[백엔드] 계층형 데이터를 DBMS차원에서 손쉽게 관리할 수 있는 방안(불필요한 조회비용 감소) - 계층구조의 문자열화 및 MySQL Collation을 중심으로
백엔드
1. 개요
지금까지 데이터 관리를 할때 계층 구조가 존재할 경우(MIS/Back Office) 단순히 ID/PARENT_ID 두가지 항목만을 관리하였다.
두 항목만을 관리항목으로 고려하였기에, 데이터를 표현할때는 CONNECT BY와 LEVEL을 활용하였고, 이러한 데이터 구조와 표현을 당연하게 생각하였다.
그러나 금번 개인 프로젝트를 진행하면서 계층 구조를 표현할 수 있는 또 다른 방안이 있다는 것을 알게 되었고, 지금까지 당연하게 생각해왔던 방법이 상황에 따라 오히려 더 어려운 접근 방법이 될 수 있다는 것을 깨닫게 되었다.
계층 구조를 표현할 수 있는 또 다른 방안에 대해 공부한 내용을 남긴다.
2. 기본적으로 CONNECT BY/LEVEL을 사용하지 않아도 적절한 정렬방식을 채택하여 계층구조를 표현할 수 있다.
다시 한번 강조하길, 지금까지 완전히 잘못생각하고 있던 점 중 하나로, 기본적으로 계층구조를 표현할 수 있는 방법에는 CONNECT BY 이외 단순히 정렬조건을 적절하게 배열하는 것도 있다.
3. 기존 2depth 데이터구조에서 Ndepth 데이터구조로 확장하였을 경우
아래 그림과 같이, 기존 2depth 계층구조(오른쪽)에서 확장 Ndepth 계층구조(왼쪽)로 데이터를 표현하다고 해보자.
