[백엔드] 인덱스가 조회성능향상에 무조건 도움이 되는가 - 조회성능향상을 위해 고려해야할 점들(단순 인덱스 활용부터 Covering Index 등의 전략까지)
백엔드
1. 개요
개인 프로젝트를 진행하면서 인덱스를 좀 더 깊게 살펴보는 기회가 생겨 공부해보았다.
- 단순히 정렬된 데이터를 저장하는 공간인가?
- 필요한 데이터를 추출하기 위한 데이터 저장공간에 이미 데이터가 정렬이 되어있기 때문에 조회 성능이 향상하는가?
- 인덱스를 사용하여 조회성능이 향상하는 "정확한 이유는" 무엇인가?
MySql에서 InnoDB가 쿼리를 동작하는 과정을 찬찬히, 자세하게 살펴보면서 인덱스가 왜 조회성능을 향상하는지, 향후 인덱스를 활용할때 어떠한 전략을 세우면 될 지 생각해보기 위해 공부한 내용을 남긴다.
2-1. ASIS #1-1 - index를 사용하지 않은 단순한 조회 쿼리
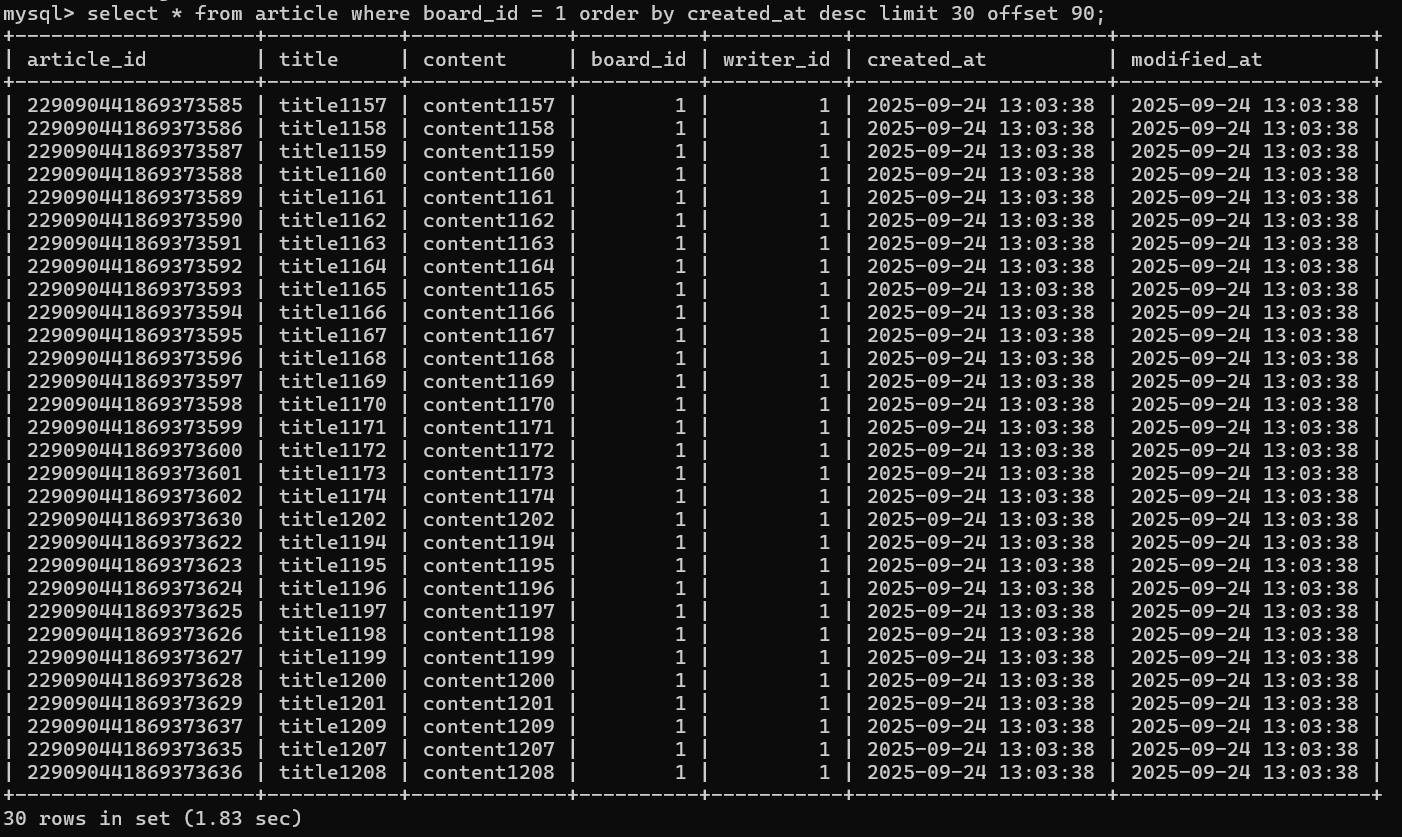
기본적으로 인덱스를 사용하지 않고 단순히 데이터를 추출하는 SELECT 쿼리를 사용할 경우 아래와 같이 1.83sec의 시간이 소요된다.
2-2. ASIS #1-2 - MySQL의 Query Plan
30건의 데이터를 조회하는 것 치고는 상당히 성능이 안좋다는 것을 확인할 수 있다.
어디서 성능적 하자가 발생하는지 Query Plan을 자세히 살펴보도록 한다.

이처럼 type - all(모든 데이터를 full-scan)하고, 최종 정렬을 위해 디스크 상에서 정렬 작업을 진행하는 file-sort가 발생하여 불필요한 성능 하락이 많이 발생하였음을 알 수 있다.
