[개발지식] Web Application의 상호보완적 Eventually Consistency #10 - 관계형 데이터베이스를 Spring Job을 통해 읽고 쓰는 과정 분석(*With Postgresql)
개발지식
1. 개요
지금까지 분석해왔던 데이터를 flatFile 형태(.csv, .txt, .jsonl 등)로 저장할 수 있겠지만, 본질적으로는 당연히 관계형 데이터베이스가 데이터를 저장하기에 가장 적절하고 중요하겠다.
수백만건, 수천만건의 데이터를 다루기 위해선 flat file로는 부족할 수 밖에 없다.
spring batch의 꽃은 관계형 데이터베이스에 저장된 데이터들을 다루는데에서 시작한다.
그리고 또 하나 중요한 점, 계속 강조해왔던 점은 우리가 생각해왔던 web application와 spring batch는 본질적으로 다른 개념이라는 것이다.
표지에서 볼 수 있듯이 Spring Batch는 실시간 처리가 아닌, Eventually Consistency가 목적이다.
이에 대해 Spring Batch의 처리과정과, 이를 위해 제공해주는 도구들이 어떤 것들이 있는지 자세하게 살펴보고자 한다.
2. 숲을 먼저 보자 - Spring Batch의 관계형데이터베이스의 대용량 데이터를 처리하기 위한 두가지 도구들
Spring batch는 관계형데이터베이스에 저장되어있는 대용량 데이터를 처리하기 위한 도구 2가지를 제공해주며, 이 두가지 만으로도 충분하게 처리가 가능하다.
JdbcCursorItemReader
DB와의 connection(연결)을 유지하면서, 데이터를 순차적으로 스트리밍하면서 읽는 방식의 Reader이다.
말 그대로, row 한줄한줄 스트리밍하면서 읽어오기에(모든 데이터를 한 메모리에 올려두는 것이 아니라) 메모리 과부하가 발생할 여지가 없고, 그러면서 속도가 빠르다.
JdbcPagingItemReader
말 그대로 페이징 기반, 전체 데이터를 일정 기준으로 잘라서 차근차근 처리한다.
각 페이지마다 쿼리를 새롭게 적용하여 안정성을 보장한다.
2-1. 나무1 - JdbcCursorItemReader
커서기반 처리에 대해 먼저 살펴보도록 하자.
2-1-1. 작동원리
결론부터 말하면 다음과 같다.
- 마트에 가서 “한 상자(fetchSize)씩만 주세요.”
- 냉장고(메모리)에 넣어둔다.
- next()로 하나씩 꺼내먹는다.
- 다 먹으면 마트에 다시 가서 “또 한 상자 주세요.”
이 DB를 통한 왕복 IO비용을 줄이고 최적화하기 위해, "냉장고"역할을 하는 중간다리인 "resultSet"이 존재하는 것이다.
JdbcCursorItemReader의 진행과정은 아래와 같다.
- ItemReader가 최초 open()하여 DB Connection을 생성한다.
- fecthSize와 이만큼의 preparedStatement를 실행하여 최초 DB에서의 데이터를 ResultSet에 1차 fetch 데이터를 저장해두고, 이 시점에 cursor가 최초 오픈되어 index 0을 가르킨다.
- itemReader의 read()를 청크사이즈 만큼 호출 반복하여, 내부 RowMapper를 통해 객체화하고 반복 호출 후 배열화한다.
- resultSet의 읽을 레코드가 없을때까지 혹은 청크사이즈 만큼 반복하고, 이를 processor 및 writer에게 전달한다.
- reading 최종 종료 시 ItemReader의 close를 호출하여 JdbcCursorItemReader를 close하고 DB커넥션을 최종 폐쇄한다.
(참고로 flatFileReader의 경우 lineMapper가 파일 한줄을 읽고 토큰화하고, fieldSet 객체로 변환 후 최종적으로 targetClass로 변환한다. RowMapper도 이와 동일하다.)
이를 도식화하여 정리하면 다음과 같다.
[Step 시작]
│
▼
Chunk-Oriented Processing 시작
│
▼
ItemReader.open(ExecutionContext) 호출
│
├─ JdbcCursorItemReader.open()
│ │
│ ├─ DataSource.getConnection() ← DB 커넥션 생성
│ │
│ ├─ connection.setFetchSize(n) (옵션)
│ │
│ ├─ connection.prepareStatement(sql) ← SQL 준비
│ │ │
│ │ ├─ PreparedStatement 생성
│ │ └─ (setMaxRows, setQueryTimeout 등 옵션 세팅)
│ │
│ ├─ preparedStatement.executeQuery()
│ │ │
│ │ └─ ResultSet 생성 ▷ "DB Cursor" 오픈됨
│ │
│ └─ 내부 커서 index = 0 초기화
│
▼
[Reader 준비 완료]
[read() 호출 반복 시작]
│
▼
ItemReader.read()
│
├─ JdbcCursorItemReader.read()
│ │
│ ├─ resultSet.next() 호출
│ │ │
│ │ ├─ resultSet.next() == true ?
│ │ │ │
│ │ │ ├─ true → 다음 레코드 존재
│ │ │ │ │
│ │ │ │ └─ RowMapper.mapRow(resultSet)
│ │ │ │ │
│ │ │ │ └─ resultSet 현재 row → 객체로 매핑
│ │ │ │
│ │ │ └─ false → 더 이상 읽을 레코드 없음
│ │ │ │
│ │ │ └─ return null → Reader 종료 신호
│ │
│ └─ 객체 반환
│
▼
[read()가 객체를 반환하면 → Processor → Writer 로 전달]
│
├─ 다음 chunk 단위까지 read() 계속 반복
│
▼
resultSet 끝까지 도달 → read()가 null 반환
│
▼
Spring Batch 가 ItemReader.close() 호출
│
├─ JdbcCursorItemReader.close()
│ │
│ ├─ resultSet.close()
│ ├─ preparedStatement.close()
│ └─ connection.close() ← DB와 커넥션 종료
│
▼
[ItemReader 종료]
이때 DB를 바라보는 cursor의 위치는 read를 통해 1 row를 읽을때마다 한줄한줄씩 이동한다. 정확하게는 re.next()를 한 만큼 cursor는 다음 읽을 데이터를 항상 바라본다.
그렇기에,
cursor는 무조건 DB를 바라본다.
참고로 DB별로 fetchsize는 아래와 같이 chunksize보다 적정량 분 크게 튜닝한다.
| DB | 권장 fetchSize |
|---|---|
| MySQL | 100 ~ 1000 (또는 streaming 모드) |
| PostgreSQL | 200 ~ 2000 |
| Oracle | 200 ~ 5000 |
| SQLServer | 드라이버 튜닝에 따라 수백 |
참고로 fetchSize 곧이 곧대로 데이터를 resultSet으로 옮기진 않고, 내부적인 드라이버 구현체 및 RDBMS/application 정책 및 환경 등에 따라 적절히 조절되어 fetch하는데, 적절한 조정을 통해 DB와의 빈번한 I/O통신 및 이로 인한 소모를 줄이고 통신을 최적화할 수 있을 것이다.
또한 상기하자면, Reader - Processor - Wirter는 묶음으로 보기보다는 청크사이즈대로 각개전투를 한다.
각각의 버퍼에 청크사이즈만큼 진행한 데이터들을 저장하고, 다음 단계로 위임할 뿐이다.
특히 Writer의 경우 청크사이즈만큼 진행한 데이터들을 최종적으로 write하여 반영하는 것일 뿐, 각각의 컴포넌트들은 다음 컴포넌트들의 작업 마무리를 기다리지 않고 데이터 크기만큼의 일정량 수행 후 전달할 뿐이다.
2-1-2. RowMapper
row mapper는 mapRow라는 내장기능을 사용하여, resultSet에 저장되어있는 record들을 서버사이드에서 활용가능한 객체로 변환하기 위한 매퍼이다.
보통은 JPA의 entity처럼 스네이크 기반의 데이터베이스 컬럼명을 카멜케이스 기반의 프로퍼티(객체 필드)명으로 매핑하는 BeanPropertyRowMapper를 구현체로 하여 사용한다.
이외에 Record와 같은 Immutable 객체의 매핑을 위해 DataClassRowMapper를 사용하기도 하며, Customized한 Row mapper 구현체를 사용하기도 한다.
@Bean
public JdbcCursorItemReader<Victim> terminatedVictimReader() {
return new JdbcCursorItemReaderBuilder<Victim>()
.name("terminatedVictimReader")
.dataSource(dataSource)
.sql("SELECT * FROM victims WHERE status = ? AND terminated_at <= ?")
.queryArguments(List.of("TERMINATED", LocalDateTime.now()))
.beanRowMapper(Victim.class)
.build();
}위와 같이 beanRowMapper를 통해 객체화하거나,
public JdbcCursorItemReader<Victim> terminatedVictimReader() {
return new JdbcCursorItemReaderBuilder<Victim>()
.name("terminatedVictimReader")
.dataSource(dataSource)
.sql("SELECT * FROM victims WHERE status = ? AND terminated_at <= ?")