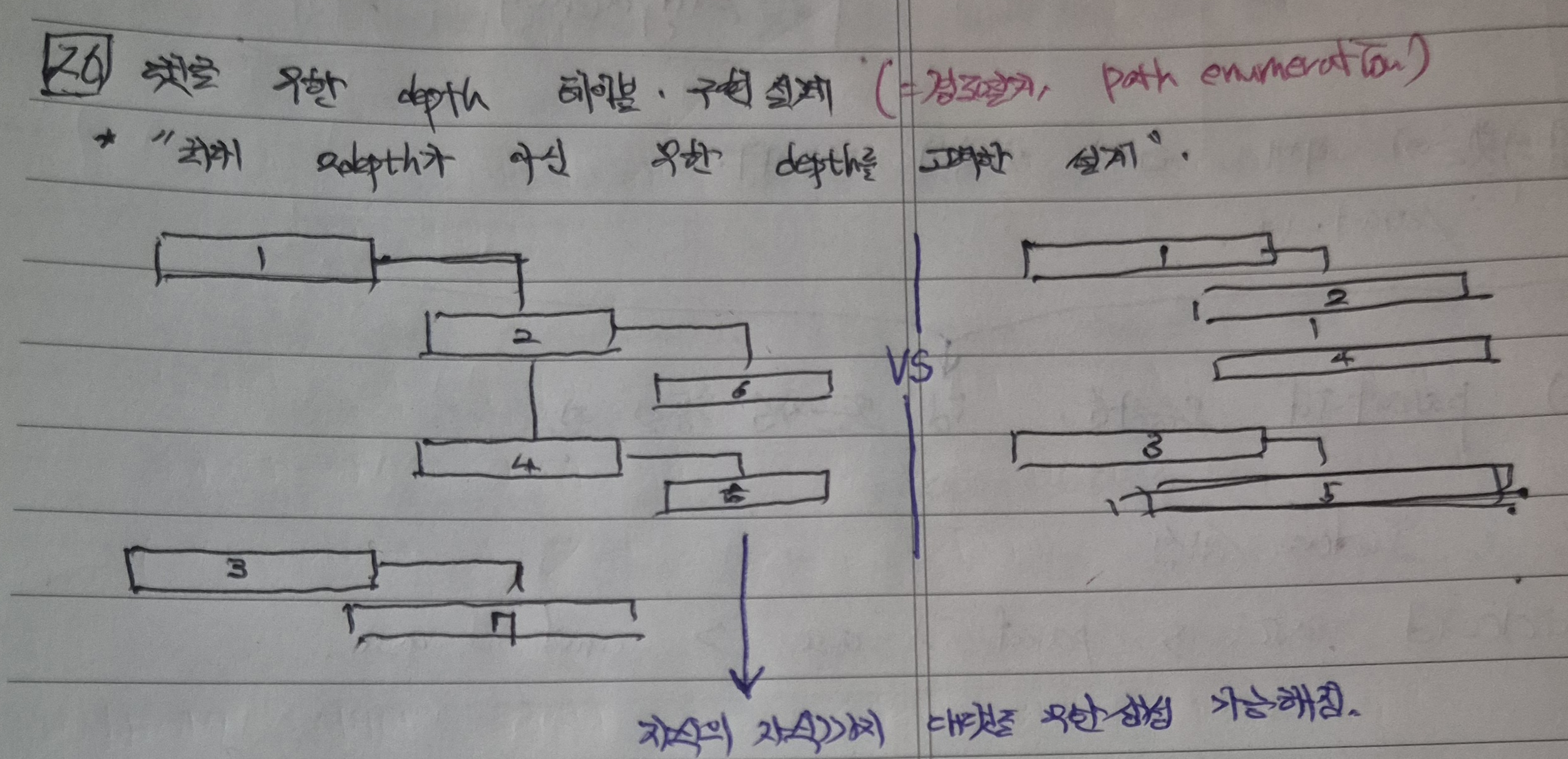
이 구조에서는 기존 부모댓글과 하위댓글의 2depth 계층구조만으로 존재했던 부분이, 부모댓글에서 무한한 depth로 대댓글이 이어져가는 형태로 확장하였음을 파악할 수 있다.
이때, 기존 2depth에서 이용하였던 parent_id asc, comment_id asc로 페이징형 정렬 조건을 활용한다 하더라도 계층구조를 온전히 보장하지 못하므로 다르게 표현하기 위한 방안을 고민해야 한다.
그리고 이때 중요한 점은 굳이 CONNECT BY/LEVEL 등으로 natvie query를 복잡하게 만들지 않고도 DBMS에서 제공하는 장치 및 정렬 조건 등을 통해 계층 구조 표현이 가능하다는 점이다.
4. 문자열을 통해 각 계층구조를 표현하는 아이디어
이 아이디어의 핵심은 각 계층구조를 문자열로 나타내는 것이며, 하위 댓글은 상위 댓글의 문자열(=경로 혹은 계층정보)를 그대로 상속받아 사용한다는 점이다.
기존의 id 정렬만으로는 N depth의 계층구조를 표현하는데 한계가 있고, 각 계층 정보는 지금까지 거쳤던 모든 부모의 정보를 보유하고 있어야 한다는 점을 활용하여 문자열 정보로 각 계층 정보를 표현하겠다는 의도이다.
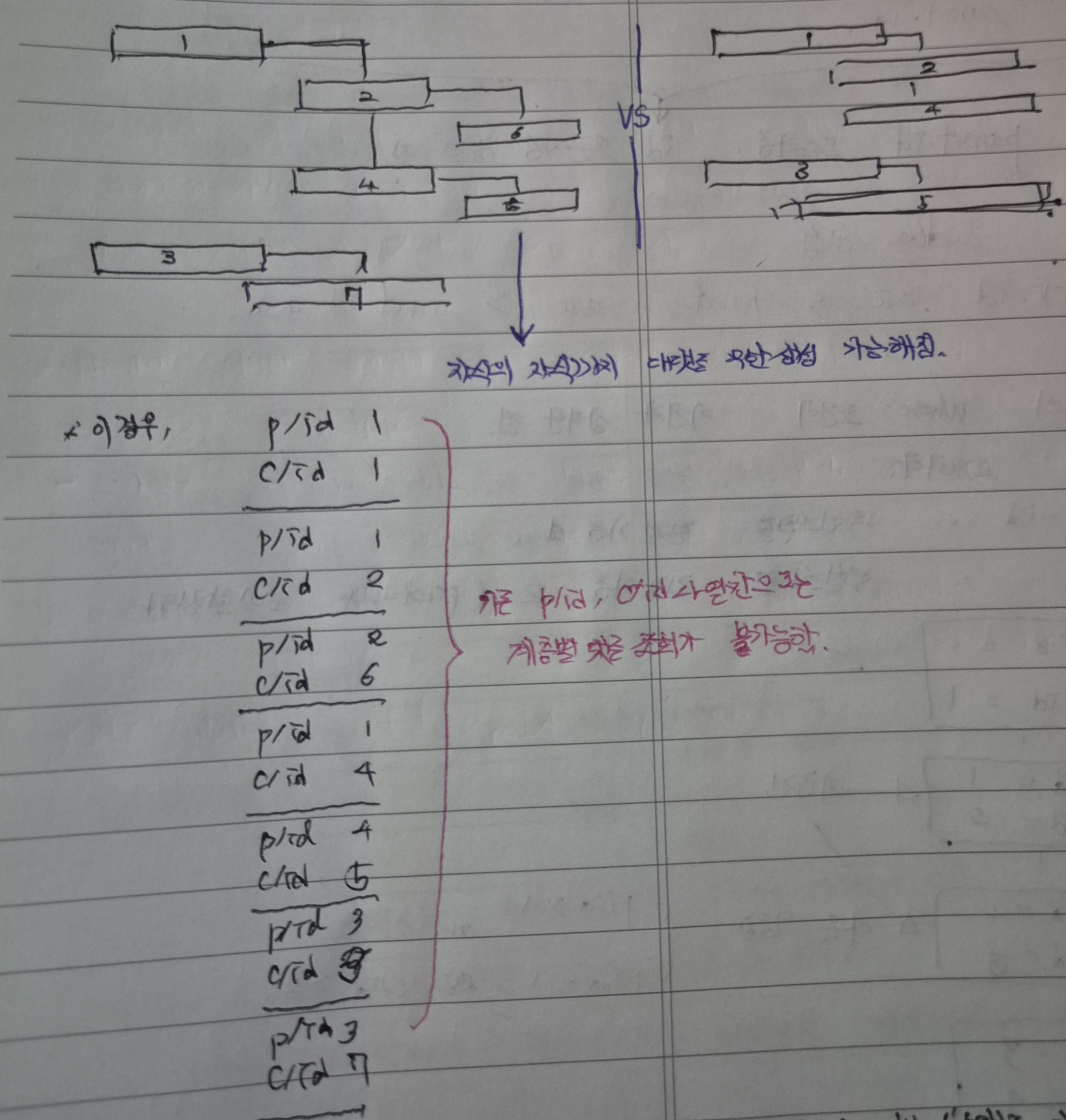
이처럼 N depth 계층구조의 데이터를 문자열로 표현하고자 할때, 각 depth별로 5자리의 문자열로 표현한다는 것이 핵심이며 하위 depth의 데이터는 부모의 문자열을 그대로 상속받고 자신의 depth 구조를 이어서 표현한다.