3-1. TOBE #1-1 - 인덱스 생성
위와 같이 성능하락을 유발하는 지점들을 하나씩 제거하여 조회성능을 개선하여 보자.
그 중 첫번째 단계로는 당연히 인덱스 생성이겠다.

위와 같이 PK와 함께, 조회 조건인 board_id도 같이 Secondary Index의 컬럼 인덱스를 구성하도록 해주었다.
3-2. TOBE #1-2 - 조회성능향상(추출 조건에 부합하는 인덱스 존재 시)
기본적으로 인덱스는 단순히 "데이터 생성 순서"가 아닌, "가장 많이 활용하는 쿼리" 혹은 "빈번하게 발생하는 쿼리"를 참고하여 구성하는 것이 좋겠다.
MySQL 기준으로, InnoDB가 쿼리를 보고 추출할 데이터 조건 그대로 Secondary Index에서 해당 데이터를 탐색하기 때문이다.
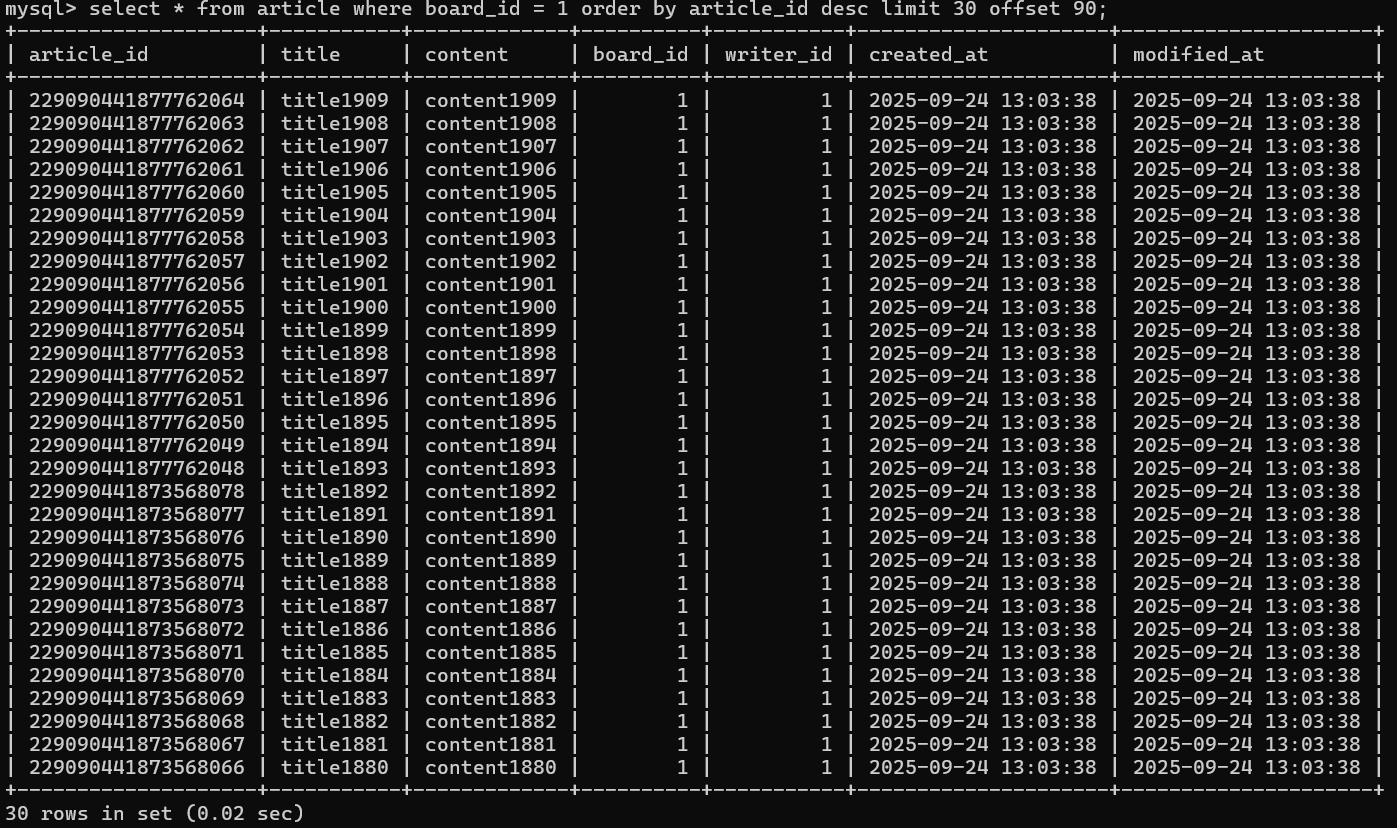
쿼리의 조건과 인덱스의 조건이 그대로 부합하여, 이미 정렬된 데이터를 탐색하였기에 불필요한 정렬과정의 제거, 원하는 데이터를 인덱스에서 바로 찾을 수 있으므로 동선적 이점이 발생하여 조회성능에 유의미한 향상이 발생할 수 있었다.
3-3. TOBE #1-3 - 인덱스를 활용한 MySQL의 Query Plan(Key)
실제 Query Plan을 보면 조회성능향상의 이유를 확실하게 알 수 있다.

일전 비효율적인 쿼리의 Query Plan type이 all이 아닌 index를 확실하게 타는 것을 확인할 수 있고, file sort 역시 발생하지 않아 디스크에서 발생하는 비효율적인 I/O 소모가 일어나지 않음을 볼 수 있다.