.queryArguments(List.of("TERMINATED", LocalDateTime.now()))
.dataRowMapper(Victim.class)
.build();
}dataClassRowMapper를 사용하여 Record화 하거나,
rowmapper 그대로 이용하여 customized하거나 아래와 같이 사용자정의의 매핑을 진행할 수도 있다.
//lambda
public JdbcCursorItemReader<Victim> terminatedVictimReader() {
return new JdbcCursorItemReaderBuilder<Victim>()
.name("terminatedVictimReader")
.dataSource(dataSource)
.sql("SELECT * FROM victims WHERE status = ? AND terminated_at <= ?")
.queryArguments(List.of("TERMINATED", LocalDateTime.now()))
.rowMapper((rs, rowNum) -> {
Victim victim = new Victim();
victim.setId(rs.getLong("id"));
victim.setProcessId(rs.getString("process_id"));
})
.build();
}2-1-3. PreparedStatementSetter
PreparedStatement를 통해 sql 쿼리를 실행한다면, preparedStatementSetter를 통해 쿼리 파라미터(조회조건 및 범위 등)를 주입해줄 수도 있다.
해당 컴포넌트는 옵션으로, JdbcCursorItemReader 측에서 PreparedStatement 쿼리를 실행하기 전에 PreparedStatementSetter를 통해 파라미터를 동적으로 바인딩해주며, 자체적으로 타입안정성 및 SQL Injection 방지 등의 기능을 제공해주기도 한다.
가장 기본적인 구현체는 ArgumentPreparedStatementSetter이다.
2-1-4. 이 외 유의사항
[ResultSet의 fetch size]
MySQL의 경우, useCursorFetch Connection Property 설정이 없다면 모든 쿼리결과를 ResultSet, 즉 메모리에 저장해버린다. 따라서 수백~수천개 이상의 대용량 데이터를 저장할 것이라면 sueCursorFetch를 true로 설정하여 적절한 조정이 필요할 것이다.
이외 fetch size는 JdbcCursorItemReaderBuilder의 fetchSize() 메서드를 사용하여 설정할 수 있다.
- 참고로, flatFileItemReader 역시 이와 유사한 원리로, 내부적으로 BufferedReader를 사용하여 일단 메모리에 저장해두고, read를 호출할땤마다 I/O통신이 아닌 메모리에 저장된 데이터를 익는다.
[커서와 트랜잭션의 지속성/연속성]
위에서 잠깐 기술하였지만, 기본적으로 트랜잭션은 Writer가 청크사이즈만큼 write하여 트랜잭션을 발생시키고 커밋하는 과정으로 진행된다.
Reader에서 DB를 향해 바라보는 cursor와, Writer 측에서 이용하는 트랜잭션의 컨텍스트는 서로 별도이기에, 서로가 서로의 영향을 받지않고 connection을 비교적 안정적으로 운용이 가능하다.
[snapshot]
ItemProcessor나 ItemWriter가 동일한 DB의 동일 데이터를 변경해버린다 하더라도, Reader가 읽고 있는 내부적인 스냅샷, 즉 데이터 컨텍스트는 변경되지 않는다.
JdbcCursorItemReader의 단일 Cursor와 단일 ResultSet이기에 가능한 점이며, DB의 격리수준과는 별개의 개념이다.
따라서 Step에서 db의 데이터를 변경하더라도, Cursor가 읽고 있는 논리적인 데이터소스, 위치는 변하지 않는다.
PostgreSQL/Oracle의 격리수준인 RC라도, 이미 열린 cursor(ResultSet)는 영향을 받지 않는다. 단지 “statement 단위 스냅샷”이지 “row fetch 단위”가 아니기 때문이다.
이는 모든 DB에 적용되기에, 일관성있는 컨텍스트 유지가 가능하다.
[ORDER BY 설정]
JdbcCursorItemReader의 최초 open시점에 쿼리실행 및 이후 ResultSet.next()를 호출하면서 데이터를 순차적으로 가져오는데, 만약 중간에서 실패하였을때 cursor를 다시 해당 실패지점으로 되돌아가 순차실행을 재반복한다.
이때 cursor 이동의 결과를 보장하기 위해 order by, 즉 정렬순서도 reader 관점에서는 중요한 기준으로 작용한다.
따라서, 실패 시 재동작 등 일관된 Reader의 처리와 그 순서를 보장하기 위해, 반드시 ORDER BY절을 통한 순서유지가 필수적이며 보통은 PK값과 같이 유일성을 보장할 수 있는 유니크인자를 그 기준으로 삼는다.
2-2. 나무2 - JdbcPagingItemReader
JdbcCursorItemReader의 경우 cursor를 최초 open부터 마지막 close까지 게속 유지하고 있어야 하기에, 통신비용 관점에서 다소 부담이 있다.
DB자체는 커넥션풀을 유한하게 유지해야 하므로, Spring Batch 측에서 해당 작업의 소요시간이 길어진다면 그칸큼 다른 요청들에 대해 가용한 커넥션이 줄어들 수 밖에 없다. 나아가, 네트워크 오류가 발생한다면 Connection의 단일성으로 인해 batch job은 그걸로 끝이다.
JdbcPagingItemReader는 이러한 한계를 보완하고자, 읽어들이고자 하는 데이터를 일정 크기로 잘라서 읽는다.
또한 각 페이지마다 새로운 쿼리를 실행하면서, 전체적으로 단일 커넥션 유지에 대한 부담을 경감한 Reading 방식이다.
2-2-1. 작동원리
JdbcPagingItemReader의 작동원리는 크게 두가지가 있다.
- Offset based
우리가 흔히 알고있는 paging query인 offset, limit을 사용하여 읽어들이는 방식으로, offset을 바꿔가면서 데이터를 단계적으로 추출해온다.
이 방식은 모든 DB의 페이징 쿼리가 가지고 있는 단점을 그대로 가지는데, 메모리에 모든 데이터를 올리지는 않지만 offset 만큼 점프할 수는 없기에 읽고 무시할 뿐이다.
참고로 인덱스를 활용하더라도, 풀스캔만 피할 수 있고 I/O비용이 어느정도 감소될 수는 있지만 offset 비용 자체는 무조건 있을 수 밖에 없다.
| 측면 | 실제 동작 |
|---|---|
| 메모리 | 전부 메모리에 올리지는 않음 |
| 처리 방식 | 인덱스/정렬 결과를 앞에서부터 순차 스캔 |
| CPU / IO | OFFSET이 커질수록 계속 증가 |
| 응답시간 | OFFSET에 비례해서 증가 |
즉 정리하면, offset을 건너뛸 수 없기에 limit 개수만큼의 데이터를 불러오기 위해 일단은 처음부터 데이터를 스캔하고, offset만큼의 앞 데이터를 모두 버린다(정확하게는 메모리에 올리지 않고 무시한다).
따라서, 이 방식은 페이지 번호가 뒤로 갈수록 성능이 급격하게 저하될 수 밖에 없다.
- KeySet
LIMIT, OFFSET의 단점을 보완하고 페이징이 뒤로 가더라도 일정한 읽기 성능을 유지하기 위해, unique 인자를 활용하여 해당 키값을 기준으로 이전의 읽은 시점 이후부터 읽어오도록 id key값을 이용하여 읽는 방법이다.
이때 where id = 0 , id > 5, id > 10 등 각각의 쿼리를 실행할때마다 쿼리의 조건이 달라질 수 밖에 없고, 그렇기에 paging 방식의 쿼리가 각 페이지마다 달라질 수 밖에 없는 이유이기도 하다.
2-2-2. NamedParamterJdbcTemplate
기존의 JdbcCursorItemReader를 통해선 위치기반(?)의 jdbcTemplate을 사용하였다면, JDbcPagingItemReader의 경우 나아가 파라미터의 명명을 활용하여 가독성 및 안정성을 높여주는 파라미터 할당 방식을 취할 수 있다.
2-2-3. PagingQueryProvider
JdbcPagingItemReader의 경우 Keyset 기반 페이징을 위한 특별한 쿼리 생성 도구를 필요로 하는데, 기본적으로 각 페이지마다 실행하는 쿼리가 달라지기 때문이다(또한 최초 실행 쿼리와 그 이후의 실행 쿼리도 달라질 수 밖에 없다).
따라서, 이를 위해 PagingQueryProvider라는 특별한 구현체를 제공하며, DB별로 PostgresPagingQueryProvider, MySqlPagingQueryProvider 등을 제공한다.
사실 순수 keyset 기반(WHERE id > lastId)은 아니기에, DB별로 아래와 같이
| DB | 내부 전략 |
|---|---|
| MySQL, PostgreSQL | ORDER BY + LIMIT |
| Oracle | ROWNUM 서브쿼리 |
| SQL Server | TOP, OFFSET/FETCH (버전에 따라 다름) |
완전한 cursor/keyset pagination은 아니고 limit, rownum과 같이 DB에 대해 적절한 페이징 쿼리를 사용하는 방식이다.
