네이버페이 증권에서 삼성전자 주가 정보 url를 찾아서 크롤링하는 실습을 해 봤다.
튜터님이 작성하신 정답코드와 어떤점이 다른지 비교분석 해보자...
실습코드
import requests
from bs4 import BeautifulSoup
import json
from typing import List, Dict
import pandas as pd
def get_samsung_info(page: int) -> str:
"""
삼성 주가 정보 페이지의 HTML을 가져오는 함수
Args:
page (int): 페이지 번호
Returns:
str: 웹 페이지의 HTML 내용
"""
url = "https://finance.naver.com/item/sise_day.naver?code=005930"
params = {"page": page}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/120.0.0.0'
}
try:
response = requests.get(url, params=params, headers=headers)
response.raise_for_status() # 오류가 있으면 예외를 발생시킴
return response.text
except requests.exceptions.RequestException as e:
print(f"페이지 {page} 요청 중 에러 발생: {e}")
return ""
def parse_stock_info(html: str) -> List[Dict[str, str]]:
"""
HTML에서 주가 정보를 파싱하는 함수
Args:
html (str): 파싱할 HTML 문자열
Returns:
List[Dict[str, str]]: 주가 정보 딕셔너리의 리스트
"""
stock_data = []
soup = BeautifulSoup(html, 'html.parser')
# HTML 문서의 제목을 출력 (디버깅용)
print(soup.title.get_text())
# <table class="type2">에서 모든 <tr> 요소를 가져와 분석
table = soup.find("table", class_="type2")
if not table:
print("Error: 'type2' 클래스를 가진 <table> 요소를 찾을 수 없습니다.")
return stock_data
for tr in table.find_all("tr"):
tds = tr.find_all("td")
# <td>가 7개 이상인 경우에만 유효한 데이터로 간주
if len(tds) >= 7:
# <td>의 <span> 요소에서 텍스트를 가져와 data 딕셔너리에 저장
data = {
"Date": tds[0].find("span").text.strip() if tds[0].find("span") else "",
"Closing Price": tds[1].find("span").text.strip() if tds[1].find("span") else "",
"Change": tds[2].find("span").text.strip() if tds[2].find("span") else "",
"Opening Price": tds[3].find("span").text.strip() if tds[3].find("span") else "",
"High Price": tds[4].find("span").text.strip() if tds[4].find("span") else "",
"Low Price": tds[5].find("span").text.strip() if tds[5].find("span") else "",
"Trading Volume": tds[6].find("span").text.strip() if tds[6].find("span") else ""
}
stock_data.append(data)
return stock_data
# stocks = parse_stock_info(html)
# print(json.dumps(stocks, ensure_ascii=False, indent=2))
def save_to_files(stocks: List[Dict], base_path: str = "./"):
"""
매장 정보를 CSV와 JSON 파일로 저장하는 함수
Args:
stores (List[Dict]): 저장할 매장 정보 리스트
base_path (str): 파일을 저장할 기본 경로
"""
# CSV 파일로 저장
df = pd.DataFrame(stocks)
csv_path = f"{base_path}samsung_stocks.csv"
df.to_csv(csv_path, encoding='utf-8', index=False)
# JSON 파일로 저장
json_path = f"{base_path}samsung_stocks.json"
with open(json_path, 'w', encoding='utf-8') as f:
json.dump(stocks, f, ensure_ascii=False, indent=4)
print(f"CSV 파일 저장 완료: {csv_path}")
print(f"JSON 파일 저장 완료: {json_path}")
# 데이터 미리보기
print("\n데이터 미리보기:")
print(df.head())
# 테스트: 첫 페이지 데이터 저장하기
# save_to_files(stocks)
# 전체 데이터 저장하기
def main():
stocks = []
# 매장 정보 수집
print("삼성 주가 정보 수집 중...")
for page in range(1, 7): # 1~6 페이지만 수집
html = get_samsung_info(page)
if html:
stocks.extend(parse_stock_info(html))
print(f"페이지 {page}: {len(parse_stock_info(html))}개의 주식 정보")
if not stocks:
print("매장 정보를 가져오는데 실패했습니다.")
return
print(f"\n총 {len(stocks)}개의 주식정보를 수집했습니다.")
