LangChain 공식문서 Documet_loders 참고
LangChain Document Loaders
1. Document Loaders란 무엇인가요?
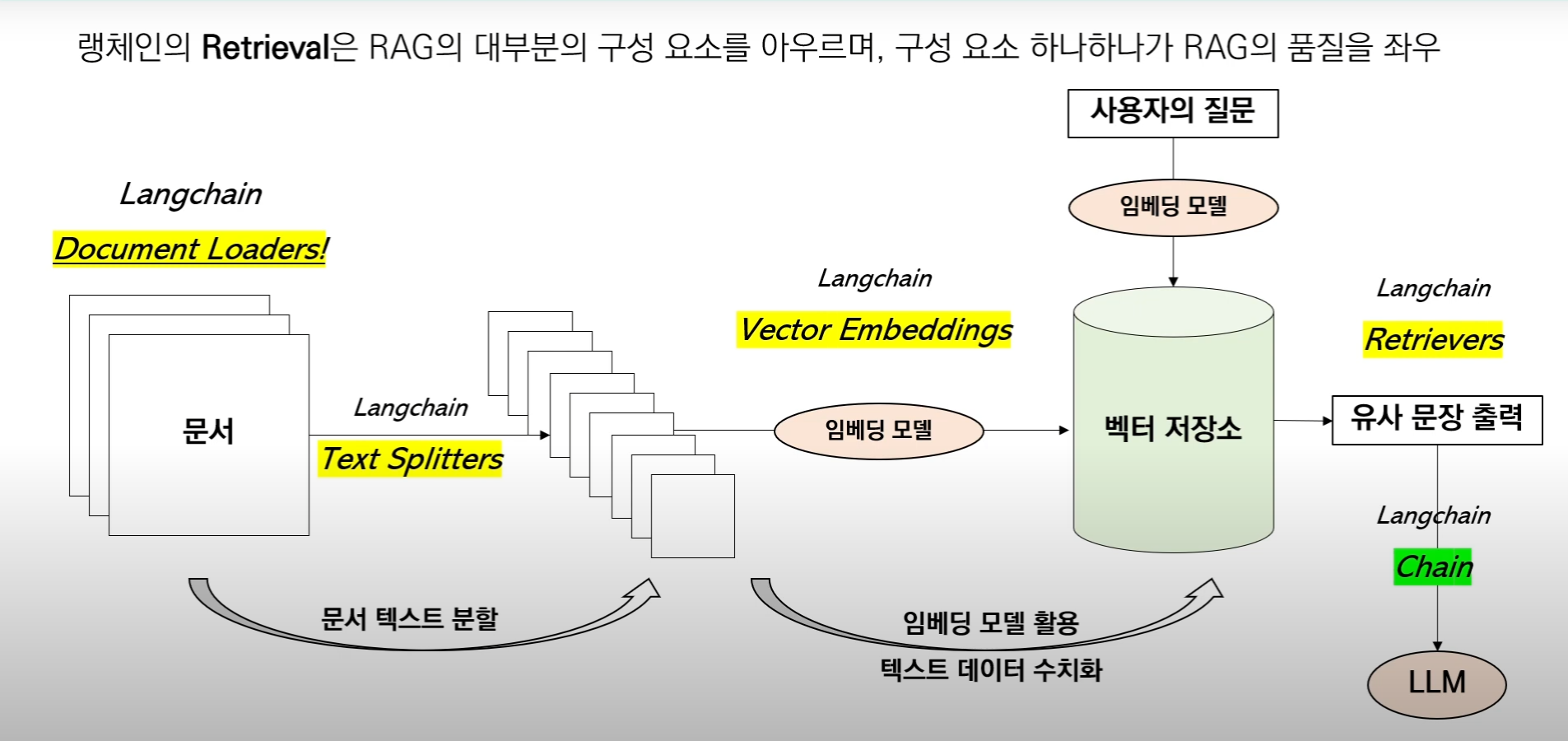
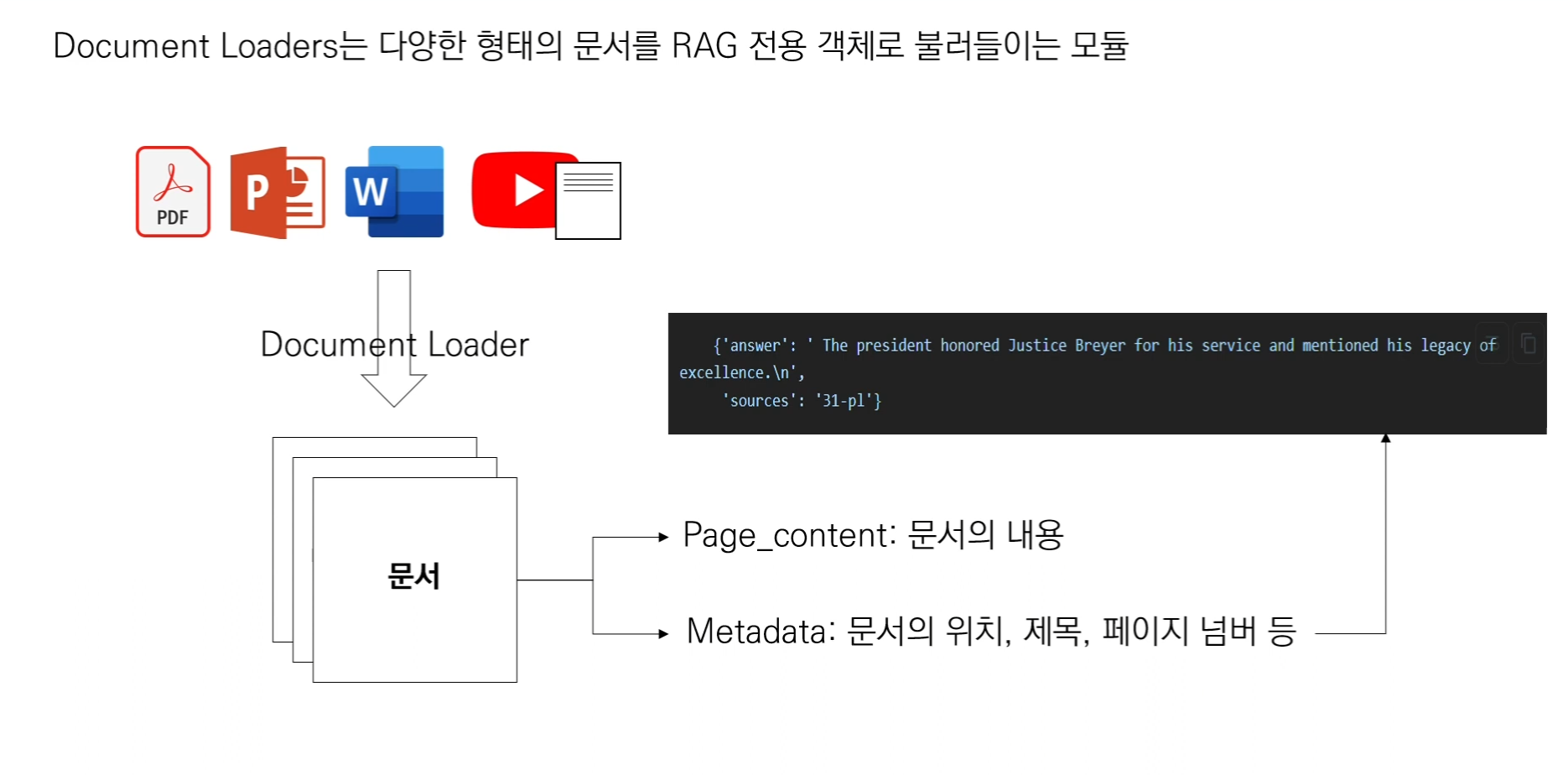
LangChain의 Document Loaders는 텍스트 데이터를 다양한 소스(파일, 웹, 데이터베이스 등)에서 로드하여 Document 객체로 변환하는 역할을 합니다. 이 객체는 언어 모델이 처리할 수 있는 형식으로 텍스트와 메타데이터를 포함하고 있습니다.
2. 사용 가능한 Document Loaders 종류
LangChain은 다양한 형식의 데이터 소스를 지원하기 위해 여러 가지 Document Loader를 제공합니다. 주요한 Loader들은 다음과 같습니다:
파일 기반 Loader
CSVLoader: CSV 파일 로드UnstructuredPDFLoader: PDF 파일 로드TextLoader: 일반 텍스트 파일 로드JSONLoader: JSON 파일 로드PythonLoader: Python 파일 로드MarkdownLoader: Markdown 파일 로드
웹 기반 Loader
WebBaseLoader: 웹 페이지 로드SeleniumURLLoader: JavaScript로 동적으로 생성된 웹 페이지 로드BSHTMLLoader: HTML 파일 로드 (BeautifulSoup 사용)
클라우드 및 데이터베이스 Loader
AirbyteLoader: Airbyte 커넥터를 통한 데이터 로드NotionDBLoader: Notion 데이터베이스 로드S3Loader: AWS S3에서 파일 로드
기타 Loader
EmailLoader: 이메일 로드DataFrameLoader: Pandas DataFrame 로드
3. CSV 파일 로드: CSVLoader
사용 방법
CSV 파일을 로드하려면 CSVLoader 클래스를 사용합니다. 이 Loader는 CSV 파일의 각 행을 하나의 Document로 변환합니다.