이 페이징쿼리가 db마다 다르게 제공되는 것이고, 이에 대한 각 구현체는 아래와 같다.
| DB | 구현체 |
|---|---|
| PostgreSQL | PostgresPagingQueryProvider |
| MySQL / MariaDB | MySqlPagingQueryProvider |
| Oracle | OraclePagingQueryProvider |
| SQL Server | SqlServerPagingQueryProvider |
| DB2 | Db2PagingQueryProvider |
| H2 | H2PagingQueryProvider |
| HSQLDB | HsqlPagingQueryProvider |
| Derby | DerbyPagingQueryProvider |
| Sybase | SybasePagingQueryProvider |
그래서 보통 실무에서는 QueryProvider 구현체를 직접 사용하기보다는, customized한 쿼리를 구성하거나 factory를 통해 페이징 쿼리를 직접 구성하는 방식을 사용 한다(SqlPagingQueryFactoryBean 구현체를 사용하여 직접 페이징 쿼리를 지정하는 방식).
SqlPagingQueryProviderFactoryBean factory =
new SqlPagingQueryProviderFactoryBean();
factory.setDataSource(dataSource);
factory.setSelectClause("select id, name");
factory.setFromClause("from orders");
factory.setWhereClause("where status = 'READY'");
factory.setSortKey("id"); // 필수DataSource 기반으로 DB 자동 판별하며, Oracle ↔ PostgreSQL ↔ MySQL 전환 시 코드 없이 유지할 수 있다(DB독립성).
sortKey값의 경우 반드시 유니크 값으로 지정해주어야 데이터 순서가 뒤바뀌지 않는 안정성을 확보할 수 있고, 참고로 위의 factory 방식과 구현체를 모두 사용한다면 factory방식은 무시되기에 하나의 방식만 사용해야 한다(*Order by 정렬기준도 명기할 것을 권장).
더불어 내부적으로 firstPageSql, remainingPageSql을 사용하여 최초 호출 및 이후의 호출에 대해 동작하는 쿼리가 달라진다는 것을 유의해두자.
2-2-4. debugging
./gradlew batch:postgresql:bootRun --args='--spring.batch.job.name=victimRecordJob' 이에 대한 동작을 디버깅하기 위해 위 job을 실행해보도록 한다.
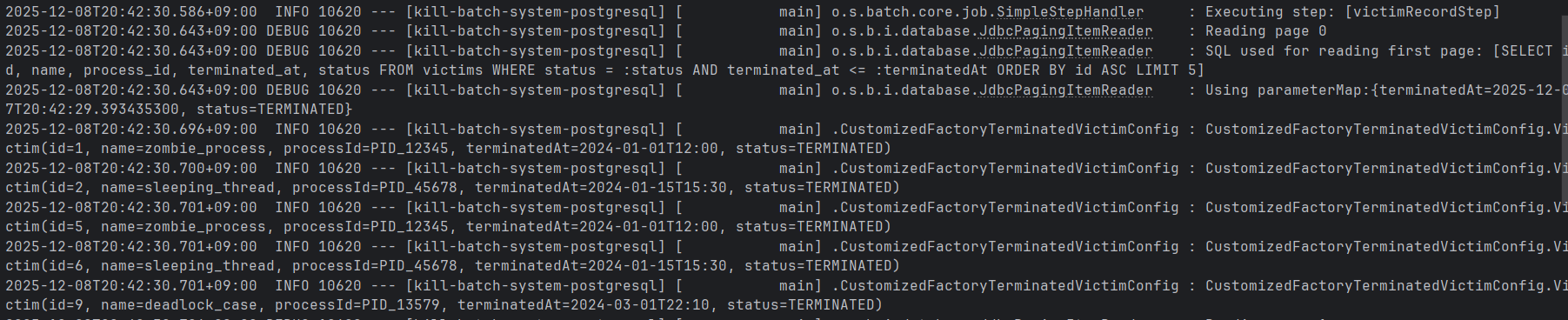
위와 같이, 최초 페이지(0)을 읽을때,
SQL used for reading first page: [SELECT id, name, process_id, terminated_at, status FROM victims WHERE status = :status AND terminated_at <= :terminatedAt ORDER BY id ASC LIMIT 5]위와 같이 지정한 쿼리를 실행해주는 것을 확인할 수 있다.

그 이후의 페이지는
SQL used for reading remaining pages: [SELECT id, name, process_id, terminated_at, status FROM victims WHERE (status = :status AND terminated_at <= :terminatedAt) AND ((id > :_id)) ORDER BY id ASC LIMIT 5]id > lastst_id의 조건이 붙은 새로운 쿼리가 실행되었음을 확인할 수 있으며, 이에 따라 paging한 5개의 데이터를 추출하였음을 볼 수 있다.
참고로 위 방식은 customized factory를 활용한 쿼리이며, 이는 DB별로 제공하는 구현체를 그대로 사용하거나, api 내에서 직접 페이징 쿼리를 작성하는 등으로 동일한 결과를 추출해낼 수 있다.
3. JdbcBatchItemWriter
파라미터를 순서에 따른 대입이 아닌 프로퍼티와 매핑하여, NamedParameterJdbcTemplate를 거쳐 최종적으로 batchUpdate를 동작하여 DB Write를 진행한다.
결론부터 살펴보면 다음과 같다.
[Chunk 트랜잭션 시작]
↓
ItemWriter.write(chunkItems)
↓
JdbcBatchItemWriter
↓
NamedParameterJdbcTemplate
↓
JdbcTemplate.batchUpdate()
↓
PreparedStatement 생성
↓
JDBC Driver
↓
DB (multi-value INSERT 또는 batch execution)
↓
[Chunk 트랜잭션 커밋]write를 하기위해 write buffer에 모여진 chunk 크기의 처리데이터를 최종적으로 JdbcTemplate의 batchUpdate()를 통해 대량의 데이터를 insert 처리한다.
이때,
write(chunk) 호출 후 청크단위로 데이터를 처리한다. 즉,
-
batchUpdate(SQL, chunkSize만큼 파라미터) 호출 후
-
JDBC 레벨에서 일괄 전송하며
-
DB에 "묶어서" multi value insert를 진행한다.
ItemWriter는 row 단위가 아니라 chunk 단위로 동작하며, 실제 DB 호출은 write 1번 = SQL 실행 1회만을 진행한다.
이때 청크데이터는
chunk size = 1000
[
[1, 1000],
[2, 2000],
[3, 3000],
...
]이와 같이 배열 형태로 되어있으며
PreparedStatement ps = connection.prepareStatement(sql);
for (each item in chunk) {
ps.setXXX(...)
ps.addBatch()
}
ps.executeBatch()최종적으로, 해당 배열의 컴포넌트들을 순회하면서 sql 실행을 위한 파라미터를 전달하게 되며 마지막에 1번의 write sql을 호출하여 여러값에 대한 하나의 쿼리를 db에 전달한다.
이때, 내부적으로 multi value insert를 할지 혹은 multi insert(insert 자체를 여러 패킷에 걸쳐 진행)할지는 선택한 dataSource(jdbcDriver)를 통해 결정한다.
| DB | 실제 동작 |
|---|---|
| MySQL | rewriteBatchedStatements=true → multi-value INSERT |
| PostgreSQL | Server-side prepared statement + batched bind |
| Oracle | Array bind (cursor 기반 bulk insert) |
기본적으로 db에 따른 최적화가 진행되지만, 또한 "기본적으로는" batchUpdate + multi value Insert를 통해 대량데이터 INSERT 과정을 진행한다.
이로 인해 각각 독립적인 insert I/O 패킷을 계속 전달하는 것보다는 1번에 sql을 수행하기에, 네트워크 비용이나 DB Parsing, 지연 등에 대한 불필요한 소모가 확실히 줄어든다.
정리하면, JdbcBatchItemWriter의 본질은
“chunk 단위로 batchUpdate를 호출하여 DB와의 상호작용 자체를 최소화하는 것”이고,
multi-value INSERT는 그 위에 얹히는 DB/Driver의 최적화 단계이다.
multi-value insert가 일반적인 insert보다는 유리하긴 하지만, 무조건적으로 실행을 보장하는 생각을 해서는 곤란하겠다.
3-1. 파라미터 전달 과정
몇가지 jdbc item writer의 세부동작사항을 살펴보자.
먼저, NameParameterJdbcTemplate는 내부적으로 프로퍼티 매핑기반의 매개변수 지정을 해주고, 뿐만 아니라 최종적으로 한번의 batchUpdate() 호출을 통해 preparedStatement를 db에 전송하도록 한다.
이때, 파라미터를 전달하는 방법은 NamedParameterJdbcTemplate는 ItemSqlParameterSourceProvider 혹은 ItemPreparedStatementSetter 이 두가지가 존재한다.
