
(팀과제) 도전과제 1번
준비
- Kaggle링크에 있는 파일 다운로드 해서 데이터 불러오기
import pandas as pd
import numpy as np
df = pd.read_csv("netflix_reviews.csv") # 파일 불러오기
df- 데이터 확인
print(df.shape)
print(df.columns)(117134, 8)
Index(['reviewId', 'userName', 'content', 'score', 'thumbsUpCount',
'reviewCreatedVersion', 'at', 'appVersion'],
dtype='object')df['score'].dtypedtype('int64')- 데이터 고르기
df = df.iloc[:,0:5]
df.head()
데이터 전처리
# 전처리 함수
import re
def preprocess_text(text):
if isinstance(text, float):
return ""
text = text.lower() # 대문자를 소문자로
text = re.sub(r'[^\w\s]', '', text) # 구두점 제거
text = re.sub(r'\d+', '', text) # 숫자 제거
text = text.strip() # 띄어쓰기 제외하고 빈 칸 제거
return text여기서 뭘 더 전처리 할 수 있을지 고민했다. (고민만 했다...)
df['reviewId'] = df['reviewId'].apply(preprocess_text)
df['userName'] = df['userName'].apply(preprocess_text)
df['content'] = df['content'].apply(preprocess_text)
print(df)apply함수를 통해 column들 전처리 진행
데이터 시각화 하기
import seaborn as sns # 그래프를 그리기 위한 seaborn 라이브러리 임포트 (없으면 설치 바랍니다)
import matplotlib.pyplot as plt # 그래프 표시를 위한 pyplot 임포트
score_counts = df['score'].value_counts().reset_index() # score 컬럼의 값에 대한 빈도수를 계산한 후 시각화
score_counts.columns = ['score','score_count']
# score_counts
sns.barplot(x='score', y='score_count', data=score_counts, palette='Set1', hue = 'score', legend=False)
# # sns.countplot(x=df['score']) : countplot 이용한 방법 , 간단하게 표현가능
plt.xlabel('Score')
plt.ylabel('Count')
plt.title('Distribution of Scores')
plt.show()seaborn 라이브러리를 설치하고 시각화했다.
palette='Set1' ... 'Set2', 'Blue' 등등으로 색을 지정 할 수 있다.
CUDA 및 버전 확인
여기서 문제가 발생했다.
torchtext라이브러리를 설치하는데, 환경충돌 문제가 발생했다. 그 전 포스팅 참고.
문제 해결하려고 애를쓰다 쓰다 튜터님 찾아가서 함께 애를쓰고 결국 초기화 엔딩.
(처음부터 설정을 완벽하게 할 수 없으니, 필연적으로 한번은 겪을 상황이었다. 빨리 겪었음에 감사했다.)
다시 돌아와서,
import torch
print(torch.__version__)
print(torch.version.cuda)
print(torch.cuda.is_available()) 2.4.1
12.4
True
이렇게 버전을 시작하기 전에 확인해줬다.
LSTM 실전 과제
LSTM을 이용해서 모델 학습을 진행중이다. 큰 데이터를 학습하는데 시간이 얼마나 걸릴지 모르고 바짝 쫄아있다. BATCH_SIZE도 64에서 16으로 돌리고 진행중인데, 끝날 기미가 보이질 않는다. 뭔가 잘못된거 같은 예감이 솔솔든다. 이런 감은 언제나 잘 맞는다.
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
from torch.utils.data import DataLoader, Dataset
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import numpy as np어쨋든 정리는 필요하니 계속하자면, 필요한 라이브러리를 불러왔다.!
