1. 개요
개인 프로젝트를 진행하면서 "조회수"라는 비교적 간단한 기능을 구현할때 기능적/환경적 요인을 고려할때 꽤 흥미있는 장치를 결합할 수 있지 않을까라는 생각을 하게 되었다.
일전의 게시글 및 게시글 좋아요 수와 달리, 조회수는 데이터의 실시간 처리가 즉각적으로 이루어지지 않아도 품질에 유의미한 영향이 없고(미비하며) 그러면서도 트래픽은 그보다 많은(조회 행위를 함과 동시에 조회수를 처리해야 함) 요구사항을 도출할 수 있었다.
조회수를 정말 단순하게 생각하면 article table에 view_count 등의 조회수 컬럼을 신규 생성하여 관리할 수 있겠지만, 이러한 기능적/환경적 요인을 고려하고 이에 수반하는 책임분리까지 생각하였을때 도메인을 분리하고(데이터 모델링) 기능도 별도 관리하는 것이 좋겠다는 결론을 지었다.
조회수 트래픽을, 실시간은 아니지만 안정적으로 처리하고, 나아가 고가용성과 확장성, 안정성 등을 고려하여 어떤 도구를 활용할 수 있고 어떻게 구현할 것인지 설계한 과정을 기록한다(설계하면서 공부하고 새로 알게된 내용들이 매우 중요하므로 반드시 기억할 것!).
2. ASIS - 조회수 기능 기존 설계과정 및 의문점
기존 설계과정 : 파생데이터가 아니므로 정상적으로 정규화 데이터를 추출할 수 있다.
조회수 기능을 처음 설계할때는 단순하게 article table에 조회수 컬럼을 생성하고, 특정 게시글을 조회할때마다 조회수 count + 1를 하면 되지 않을까 생각하였다.
좋아요 수와 달리 별도 연산이나 추출이 필요없는 항목이기에, 파생데이터로 보기엔 충분히 정규화되어 있는 요소라 판단하였다.
하지만 너무 단순하게 접근하기엔 기능적/설계적 하자가 눈에 보였다.
하지만 일전의 동시성 문제를 겪고 이에 대한 해결방안을 고민하면서, 지금의 기능 역시 동시성 문제로 인해 데이터 유실이 많을 것이라는 생각이 들었다.
더불어 이미 article 도메인에는 충분히 많은 책임과 기능들이 존재하는데, 조회수 기능을 넣음으로인해 유지관리 측면에서 불리하지 않을까라는 생각이 들었다.
또한 동일하게 동시성 문제를 다루기엔 트래픽이 너무 과다할 것으로 보였기에(사용자의 직접적인 의도로 인한 게시글 작성이 아닌, 조회만으로 트래픽 생성), 다만 이 트래픽을 모두 동시에 처리할 필요는 없기에, 이를 구현할 수 있는 방안을 좀 더 고민해보게 되었다.
3. TOBE - 조회수 기능 개선 설계과정
그래서 얻은 결론은 Redis를 사용하고 "조회수" 기능의 데이터 모델링과 기능 도메인을 신규 영역으로 생성하는 것이다.
조회수 기능의 특징적인 두가지를 뽑자면,
- 사용자가 조회만으로 조회수 카운트 발생하여 트래픽이 매우 많을 것으로 예상
- 다만 게시글만큼의 실시간 반영이나 중요도가 떨어지기에 실시간 데이터 반영보다는 안정적인 데이터 반영이 더 중요함
이 두가지를 일전과 같이 단순 RDBMS로 처리하여 일관성를 유지하고 안정적인 부분을 확보하고자 한다면,
- RDBMS의 트랜잭션을 이용하여 디스크 저장을 하는 만큼 기능적/비용적/관리적 비용이 커진다.
- 트래픽이 많을 것으로 예상하는데 락처리 및 디스크 접근 비용으로 인해 처리시간이 너무 많이 필요(소요)할 것으로 예상한다.
따라서 빠른 처리와 실시간 데이터보다는 안정적인 데이터 처리에 중점을 두어,
빠른 처리 - In Memory Database (Redis)
안정적인 데이터 처리 - Redis/MySQL 간의 적절한 데이터 백업 정책 마련
의 상기 두가지 전략을 조회수 기능 설계에 반영해보기로 결정하였다.
3-1. 더 깊게 살펴보고 확실히 이해하는 Redis #1 - 기본적인 Redis 특징
Redis, 그렇게 많이 봐오고 사용하였지만 이 기회에 실무적으로 더 확실히 이해하기 위해 이번 설계를 통해 배운 점들을 모두 정리해보겠다.
In Memory Database
디스크가 아닌 메모리를 사용하는 "데이터베이스"이기에 "훨씬 빠른 속도로" 데이터를 "저장할 수 있고", 그만큼 처리 성능을 개선할 수 있다.