이때,
- ItemSqlParameterSourceProvider
이 메소드를 통해 BeanPropertyItemSqlParameterSourceProvider 구현체를 사용하여, 빈객체를 리플렉션할때 객체의 프로퍼티를 자동적으로 파라미터로 매핑하여 전달하여 준다.
Record 매핑도 가능하며, 해당 api에 대해 customized 구현체를 사용하여 파라미터를 지정해줄 수도 있다.
- ItemPreparedStatementSetter
물음표(?) 방식의 순차적인 파라미터 전달 방식이고, 말그대로 순차적인 매개변수를 설정해주는 방식이다.
4. JdbcPagingItemReader -> JdbcItemWriter 실무 적용
예를 들어 특정 데이터들을 조회하여, 데이터 상태를 바꾸고 바꾼 상태를 DB에 다시 write하는 batch 과정을 진행한다고 하자.
금융권에서 이에 대한 과정을 적용한다면, 아래와 같이,
계약처리를 진행하였는데 중간에 해지하거나, 계약중단을 하였을 경우 해당 내역들을 읽어오고 해당 계약내역을 삭제처리하거나 status를 계약불가 상태로 바꾸는 등의 작업을 진행할 수 있다.
이때 드디어 status를 바꾸는 작업이 바로 "가공하는 과정"인 "ItemProcessor"인데, 그리 중요한 내용은 아니기에 잠깐만 살펴보고 넘어갈 예정이다.
@Bean
public Step orderRecoveryStep() {
return new StepBuilder("dataBatchStep", jobRepository)
.<Pay, Pay>chunk(10, transactionManager)
.reader(dataReader())
.processor(dataProcessor())
.writer(dataWriter())
.build();
}위와 같이 dataReader, dataProcessor, dataWriter를 순서대로 정의한다.
@Bean
public JdbcPagingItemReader<Pay> dataReader() {
return new JdbcPagingItemReaderBuilder<Pay>()
.name("dataReader")
.dataSource(dataSource)
.pageSize(10)
.selectClause("SELECT id, customer_id, pay_datetime, status, product_id")
.fromClause("FROM pay")
.whereClause("WHERE (status = 'CANCELLED' OR status = 'ABORTED'))
.sortKeys(Map.of("id", Order.ASCENDING))
.beanRowMapper(Pay.class)
.build();
}이 중 계약금 지불을 중간에 취소하거나 중단된 내역들에 대해 조회해오며, 일관된 수서 보장을 위해 pay pk(id)를 기준으로 오름차순 정렬한다.
@Bean
public ItemProcessor<Pay, Pay> orderStatusProcessor() {
return pay -> {
pay.setStatus("DISABLED");
return pay;
};
}Processor는 Input Pay를 전달받아, status를 disbaled로 바꾼 후에 다시 Output Pay로 변환, 이를 Writer에게 전달한다(마찬가지로 chunk size만큼 buffer에 저장한 후에 writer에게 전달).
@Bean
public JdbcBatchItemWriter<Pay를> orderStatusWriter() {
return new JdbcBatchItemWriterBuilder<Pay를>()
.dataSource(dataSource)
.sql("UPDATE pay SET status = :status WHERE id = :id")
.beanMapped()
.assertUpdates(true)
.build();
}이후 writer는 processor로부터 전달받은 pay의 상태를 그대로 db에 write한다(beanMapper를 통해 프로퍼티 매핑을 자동적으로 진행하며, update 쿼리를 진행하게 된다).
단, assertUpdates의 경우 true로 설정 시 모든 데이터의 업데이트를 보장(하나라도 업데이트 진행 불가 시 예외를 던져 중단), false로 설정할 경우 일부 데이터를 업데이트하지 않아도 batch job을 계속 수행한다(중복 데이터 처리 및 조건부 처리 등에 사용).
./gradlew batch:postgresql:bootRun --args='--spring.batch.job.name=orderRecoveryJob'동작을 확인해보면,
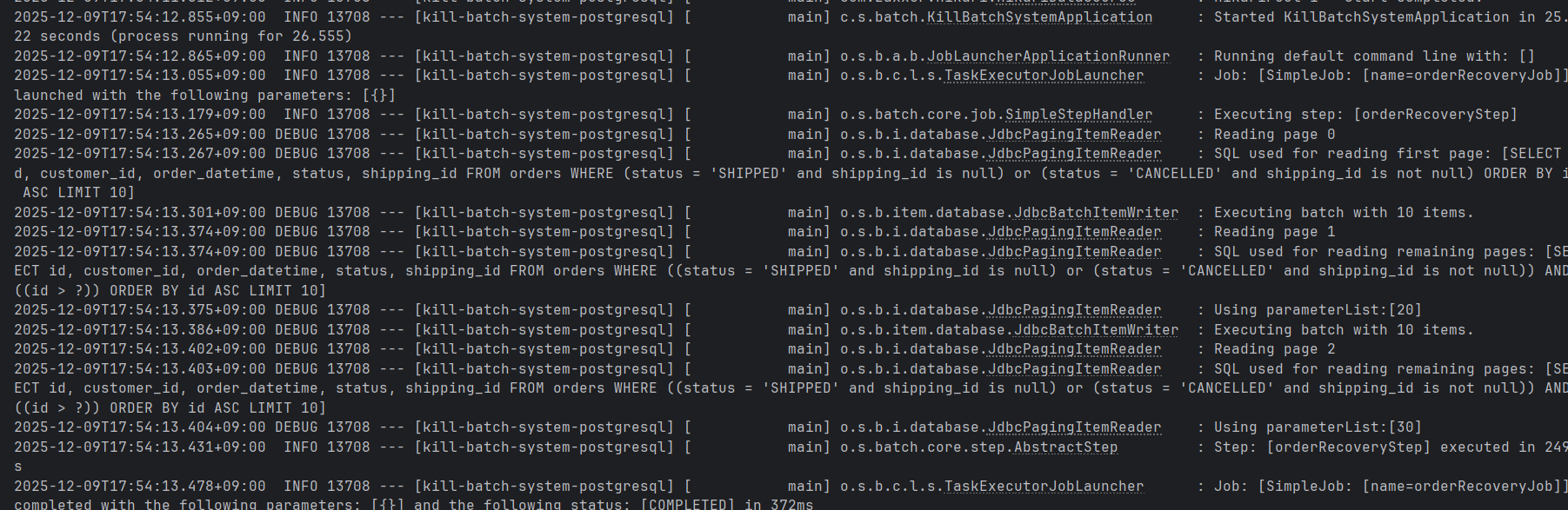
정상적으로 동작했을뿐만 아니라, 내부적으로 데이터도 정상적으로 변경하였음을 확인할 수 있다.
4. 숲을 먼저 보자 - Spring Batch의 관계형데이터베이스의 대용량 데이터를 처리하기 위한 또다른 핵심 도구, JPA ItemReader/ItemWriter
JPA를 활용한 batch Item Reader/Writer 적용 시, 가장 유리한 점은 무엇보다도 기존의 RDD/책임분리 등의 프로젝트 환경을 그대로 활용하여 batch job을 구성할 수 있다는 점이다.
즉, jpa의 영속성 및 책임을 그대로 활용가능하며, 굳이 별도의 책임을 두는 등의 번거로운 작업을 할 필요가 없다.
이것이 가능한 이유는 무엇보다도 JPA가 실무적으로 가장 보편화되고, 많이 활용하는 도구이기 때문일 것이다.
이에 대한 기본배경을 바탕으로, JPA를 활용한 Batch Reader 및 Writer를 구성하는 과정에 대해 분석해도록 한다.
4-1. JPA Item Reader
먼저 JPA를 통해 데이터를 어떻게 읽어오는지 분석해보도록 한다.
JPA도 jdbc와 마찬가지로, cursor 기반의 reader를 제공하거나 paging 기반의 reader를 제공하거나 둘 중 하나의 읽기방식을 제안한다.
다만 이 읽기과정에서 JPA와 Jdbc의 중요한 차이점은 entity manager가 개입하는지에 대한 여부이다.
이에 대한 기본적인 이해를 바탕으로 JPA Item Reader는 어떻게 동작하는지 분석해보자.
4-1-1. JpaCursorItemReader
결론부터 기술해보면, JpaCursorItemReader의 데이터 읽기 과정은 아래와 같다.
JpaCursorItemReader는 entityManager를 기반으로 쿼리를 실행하고, 이 실행한 쿼리결과를 resultSet을 거쳐 최종적으로 entity화한다는 것이 핵심이다.