정의 1
reviews = df['content'].tolist() # 'content'를 리스트로 변환
ratings = df['score'].tolist() # 'score'를 리스트로 변환
# 데이터셋 클래스 정의
class ReviewDataset(Dataset):
def __init__(self, reviews, ratings, text_pipeline, label_pipeline):
self.reviews = reviews
self.ratings = ratings
self.text_pipeline = text_pipeline
self.label_pipeline = label_pipeline
def __len__(self): # 데이터의 총 길이 반환 , 모델이 몇 개의 샘플을 다룰지 알려준다.
return len(self.reviews)
def __getitem__(self, idx):
review = self.text_pipeline(self.reviews[idx]) # 텍스트 파이프라인을 통해 리뷰를 인덱스로 변환
rating = self.label_pipeline(self.ratings[idx]) # 평점을 변환 (여기선 변환 없음)
return torch.tensor(review), torch.tensor(rating) # torch 텐서로 변환하여 반환reviews를 활용할 데이터인 df['content'] 로 지정하고 리스트로 변환하는 tolist()를 사용했다. 그래야 파이토치에서 활용되는 라이브러리에 사용된다.!
데이터셋 클래스에서,
text_pipeline은 텍스트를 (지금은 reviews) 변환하는 함수고 단어들을 숫자 인덱스로 반환한다.
label_pipeline은 라벨 (지금은 rating변환) 변환 함수다.
정의 2
# 기본 영어 토크나이저 정의
tokenizer = get_tokenizer('basic_english')
"""
기본적으로 영어 텍스트를 토큰 단위(단어 단위)로 분리하는 역할을 하는 토크나이저입니다.
예를 들어, 'This is a test.'라는 문장을 ['this', 'is', 'a', 'test']로 변환합니다.
"""
# 어휘 사전을 생성하기 위한 토큰 생성 함수 정의
def yield_tokens(data_iter):
"""
데이터셋 내 텍스트 리뷰를 하나씩 가져와 토큰(단어)으로 분리한 후 이를 반환하는 제너레이터 함수입니다.
vocab을 만들기 위해 사용됩니다.
data_iter: 텍스트 리뷰가 포함된 데이터셋(리스트 형식)
"""
for text in data_iter:
yield tokenizer(text) # 각 리뷰 텍스트를 토크나이저로 분리하여 반환
# 어휘 사전(vocab) 생성
vocab = build_vocab_from_iterator(yield_tokens(reviews))
"""
위에서 정의한 토크나이저 함수를 통해 각 리뷰의 단어를 토큰화한 후, 이를 기반으로 어휘 사전을 생성합니다.
vocab 객체는 각 단어에 고유한 숫자 인덱스를 할당합니다.
"""
# 텍스트 파이프라인 정의 (어휘 사전에 있는 단어만 처리)
def text_pipeline(text):
"""
입력된 텍스트를 토크나이저로 분리한 후, 각 단어를 어휘 사전의 인덱스로 변환합니다.
어휘 사전에 있는 단어만 변환되고, 없는 단어는 무시됩니다.
text: 입력 텍스트 (리뷰)
반환값: 단어 인덱스 리스트
"""
return [vocab[token] for token in tokenizer(text) if token in vocab]
# 이미 score가 숫자형이므로 label_pipeline은 변환 작업을 생략
def label_pipeline(label):
"""
평점 데이터는 이미 숫자형이므로 별도의 변환 작업이 필요 없습니다.
그대로 반환합니다.
label: 평점 데이터
반환값: 그대로 반환된 평점 값
"""
return label
# 데이터를 학습용(train)과 테스트용(test)으로 분리 (train: 80%, test: 20%)
train_reviews, test_reviews, train_ratings, test_ratings = train_test_split(reviews, ratings, test_size=0.2, random_state=42)
"""
train_test_split 함수를 사용하여 리뷰와 평점 데이터를 학습용(80%)과 테스트용(20%)으로 나눕니다.
random_state=42는 데이터를 무작위로 나눌 때 동일한 결과가 나오도록 설정하는 시드 값입니다.
"""
# 학습용 데이터셋 생성
train_dataset = ReviewDataset(train_reviews, train_ratings, text_pipeline, label_pipeline)
# 테스트용 데이터셋 생성
test_dataset = ReviewDataset(test_reviews, test_ratings, text_pipeline, label_pipeline)
"""
ReviewDataset 클래스를 이용해 학습용(train)과 테스트용(test) 데이터셋을 생성합니다.
train_reviews, train_ratings는 학습용 데이터, test_reviews, test_ratings는 테스트용 데이터입니다.