5. DB Collation
이때 제기할 수 있는 의문은, 그렇다면 각 자리를 0~9의 숫자로 표현하므로 depth별 표현할 수 있는 데이터의 수가 10만개로 제한이 되는지에 대한 여부이다.
이때 이러한 공간적 한계를 극복하고자 활용할 수 있는 장치가 바로 DB Collation이다.
문자열을 정렬하고 비교하는 방법(즉 구분 여부 등)을 설정하는 장치로, 쉽게 말하면 대소문자나 악센트 등을 구분하는지 그 여부를 설정하여 언어 혹은 문자열의 정렬방법을 정의할 수 있는 장치이다.
select TABLE_NAME, TABLE_COLLATION
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'comment';이처럼 Collation 설정은 쿼리를 통해서도 확인할 수 있다.

MySQL의 기본 Collation 설정을 확인하였을때, utf8mb4_0900_ai_ci임을 확인할 수 있겠다.
5-1. Collation Detail
세부적으로 Collation 설정 정의를 아래와 같이 확인할 수 있으며, 상황에 따라 적절한 설정을 해주어야 한다.
- utfbmb4 - 각 문자열 자리에서는 utf8 문자 및 최대 4바이트(max byte)의 문자열 표기 가능
- 0900 - 정렬방식버전
- ai - 악센트를 구분하지 않는다.
- ci : 대소문자를 구분하지 않는다.