[Step 시작]
|
v
[JpaCursorItemReader.open()]
|
|-- (1) JPQL 결정
| - queryString (직접 지정)
| - OR JpaQueryProvider.buildQuery()
|
v
[EntityManager 생성]
|
v
[EntityManager.createQuery(JPQL)]
|
v
[Query 구성]
|-- setParameter(...)
|-- setHint(fetchSize, readOnly 등)
|
v
[Query 실행]
|
v
[ResultStream / ResultList → Cursor 확보]
|
v
[read() 반복 호출]
|
|-- cursor.next()
|-- row → Entity 객체
|
v
[Entity 반환]가장 우선적으로 데이터 조회를 위한 쿼리 언어를 구성(JPQL, Java Persistence Query Language)하며, queryString 및 JpaQueryProvider를 통해 쿼리를 명기해줄 수 있다(쿼리객체생성의 핵심과정).
JpaCursorItemReader
├─ queryString (고정 JPQL)
└─ JpaQueryProvider (동적 JPQL)이때 queryString의 경우 아래와 같이
reader.setQueryString(
"SELECT o FROM Order o WHERE o.status = :status"
);고정적인 쿼리를 실행하며, 반면 JpaQueryProvider의 경우
provider.setEntityClass(Order.class);
provider.setWhereClause("o.status = :status");
provider.setOrderClause("o.id asc");일전의 jdbcPagingItemReader에서 볼 수 있었던, JPQL 구조를 분해하여 이를 api형태로 나타내어, keySet/Paging 기반의 처리 시 유리한 형태의 쿼리객체 생성방안을 제공한다.
참고로 이 두개의 방안을 모두 설정해주었다면 JpaQueryProvider를 우선적으로 적용하며, 둘 중 하나는 반드시 구성해주어야 한다(쿼리생성).
또한, QueryProvider를 사용할 경우 엔티티에 해당 쿼리를 명시해주는 JpaNamedQueryProvider를 사용하거나, Native SQL을 사용하여 데이터를 조회하는 JpaNatvieQueryProvider를 사용하면 된다.
[JpaCursorItemReader.open()]
|
v
[EntityManagerFactory.createEntityManager()]이후 EntityManager를 생성하여, 해당 쿼리를 실행 및 데이터 읽어오기를 진행하는데, 이 과정이 CursorReader 내부적으로 entityManagerFactory 인스턴스를 생성, 최종적으로 이를 통해 entityManager를 생성한다.
이 entityManager가 읽어온 데이터는 ResultStream/ResultSet에 저장하여, 이때부터 cursor 기반의 스트리밍 기반 데이터 읽어오기가 진행된다.
즉, query를 실행하여 resultStream에 데이터를 적재하는 순간부터 cursor는 open되며, 이때 row와 entity 객체간의 변환과정과 persistence context의 ORM 메모리로의 데이터 적재과정이 발생한다.
DB
──(네트워크)──► JDBC Driver
|
v
ResultSet (JDBC)
|
(fetchSize 힌트 적용)
|
v
Hibernate / JPA Provider
|
(row → Entity 변환)
|
v
Persistence Context (1차 캐시)
일전 jdbc에서 resultSet이라는 원천데이터에서, 우리가 읽을 수 있는 객체로 변환하기 위한 rowMapper를 사용하였다면, JPA에서는 이를 하나의 layer로 감싸서(Adapter pattern과 유사) entity manager를 통해 우리가 읽을 수 있는 객체형태인 persistence context로 저장하는 과정을 진행한다.
이때 cursor는 resultSet 혹은 resultStream을 바라보게 되는데,
[Step 시작]
|
v
EntityManager 생성
|
v
Connection 획득 및 유지
|
v
Query 실행
|
v
ResultSet / Cursor OPEN (계속 유지)
|
v
read() → next() → row fetch
|
v
Entity 생성 → Persistence Context 저장
|
v
다음 read() ...이와 같이 read()호출에 따른 row fetch가 발생할때마다 객체변환 및 cursor 이동이 일어나며, 최종적인 Step 종료시까지 이를 유지한다.
전체적인 동작흐름이 jdbc에 비해서는 다소 복잡하기도 하고, 필요한 물리적 공간이 cursor/persistence context(fetch size + context에 적재하는 메모리 전체)에 해당하기에, jdbc보다는 OOM이 발생할 수 있는 위험이 다소 존재한다.
따라서, JPA의 경우
entityManager.clear(); // PC 초기화
query.setHint("org.hibernate.readOnly", true);와 같이 manager를 clear해주거나, hint를 지정해주는 등의 메모리 과부하 방지 전략을 세우는 것이 필요하다(*이때 hint는 hitValues라는 Batch 5.2ver부터 제공하는 Reader api를 통해 제공할 수 있으며, 특히 fetch size를 직접 명시할 수 있기에 어느정도 편한 최적화가 가능해졌다).
참고. Persistence Context
추가적으로 Persistence Context 적재과정에 대해 기술하면, ResultSet으로 부터 row 1개를 읽어오고 entity로 변환하는 과정 발생 즉시 context에 적재하며, 내부적으로 아래와 같은 Map 형태로 되어있다.
Map<EntityKey, Entity>이때, EntityKey는 아래와 같은 형태로 되어있으며,
EntityKey
├─ entityName
└─ identifier (PK 값)이 형태에서 entity명과 PK값이 저장되어 각각의 row 구분이 가능해진다.
PK = row.id
EntityKey(Order, 42)이러한 형태로, context에 계속 데이터가 쌓이게 되는 것이다.
향후 적재된 context로부터 데이터 조회 시,
if (pc.containsKey(EntityKey)) {
return existingEntity;
}위와 같은 처리를 통해 entity를 반환하여, 데이터를 조회한다(중복 시 내부적으로 update).
clear하지 않으면 제거되지도 않고, GC대상도 아니기에 OOM를 대비하여 적절한 전략이 필요하다.
참고. fetch
내부적으로는 jdbc와 마찬가지로 fetch 후 ResultSet이라는 driver buffer(JPA에서의 1차 캐시는 resultSet이 아닌 Persistence Context이다)에 fetched row들을 저장하는데, cursor는 이 resultSet의 row들을 바라보고 있다.
조금 특이하긴 한데, fetch를 진행할때마다 cursor는 resultSet 버퍼에서 움직이는 것이고, 해당 driver buffer인 resultSet/ResultStream에서 buffer를 모두 소진했다면, 다시 fetch 크기만큼 DB의 데이터를 불러온다.
그리고 충격적인 사실은, 위의 cursor는 application의 cursor이고 DB를 바라보는 cursor또한 따로 존재한다는 것이다(사실 resultSet의 cursor는 DB cursor와 연결된 포인터의 개념).
Application
|
ResultSet.next() -- cursor
|
JDBC Driver
|
DB Cursor (서버 메모리) -- cursor다시, 만약 버퍼에 데이터가 없어서 row를 모두 소비했다면 application cursor는 db cursor에게 또다른 "fetch"를 요청하며, 다만 query를 재실행하거나 cursor를 재생성하지는 않는다.
모든 cursor는 동일하게 유지한다. 다만 fetch만 지속한다.
이때 fetch를 지속하면서, DB cursor 측에서 이 다음에도 계속 읽을 데이터가 있다고 판단한다면, 필요 시점에 적절하게 buffer를 채운다(다음 버퍼를 읽어야하는데 버퍼에 row가 없고, fetch가 가능할 경우).
next()
├─ 버퍼에 row 없음
├─ 아직 fetch 한 적 없음
└─ → DB에 fetch 요청 발생 따라서, buffer, 즉 resultSet/resultStream이 없을때까지 읽어서 cursor의 next가 없다는 의미는 곧 DB의 cursor도 다음이 없다는 의미이며, 더이상의 읽을 데이터가 없기에 모든 읽기 수행을 종료하는 것이다.
4-1-2. 실무적용방안
위 동작원리를 바탕으로 실무에 적용할 수 있는 방안을 탐색해보도록 한다.
@Bean
public Step postBlockStep(
JpaCursorItemReader<Posts> postBlockReader,
PostBlockProcessor postBlockProcessor,
ItemWriter<BlockedPost> postBlockWriter
) {
return new StepBuilder("postBlockStep", jobRepository)
.<Posts, BlockedPost>chunk(5, transactionManager)
.reader(postBlockReader)
.processor(postBlockProcessor)
.writer(postBlockWriter)
.build();
}먼저 step을 JpaCursorItemReader - ItemProcessor - ItemWriter로 구성한다.
@Bean
@StepScope
public JpaCursorItemReader<Posts> postBlockReader(
@Value("#{jobParameters['startDateTime']}") LocalDateTime startDateTime,
@Value("#{jobParameters['endDateTime']}") LocalDateTime endDateTime
) {
return new JpaCursorItemReaderBuilder<Posts>()
.name("postBlockReader")
.entityManagerFactory(entityManagerFactory)
.queryString("""
SELECT p FROM Posts p JOIN FETCH p.reports r
WHERE r.reportedAt >= :startDateTime AND r.reportedAt < :endDateTime
""")
.queryProvider(createQueryProvider())
.parameterValues(Map.of(
"startDateTime", startDateTime == null ? LocalDateTime.now().minusMonths(3) : startDateTime,
"endDateTime", endDateTime == null ? LocalDateTime.now().plusMonths(3) : endDateTime
))
.hintValues(Map.of("org.hibernate.fetchSize", 100))
.build();
}reader가 중요한데, JpaCursorItemReader를 통해 구성하고 동적파라미터는 job 실행시 cli를 통해 받아오도록 구현하였다.