"""
# DataLoader 정의
BATCH_SIZE = 16 # 배치 크기 설정 (한 번에 16개의 샘플을 모델에 전달)
train_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
"""
DataLoader는 Dataset에서 데이터를 미니배치 단위로 가져오는 역할을 합니다.
배치 크기를 BATCH_SIZE로 설정하고, 학습용 데이터는 무작위로 섞이도록 설정(shuffle=True)했습니다.
테스트용 데이터는 섞지 않고 순차적으로 불러옵니다(shuffle=False).
"""LSMT 모델 정의
# LSTM 모델 정의
class LSTMModel(nn.Module):
"""
리뷰 데이터를 바탕으로 점수를 예측하는 LSTM(Long Short-Term Memory) 모델을 정의합니다.
텍스트 데이터를 처리하기 위해 임베딩, LSTM, 그리고 완전연결층을 사용합니다.
"""
def __init__(self, vocab_size, embed_dim, hidden_dim, output_dim):
"""
모델의 초기화 함수로, 모델의 각 층을 정의합니다.
vocab_size: 어휘 사전 크기 (단어 개수)
embed_dim: 임베딩 차원 (단어를 임베딩할 때 사용할 벡터의 크기)
hidden_dim: LSTM의 숨겨진 상태(hidden state)의 차원
output_dim: 출력 차원 (예측할 점수의 개수)
"""
super(LSTMModel, self).__init__()
# EmbeddingBag을 사용하여 입력 텍스트를 임베딩 벡터로 변환 (vocab_size 크기의 단어를 embed_dim 차원으로 변환)
self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=True)
# LSTM 레이어: 임베딩된 텍스트 데이터를 LSTM을 통해 순차적으로 처리
self.lstm = nn.LSTM(embed_dim, hidden_dim, batch_first=True)
# Fully Connected Layer: LSTM의 숨겨진 상태를 사용하여 점수 예측
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, text):
"""
모델이 입력을 받았을 때의 순전파(forward pass)를 정의합니다.
입력 텍스트 데이터를 임베딩하고, LSTM을 거쳐 최종 출력값을 계산합니다.
text: 입력 텍스트 데이터 (리뷰)
반환값: 점수 예측값
"""
# 텍스트 데이터를 임베딩 벡터로 변환
embedded = self.embedding(text)
# LSTM에 임베딩된 텍스트 데이터를 전달
output, (hidden, cell) = self.lstm(embedded.unsqueeze(0)) # unsqueeze(0)은 배치 차원을 추가하기 위함
# LSTM의 마지막 숨겨진 상태를 완전연결층에 통과시켜 점수 예측값 반환
return self.fc(hidden[-1])LSTM 모델 학습 (진행중...) 이상하다.
# 하이퍼파라미터 정의
VOCAB_SIZE = len(vocab) # 어휘 사전 크기 (단어 개수)
EMBED_DIM = 64 # 임베딩 차원: 단어를 64차원 벡터로 변환
HIDDEN_DIM = 128 # LSTM의 숨겨진 상태 크기
OUTPUT_DIM = len(set(ratings)) # 출력 차원: 예측할 점수(레이블)의 개수
# 모델 초기화
model = LSTMModel(VOCAB_SIZE, EMBED_DIM, HIDDEN_DIM, OUTPUT_DIM)
"""
LSTM 모델을 위에서 정의한 하이퍼파라미터로 초기화합니다.