- bin : 대소문자를 구분한다.
금번의 경우 대소문자 구분 등 세부적인 구분인자 설정이 필요하므로, 기존 ci에서 bin 설정으로 변경해주어야 한다.
참고로, Collation 설정은 https://blog.naver.com/sory1008/223071678680 이곳에서 확인하였다.
5-2. Collation 설정을 참고하여 depth 문자열을 표현하기 위한 컬럼 추가
경로를 문자열화하여 표현하기 위한 컬럼을 별도로 추가해주어야 한다.
이때 데이터의 크기는 부모 댓글에서 최대 5depth를 표현할 수 있다고 제한하여, 5*5인 VARCHAR2(25) 만큼의 데이터 크기를 마련해주도록 한다.
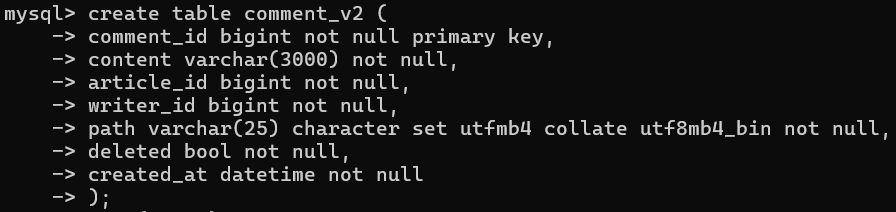
참고로 utf8mb4 세팅을 DDL에서 별도 설정해주어야 collation을 적용할 수 있다.
5-3. 데이터 정렬 기준에 대한 Unique Index 생성
빠른 조회성능을 확보하기 위해, 새롭게 정의한 데이터 정렬 기준에 대한 Index를 생성해주도록 한다.
이때 유의할 점은 각 계층구조를 표현하는 정렬정보의 고유성을 강제하는 의도까지 DB에 기억하도록 조치해야 한다는 점이다.
따라서 일반 Index가 아닌 Unique Index를 생성하여, 데이터 정렬 뿐만 아니라 해당 데이터의 고유성까지 강제하도록 조치한다.
create unique index idx_article_id_path on comment_v2(article_id asc, path asc);
이렇게 하면 comment_v2라는 테이블에서 새롭게 생성한 경로 정보에 고유성(unique) 정보를 추가할 수 있다.
5-3-1. 알아두면 좋은 상식 - PK와 비교(*cf. PK / Clustered Index)
참고로 PK 역시, DBMS가 자동적으로 PK에 대한 Unique Index를 생성하여 고유성을 보장하게 된다.
다만 일반 Unique Index와는 달리 고유성/Not Null의 특성까지 지정이 되는 것이고, 하나의 "특성"이라 보면 되겠다.
Unique Index는 말 그대로 "Index"의 일종이기에 정렬된 데이터를 표기하기 위한 포인터(=PK)를 가지고 있는 하나의 자료구조라 할 수 있고(B Tree), 참고로 Clustered Index는 각 leaf node에서 실제 데이터가 존재하는, "물리적으로 데이터를 위치해놓기 위한 구조"라 보면 되겠다.