다만, 파라미터를 통한 값이 없을 경우
.parameterValues(Map.of(
"startDateTime", startDateTime == null ? LocalDateTime.now().minusMonths(3) : startDateTime,
"endDateTime", endDateTime == null ? LocalDateTime.now().plusMonths(3) : endDateTime
))를 통해 현재시각에서 -3, +3을 한 지점을 각각 시작 및 종료시각조건으로 설정해주도록 하였다(parameterValues를 프로퍼티화하여 매핑하는 방식이 이토록 편한 이유이다).
그 후 processor, writer를 거쳐 특정 데이터에 대해서만 조회 및 로그로 출력하도록 job을 구성해주었다.
이후,
./gradlew batch:postgresql:bootRun --args='--spring.batch.job.name=postBlockBatchJob'위 batch job을 실행하면
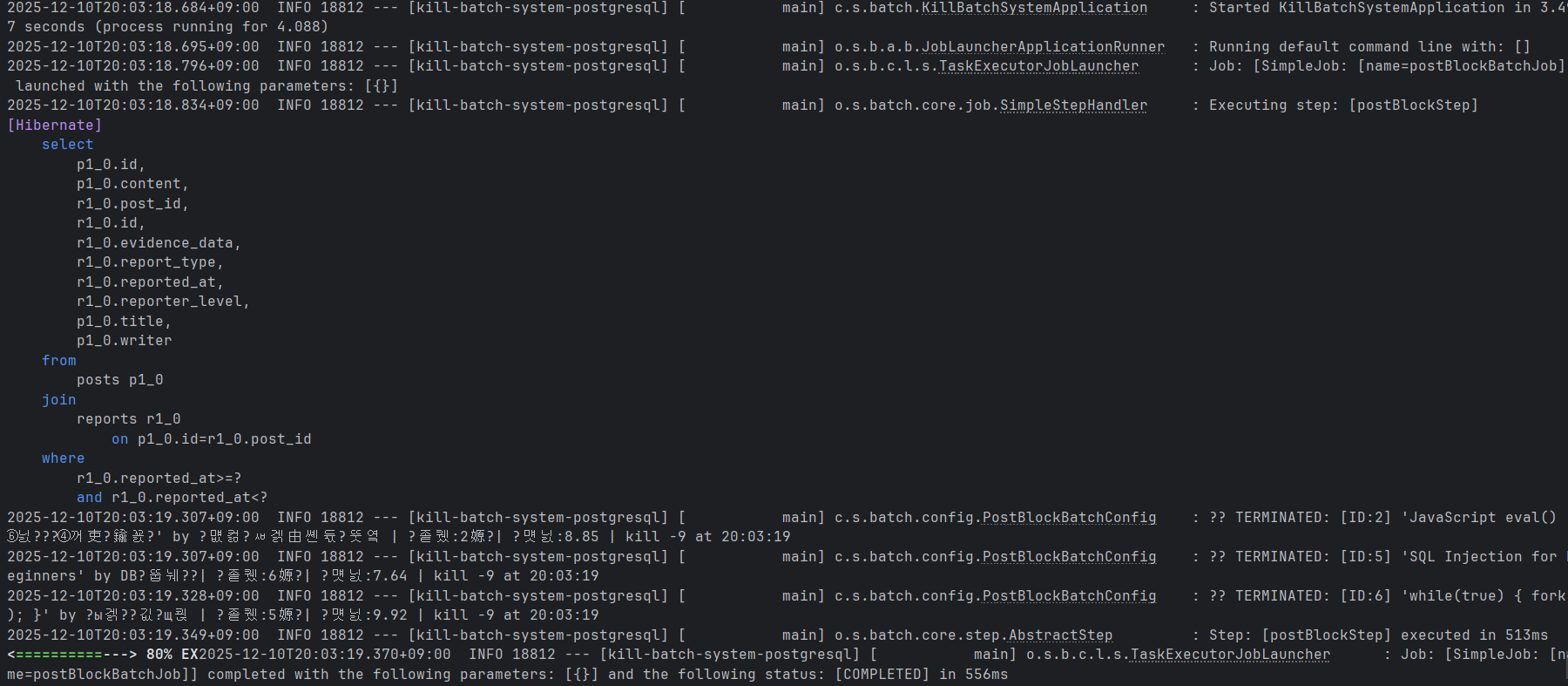
위와 같이 정상적인 실행을 확인할 수 있다.
4-1-2. JpaPagingItemReader
실무적으로는 cursor 기반의 item reader가 권장되지만, 이것 말고도 Spring Batch는 페이징 기반의 데이터를 읽어오는 JpaPagingItemReader 또한 존재한다.
JdbcPagingItemReader와 같이 페이징 방식의 처리이지만, jpa entity를 사용하는 등 내부적인 동작과정에서 다소 차이가 있다.
offset 기반만 제공한다.
JpaPagingItemReader의 치명적인 단점이자, 실무적으로 cursor 기반만 사용하는 이유이다.
JpaPagingItemReader는 offset 기반의 데이터 조회만 가능하며, jdbc와 같은 keySet기반의 확실하고 성능적으로 유리한 reader는 공식적으로 지원하지 않는다.
| Reader | 지원 페이징 방식 | 비고 |
|---|---|---|
| JdbcPagingItemReader | Offset 기반, Keyset 기반(Postgres/MySQL 전용 PagingQueryProvider들) | JDBC 레벨에서 DB Dialect별로 구현체 존재 |
| JpaPagingItemReader | Offset 기반만 | JPA Criteria / JPQL 기반이라 Keyset paging 구조가 없음 |
| HibernateCursorItemReader | Cursor 기반(Streaming) | 페이징 방식 아님 |
이로 인해, 아래와 같이 offset만 변경하면서 데이터를 불러온다.
SELECT id from PAY ORDER BY id ASC LIMIT 10 OFFSET 0;SELECT id from PAY ORDER BY id ASC LIMIT 10 OFFSET 10;SELECT id from PAY ORDER BY id ASC LIMIT 10 OFFSET 20;그러나, 중요한 점은 위에서 기술하였듯이 필요한 데이터만 조회해오는 것이 아니라, 일단은 offset + limit의 데이터를 모두 조회한 후에 offset 이전의 데이터는 무시하고 이후의 데이터만 읽어오는 방식을 취한다.
이 동작방식으로 인해, 뒤로 갈수록 성능은 급격하게 감소하는 특징이 있다.
더불어, 추가적인 문제점이 존재한다.
- 데이터 추가 및 삭제에 대한 데이터 중복 및 누락 등, 실시간 데이터 변경에 취약하다.
- 데이터가 클 수록 성능적으로 취약하고, 그만큼 DB 측에서도 엄청난 메모리/성능적인 취약점이 발생한다.
- Pagigng 원리상, fetch type이 eager로 하는 것이 사실상 필수적, batchSize 역시 lazy type에서는 적용되지 않기에 환경적 한계점이 존재한다.
따라서, 전반적으로 실시간 데이터를 반영하기에 취약하고 그만큼 데이터정합성을 확보하는 것이 불리하므로, 이를 보완하기위해 Spring Batch에서 실시간으로 바뀌는 데이터에 대해 지원하는 스트리밍 및 실시간 처리를 사용하거나, 애초에 데이터가 바뀌지 않는 환경적 구성을 보장해주도록 한다.
페이지를 진행하면서 새로운 쿼리 실행
Jdbc와 마찬가지로, 한번의 쿼리가 아닌 각 페이지마다 새로운 쿼리를 날려서 실행한다.
offset이 달라지기에 당연한 부분이고, 기존 cursor기반의 경우 doOpen 최초 쿼리 한번 실행 후, resultSet/resultStream의 fetch/doRead내부의 hasNext를 반복했지만, doReadPage()를 max page까지 반복호출하여 읽는다.
이때 내부적으로 setFirstPage, maxResult를 통해 시작위치(offset) 및 페이지 크기를 설정 후 동작하게 되고, getResultList를 통해 현재 페이지에 대한 데이터를 추출해온다.
.queryString("""
SELECT DISTINCT p FROM Posts p
JOIN p.reports r
WHERE r.reportedAt >= :startDateTime AND r.reportedAt < :endDateTime
ORDER BY p.id ASC
""")
.parameterValues(Map.of(
"startDateTime", startDateTime == null ? LocalDateTime.now().minusMonths(3) : startDateTime,
"endDateTime", endDateTime == null ? LocalDateTime.now().plusMonths(3) : endDateTime
))
.pageSize(5)JpaCursorItemReader를 해당 빌더를 사용하고, 위와 같이 queryString(JPQL) 및 pageSize 설정에 대한 부분을 변경해주면 된다.