# 데이터 저장
try:
save_to_files(stocks, './')
except Exception as e:
print(f"데이터 저장 중 에러 발생: {e}")
# 전체 과정 실행
main()<samsung_stocks.csv> 결과
Date,Closing Price,Change,Opening Price,High Price,Low Price,Trading Volume
2024.11.12,"53,000",하락,"54,600","54,600","53,000","32,862,501"
2024.11.11,"55,000",하락,"56,700","56,800","55,000","29,811,326"
2024.11.08,"57,000",하락,"58,000","58,300","57,000","13,877,396"
2024.11.07,"57,500",상승,"56,900","58,100","56,800","17,043,102"
2024.11.06,"57,300",하락,"57,600","58,000","56,300","22,092,218"
2024.11.05,"57,600",하락,"57,800","58,100","57,200","17,484,474"
2024.11.04,"58,700",상승,"58,600","59,400","58,400","15,586,947"
2024.11.01,"58,300",하락,"59,000","59,600","58,100","19,083,180"
2024.10.31,"59,200",상승,"58,500","61,200","58,300","35,809,196"
2024.10.30,"59,100",하락,"59,100","59,800","58,600","19,838,511"
.
.
.정답 코드(튜터님 작성)
# 1. 필요한 라이브러리 임포트
import requests
from bs4 import BeautifulSoup
import pandas as pd
from datetime import datetime
import time
import os
# 2. User-Agent 설정
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
# 3. 빈 리스트 생성하여 데이터 저장 준비
stockList = []
# 4. 페이지별로 데이터 수집 (10페이지)
for i in range(1, 11):
# URL 설정
url = f"https://finance.naver.com/item/sise_day.nhn?code=005930&page={i}"
# HTML 가져오기
try:
response = requests.get(url, headers=headers)
response.encoding = 'euc-kr'
if response.status_code != 200:
print(f"페이지 {i} 크롤링 실패")
continue
except Exception as e:
print(f"Error fetching URL: {e}")
continue
# BeautifulSoup으로 HTML 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# 주가 데이터가 있는 행 찾기
tag_trs = soup.find_all('tr', attrs={"onmouseover": "mouseOver(this)"})
# 각 행에서 데이터 추출
for tr in tag_trs:
tds = tr.find_all("td")
if len(tds) != 7: # 데이터 검증
continue
stock = {}
# 날짜 추출
date_text = tds[0].text.strip()
if not date_text:
continue
stock['날짜'] = date_text
# 종가 추출
try:
stock['종가'] = int(tds[1].text.replace(',', '').strip())
except:
continue
# 전일비 추출
if tds[2].find('span'):
value = tds[2].find('span', class_='tah').text.strip().replace('\n', '').replace('\t', '').replace(',', '')
stock['전일비'] = f"-{value}" if tds[2].find('span', class_ = 'blind').text.strip() == '하락' else value
else:
stock['전일비'] = tds[2].find('span', class_='tah').text.strip().replace('\n', '').replace('\t', '').replace(',', '')
# 시가, 고가, 저가, 거래량 추출
try:
stock['전일비'] = int(stock['전일비'])
stock['시가'] = int(tds[3].text.replace(',', '').strip())
stock['고가'] = int(tds[4].text.replace(',', '').strip())
stock['저가'] = int(tds[5].text.replace(',', '').strip())
stock['거래량'] = int(tds[6].text.replace(',', '').strip())
except:
continue
# 데이터 리스트에 추가
stockList.append(stock)
# 크롤링 간격 설정
time.sleep(0.5)
print(f"{i}페이지 크롤링 완료")
# 5. DataFrame 생성
df = pd.DataFrame(stockList)
# 6. 수집된 데이터 미리보기
print("\n수집된 데이터 미리보기:")
print(df.head())
# 7. 데이터 저장
# 저장할 디렉토리 생성
os.makedirs('./웹크롤링/data', exist_ok=True)
# CSV 파일로 저장
filename = f'./웹크롤링/data/삼성전자주가_{datetime.now().strftime("%Y%m%d")}.csv'
df.to_csv(filename, index=False, encoding='utf-8')
print(f"\n데이터가 성공적으로 저장되었습니다: {filename}")
print(f"총 {len(df)}개의 주가 데이터가 수집되었습니다.")
결과
날짜,종가,전일비,시가,고가,저가,거래량
2024.11.12,53000,-2000,54600,54600,53000,32862501
2024.11.11,55000,-2000,56700,56800,55000,29811326
2024.11.08,57000,-500,58000,58300,57000,13877396
2024.11.07,57500,200,56900,58100,56800,17043102
2024.11.06,57300,-300,57600,58000,56300,22092218
2024.11.05,57600,-1100,57800,58100,57200,17484474
2024.11.04,58700,400,58600,59400,58400,15586947
2024.11.01,58300,-900,59000,59600,58100,19083180
2024.10.31,59200,100,58500,61200,58300,35809196
2024.10.30,59100,-500,59100,59800,58600,19838511
2024.10.29,59600,1500,58000,59600,57300,28369314
2024.10.28,58100,2200,55700,58500,55700,27775009
2024.10.25,55900,-700,56000,56900,55800,25829315
2024.10.24,56600,-2500,58200,58500,56600,31499922
2024.10.23,59100,1400,57500,60000,57100,27300780
2024.10.22,57700,-1300,58800,58900,57700,27582527이렇게 두 코드를 비교해 봤다.
