1. 개요
금번의 개인 프로젝트는 각 서비스마다 별도의 Database를 두는 MSA 환경으로 진행하고 있는데, 그러다보니 일전에는 단순하게 생각했던 부분들이 지금의 환경에서는 좀 더 깊게 생각해볼 문제라는 것을 알게되었다.
이번에 게시글(Article), 좋아요(like) 기능을 구현하였다.
그 설계과정에서 이러한 구조적/성능적 고민을 많이 하였는데, 그 고민하였던 과정과 이를 통해 공부한 내용들을 기록한다.
2. 좋아요 수 기능 설계 과정
테이블 비정규화와 이와 관련한 분산 트랜잭션 등, 설계적인 고민을 많이 하였던 기능이 바로 좋아요 수 기능이었다.
한 게시글에서 사용자는 한개의 좋아요를 생성하거나 취소할 수 있다.
이때 그 게시글에 대해 생성한 총 좋아요 개수를 구하고자 한다.
이전의 나라면 단순하게
ASIS : 게시글 테이블에 단순히 좋아요 수 컬럼을 넣으면 되지 않을까? 사용자가 좋아요를 누를때마다 좋아요 수를 갱신하면 되니까.
하지만 지금의 환경에서는 고려사항이 많다.
- 어떤 사용자가 좋아요를 눌렀는지 알아야 한다.
- 좋아요 수가 위 상황에서는 비정규화는 아니지만, 게시글과 좋아요 수 처리에 대한 책임이 하나의 테이블에 있어 동시성 문제로 인한 데이터 유실 가능성이 존재한다.
- 게시글과 사용자까지 고려한 별도의 좋아요 테이블이 필요하며, 두 기능은 서로 다른 도메인이므로 완전히 분리하여 구현해야 한다.
3. 게시글과 좋아요는 다른 도메인이다.
TOBE : 이에 따라 두 기능의 도메인을 분리하여 구현하도록 한다.
따라서 두 기능의 도메인을 분리함에 따라, 최소한 "게시글" 도메인과 "좋아요" 도메인 및 데이터베이스 역시 분리가 되어야 함을 알 수 있겠다.
다만 여기서 좋아요와 좋아요 수를 산출하는 도메인을 어떻게 관리하는지까지 정하는 것도 여러 고려사항이 존재하였다.
3-1. 좋아요 테이블에 파생컬럼(비정규화)를 두는 방안
TOBE #1 : 좋아요 테이블에 좋아요 수 컬럼을 넣는다.
이 경우, 일전에 생성한 "좋아요 테이블"에 like_count를 단순하게 넣으면 되는데
- 게시글의 총 좋아요 count(*)를 산출하는 것은 기본적으로 모든 row에 대한 full scan이 필요하므로 소모가 큰 작업이다.
- 좋아요 및 좋아요 수의 테이블이나 로직 복잡도가 그리 크지 않고, 좋아요 수를 처리하는 쓰기작업 역시 "사용자가 이 행위를 수행하기까지의 과정을 고려할때 트래픽이 그렇게 크다고는 할 수 없다".
- 게시글 당 사용자는 한개의 좋아요만 누를 수 있고 이에 따라 사용자 별 중복 처리가 발생하지 않아 테이블 비정규화(좋아요 수 파생컬럼을 활용한) 작업이 비합리적이라 볼 수 없다.
3-2. 테이블 비정규화 시 최우선적으로 고려해야할 사항
여기서, 이전의 나라면 "단순한 컬럼 추가"로 보았겠지만, 지금은 설계적으로 "정규화된 테이블 구조에서 충분히 산출 가능한 데이터임에도, 굳이 비용소모를 감수하면서 파생컬럼 등의 추가 작업을 진행하는 것" 이라는 관점이 보이게 되었다.
여기서, 테이블 비정규화에 대한 개념을 공부하면서 깨달은 점 중 하나,
테이블 비정규화 시 고려해야할 최우선적 사항은 동시성 이슈, 데이터 중복 처리로 인한 일관성 문제이다.
예를 들어, 좋아요 테이블에 게시글의 "전체 좋아요 개수"까지 관리한다고 하면, 동일한 article_Id에 대한 record에 카운팅 처리가 동시적으로 발생하여 데이터의 일관성을 보장할 수 없다. 즉, 좋아요 테이블에 "좋아요 수"에 그치지 않고 "전체 좋아요 수"까지 넣는다면 데이터 일관성을 보장하지 못하므로 잘못된 테이블 비정규화를 하고 있는 것이다.
