로 SimpleStepHandler를 전달한다.
public void setJobRepository(JobRepository jobRepository) {
this.jobRepository = jobRepository;
stepHandler = new SimpleStepHandler(jobRepository);
}이에 따라, stepHandler의 handleStep은 전략패턴을 통해 SimpleStepHandler.handleStep을 수행하게 된다.
@Override
public StepExecution handleStep(Step step, JobExecution execution)
throws JobInterruptedException, JobRestartException, StartLimitExceededException {
..
JobInstance jobInstance = execution.getJobInstance();처음 시작은 전달받은 jobExecution 정보로부터 jobInstance 객체를 생성하는 것에서 부터 시작한다.
StepExecution lastStepExecution = jobRepository.getLastStepExecution(jobInstance, step.getName());이후, 가장 최근(마지막)으로 실행된 stepExcetuion 정보를 jobRepository로부터 추출해온다.
if (stepExecutionPartOfExistingJobExecution(execution, lastStepExecution)) {
// If the last execution of this step was in the same job, it's
// probably intentional so we want to run it again...
if (logger.isInfoEnabled()) {
logger.info(String.format(
"Duplicate step [%s] detected in execution of job=[%s]. "
+ "If either step fails, both will be executed again on restart.",
step.getName(), jobInstance.getJobName()));
}
lastStepExecution = null;
}
StepExecution currentStepExecution = lastStepExecution;이때 만약 최근에 실행한 stepExecution 정보가 없다면 null이며, 존재한다면 마지막으로 실행한 stepExecution 객체를 그대로 활용한다.
그 다음 단계로, 해당 stepExecution 및 jobExecution 정보를 전달받아 해당 step을 실행할 수 있는지 가능여부를 판단한다.
if (shouldStart(lastStepExecution, execution, step)) {이때, 해당 판단기준은
protected boolean shouldStart(StepExecution lastStepExecution, JobExecution jobExecution, Step step)
throws JobRestartException, StartLimitExceededException {
BatchStatus stepStatus;
if (lastStepExecution == null) {
stepStatus = BatchStatus.STARTING;
}
else {
stepStatus = lastStepExecution.getStatus();
}
if (stepStatus == BatchStatus.UNKNOWN) {
throw new JobRestartException("Cannot restart step from UNKNOWN status. "
+ "The last execution ended with a failure that could not be rolled back, "
+ "so it may be dangerous to proceed. Manual intervention is probably necessary.");
}
if ((stepStatus == BatchStatus.COMPLETED && !step.isAllowStartIfComplete())
|| stepStatus == BatchStatus.ABANDONED) {
// step is complete, false should be returned, indicating that the
// step should not be started
if (logger.isInfoEnabled()) {
logger.info("Step already complete or not restartable, so no action to execute: " + lastStepExecution);
}
return false;
}
if (jobRepository.getStepExecutionCount(jobExecution.getJobInstance(), step.getName()) < step.getStartLimit()) {
// step start count is less than start max, return true
return true;
}
else {
// start max has been exceeded, throw an exception.
throw new StartLimitExceededException(
"Maximum start limit exceeded for step: " + step.getName() + "StartMax: " + step.getStartLimit());
}
}먼저, Step에 대한 진행상태값(BatchStatus)을 설정하며, 만약 이전의 stepExecution 내역이 없다면(null) 현재 진행상태는 진행중(STARTING), 내역이 존재한다면 현재 진행상태는 해당 상태값을 그대로 물려받는다.
만약 이전 상태값이 COMPLETED이거나, COMPLETED상태에서 재시작이 불가능한 경우 step을 시작할 수 없는 판단을 한다(return false). ABANDONED 상태값에 대해서도 재시작할 수 없다.
이때 isAllowStartIfComplete에 대한 구성은 StepBuilder에서 allowStartIfComplete을 통해 지정해줄 수 있다. 이 api구성값이 true라면, COMPLETED된 step이라도 재시작이 가능하다.
builder
.allowStartIfComplete(true) 이 설정값은 후속 Step이 이전의 Step에 영향을 받을때, 한번 Step이 실패하여 재시작해야 하는 경우 모든 Step을 다시 시작해야 한다면 이때 allowStartIfComplete 값을 true로 설정한다.
이처럼 allowStratIfComplete의 설정값은 step간의 데이터 결합성/의존도 및 설계적 필요사항에 따라 결정된다.