이때 유의할 점은, 기존 fetch를 페이징 방법에 그대로 사용하면 스트리밍 방식이 아닌, 모든 데이터를 일단 DB버퍼에 저장하고 선별하는 작업을 진행하기에 대량의 데이터의 경우 메모리/성능 상으로 적합하지 않다(크기가 너무 크고, 모든 데이터를 한번에 로드한다).
다만, 이 경우 N+1문제가 그대로 발생할 수 밖에 없기에, 이 경우 fetchType을 eager로 임시조치해주었으며, batchSize를 적용하여 한번에 페이지크기만큼 fetch해올 수 있도록 설정하였다(batchSize가 lazy에서는 적용되지 않는 것도 이유이기도 하다).
유의해야할 점, lazy 동작 시 내부적으로 트랜잭션을 시작하는 동안에는 Report 엔티티를 조회하지 않는다, 트랜잭션 종료 이후 필요시점에 실제 DB로부터 데이터를 fetch해오기에, 트랜잭션 내에 동작하는 batchSize는 순서상 동작하지 않는다(원리적으로도 한번의 조회를 위한 fetch를 위해선 eager가 적절).
즉, report를 page size만큼 조회해야 하는데, 이러한 IN조건을 적용하기 위해선 모든 데이터가 일괄 조회되어야 한다.
이때 batchSize의 IN조건은 트랜잭션 내에서만 유효하지만, lazy로딩으로 인해 그 이후의 쿼리실행 및 트랜잭션에 대해서는 적용되지 않으므로 혹시나 lazy fetch type에 대한 batch size는 적용되지 않는다는 것을 기억하자.
페이징 정렬의 유지를 위해 ORDER BY는 필수이다. 이는 jdbc 방식과 동일하다.
참고로 데이터 중복 제거를 위해 distinct를 사용하였다.
참고. transacted
내부적으로, JpaPagingItemReader는 transacted라는 조건 내에서 데이터를 읽기전에(executeQuery), entityManager를 열고 flush, clear 작업을 진행한다.
즉, 내부적으로 컨텍스트를 읽어왔음에도, 본인이 변경한 컨텍스트를 flush를 통해 반영해옴으로써 읽기 이외의, 마치 "변경이 필요한 사항을 미리 읽어와버리는" Dirty Read의 상황이 발생해버리는 것이다(청크단위의 커밋이 아닌, 읽기 단위의 커밋 발생).
즉, 의도치않게 DB수정이 발생하게 되어, 참 여러가지로 JpaPagingItemReader 사용 시 골치아픈 상황이 일어난다.
따라서, Dirty Read를 방지하기 위해(데이터를 읽기전에 entityManager를 flush하는 행위), 또한 batchSize를 정상적으로 적용하기 위해 trasnacted를 애초에 false로 설정하여야 한다.
batchSize는 애초에 lazy 상황에서는 적용 불가하며, transacted false 설정 시, entityManager의 entity 관리가 더이상 일어나지 않기 때문에 lazy로딩 자체도 불가능해진다.
pagingItemReader를 사용할때는 transacted false, fetch type EAGER로 설정하여 진행하는 것이 맞다.
물론 이러한 복잡한 설정을 피하고 애초부터 Cursor Item Reader를 선택하는 것이 현명한 방법일 수 있다.
4-2. JPA Item Writer
jpa item writer는 말 그대로 JPA에서 제공하는 jpaTransactionManager를 활용하여, entity manager에서 관리하는 영속성 컨텍스트를 DB에 반영하는 컴포넌트이다.
@Bean
public JpaItemWriter<BlockedPosts> postBlockWriter() {
return new JpaItemWriterBuilder<BlockedPosts>()
.entityManagerFactory(entityManagerFactory)
.usePersist(true)
.build();
}JpaItemReader와 빌더패턴은 거의 비슷하다.
위와 같이 entityManagerFactory를 주입받고, usePersist를 통해 Batch 작업내역을 insert 할 것인지(false), update 할 것인지(true) 선택해주면 되겠다.

위에서 구성해준 job을 설정해주었다면, usePersist를 true로 설정한대로 INSERT를 진행해주었음을 확인할 수 있다.
참고로, 이 hibernate 로그는 생성한 쿼리일 뿐이고, 내부적으로는 각 itemWrite의 transactionManager가 동작한 batchUpdate 구문(multi value insert)으로 보아도 무방하다.
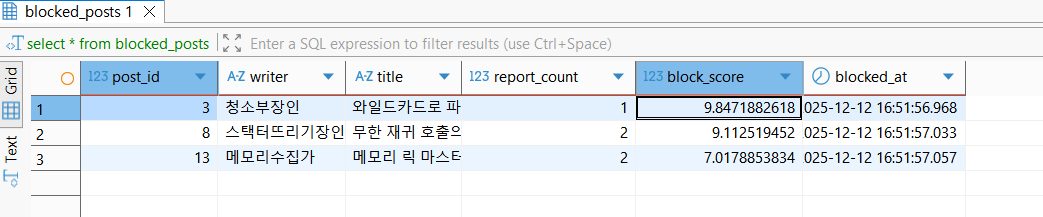
만약 이 상태로 batch를 실행하면 위와 같이 post id를 그대로 blocked post의 pk값(id)로 사용하는 동작으로 진행한다.
하지만, 원본 post엔티티의 id값을 그대로 pk에 사용하지 않고, 해당 도메인의 독립적인 id값을 가지도록 그 정책을 정할 수도 있다(특히, 하루가 지난 이후에 동일한 게시물의 신고이력 등 동일 게시물에 대한 누적 전략을 활용할 필요가 있을 경우).
이럴 경우, Blocked Post라는 도메인의 별도 ID생성전략을 사용할 수 있다.
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "bloked_posts_id_seq")
@SequenceGenerator(name = "blocked_posts_id_seq", sequenceName = "blocked_posts_id_seq", allocationSize = 50)
private Long id;이처럼 pk id값에 대해 postgresql(또는 이에 준하는 RDB)에서 제공하는 시퀀스를 할당(allocated) 받아 사용하도록 PK전략을 구성해준다.

이를 통해 기존의 id값과 별도로 blocked_post 별도 도메인의 pk값을 설정하여 관리가 가능해진다.
참고. JPA Transaction Manager
JPA Item Writer에 대해 알아보기 전에 먼저 유의해야할 점은, 트랜잭션 매니저에 대한 부분이다.
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'JPA 의존성을 추가하는 순간, Spring Boot의 transaction Manager의 교체가 이루어져, 기존 JDBC기반에서 변경 후 JPA기반으로 설정된다. 정확히는 JpaTransactionManager를 등록함으로써 Batch는 PlatformTransactionManager 타입의 매니저 객체를 Jpa트랜잭션 매니저로 자동 선택하게 된다.
즉, spring boot는 위 의존성을 추가하는 순간 단순 classpath 등록 뿐만 아니라, spring boot에서 사용하는 기본 datasource를 JpaTransactionManager로 변경, 선택한다.
참고로 spring boot가 아닌 환경에서는 transactionManager를 JpaTransactionManager로 직접 명시해주어야 할 필요가 있다. 기본적으로 엔티티매니저에 의한 트랜잭션이 이루어지기 위해서는 그에 맞는 트랜잭션 매니저인 JPaTransactionManager를 사용하는 것이 적절하기 때문이다.
JPA 쓰기(merge/persist/flush)는 JPA 트랜잭션과 영속성 컨텍스트의 관리가 필요하므로, 명시적으로 JPA TM을 사용하도록 하는것이 기본적인 권장사항이기 때문이다.
이러한 사항들을 종합하여 고려하였을때, Jpa 설정에는 transactionManager를 Jpa기반으로 변경하여 사용하고, 그 이외 jdbc기반 설정에는 dataSourceDataTransactionManager를 사용하도록 직접 명기하는 것이 가장 좋을 것이다.
참고로 transacted = true일 경우 Read-only(Writer를 통해 DB update가 이루어지지 않는 job의 경우 트랜잭션 매니저 종류와 상관없이, 자체적으로 엔티티 매니저를 생성하여
protected void doOpen() throws Exception {
this.entityManager = entityManagerFactory.createEntityManager();
}Reader가 Writer에게 컨텍스트를 넘기기 전에 flush하여 DB에 예상치 못한 반영이 일어날 수 있다.
이를 방지하기 위해, transacted = false로 설정하여 Step 트랜잭션이 애초부터 reader의 컨텍스트를 공유하도록 설정해주는 것이 좋다.
그리고 기억해두자, 애초에 트랜잭션 매니저를 직접 명시해주어 Reader/Writer에 맞게 적절한 트랜잭션 매니저가 구성되도록 하자.
참고. Entity Builder 설정과 생성자
Processor를 통해 Input class를 전달받고, 이를 target class(Output)으로 변환할 수 있도록 아래와 같이 빌더패턴을 설정해주었다.