그리고 지금 보았을때, 현재의 테이블 구조도 동시성 문제를 직면한다.
한 게시글에 대한 좋아요 개수를 관리하는데, 이게 여러 row로 나뉘다보니 사용자의 좋아요 개수까지는 괜찮겠지만 여러 사용자의 좋아요 처리를 책임지기에는.. 이것 또한 비합리적인 테이블 비정규화로 보이게 되었다.
3-3. 다양한 동시성 문제로 인해 발생하는 비정상적 상황들
기본적인 동시성 문제는 격리수준에 따라 다른데, MySQL의 경우 보통 공유락 혹은 락이 없으므로(즉 다른 트랜잭션이 진행할때도 조회 허용) 지금과 같은 데이터 소실이 발생한다.
중요한 점은, 보통의 DBMS는 조회에 대한 락을 걸지 않으므로 처리에 대한 격리수준이 어떻든지 동시성 문제는 무조건 발생할 수 밖에 없다(트랜잭션을 하기 전에 최초 조회를 하여 컨텍스트를 얻으므로).
-
READ UNCOMMITTED
→ (분리된 트랜잭션에서 동시성 상황이 아님에도) 아직 commit 안 된 데이터도 읽을 수 있음 (“Dirty Read”).
→ T2가 T1의 commit 전 상태를 조회할 수 있음. -
READ COMMITTED (기본값: Oracle, PostgreSQL)
→ "트랜잭션 발생 시점에서의" commit 완료된 데이터만 읽는다(commit 전이라면 "단독" 처리 불가).
→ T1이 좋아요 수를 갱신했어도 commit 전이라면 T2는 그 값을 못 보고, 이전 값(0)을 읽음(동시성 이슈는 계속 발생) -
REPEATABLE READ (MySQL InnoDB 기본)
→ 같은 트랜잭션 안에서 반복 조회 시 항상 같은 값만 보장.
→ T2가 트랜잭션 시작할 때 스냅샷을 잡고, 그 이후의 commit된 변경도 못 봄. -
SERIALIZABLE
→ 트랜잭션이 직렬적으로 실행되는 것처럼 동작.
→ 사실상 SELECT 시점에도 락을 강하게 걸어서 동시성 크게 제한(조회까지 lock을 걸어 동시성 이슈를 방지할 수 있는 유일한 DBMS 수준의 격리수준).
이처럼 찬찬히 살펴보니 동시성 문제에 대해 깊게 알 수 있게 되었는데, 너무나도 중요한 개념이기에 한번 더 짚고 넘어가도록 한다.
지금의 상황에 맞게 동시성 문제의 다양한 경우를 비유하자면,
- Update anomaly (갱신 이상): 하나를 고치면 다른 복사본을 갱신하지 않아서, 혹은 못해서, 혹은 갱신시점에서 처리할 데이터를 불러오지 못하였을 경우 최종 데이터의 일관성 불일치.
- Insertion anomaly (삽입 이상): 카운터를 초기화/계산하는 로직이 복잡해져 삽입 시 오류 가능성.
- Deletion anomaly (삭제 이상): 하나를 삭제했을 때 카운터를 감소시키는 로직이 누락되면 불일치.
- Race condition / Lost update: 동시성에서 잘못된 값이 남음(위 동시성 예시).
- 복잡도 증가: 애플리케이션/트리거/업데이트 로직이 중복된 모든 복사본을 관리해야 하므로, 혹은 스파게티 코드가 발생하여 하이젠 버그 혹은 이에 수반하는 버그 가능성 증가.
참고로 DBMS는 기본적으로 X-Lock(Exclusive Lock)을 통해 다른 트랜잭션이 하나의 자원을 점유하고 있을때, 다른 트랜잭션의 접근을 차단한다.