위 판단기준을 통과하여 재시작이 가능하더라도, stepExecutionCount를 도출하여, step 실행횟수가 최대허용횟수보다 작다면 실행가능, 크다면 예외를 throw한다.
참고로, 최대허용횟수에 대한 예외는 우리가 일전에 살펴보았던 limitExeddedException이다.
이 판단기준을 통과한 stepExecution은 다음 단계에서 그대로 step실행대상이 된다.
다음 단계로 stepExecution을 생성하여, 재시작 시 stepExecution을 그대로 활용하거나, 최초 실행에 대한 stepExecution을 새롭게 만들어서 해당 stepExecution을 jobRepository를 통해 반영하고 step을 실행(execute)한다.
if (isRestart) {
currentStepExecution.setExecutionContext(lastStepExecution.getExecutionContext());
if (lastStepExecution.getExecutionContext().containsKey("batch.executed")) {
currentStepExecution.getExecutionContext().remove("batch.executed");
}
}
else {
currentStepExecution.setExecutionContext(new ExecutionContext(executionContext));
}
jobRepository.add(currentStepExecution);
...
try {
step.execute(currentStepExecution);
currentStepExecution.getExecutionContext().put("batch.executed", true);
}step을 실행하기 전에, 먼저 그 step이 실행가능한지 여부를 판단(이전실행상태를 참고하여), 이후 재시작 여부를 확인하여 그 결과에 따라 stepExecution 정보를 그대로 활용하거나 새롭게 생성한다. 이후 최초 step 시작에 대한 상태데이터를 반영하고, step.execute()를 통해 step을 본격적으로 실행한다.
jobRepository.updateExecutionContext(execution);step을 실행한 후에는 stepExecutionContext에 해당 진행상태를 기록하고 메타데이터를 최종 반영한다.
@Bean
public Job myJob(JobRepository jobRepository, Step step1, Step step2) {
return new JobBuilder("myJob", jobRepository)
.start(step1)
.next(step2)
.build();
}job을 만들때 구성한 step 빈 객체를 기억하는가?
이 과정을 내부적으로 간단히 살펴보면,
SimpleJob job = new SimpleJob();
job.setSteps(List<Step>);SimpleJob 구현체를 만들 당시, 해당 job의 step 리스트에 step 구현체들이 넘어가 저장된다.
이 시점에서,
class SimpleJob {
private List<Step> steps;
}SimpleJob의 구현체 멤버변수, step 리스트에 해당 step구현체들이 이미 내장되어있다는 의미이다. 이후 과정은 template method pattern에 따라 진행된다.
최초 step.execute()를 호출하였기에, TaskletStep.execute를 찾고, 이 구현체에 해당 과정이 없기에 부모클래스인 abstractStep.execute를 실행하게 되는 것이다.
AbstractJob.execute
↓
SimpleJob.doExecute
↓
for (Step step : steps)
↓
handleStep(step, jobExecution)
↓
SimpleStepHandler.handleStep
↓
step.execute(stepExecution)
↓
AbstractStep.execute (템플릿)
↓
TaskletStep.doExecute그리고, doExecute()를 실행하기 위해 TaskletStep.doExecute()를 실행한다. 전체적인 양상이 Job과 완전히 동일한 것을 알 수 있다.
지난번에 한번 살펴보긴 하였지만, 상기 차원에서 다시 살펴보도록 하자.
step.execute를 실행하면, 아래와 같이 AbstractStep.execute를 거치게 된다.
stepExecution.setStartTime(LocalDateTime.now());
stepExecution.setStatus(BatchStatus.STARTED);
..
getJobRepository().update(stepExecution); 첫번째 과정으로 시작시간과 현재의 step 진행상태(STRATED)를 execution에 반영하고, 이를 영속화(update)한다.
ExitStatus exitStatus = ExitStatus.EXECUTING;이후 ExitStatus를 EXECUTIONG 상태로 바꾸는데, 앞서 기술하였듯이 BatchStatus가 Step 실행의 실시간 상태를 반영하는 상태값이고 ExitStatus는 말그대로 Step/Job의 최종적인 종료상태, 실시간으로 반영하지 않고 최종적인 상태만 알려주는 상태값이라 하였다.
따라서, ExitStatus는 반영은 하지 않고, 일단 초기화만 한다. 그 후에 TaskletStep.doExecute()를 실행한다.