3-3. 전략에 맞는 인덱스의 중요성
참고로 order by를 created_at 컬럼 기준으로 바꾸면 어떻게 될까?
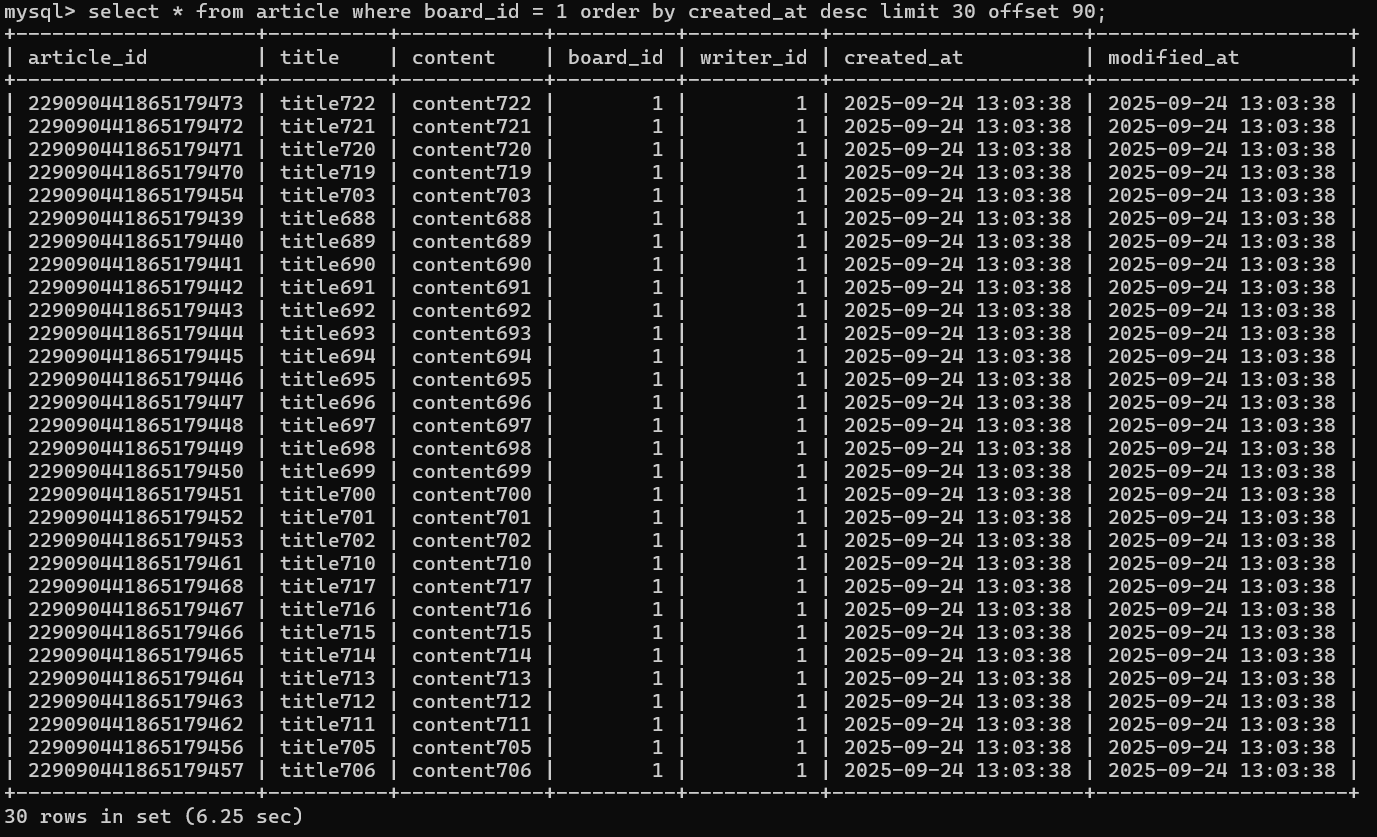
아래와 같이, index에서 정렬되어있는 데이터가 쿼리와 일치하지 않기 때문에 Query Plan이 원하는 데이터를 찾기 위해서는 어쩔 수 없이 full-scan을 다시 할 수 밖에 없다.
이에 따라 index를 활용하지 못하는 상황이 발생하여, 조회성능이 그대로 하락해버렸음을 알 수 있다.
따라서 자주 활용하는 Query가 무엇인가, 조건이 무엇인가 등을 확인하여 구성한 index를 최대한 활용할 수 있도록 성능이점을 최대화할 수 있는 전략이 필요하겠다.
4-1. ASIS #2-1 - 인덱스를 생성하였지만 offset이 방대해져 제 역할을 하지 못하는 상황
이번엔 다른 상황이 발생하였는데, 데이터 갯수가 너무 많아 offset이 지나치게 방대해져 index를 구성하고 이를 활용함에도 불구하고 조회성능이 안좋아지는 경우이다.