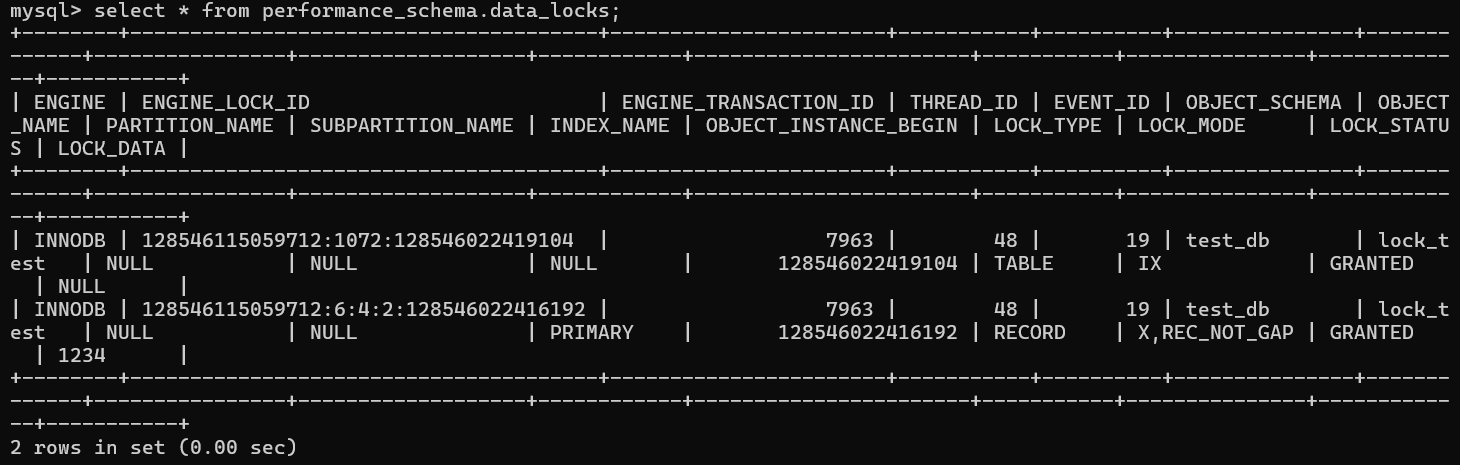
이처럼 engine_transaction_id가 다를때 다른 트랜잭션의 점유를 막기 위해 MySQL은 X-LOCK(베타락)을 두는데, 이 락을 해제할때까지 다른 트랜잭션의 동작은 무한정 대기상태에 빠지므로 성능적으로도 엄청난 소모일 수 밖에 없다.
3-4. 동시성 문제까지 고려하였을때, 좋아요와 좋아요 수까지 별도로 관리하는 것이 좋겠다.
다시 말하자면, 이것이 핵심이다.
동시성 문제를 살펴보았을때, 좋아요 생성과 좋아요는 별도의 테이블에 관리하는 것이 맞고, 특히 지금과 같은 분산 데이터베이스 환경에서 굳이 트랜잭션을 분리하기보다는 물리적으로 하나의 데이터베이스에 생성하여 트랜잭션의 성능 하락을 방지한다.
(*데이터 모델링과 아키텍칭은 다른 관점에서 보아야하는 이유!)
TOBE #2 : 좋아요와 좋아요 수는 동일 도메인에서 관리하되, 데이터 모델링 측면에서는 다르게 관리한다.
이때 추가적으로,
- 좋아요와 좋아요 수는 동일 도메인(동일 데이터베이스)에서 관리하되, 다른 테이블로 생성한다.
- 좋아요 테이블은 적절한 데이터 분산 저장을 위해 shard key를 지정하여 관리하는데, 분산 트랜잭션으로 굳이 구현하지 않고 단일 데이터베이스의 단일 트랜잭션으로 관리하기위해 좋아요 수 역시 article_id를 shard key로 지정한다.
4. 결론
단순하게 컬럼을 추가하지 말자.
좀 더 설계적으로 고민해보고,
- 컬럼을 추가하게 된다면 비정규화 혹은 파생컬럼이 아닌가?
- 정규화된 테이블에서 추출할 수 있지 않는가? 불가능하다면 어디서 하자점이 발생하는가?
- 데이터 모델링과(DB 혹은 schema / table 등) 기능적 아키텍칭을 잘 분리해서 이해하고 있는가?
- 비정규화를 하였을때 발생할 수 있는 동시성 이슈나 중복 처리를 충분히 고려하였는가?
좋은 품질은 사소한 고민 하나에서 시작한다. 사소한 고민을 쓸데없는 과정으로 치부하지 말고, 알게된 만큼 충분히 고려하고 생각하도록 하는 것이 좋겠다.