NoSQL
정해진 스키마없이 자료구조를 유연하게 활용하여 데이터모델을 정하고 활용할 수 있다(String, List, Set, Sorted Set, Hash). 주로 key/value를 활용하여 데이터를 저장한다.
TTL(Time To Live)
기본적으로 Memory를 점유하고, 점유한 Memory에 데이터를 일시적으로 저장하는 용도로 활용하는 도구이기에 일정 시간이 지나면 자동적으로 데이터가 소멸(휘발)한다.
별도의 TTL 정책을 통해 데이터 유지시간을 조절하거나, 이를 활용하여 캐싱에 사용하기도 한다.
Backup (RDB SnapShot & AOF)
데이터의 영구 저장을 위한 방안도 제시한다. 다만 MySQL과 같은 RDBMS에 비해 영구적으로 운용하기엔 한계점이 많아 RDBMS로 데이터 복제(Backup) 정책을 적절히 마련하여 활용한다.
RDB 스냅샷을 통해 저장한 데이터를 주기적으로 파일에 저장하거나, AOF(Append Only File)을 통해 수행한 명령어를 로그파일에 기록하여 향후 데이터 복구 시 해당 로그를 재실행하는 방식으로 커맨드 라인을 파일에 저장하기도 한다.
3-2. ## 3-2. 더 깊게 살펴보고 확실히 이해하는 Redis #2 - RAM Memory 관점에서 바라보는 Redis (cf. RAM/ROM/disk)
Redis는 RAM Memory를 점유하여 이곳에 데이터를 저장하는 도구이다.
Redis는 디스크가 아니라 RAM Memory를 점유하고 이곳에 데이터를 저장하는 장치로, Memory를 활용하기에 데이터 처리 속도가 매우 빠르고, 다만 휘발적이다.
물리적 한계로 인해 데이터를 영구적으로 저장할때는 보통 RDB와 연결하여 백업정책을 많이 활용한다.
운영환경에서 Redis는 해당 장치를 운용하기 위한 서버의 RAM Memory를 점유한다는 것이다.
운영환경에서 Redis를 활용한다면, 온프레미스 환경이나 Cloud 환경 어떤 곳이든 해당 RAM Memory 일부를 Redis가 점유하여 사용한다는 의미이다.
예를 들어,
- Docker : Redis 이미지를 실행하여 만들어진 컨테이너 혹은 해당 컨테이너가 할당된 실제 RAM Memory를 점유하여 사용한다.
- AWS ElastiCache(Redis) : Cloud 환경의 RAM Memory를 점유하여 사용한다.
- 쿠버네티스 : Pod가 할당된 Node의 RAM Memory를 점유한다.
Redis를 설치하지 않는다는 것은,
- Cloud에서 관계형 서비스로 사용한다는 의미이다.
- AWS ElastiCache, Azure Cache for Redis, GCP Memory Store 등 해당 환경에서 RAM Memory를 데이터 저장소로 사용한다는 의미로 보면 된다.
ROM Memory = Read Only Memory
이참에 ROM Memory도 알아보았는데, 참고로 알아두도록 한다.
- Bios, 부트로더 등 영구적으로 저장하며 변경이 필요하지 않은 설정정보 등에 대해 전원이 꺼져도 데이터 유실이 일어나지 않은(비휘발성), RAM과 정반대 성격의 저장소이다.
- Disk와는 또 다른 개념이다!
Disk
디스크는 영구적인 저장장치로, ROM과 같이 완전한 내용불변성이 아닌 항목에 대해 안정적으로 영구히 저장하며 비휘발성을 제공해주는 장치이다.
- HDD/SSD 등
3-3. 더 깊게 살펴보고 확실히 이해하는 Redis #3 - 동시성 및 이벤트 발행
Single Thread
Pub/Sub
Redis는 우리가 사용하는 Application과 달리 Single Thread를 통한 순차적 작업을 하기에, 어떠한 요청이 동시에 들어와도 원자성/순차성을 보장하면서 처리한다.
이로 인해 동시성 문제 해결 시 유리하다.
더불어 Redis를 통한 처리 이후 메시지 발행 및 구독이 가능하여, Redis 기반 분산 환경에서도 실시간 통신이 가능하다.
3-4. 더 깊게 살펴보고 확실히 이해하는 Redis #4 - 고가용성/확장성
Redis는 데이터 백업이 가능하여 고가용성 환경 구성에 유리하고, 분산환경 지원 역시 가능하여 데이터 분산을 통한 확장성 확보에도 유리할 수 있다.
더 깊게 보자면, 여러개의 Redis 서버를 1개의 Cluster로 구성하여 분산환경을 설정함으로써 안정적이고 확장적인 데이터 구성에 좋은 방안이 될 수 있겠다.
또한 물리적 샤딩과 논리적 샤딩(slot)을 통해 데이터 분산(확장성)이 가능한데
- 논리적 샤딩과 물리적 샤딩을 활용하여 데이터 분산 저장을 할 수 있고,
- hash_function을 통해 논리적 샤딩을 구한 후, select_shard를 통해 데이터 분산을 하는 과정으로 안정적인 샤딩 및 분산 환경 구축이 가능하다.