@Override
protected void doExecute(StepExecution stepExecution) throws Exception {
stepExecution.getExecutionContext().put(TASKLET_TYPE_KEY, tasklet.getClass().getName());
stepExecution.getExecutionContext().put(STEP_TYPE_KEY, this.getClass().getName());
stream.update(stepExecution.getExecutionContext());
getJobRepository().updateExecutionContext(stepExecution);아직 Step을 실행하기 전, 정확하게는 실행직전의 사전준비단계이며 job과 마찬가지로, "Step을 곧 실행하겠다는" 표지판의 의미로 ExecutionContext 정보를 즉시 영속화하여 저장한다.
그리고나서 RepeatTemplate의 iterate를 호출하고, 단계적으로 executeInternal, getNextResult, callback.doInIteration을 호출한다. 특히, 반복호출되는 지점은 callback.doInIteration으로 stepContext를 매개변수로 전달받으면서 chunk step을 진행하는 중요한 단계이다.
이때 doInIteration의 반환 형태는 아래와 같고,
return callback.doInIteration(context);이를 살펴보면
public interface RepeatCallback {
/**
* Implementations return true if they can continue processing - e.g. there is a data
* source that is not yet exhausted. Exceptions are not necessarily fatal - processing
* might continue depending on the Exception type and the implementation of the
* caller.
* @param context the current context passed in by the caller.
* @return an {@link RepeatStatus} which is continuable if there is (or may be) more
* data to process.
* @throws Exception if there is a problem with the processing.
*/
RepeatStatus doInIteration(RepeatContext context) throws Exception;
}이러한 전략패턴 형태로 되어있음을 확인할 수 있다.
이에 대한 구현체인 StepContextRepatCallback의 doInIteration을 살펴보면, 우리가 알고있는 청크 컨텍스트 기반의 doInChunkContext(청크 트랜잭션)이 진행되는 것을 볼 수 있고,
return doInChunkContext(context, chunkContext);이 내부를 살펴보면
public abstract RepeatStatus doInChunkContext(RepeatContext context, ChunkContext chunkContext) throws Exception;이와 같이 추상형태의 template method pattern을 바라보고 있음을 알 수 있다.
이 패턴을 Callback 구현체를 전달하면서, 해당 패턴을 구현하고 있는 상황인 것이다.
new StepContextRepeatCallback(stepExecution) {
@Override
public RepeatStatus doInChunkContext(RepeatContext repeatContext, ChunkContext chunkContext)
throws Exception {
StepExecution stepExecution = chunkContext.getStepContext().getStepExecution();
// Before starting a new transaction, check for
// interruption.
interruptionPolicy.checkInterrupted(stepExecution);
RepeatStatus result;
try {
result = new TransactionTemplate(transactionManager, transactionAttribute)
.execute(new ChunkTransactionCallback(chunkContext, semaphore));
}
catch (UncheckedTransactionException e) {
// Allow checked exceptions to be thrown inside callback
throw (Exception) e.getCause();
}
chunkListener.afterChunk(chunkContext);
// Check for interruption after transaction as well, so that
// the interrupted exception is correctly propagated up to
// caller
interruptionPolicy.checkInterrupted(stepExecution);
return result == null ? RepeatStatus.FINISHED : result;
}
}따라서, ChunkContext를 전달받아 step.execute를 진행하기 위해 TransactionTemplate을 통해 트랜잭션 컨텍스트를 생성하고, 최종적으로 ChunkTransactionCallback 구현체의 doInTransaction의 tasklet.execute을 반복 실행하여 chunk step을 반복적으로 실행하는 것이다.
이 내부를 살펴보자.
@Override
public RepeatStatus doInTransaction(TransactionStatus status) {
...
StepContribution contribution = stepExecution.createStepContribution();먼저, step 처리 결과(chunk 처리 시 발생한 skip/retry/chunk step 등의 통계정보)를 기록할 stepContribution을 생성한다.
result = tasklet.execute(contribution, chunkContext);item 1개에 대한 chunk step을 실행한 후,
stepExecution.apply(contribution);stepExecution에 해당 통계정보(contribution)을 반영하여, 예외가 발생하였든 정상적으로 처리되었든 해당 step 실행결과를 그대로 execution에 반영하게 된다.
이후,
stream.update(stepExecution.getExecutionContext());stepExecution의 executionContext 상태를 stream update를 통해, executionContext에 저장하고
getJobRepository().updateExecutionContext(stepExecution);커밋카운트를 증가한 stepExecution 상태를 영속화하여 즉시 반영한다.