결과를 중심으로 봤을때, ,처리나 전처리 부분에서 미흡했고 str형태로 숫자들이 나오는 것을 한눈에 알 수 있다.
어떤식으로 정답코드가 구성됐는지 살펴보자.
분석
# 빈 리스트 생성하여 데이터 저장 준비
stockList = []
# 페이지별로 데이터 수집 (10페이지)
for i in range(1, 11):
# URL 설정
url = f"https://finance.naver.com/item/sise_day.nhn?code=005930&page={i}"
# HTML 가져오기
try:
response = requests.get(url, headers=headers)
response.encoding = 'euc-kr'
if response.status_code != 200:
print(f"페이지 {i} 크롤링 실패")
continue
except Exception as e:
print(f"Error fetching URL: {e}")
continue- 빈 리스트를 먼저 생성합니다.
- 반복문 설정: 1페이지부터 10페이지까지의 데이터를 수집하기 위해 for 루프를 사용합니다.
- URL 설정: 각 페이지에 맞는 URL을 생성합니다.
- HTML 요청 및 인코딩 설정:
- requests.get을 통해 HTML 소스를 가져옵니다.
- 네이버 금융 페이지는 euc-kr 인코딩을 사용하므로 인코딩을 설정합니다.
- 응답 상태 코드 확인: 상태 코드가 200이 아닌 경우 해당 페이지의 크롤링을 건너뜁니다.
- 예외 처리: 요청 중 에러가 발생하면 에러 메시지를 출력하고 다음 페이지로 넘어갑니다
# BeautifulSoup으로 HTML 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# 주가 데이터가 있는 행 찾기
tag_trs = soup.find_all('tr', attrs={"onmouseover": "mouseOver(this)"})- HTML 파싱: 가져온 HTML 소스를 BeautifulSoup 객체로 파싱합니다.
- 데이터 행 선택: 주가 데이터가 포함된 태그들을 선택합니다. 해당 태그들은 onmouseover 속성을 가지고 있습니다.
# 각 행에서 데이터 추출
for tr in tag_trs:
tds = tr.find_all("td")
if len(tds) != 7: # 데이터 검증
continue
- 데이터 추출 반복문: 각 행(tr)에서 데이터를 추출하기 위해 for 루프를 사용합니다.
- 데이터 셀 선택: 각 행에서 태그들을 찾습니다.
- 데이터 유효성 검사: 태그의 개수가 7개가 아닌 경우 데이터가 불완전하므로 건너뜁니다.
stock = {}
# 날짜 추출
date_text = tds[0].text.strip()
if not date_text:
continue
stock['날짜'] = date_text- 빈 딕셔너리 생성: 각 주가 정보를 저장할 딕셔너리를 만듭니다.
- 날짜 추출 및 저장: 첫 번째
<td>에서 날짜를 추출하고, 비어 있지 않다면 stock 딕셔너리에 저장합니다.
# 종가 추출
try:
stock['종가'] = int(tds[1].text.replace(',', '').strip())
except:
continue- 종가 추출 및 변환: 두 번째
<td>에서 종가를 추출하고 쉼표를 제거한 후 정수로 변환하여 저장합니다. - 예외 처리: 변환 중 에러가 발생하면 해당 데이터를 건너뜁니다.