@Entity
@Getter
@Table(name = "blocked_posts")
@Builder
public class BlockedPosts {
@Id
@Column(name = "post_id")
private Long postId;
private String writer;
private String title;
@Column(name = "report_count")
private int reportCount;
@Column(name = "block_score")
private double blockScore;
@Column(name = "blocked_at")
private LocalDateTime blockedAt;
}이때 이 BlockedPosts 패턴을 실질적으로 사용하는 부분을 살펴보면 다음과 같은데,
return BlockedPosts.builder()
.postId(post.getId())
.writer(post.getWriter())
.title(post.getTitle())
.reportCount(post.getReports().size())
.blockScore(blockScore)
.blockedAt(LocalDateTime.now())
.build();위와 같이 기본생성자가 아닌 인자생성자를 build함에도 불구하고,

위와 같은 컴파일 오류가 발생한다.
그런데 이상태로 실행을 하게되면 정상적으로 동작하며, 컴파일 오류는 발생하지 않는다.
개발자 입장에서는 기본생성자가 필요가 없고, 애초에 빌더패턴을 사용하게되면 인자생성자를 만들고, 동작도 정상적으로 이루어지는데 왜 기본생성자에 대한 강제성을 부여하는가에 대한 의문이 발생한다.
이에 대한 이유는 바로 JPA 사상으로 부터 비롯된다.
우리는 아래 세가지 사항은 알고있다.
- 어떠한 생성자도 명기하지 않는다면, JPA는 기본생성자를 만들어 제공한다.
- 기본생성자를 명기하면, 인자생성자는 자동 빌드대상이 아니며 직접 명기해주어야 한다.
- 인자생성자를 명기하면, 반대로 기본생성자는 자동 빌드대상이 아니며 직접 명기해주어야 한다.
Builder 어노테이션을 사용하게 되면, 내부적으로 Lombok 이 생성자를 추가하므로 기본 생성자가 사라지게 되어 반드시 직접적인 명기가 필요하게 된다.
즉, 이로 인해 JPA의 스펙위반이 발생하여 기본생성자를 만들라는 강제성을 띄게 되는 것이다.
다만, 내부적으로 Blocked Post라는 인자생성자를 사용하지만, 기본생성자를 사용한 로직이 없기때문에 컴파일 오류 및 런타임 오류는 발생하지는 않지만, JPA 측에서는 표준위반을 감지하여 기본생성자를 만들라고 강제하게 되는 것이다.
이처럼 기본적인 생성자 관련 표준과 작동원리에 대해 이해하고, 빌더패턴을 사용하도록 하자.
참고. PK 생성전략(*GeneratedValue/SequenceGenerator)
결론부터 말하자면, JPA Hibernate는 성능최적화를 위해 시퀀스 값을 allocatedSize 만큼 할당받아 오고 메모리에 저장, INSERT 직전에 해당 시퀀스값(nextval)을 id값에 세팅하여 최종 DB에 flush한다.
이러한 기본적인 시퀀스 생성 전략을 바탕으로, 크게 3가지 방안을 선택할 수 있다.
- strategy = GeneratyionType.SEQUENCE
해당 전략을 단일로 명기해도 되고, 위와 같이 generator를 별도로 설정하여 postgresql에서 설정한 시퀀스를 별도로 명기해줄 수도 있다.
entityManager.persist(blockedPost);위와 같이 entity manager 측에서 컨텍스트를 영속화하기 전에, ID생성전략을 먼저 탐색한다.
이에 따르면 시퀀스 생성 전략이 postgresql(현재 연결되어있는 DB)의 시퀀스를 그대로 할당받아와서 사용하며, 이를 그대로 pk id값에 세팅한다.
entity.setId(42L);이제 JPA Hibernate 측에서 최종적으로 INSERT를 진행한다.
insert into blocked_posts (id, blocked_at, ...)
values (42, '2025-12-12 17:00:00', ...);참고로, hibernate의 allocationSize는 기본값이 50인데, 말 그대로 50개의 크기만큼 시퀀스를 메모리에 저장해두었다가 계속 persist를 진행한다.
시퀀스가 50개를 넘어가면, 그때 DB에게 nextval를 호출하여, 최종적으로는 DB의 통신I/O 소모비용을 절감할 수 있다.
물론 DB sequence를 create할때 by만큼의 크기를 설정하기에, 해당 환경에 맞추거나 application server에서 사용 중인 크기에 맞추어 시퀀스 크기를 알맞게 조절하는 것이 필요하겠다.
- strategy = GeneratyionType.IDENTITY
참고로 JPA에서 제공하는 자체적인 시퀀스라는 것은 없다.
무조건 현재 사용중인 DB로부터 시퀀스 정보를 추출해오는데, 이것이 시퀀스냐 auto increment인지에 따른 차이이다.
IDENTITY의 경우, DB의 auto increment를 사용하는데, SEQUENCE나 TABLE 전략에서 시퀀스를 미리 할당(캐싱)해오는 것과는 달리 DB에 직접 접근해야 비로소 id값을 알 수 있게 된다.
이 경우,
- Hibernate는 INSERT 전에는 ID 값을 모름.
- INSERT문에서 id를 제외하고 INSERT
- DB가 auto increment 로 PK 생성
- INSERT 결과에서 생성된 PK를 다시 읽어옴
의 4가지 과정을 거치게 되어, 결론적으로 말하면 INSERT 전에는 ID값이 무엇인지 모르고, INSERT를 먼저 실행해야 id값을 DB로부터 얻어올 수 있다.
따라서, IDENTITY 전략을 사용할 경우, INSERT를 개별적으로 실행해야 하며 구조적 특성상 multi value insert가 불가능하다.
따라서 성능적으로 SEQUENCE 방법과 많은 차이가 발생하기에, 웬만하면 SEQUENCE 전략을 사용하도록 하자.
- strategy = GeneratyionType.TABLE
table 전략을 선택하면 시퀀스용 테이블을 만들어 해당 테이블을 PK값 생성에 사용하겠다는 의미이다.
보통 Oracle에서 많이 사용하는데, IDENTITY와 마찬가지로 DB를 거쳐서 최종적인 ID값을 추출해온다.
더불어, 새로운 ID를 생성할때마다 table 전략의 경우 새로운 트랜잭션이 필요하고, 이 과정에서 PK table에 대한 행장금이 발생할 수 있기에, 배타락에 따른 대기열 발생으로 대량의 데이터를 다루는 batch에서는 치명적인 성능적 하락이 발생할 수 밖에 없다.
따라서, 웬만해서는 SEQUENCE 전략을 사용하자.
참고. persist 선택 전략
앞서 persist를 true로 선택시 insert, false로 선택시 update 전략을 사용한다고 하였는데, 특성상 아래와 같은 구조를 지니게 된다.
- insert(true)
Reader로 읽은 Input 항목을 다시 Processor를 통해 가공하여, 최종적으로 Write에 전달할 Output 항목이 보통 따로 운용된다.
이에 따라 Output target class는 신규 INSERT할 데이터를 저장할 엔티티로 운용하며, INSERT할 테이블에 맞게 target class/entity를 관리한다.
- update(false)
Reader로 읽은 Input 항목과 Writer에 전달할 Output 항목이 보통 같은 엔티티로 운용된다.
update하기 위해서는 청크 단위로 처리할때, 반드시 update를 위한 기존 컨텍스트를 조회해오는 SELECT가 선행이 되어야 하며, 기존의 데이터를 수정한다는 목적이 명확히 있기 때문에 읽어오고 쓸 테이블이 같고, 자연스럽게 Input / Output 항목이 동일하게 운용이 되는 것이다.
따라서, 보통 I/O targetClass가 동일하며, 이에 따라 읽기, 쓰기 트랜잭션이 동일한 테이블에서 발생한다.
5. 결론
지금까지 관계형데이터베이스의 데이터를 읽고 쓰기 위해 JDBC 및 Jpa 기반의 트랜잭션 매니저와 ItemReader/ItemWriter를 활용하여 Batch Job을 구성하고 실행하는 방법에 대해 분석해보았다.
단순히 batch job 자체에만 국한된 내용이 아닌, JPA의 설계와 sequence와의 연관관계, entity manager의 flush 동작에 따라 batchUpdate가 어떻게 이루어지는지(단일 insert/multi value insert)..여러모로 실무에 필요한 내용들을 전반적으로 넓고, 깊게 살펴볼 수 있었던 기회였다.
데이터들을 보관, 관리하고 batch를 통해 데이터를 가공하고 운용하는 모든 과정은 결국 RDBMS에서 비롯되며, 이에 대한 JDBC 및 JPA 등 여러가지 연관 개념에 대해 깊이있는 이해를 통해 데이터 관리방안 및 batch job 실행 전략을 다양하게 생각하고 고민해볼 수 있었다.
지금의 과정을 시작으로, 유연하고 적절한 설계와 batch 구현을 위해 실무에서 적극 활용할 수 있도록 하자.