이후, AbstracStep으로 다시 돌아와서,
exitStatus = ExitStatus.COMPLETED.and(stepExecution.getExitStatus());
stepExecution.upgradeStatus(BatchStatus.COMPLETED);정상 실행된 StepExecution의 batchStatus를 COMPLETED로 변경하고, ExitStatus 역시 최종 완료상태로 변경한다.
exitStatus = exitStatus.and(stepExecution.getExitStatus());
stepExecution.setExitStatus(exitStatus);
exitStatus = exitStatus.and(getCompositeListener().afterStep(stepExecution));그 후,
getJobRepository().updateExecutionContext(stepExecution);ExecutionContext 상태를 최종 반영한다.
만약 예외가 발생하여 롤백을 해야한다면, 어떤 로직을 진행할까?
doInTransaction에서 tasklet.execute를 진행하는 try에서 예외가 발생한다면, 이에 대비하는 3가지 catch문을 진행하여 예외처리를 진행한다.
catch (Error e) {
if (logger.isDebugEnabled()) {
logger.debug("Rollback for Error: " + e.getClass().getName() + ": " + e.getMessage());
}
rollback(stepExecution);
throw e;
}
catch (RuntimeException e) {
if (logger.isDebugEnabled()) {
logger.debug("Rollback for RuntimeException: " + e.getClass().getName() + ": " + e.getMessage());
}
rollback(stepExecution);
throw e;
}
catch (Exception e) {
if (logger.isDebugEnabled()) {
logger.debug("Rollback for Exception: " + e.getClass().getName() + ": " + e.getMessage());
}
rollback(stepExecution);
// Allow checked exceptions
throw new UncheckedTransactionException(e);
}보면 알 수 있듯이, 어떠한 예외 상관없이 모두 롤백처리한다.
private void rollback(StepExecution stepExecution) {
if (!rolledBack) {
stepExecution.incrementRollbackCount();
rolledBack = true;
}
}다만 메서드명대로 곧이 곧대로 롤백하는 것은 아니다. rollback 처리 시, 롤백횟수를 증가하여 stepExecution에 반영하는 과정만 진행한다.
실제 롤백처리는 TransactionTemplate에서
rollbackOnException해당 메서드를 호출하면서 처리한다.
이 예외는 AbstractStep의 execute의 catch가지 전파되어,
catch (Throwable e) {
stepExecution.upgradeStatus(determineBatchStatus(e));
exitStatus = exitStatus.and(getDefaultExitStatusForFailure(e));
stepExecution.addFailureException(e);
if (stepExecution.getStatus() == BatchStatus.STOPPED) {
logger.info(String.format("Encountered interruption executing step %s in job %s : %s", name,
stepExecution.getJobExecution().getJobInstance().getJobName(), e.getMessage()));
if (logger.isDebugEnabled()) {
logger.debug("Full exception", e);
}
}
else {
logger.error(String.format("Encountered an error executing step %s in job %s", name,
stepExecution.getJobExecution().getJobInstance().getJobName()), e);
}
}위와 같이 BatchStatus 및 ExitStatus에 대한 상태값을 판단하여, stepExecution에 반영한다(영속화 하지는 않는다).
이후, 드디어 Step의 최종 마무리 단계에 진입하여 최종적인 stepExecution 상태를 지정하고 이를 최종 영속화하며, ExitStatus 상태값까지 반영, 영속화한다.
stepExecution.setEndTime(LocalDateTime.now());
...
getJobRepository().updateExecutionContext(stepExecution);
...
getJobRepository().update(stepExecution);이때 반영하기 전에 몇가지 중간단계가 있는데, 바로 StepListener의 afterStep을 호출하는 과정이 진행된다. 이전에 해당 step 종료상태를 리스너에게 전달하기 위해 ExitStatus를 반영해둔다.
exitStatus = exitStatus.and(stepExecution.getExitStatus());
stepExecution.setExitStatus(exitStatus);
exitStatus = exitStatus.and(getCompositeListener().afterStep(stepExecution));그리고 StepListener.afterStep을 진행한다.
getJobRepository().updateExecutionContext(stepExecution);
...
getJobRepository().update(stepExecution);그 후, 해당 ExecutionContext 내용과 Execution 내용을 최종 영속화한다. 이 메타데이터 반영과정에서 문제가 생길 경우, 데이터 상태를 UNKNOWN로 표기하는 것에 유의하자(UNKNOWN - 메타데이터 반영과정에서 문제가 발생하였음).