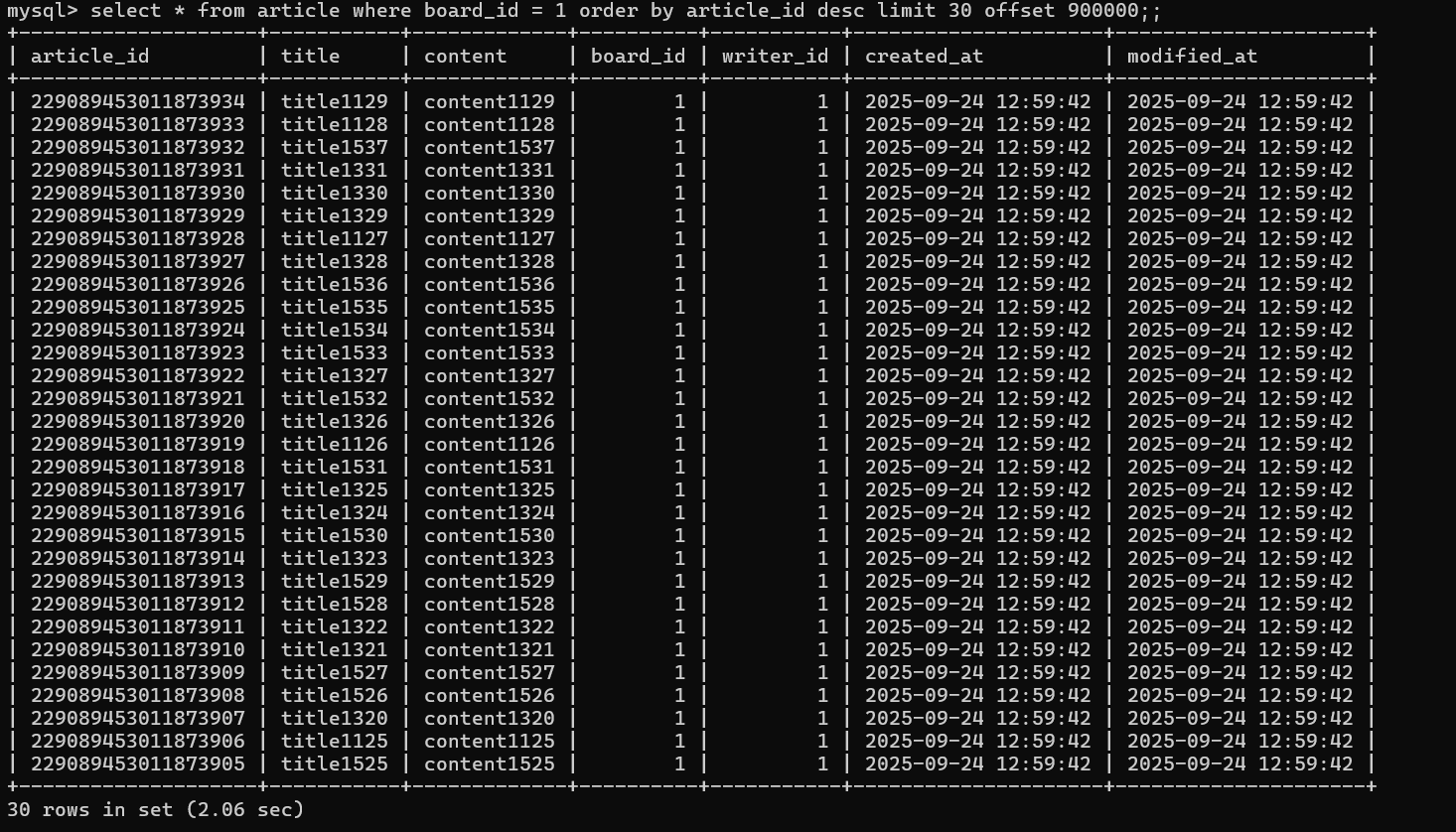
이처럼 offset을 크게 지정하였을 경우, 30개의 데이터를 추출하는데 2.06sec의 시간이 소모되어 일전의 비효율적인 쿼리 성능과 비슷해졌음을 알 수 있다.
4-2. ASIS #2-2 - Query Plan 역시 인덱스를 활용하고 있지만 조회 성능이 하락하여 의미가 없어진 상황
Query Plan을 보면 자세한 양상을 파악할 수 있다.

이처럼 Index를 확실하게 타고 있음에도 (key = idx_board_id_article_id), 조회 성능이 유의미하게 향상되지 않았음을 확인할 수 있다.
4-3. ASIS #2-2 - Clustered Index
데이터 개수가 많아짐에 따라 조회성능이 하락하는 이유를 알기위해선 인덱스 트리를 2번 타는 과정을 이해해야 하는데, 먼저 Clustered Index를 살펴보도록 하자.
우리가 생성한 index가 아닌 테이블에서 자동적으로 생성해주는 index이다.

위 그림처럼 Clustered Index는 "실제 데이터"가 담겨져 있는 index tree로, PK조건으로 조회할 경우 해당 Index를 사용하기 때문에 자연적인 조회 성능에서의 이점을 획득할 수 있으며 보조 인덱스에서 실제 데이터를 추출하기 위해 사용하는 "최종적인 목표 지점"이라 할 수 있겠다.
4-4. ASIS #2-3 - Secondary Index
우리가 생성한 index는 실제로는 "Secondary Index"로, 말 그대로 Clustered Index와 별개로 생성하여 조회성능향상에 도움을 주고자 "보조적"으로 사용하는 index이다.