VOCAB_SIZE: 어휘 사전의 단어 수
EMBED_DIM: 임베딩 차원 크기
HIDDEN_DIM: LSTM 숨겨진 상태 차원 크기
OUTPUT_DIM: 예측할 점수(레이블) 개수
"""
# 손실 함수와 옵티마이저 정의
criterion = nn.CrossEntropyLoss() # 손실 함수로 교차 엔트로피 손실을 사용 (다중 클래스 분류 문제에 적합)
optimizer = optim.SGD(model.parameters(), lr=0.01) # 옵티마이저로 확률적 경사 하강법(SGD) 사용, 학습률은 0.01
# 모델을 CUDA로 이동 (가능한 경우)
device = torch.device("cuda") # GPU가 사용 가능하면 CUDA 장치로 설정
model.to(device) # 모델을 GPU로 이동
# 모델 학습 함수 정의
def train_model(model, train_dataloader, criterion, optimizer, num_epochs=5):
"""
모델을 학습하는 함수입니다.
model: 학습할 LSTM 모델
train_dataloader: 학습 데이터를 제공하는 DataLoader
criterion: 손실 함수 (여기서는 CrossEntropyLoss)
optimizer: 옵티마이저 (여기서는 SGD)
num_epochs: 학습할 에포크 수 (기본값은 5)
"""
model.train() # 모델을 학습 모드로 설정 (Dropout이나 BatchNorm 같은 레이어가 학습 모드로 작동하도록 함)
for epoch in range(num_epochs):
total_loss = 0 # 각 에포크마다 누적 손실을 추적하기 위한 변수
for i, (reviews, ratings) in enumerate(train_dataloader):
# 리뷰와 평점 데이터를 GPU로 이동
reviews, ratings = reviews.to(device), ratings.to(device)
optimizer.zero_grad() # 이전 배치에서 계산된 기울기(gradient)를 초기화
outputs = model(reviews) # 모델에 입력 데이터를 전달하여 예측값을 계산
loss = criterion(outputs, ratings) # 예측값과 실제 레이블을 비교하여 손실 계산
loss.backward() # 손실에 대한 기울기를 계산 (역전파)
optimizer.step() # 옵티마이저를 통해 가중치를 업데이트
total_loss += loss.item() # 배치 손실을 누적
# 10번째 배치마다 현재 에포크와 배치 손실을 출력
if (i + 1) % 10 == 0:
print(f'Epoch {epoch+1}/{num_epochs}, Batch {i+1}/{len(train_dataloader)}, Loss: {loss.item():.4f}')
# 에포크마다 평균 손실 출력
print(f'Epoch [{epoch+1}/{num_epochs}], Average Loss: {total_loss/len(train_dataloader):.4f}')
print("Finished Training") # 학습 완료 메시지 출력
# 모델 학습 실행
train_model(model, train_dataloader, criterion, optimizer, num_epochs=10)
"""
train_model 함수를 호출하여 모델 학습을 시작합니다.
num_epochs=10으로 설정하여 10 에포크 동안 모델을 학습합니다.
"""
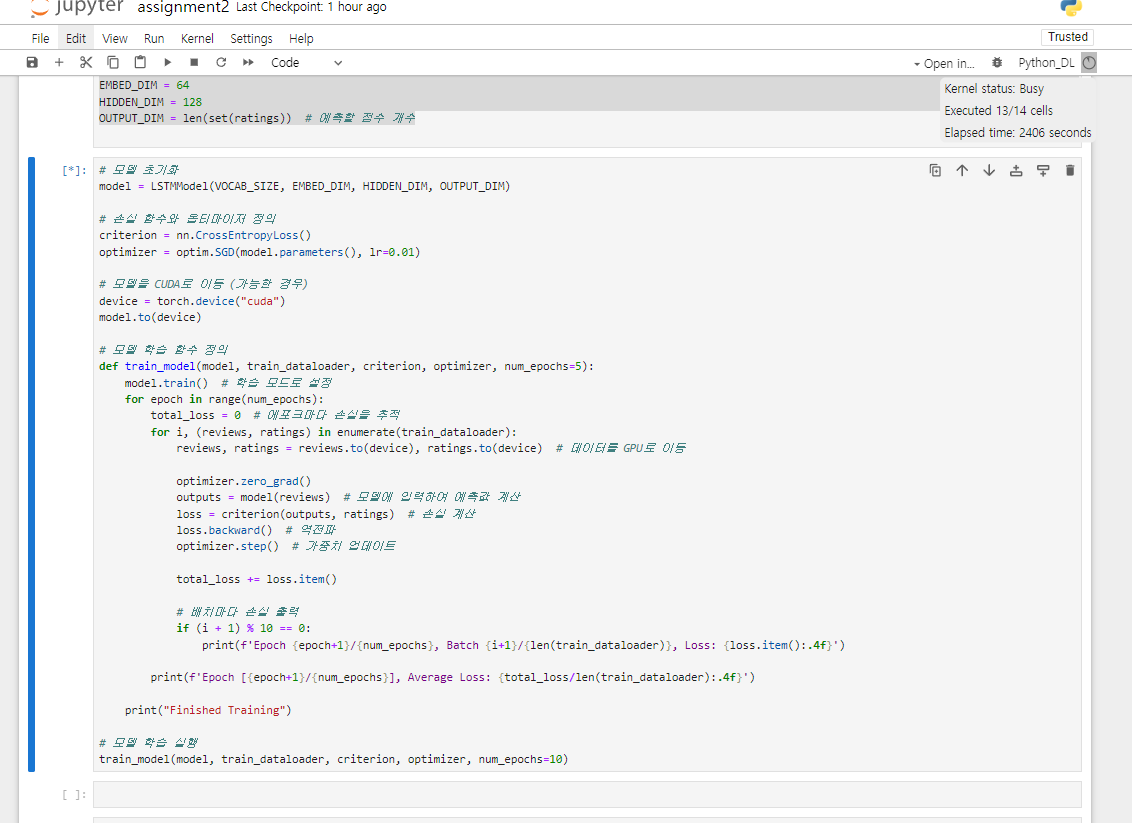
우측 상단에 2400초 지났는데 아무런 반응이 없다.
embed_dim, hidden_dim을 각각 16, 32로 줄이고 실행中
아직도 반응이 없다.
코드 수정
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
from torch.utils.data import DataLoader, Dataset
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from torch.nn.utils.rnn import pad_sequence
import numpy as np
reviews = df['content'].tolist() # 'content'를 리스트로 변환
ratings = df['score'].tolist() # 'score'를 리스트로 변환
# 라벨을 정수형으로 변환 (필수적인 과정)
label_encoder = LabelEncoder()