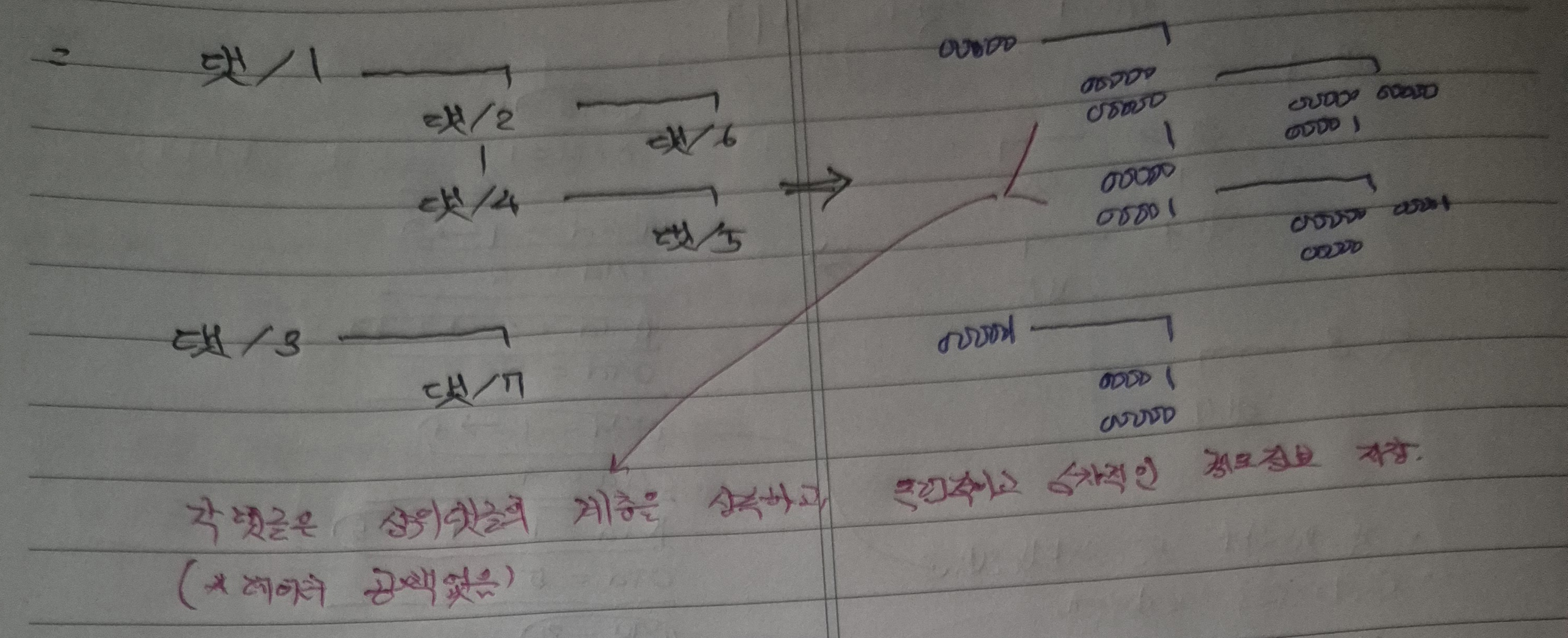
6. 경로정보 생성규칙
경로정보를 생성하기 위한 알고리즘 과정은 아래와 같이 필기한 내용과 같다.

간략하게 말하면, 동일 계층의 가장 이전의 문자열 값을 추출해내기 위해, 다음 계층의 가장 최신 문자열 정보를 추출 및 절삭하고 이에 +1을 하여 경로정보를 생성하는 것이다.
6-1. 경로정보 생성규칙과 인덱스 정렬기준이 다른 상황
다음과 같이 계층 문자열을 채번하기 위한 쿼리를 작성하였다고 하자.
select path
from comment_v2
where article_id = 1 and path > '00a0z' and path like '00a0z%'
order by path desc
limit 1;이 쿼리를 보면 order by path가 desc로 되어있어, 기존 asc로 정렬된 .path index를 정상적으로 활용할 수 있을지에 대한 의문이 들게 된다.
실제 query plan을 살펴보면서 정상적인 쿼리를 실행하는지 확인해본다.

위와 같이 인덱스를 사용하긴 하지만(Using Index), backward Index Scan이 발생한 것을 알 수 있다. Index에서 데이터가 정렬된 기준이 쿼리와 달라 역순으로 데이터를 조회했다는 의미이다(다만 Clustered Index에 도달할 필요없이 바로 데이터를 추출하기는 하였다).
인덱스의 leaf node는 양방향 포인터로 연결되었기에, 정렬이 역순으로 되어있어도 순방향과 동일하게 logN의 시간 소요로 역지점에 바로 도착이 가능하다. 이로 인해 정렬순서가 달라도 빠른 scan이 가능하다.
6-2. 다음 계층의 데이터 생성시, 최초 생성 상황으로 인해 자식 데이터의 값을 추출하지 못하는 경우
말 그대로 해당 계층의 첫번째 데이터 생성인데, 자식 데이터가 없다면 단순하게 부모 데이터를 그대로 상속받은 후 해당 계층 데이터의 최초 채번값을 concat 해주면 되겠다.