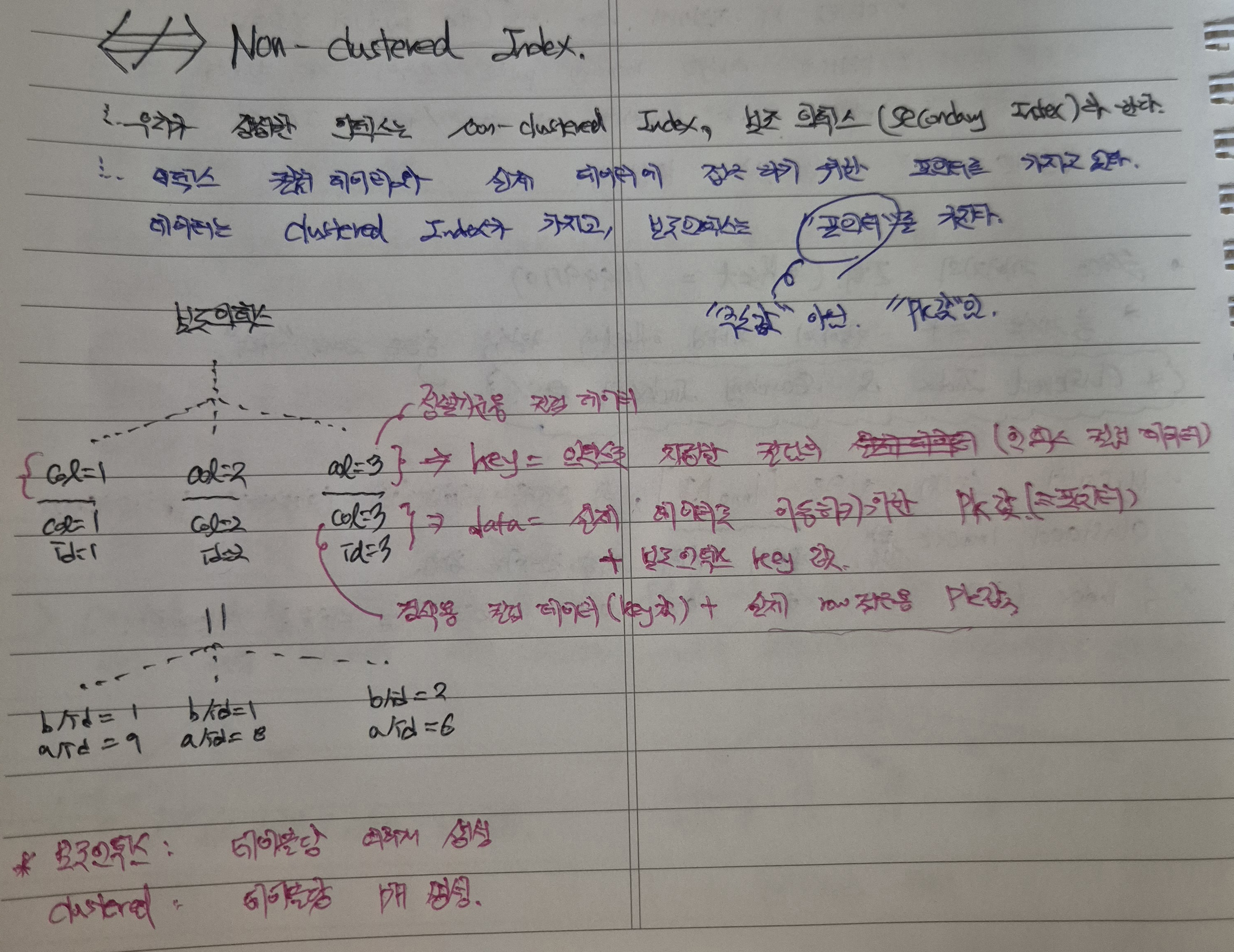
쉽게 말하면 보조 인덱스 설정으로 사용한 컬럼 데이터를 기준으로, 해당 컬럼 데이터와 그 컬럼의 PK값을 가지고 있는 인덱스 트리이다.
PK값은 실제 데이터를 찾아가기 위한 "포인터"로 사용하는 것이고, 포인터를 통해 실제 데이터를 추출하기 위해 Clustered Index로 이동하는 과정에서 인덱스 트리를 2번 타는 번거로움이 발생하게 되는 것이다.
더 자세한 예시를 들자면,
PRIMARY KEY (article_id)
CREATE INDEX idx_board_created_at ON article(board_id, created_at);이와 같이 "board id와 created_at" 컬럼을 기준으로 보조 인덱스를 만들었다고 가정하자.
board_id = 1, created_at='2025-09-24'에 해당하는 "보조 인덱스의 leaf node"에는 아래와 같은 값이 저장되어 있을 것이다.
(board_id=1, created_at='2025-09-24 12:00:00', PK=article_id=123)
즉,
- key = "정렬기준", 정렬을 위해 지정한 컬럼의 인덱스 컬럼 데이터
- data = "검색용 및 포인터", 해당 데이터 검색을 위해 사용하는 검색용 인덱스 컬럼 데이터와 실제 row(=record)로 이동하기 위한 PK값
이때 "포인터"란 보조인덱스에서, 데이터가 저장되어있는 Clustered Index로 이동하기 위해 편의상 명명한 단어로 실제로는 PK값이 저장되어 있음에 유의한다(주소값이 아님).
4-5. ASIS #2-4 - 데이터가 많아지면 실제 데이터를 찾기 위한 보조인덱스에서의 skip이 많아져 조회성능하락 발생
이러한 InnoDB가 계획한 Query Plan의 한계로 인해 데이터 수가 많아질 수록 데이터가 해당하는 Offset을 파악하기 위해 많은 시간을 소모하게 되는 것이다.