그리고,
close(stepExecution.getExecutionContext());itemStream을 close(바인딩한 step객체를 release하여 scope의 활성화 상태를 해제), 최종 step 단계를 마무리한다.
이제, SimpleStepHandler 구현체로 돌아가서, step.execute를 진행하였으니 해당 레벨을 job으로 올려서, jobExecution 상태로 저장한다.
jobRepository.updateExecutionContext(execution);그리고, SimpleJob의 doExecute 단계에 와서,
execution.upgradeStatus(stepExecution.getStatus());
execution.setExitStatus(stepExecution.getExitStatus());"Job" 레벨에서의 Batch status 상태값과 exit status 상태값을 변경하여 stepExecution에 반영시킨다.
마지막으로, AbstractJob의 fianlly 로직을 거치게 되며,
stepExecution.setEndTime(LocalDateTime.now());
..
stepExecution.setExitStatus(exitStatus);
exitStatus = exitStatus.and(getCompositeListener().afterStep(stepExecution));
..
getJobRepository().updateExecutionContext(stepExecution);
..
..
getJobRepository().update(stepExecution);
..
stpExecution의 종료시각 등을 설정 후, StepListener의 afterStep 리스너를 호출하며, 그 이후에 최종적으로 stepExecution 및 stepExecutionContext를 영속화하여 저장한다.
그리고 job의 실행을 모두 종료한다.
5. About Step Squad
위에서 진행한 step 실행 메커니즘을 정리하면 아래와 같다.
- StepExecution
- SimpleStepHandler는 StepExecution 객체를 새로 생성하며, 재시도 시작의 경우 이전의 executionContext를 복구하여 사용한다.
- Job, Step 시작 시 항상 stepExecution은 "Step 실행 시작"의 의미로 메타데이터로 영속화된다. - BatchStatus/ExitStatus
- BatchStatus는 실시간 실행 상태로, 즉시적으로 영속화되어 저장된다.
- ExitStatus는 Step 실행의 온전한 완료 후에만 저장되며, 이는 StepExecution에 설정되는 값이다.
- 예외가 발생하면 그에 맞는 BatchStatus 및 ExitStatus가 설정된다. - StepContribution, ExecutionContext
- 청크마다 청크처리/skip/retry 통계정보를 저장하는 stepContribution을 생성한다.
- 청크처리 후, stepContribution 정보가 stepExecution에 반영된다.
- 중간에 청크처리 실패 시 실패 전까지의 중간처리정보를 안전하게 기록한다. - 청크 및 롤백
- 청크 단위의 트랜잭션 관리가 이루어진다.
- 예외가 발생하면, stepExecution에 롤백 카운트를 반영하고, 실제 트랜잭션은 롤백은 TransactionTemplate에서 이루어진다. - Step 종료
- 이후 Step 종료 시, 종료시간을 설정한다.
- StepExecutionListener.afterStep을 통해 ExitStatus를 조정가능하다.
- 최종적으로 step 종료 시, itemStream을 close하고 모든 상태 데이터를 영속화하여 마친다.
6. 결론
Spring Batch의 Job 컴포넌트부터 시작하여, job의 실행과 여기서 이어지는 Step 컴포넌트 및 step 실행에 대한 내용을, 상태데이터의 반영을 중심으로 분석해보았다.
spring batch에서 줄기차게 사용하는 template method pattern, strategy pattern에 대해서도 알아보면서, 추상클래스가 언제 구현이 되어 사용이 되는지, 전략패턴의 구체화를 언제 진행하며, 오버라이드를 어떻게 진행하는지 등 구조적 메커니즘에 대해서도 꽤 흥미롭게 살펴볼 수 있었다.
사실 Spring Security의 콜백과정을 힘겹게 살펴보면서 이해가 힘들었는데, 정말 신기하게도 Spring batch에서도 물론 힘들었지만, 계속 살펴보니 차츰 눈에 익고 실력도 향상이 되는 것을 느낄 수 있었던 귀중한 시간이었던 것 같다.
지금까지 이해한 내용을 바탕으로, spring batch뿐만 아니라, 특히 유지보수적인 관점에서(pattern) 실무에서 적극적으로 활용하는 것도 나쁘지 않을 것으로 보인다.