ratings = label_encoder.fit_transform(ratings) # 평점 정수형으로 변환
# 데이터셋 클래스 정의
class ReviewDataset(Dataset):
def __init__(self, reviews, ratings, text_pipeline, label_pipeline):
self.reviews = reviews
self.ratings = ratings
self.text_pipeline = text_pipeline
self.label_pipeline = label_pipeline
def __len__(self):
return len(self.reviews)
def __getitem__(self, idx):
review = self.text_pipeline(self.reviews[idx])
rating = self.label_pipeline(self.ratings[idx])
return torch.tensor(review), torch.tensor(rating)
# 토크나이저 정의 (기본 영어 토크나이저)
tokenizer = get_tokenizer('basic_english')
# 어휘 사전 생성 함수
def yield_tokens(data_iter):
for text in data_iter:
yield tokenizer(text)
# 어휘 사전 생성
vocab = build_vocab_from_iterator(yield_tokens(reviews))
# 텍스트 파이프라인 정의 (어휘 사전에 있는 단어만 처리)
def text_pipeline(text):
return [vocab[token] for token in tokenizer(text)]
# 평점 그대로 사용
def label_pipeline(label):
return label # 이미 숫자형이므로 변환 생략
# 데이터를 학습용(train)과 테스트용(test)으로 분리
train_reviews, test_reviews, train_ratings, test_ratings = train_test_split(reviews, ratings, test_size=0.2, random_state=42)
# 데이터셋 정의
train_dataset = ReviewDataset(train_reviews, train_ratings, text_pipeline, label_pipeline)
test_dataset = ReviewDataset(test_reviews, test_ratings, text_pipeline, label_pipeline)
# 패딩을 적용하는 함수 정의
def collate_fn(batch):
reviews, ratings = zip(*batch)
reviews = pad_sequence([torch.tensor(r, dtype=torch.long) for r in reviews], batch_first=True) # 정수형 텐서로 변환
ratings = torch.tensor(ratings, dtype=torch.long) # 평점도 정수형으로 변환
return reviews, ratings
# 데이터 로더 정의
BATCH_SIZE = 16
train_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_fn)
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, collate_fn=collate_fn)
# LSTM 모델 정의
class LSTMModel(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, output_dim):
super(LSTMModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim) # Embedding으로 변경
self.lstm = nn.LSTM(embed_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, text):
embedded = self.embedding(text)
output, (hidden, cell) = self.lstm(embedded)
return self.fc(hidden[-1])
# 하이퍼파라미터 정의
VOCAB_SIZE = len(vocab)
EMBED_DIM = 64
HIDDEN_DIM = 128
OUTPUT_DIM = len(set(ratings)) # 예측할 점수 개수 (평점이 정수형)