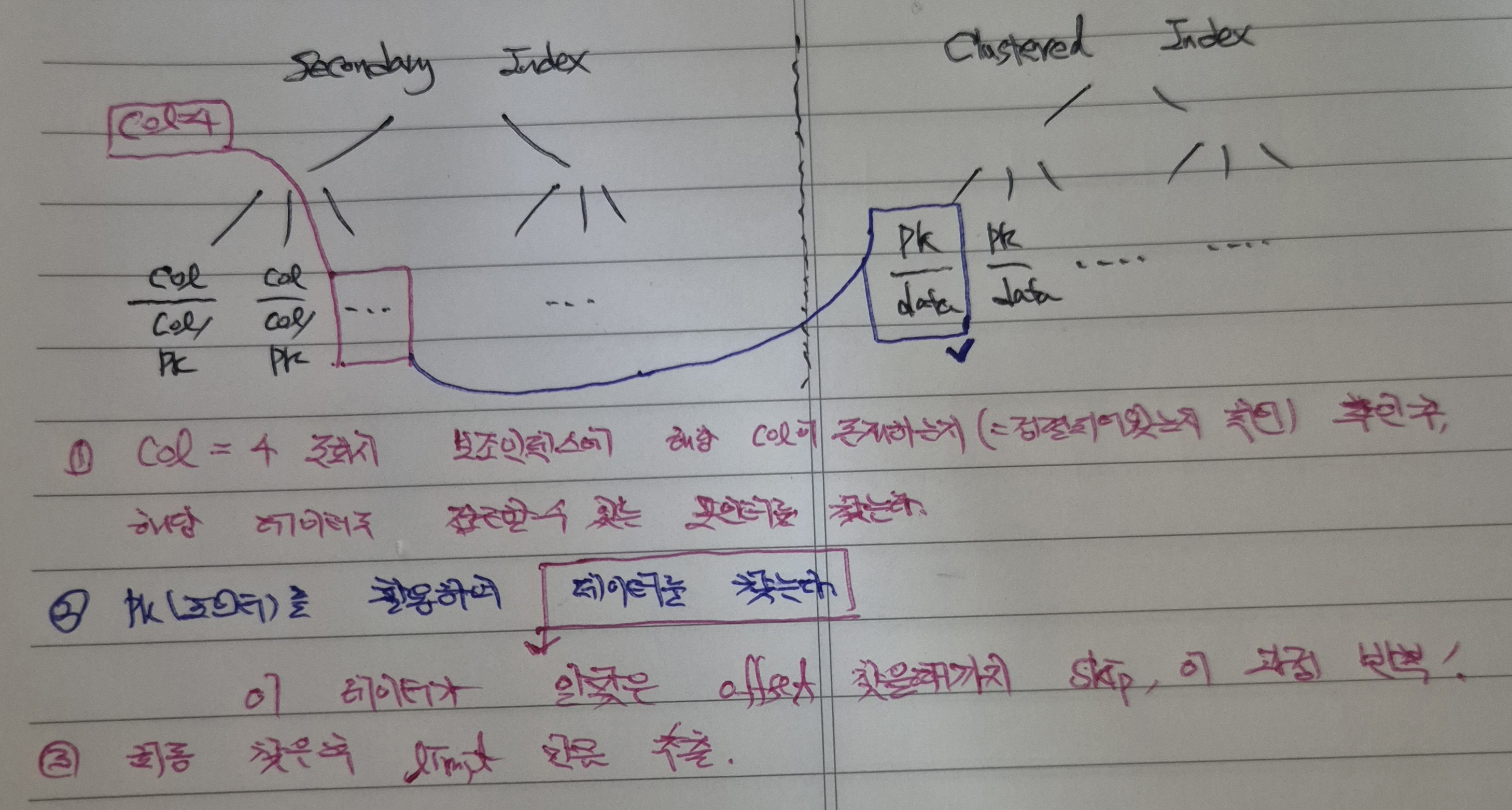
즉 위 과정처럼 Secondary -> Clustered를 통해 실제 데이터를 추출하게 되는데, 조건에 만족하지 못한 데이터라면 다시 Secondary에서 offset skip을 진행하고 다음 데이터를 찾게 된다.
최종 데이터를 추출할 때까지 skip의 과정이 발생하므로, 데이터가 많아지면 Secondary Index를 구성했다 하더라도 성능적인 한계가 발생할 수 밖에 없는 것이다.
5-1. TOBE #2-1 - Query Plan의 효율화를 위한 쿼리 튜닝(Covering Index)
Clustered Index에 가지 않고도 Secondary Index에서 추출할 수 있는 정보(colum index data / PK)를 활용해서 쿼리를 튜닝한다.