# 전일비 추출
if tds[2].find('span'):
value = tds[2].find('span', class_='tah').text.strip().replace('\n', '').replace('\t', '').replace(',', '')
stock['전일비'] = f"-{value}" if tds[2].find('span', class_ = 'blind').text.strip() == '하락' else value
else:
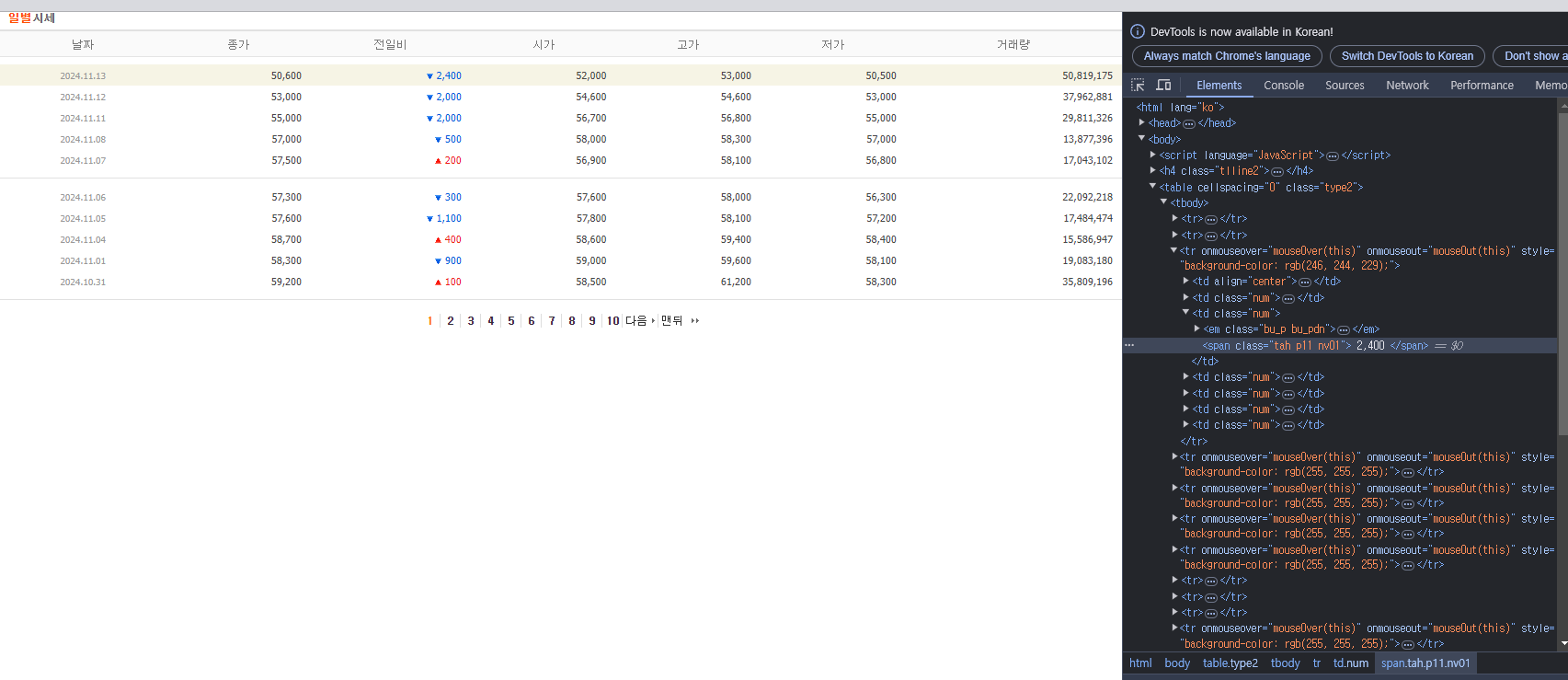
stock['전일비'] = tds[2].find('span', class_='tah').text.strip().replace('\n', '').replace('\t', '').replace(',', '')class가 'tah'인 값을 찾아서 전처리를 진행하는 과정입니다.
- 전일비 추출: 상승 또는 하락 여부에 따라 전일 대비 가격 변동을 추출합니다.
- 하락인 경우: 값 앞에 마이너스(-)를 붙입니다.
- 상승인 경우: 그대로 값을 사용합니다.
- 불필요한 문자 제거: 탭, 쉼표 등을 제거합니다.
# 시가, 고가, 저가, 거래량 추출
try:
stock['전일비'] = int(stock['전일비'])
stock['시가'] = int(tds[3].text.replace(',', '').strip())
stock['고가'] = int(tds[4].text.replace(',', '').strip())
stock['저가'] = int(tds[5].text.replace(',', '').strip())
stock['거래량'] = int(tds[6].text.replace(',', '').strip())
except:
continue
# 데이터 리스트에 추가
stockList.append(stock)
# 크롤링 간격 설정
time.sleep(0.5)
print(f"{i}페이지 크롤링 완료")
데이터 추출 및 변환: 나머지 항목들(시가, 고가, 저가, 거래량)을 추출하고 정수로 변환하여 stock 딕셔너리에 저장합니다.
지연 시간 부여: 서버에 과부하를 주지 않기 위해 0.5초의 지연 시간을 줍니다.
진행 상황 출력: 현재 페이지의 크롤링이 완료되었음을 출력합니다.
데이터 활용을 위해서 필수적인 크롤링에 대해서 배웠다. 아직 완벽하게 할 수는 없지만 넉넉한 시간이 주어지면 어떻게든 해볼만하다. 를 배웠다.
참고

안녕하세요.