6-3. 계층의 마지막 데이터까지 쌓여 다음 데이터 채번 시 overflow가 발생하는 경우
다음과 같이, 2계층에서 zzzzz까지 문자열 채번이 완료되어 다음 경로 정보를 채번할 수 없는 상황이 발생하였다.
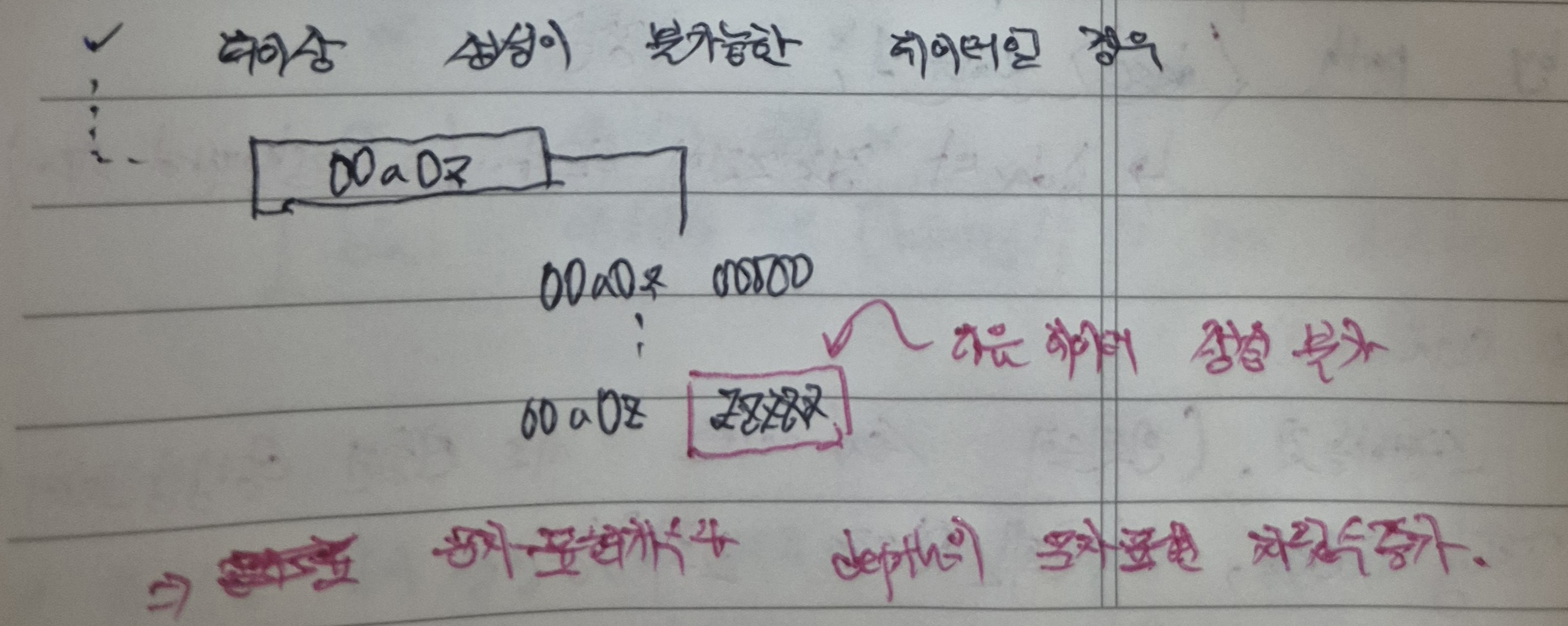
이럴 경우, 문자열의 표현 방법이나 개수를 늘리거나 계층별 문자로 표현하는 자릿수(기존 5자리에서 그 이상으로) 증가 등의 방법을 고려할 수 있겠다.
7. 인덱스 개념 최종 정리(*잘못된 부분 바로잡기)
그리고 이러한 Index Scan 과정을 살펴보면서 잘못 알고있었던 인덱스 개념을 바로 잡고자 한다.
너무나도 중요한 개념이기에 필기내용과 함께 다시 한번 더 이곳에 기록한다.