SELECT board_id, article_id -- PK를 보조 인덱스에서 바로 가져올 수 있음
FROM article
WHERE article_id = 1
ORDER BY article_id DESC
limit 30 offset 900000;이를 실행하면
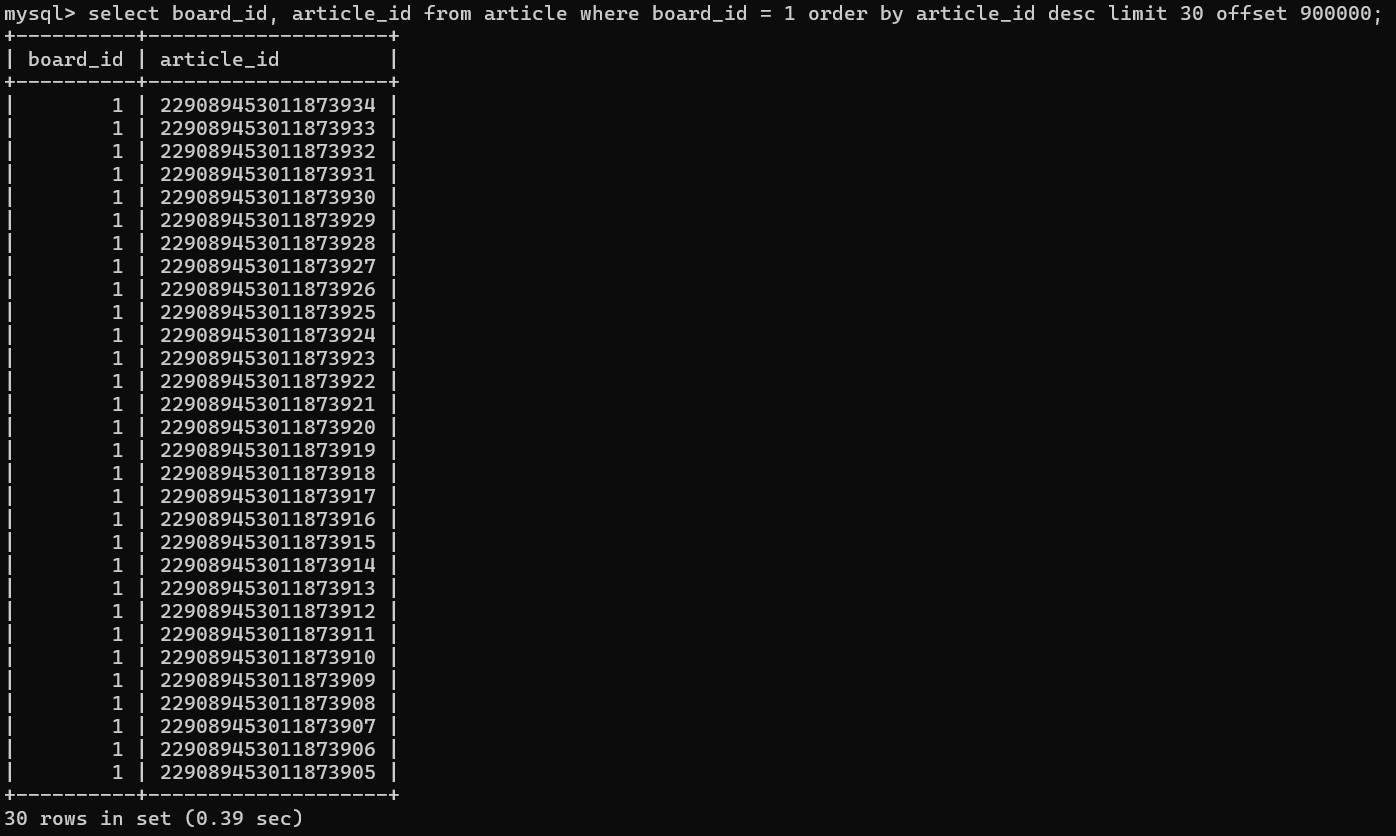
이와 같이, 조회성능이 하락한 이전의 쿼리와 동일한 offset이나 limit 등의 조회 조건을 사용하였음에도 불구하고, 추출 데이터를 바꾸어주었을때 0.39sec로 기존 6sec 대비 상당한 조회 성능 개선을 확인할 수 있다.

이처럼 Clustered Index에 도달하지 않고도, Secondary Index에서 바로 컬럼 데이터를 추출할 수 있는 경우를 Covering Index라 하며 위와 같이 "Using Index"라는 Query Plan을 확인할 수 있겠다.
인덱스를 2번 타거나, Skip 과정을 모두 거치지 않고 바로 Secondary Index에서 데이터를 가져올 수 있기 때문에 엄청난 성능적 이점을 가져올 수 있다.
5-1. TOBE #2-2 - Query Plan의 효율화를 위한 쿼리 튜닝(Secondary Index의 활용 및 추출 데이터 범위 한정 후 join)
이를 활용하여, 바로 추출가능한 30개의 article_id에 대해서만 Clustered Index에 접근하는 전략을 세워보도록 한다.
이는 아래와 같이 article_id 추출 후 이와 Clustered Index의 데이터를 join하는 방식으로, 단순 쿼리튜닝을 통해 성능향상을 기대할 수 있다.
SELECT *
FROM (
SELECT ARTICLE_ID
FROM ARTICLE
WHERE BOARD_ID = 1
ORDER BY ARTICLE_ID DESC
LIMIT 30 OFFSET 9000000
) s
