1. 개요
일전의 인덱스를 통한 조회성능향상에 이어, "근본적으로 데이터가 너무 많아 조회성능을 향상하고 싶은 상황"에 대해 공부한 내용을 기록하고자 한다.
데이터가 많아진다면, 아무리 인덱스를 잘 구성하고 쿼리를 잘 사용하여 Covering index를 활용한다고 한들 물리적인 데이터 개수가 많기 때문에 속도가 느려질 수 밖에 없다.
이러한 근본적인 한계 상황에서 조회성능을 향상할 수 있는 방안, 페이징 처리를 왜 하는지를 중심으로 살펴보고자 한다.
2-1. ASIS #1-1 - 전체 게시글 조회에 소모하는 비용
데이터가 92만 4천건이 있을때 전체 게시글을 조회한다고 가정한다.
전체 게시글 수 조회를 통해 총 페이지 수를 추출하기 위한 count(*) 쿼리가 필요할 것이고, 이는 아래와 같은 결과를 얻게 된다.
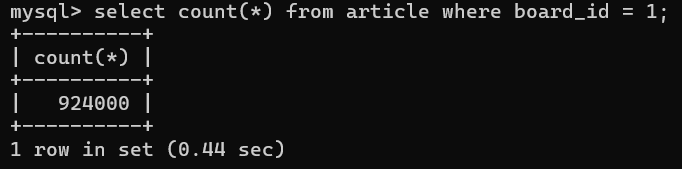
1200만건 기준 거의 1.44sec, 92만건 기준으로도 0.44sec가 소요되어 기대한 것 만큼 조회속도가 나오지 않는다는 것을 확인할 수 있다.
2-2. ASIS #1-2 - Covering index를 활용해도 근본적인 한계로 인한 성능하락 발생
Query Plan을 한번 살펴보자.

분명히 Covering index(=Using Index)를 사용하고 있음에도, 대용량 데이터라는 근본적인(물리적) 한계로 인해 조회속도가 예상보다 하회하고 있다는 것을 파악할 수 있겠다.
3-1. TOBE #2-1 - 페이징을 활용하여 조회 성능을 개선하는 전략에 대해
이때 우리는 application client 관점에서, 굳이 전체 데이터에 관심을 주지 않고도 사용자가 필요로 하는 데이터에 대해서만 추출하는 페이징을 활용하는 방안을 생각해볼 수 있겠다.
일전의 내용에서 Covering Index를 활용하기 위해, Secondary Index와 이에 따른 서브쿼리(join)을 통해 조회성능을 향상하였던 것처럼 데이터를 추출하는 근본적인 조건을 완화하여 성능향상을 기대해볼 수 있는 것이다.
간단히 말하면, 필요한 페이지 수와 이에 따른 페이지 버튼을 활성화한다는 의미이다(현재 페이지가 3페이지라면 1 ~ 10페이지 데이터만 활성화).
3-2. TOBE #2-2 - 특정 페이지에 들어갔을때 해당 페이지에 관련된 데이터들만 조회해온다.
예를 들어 10페이지가 활성된 상태에서 한 페이지에 30개의 데이터를 조회한다고 하였을때,
- 사용자가 1페이지에 위치하였다면 페이징 작업을 위해 301개 데이터가 필요하다.
- 사용자가 11페이지에 위치하였다면 페이징 작업을 위해 601개 데이터가 필요하다.
이를 위해 두가지 작업이 필요한데,
- 특정 페이징 환경조건에 필요한 데이터 개수를 구한다.
= ((N-1)/K + 1) * M x K + 1
(이때 N=현재 페이지, M = 페이지당 글 개수, K = 활성화한 페이지 개수)
- 필요한 데이터 개수만큼만 조회해온다.
위에서 도출한 페이지 개수만큼 limit를 걸어 총 데이터 개수를 구한다.
(아래 300301 값이 위에서 도출한 limit 값)
SELECT COUNT(*)
FROM (
SELECT ARTICLE_ID
FROM ARTICLE
WHERE BOARD_ID = 1
LIMIT 300301
) s
;이 전체 데이터 개수에 대한 쿼리를 실행하면 아래와 같다.

이렇게 하면 기존에 비해 조회성능이 향상하였음을 확인할 수 있다(참고로 12만건 데이터에 대해 유의미한 데이터 조회 성능 향상이 나타났음을 볼 수 있음).
4. 결론
일전과 마찬가지로 Covering Index를 활용하고 있어도 물리적인 한계, 근본적인 문제로 인해 성능이 하락할 수 밖에 없는 상황에 직면하였다.
이전의 JOIN, 지금의 limit과 같이 사용자 입장에서 필요로 하는 데이터만 추출할 수 있도록 상황의 조건을 변경하여 해결할 수 있음을 확인하기도 하였다.
그리고 이러한 전략의 출발점은 결국 "페이징 쿼리"로, 페이징 쿼리를 적절하게 수립하기 위한 전략이 중요하다는 것을 알 수 있었다.
결국 Index에 대해 잘 이해하고 있어도 중요한 것은 개발자의 전략 혹은 제한조건 및 이에 대한 방안을 마련하는 것이겠다. 상황에 맞는 적절한 전략 채택/혼용/취사선택 등을 통해 성능개선을 기대하는 것이 좋겠다.