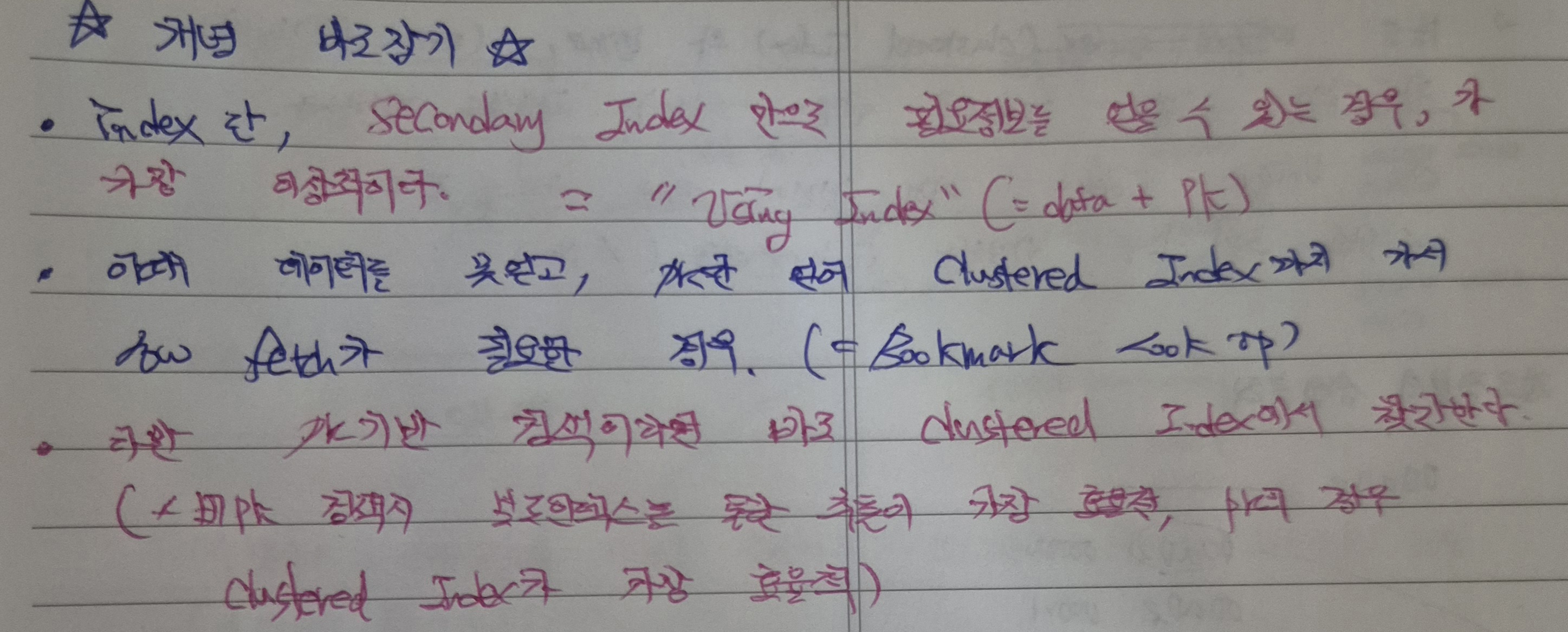
- Using Index는 Secondary Index 만을 이용하더라도 필요한 데이터를 찾았다는 의미로, 비PK 컬럼에 대해서는 생성한 Secondary Index만으로 데이터를 찾는 것이 이상적이다.
- 이때 데이터를 찾지 못한다면, Secondary Index에서 가지고 있는(=Column Index data + PK) PK를 통해 Clustered Index로 이동하고, leaf node에 있는 row data를 fetch하여 최종 데이터를 탐색한다(=Bookmark look up).
- 다만 PK기반의 검색이라면 바로 Clustered Index에서 찾을 수 있긴 한데, PK가 아니라면 Secondary Index 부터 탐색하므로 어떤 데이터냐에 따라 동선적 이점이 생기는 인덱스 경로가 달라진다.
- Clustered Index != Using Index, Using Index = Covering Index, 즉 Index 만으로도 원하는 데이터를 찾았다는 의미이며 Clustered Index로 이동하는 것은 (비PK 데이터에 대해) 비효율적이다.
8. 참고자료
Collation - https://blog.naver.com/sory1008/223071678680
Unique Index - https://velog.io/@profile_exe/DB-UNIQUE-INDEX-%EC%82%AC%EC%9A%A9-%EC%9D%B4%EC%9C%A0