# 모델 초기화
model = LSTMModel(VOCAB_SIZE, EMBED_DIM, HIDDEN_DIM, OUTPUT_DIM)
# 손실 함수와 옵티마이저 정의
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
# 모델을 CUDA로 이동 (가능한 경우)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 모델 학습 함수 정의
def train_model(model, train_dataloader, criterion, optimizer, num_epochs=10):
model.train() # 학습 모드로 설정
for epoch in range(num_epochs):
total_loss = 0 # 에포크마다 손실을 추적
for i, (reviews, ratings) in enumerate(train_dataloader):
reviews, ratings = reviews.to(device), ratings.to(device) # 데이터를 GPU로 이동
optimizer.zero_grad()
outputs = model(reviews) # 모델에 입력하여 예측값 계산
loss = criterion(outputs, ratings) # 손실 계산
loss.backward() # 역전파
optimizer.step() # 가중치 업데이트
total_loss += loss.item()
# 배치마다 손실 출력
if (i + 1) % 10 == 0:
print(f'Epoch {epoch+1}/{num_epochs}, Batch {i+1}/{len(train_dataloader)}, Loss: {loss.item():.4f}')
print(f'Epoch [{epoch+1}/{num_epochs}], Average Loss: {total_loss/len(train_dataloader):.4f}')
print("Finished Training")
# 모델 학습 실행
train_model(model, train_dataloader, criterion, optimizer, num_epochs=10)이렇게 수정을 하고, 결과를 보니
Epoch 1/10, Batch 10/5857, Loss: 1.5871
Epoch 1/10, Batch 20/5857, Loss: 1.5787
Epoch 1/10, Batch 30/5857, Loss: 1.5611
Epoch 1/10, Batch 40/5857, Loss: 1.6022
Epoch 1/10, Batch 50/5857, Loss: 1.5740
Epoch 1/10, Batch 60/5857, Loss: 1.5352
Epoch 1/10, Batch 70/5857, Loss: 1.5795
Epoch 1/10, Batch 80/5857, Loss: 1.5721
Epoch 1/10, Batch 90/5857, Loss: 1.5562
.
.
.
Epoch 10/10, Batch 5790/5857, Loss: 1.5089
Epoch 10/10, Batch 5800/5857, Loss: 1.4243
Epoch 10/10, Batch 5810/5857, Loss: 1.4179
Epoch 10/10, Batch 5820/5857, Loss: 1.1962
Epoch 10/10, Batch 5830/5857, Loss: 1.2337
Epoch 10/10, Batch 5840/5857, Loss: 1.5011
Epoch 10/10, Batch 5850/5857, Loss: 1.5205
Epoch [10/10], Average Loss: 1.4340
Finished Training
학습이 잘 되지도 않았다.
correct = 0
total = 0
with torch.no_grad(): # 평가 시에는 기울기 계산을 하지 않음
for reviews, ratings in test_dataloader:
reviews, ratings = reviews.to(device), ratings.to(device)
outputs = model(reviews)
_, predicted = torch.max(outputs, 1)
total += ratings.size(0)
correct += (predicted == ratings).sum().item()
print(f'Accuracy: {100 * correct / total}%')Accuracy: 39.13860075980706%
39퍼! 망했다.