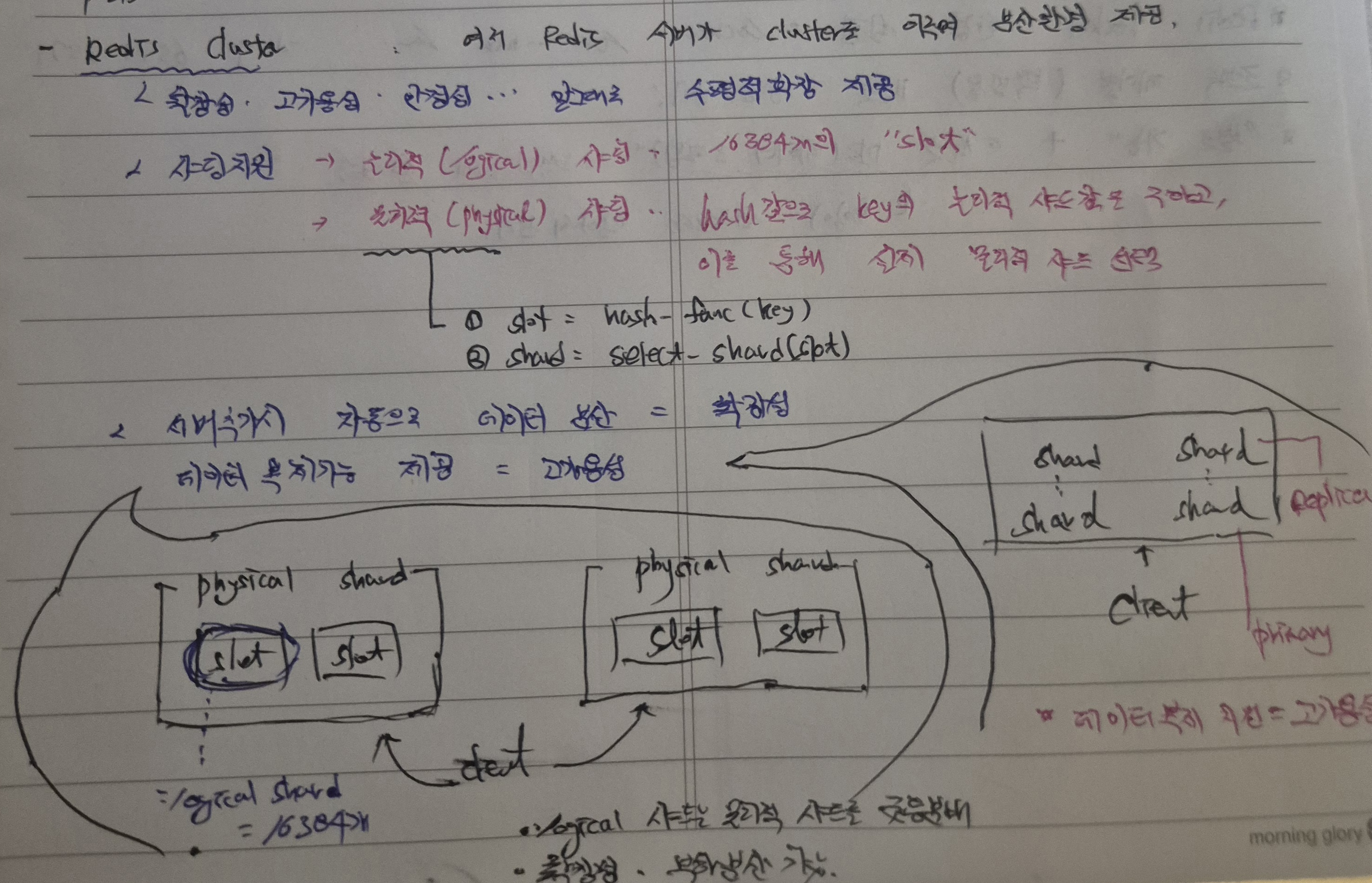
또한 물리적 샤드를 나눈 후에 Primary와 Replica를 나누어 데이터 복제(백업)를 할 수 있으나, 보통은 RDBMS와 함께 데이터 백업 정책을 수립하는 것으로 활용한다.
4. 최종 설계안
결론적으로, 현재의 기능적/환경적 제약조건을 보았을때 Redis를 활용하여 안정적으로, 많은 트래픽을 빠르게 처리하도록 설계안을 구상해보았다.
데이터 백업의 경우 시간단위(스케쥴링) 혹은 개수단위(N개 단위의 Redis) 등 여러 형태의 백업이 있을 수 있겠지만, 조회시점에 간단히 처리할 수 있기도 하고 N개의 데이터가 가득 찼을 시점에서의 백업은 인기글 집계에서도 활용할 수 있기에 개수단위의 백업을 시도할 예정이다.