LEFT JOIN ARTICLE a
ON s.ARTICLE_ID = a.ARTICLE_ID이 쿼리를 실행하면
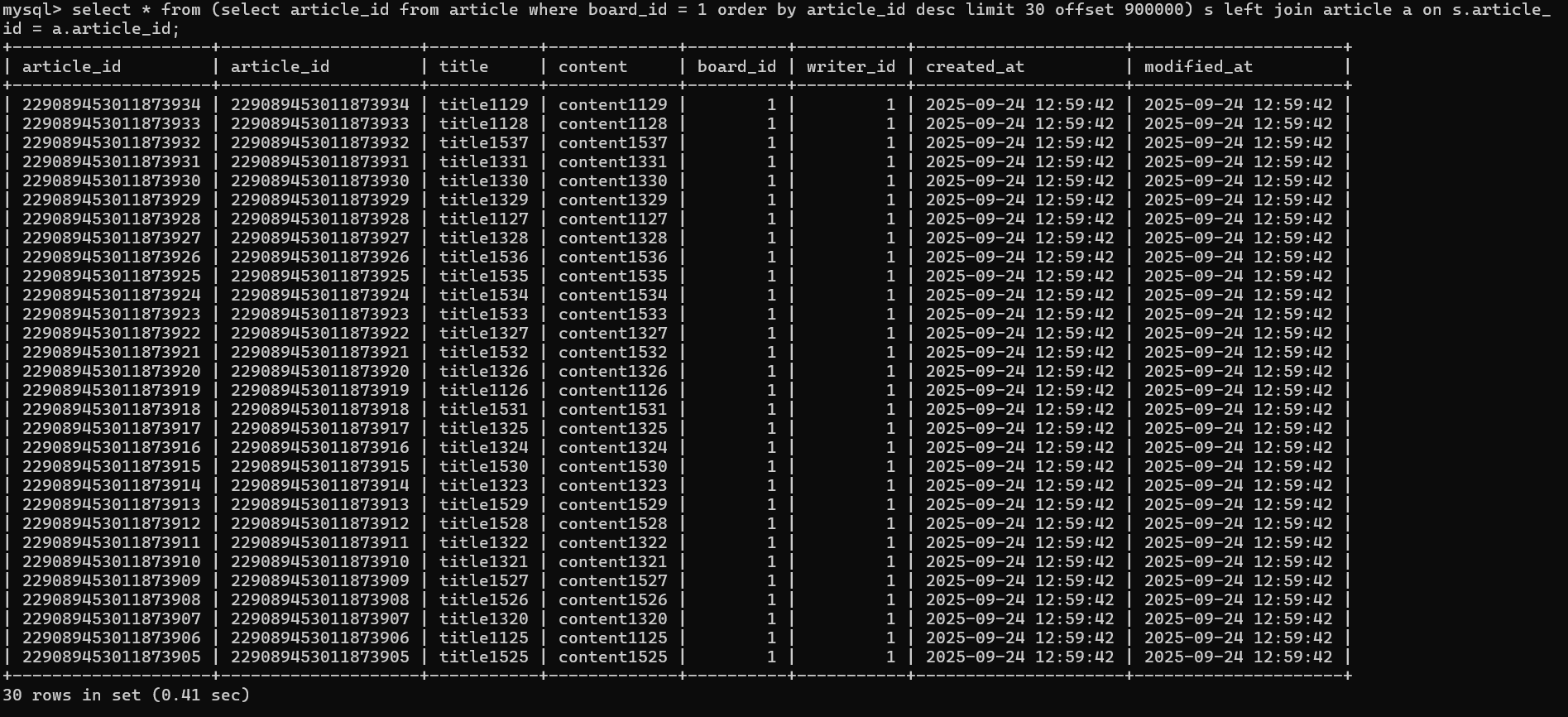
위와 같이 기존 2sec에서 0.41sec까지 유의미한 조회성능향상 결과를 확보할 수 있었다.
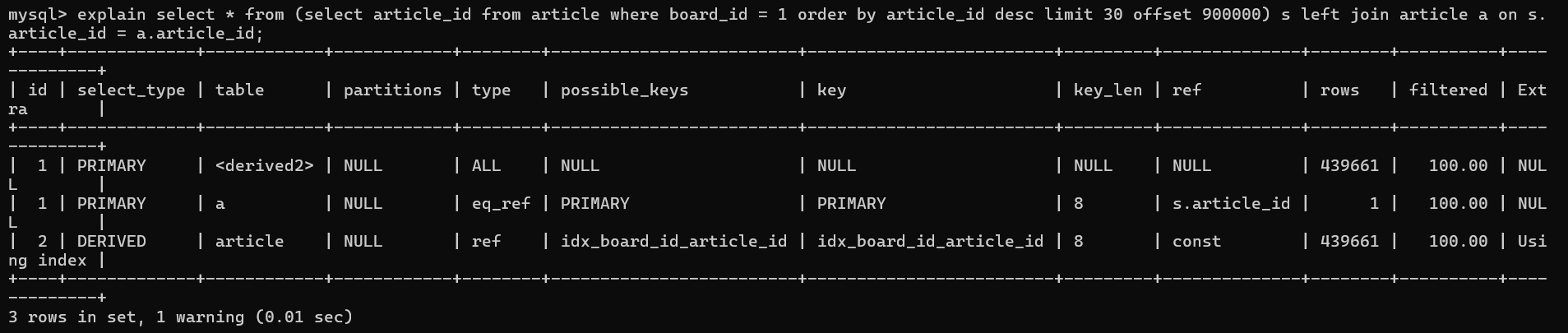
Query Plan을 보았을때, Derived(파생) 테이블이 생겼음에도 Clustered Index와 Skip과정을 제거하여, 유의미한 조회성능향상이 발생하였음을 알 수 있다.
6. 추가 개선방안
참고로 offset이 너무 커지면 Clustered Index를 거치지 않더라도, Index Scan 자체에서 해당 Offset으로 이동하기 위한 이동비용을 소모한다.
따라서 Offset 자체를 감소하기 위한 데이터 범위 분리(최근 1년) 및 테이블 자체를 1년마다 분리하는 등의 방안을 고려할 수 있겠다.
또는 관련한 정책을 마련하거나 Front level에서 최대 조회 범위를 처음부터 조정하는 등의 방안도 생각해볼 수 있겠다.
7. 인덱스 활용을 통한 MySQL 조회성능향상의 "본질적인 의미"
지금까지 살펴보았을때, 처음에 알고있던 Index 개념보다 훨씬 복잡하고 깊게 알고있어야 정상적으로 전략 수립이 가능하다는 것을 느낄 수 있었다.
최종적으로, 우리는 이를 통해 단순 Index를 구성하는 것에 그치지 않고, Index를 Query Plan이 잘 활용하기 위한 방안과 Secondary Index와 Clustered Index의 동선을 최적화하는 방안까지 모두 고려하여 적절한 전략을 마련하는 것이 중요한 것을 알 수 있다.
즉 Index를 활용함에도, 위에서 찬찬히 살펴보았던 조회성능하락 및 이를 개선하는 과정을 통해 매우 어렵고 복잡한 전략 수립이 필요하다는 것을 알 수 있다.