필요한 라이브러리
pandas 라이브러리가 필요합니다. 설치되어 있지 않다면 다음과 같이 설치합니다:
pip install pandas예제 코드
from langchain.document_loaders import CSVLoader
# CSV 파일 경로 설정
file_path = 'data.csv'
# CSVLoader 초기화
loader = CSVLoader(file_path=file_path)
# 문서 로드
documents = loader.load()
# 결과 확인
for doc in documents:
print(doc.page_content)
print(doc.metadata)주의사항
- CSV 파일의 크기가 큰 경우 로드 시간이 오래 걸릴 수 있습니다.
- 파일 인코딩을 지정해야 할 경우
encoding매개변수를 사용할 수 있습니다.
4. PDF 파일 로드: UnstructuredPDFLoader
사용 방법
PDF 파일을 로드하려면 UnstructuredPDFLoader 클래스를 사용합니다. 이 Loader는 PDF 파일의 텍스트를 추출하여 Document로 변환합니다.
필요한 라이브러리
unstructured 및 관련 패키지가 필요합니다. 다음과 같이 설치합니다:
pip install unstructured
pip install pdfminer.six # PDF 지원을 위해 필요예제 코드
from langchain.document_loaders import UnstructuredPDFLoader
# PDF 파일 경로 설정
file_path = 'document.pdf'
# UnstructuredPDFLoader 초기화
loader = UnstructuredPDFLoader(file_path)
# 문서 로드
documents = loader.load()
# 결과 확인
for doc in documents:
print(doc.page_content)
print(doc.metadata)주의사항
- PDF 파일의 구조에 따라 텍스트 추출 결과가 달라질 수 있습니다.
pdfminer.six이외에도PyPDF2등을 사용할 수 있지만,UnstructuredPDFLoader는unstructured패키지를 기본으로 합니다.
5. URL을 이용한 로드: WebBaseLoader
사용 방법
웹 페이지의 내용을 로드하려면 WebBaseLoader 클래스를 사용합니다. 이 Loader는 지정한 URL의 HTML 콘텐츠를 가져와서 텍스트를 추출합니다.
필요한 라이브러리
requestsbeautifulsoup4
다음과 같이 설치합니다:
pip install requests
pip install beautifulsoup4예제 코드
from langchain.document_loaders import WebBaseLoader
# 대상 URL 설정
url = 'https://example.com'
# WebBaseLoader 초기화
loader = WebBaseLoader(url)
# 문서 로드
documents = loader.load()
# 결과 확인
for doc in documents:
print(doc.page_content)
print(doc.metadata)주의사항
- JavaScript로 생성되는 콘텐츠는 로드되지 않을 수 있습니다.
- 이러한 경우
SeleniumURLLoader를 사용할 수 있습니다. - 웹 페이지의 혀용 여부(robots.txt)를 준수해야 합니다.
- 대상 사이트의 이용 약관을 확인하여 크롤링이 허용되는지 확인 후 사용해야 합니다.
참고
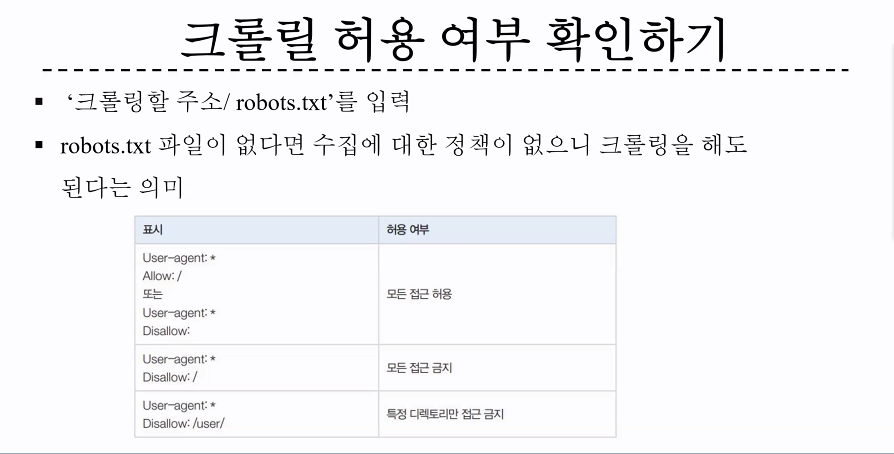
다음에는 URL 데이터 로드(크롤링)에 대해서 자세히 알아보겠다....

안녕하세요.