1. 프로젝트 설명
2021년 2학기 데이터 관리와 분석 전공 강의에서 진행하였던 프로젝트를 정리하고자 한다. 한 학기동안 DB에 대해서 이해하고 SQL을 통해 이를 다루는 법을 배웠다. 학기 중반이 지나고는 데이터마이닝 기법에 대해 배웠다. 의사결정나무, KNN, 추천 시스템, 정보 검색, 텍스트 마이닝(워드 임베딩), 토픽 모델링, 문서 군집화 등 여러 기법들을 간단하게 배웠다. 프로젝트는 3개로 각각의 requirement가 주어졌으며 1차와 2차 프로젝트에서는 주어진 요구사항들을 만족하는 데이터베이스를 설계 및 구현, 그리고 이를 기반으로 한 DB 마이닝과 추천 시스템 구현이 목적이었고, 3차 프로젝트에서는 텍스트 데이터를 대상으로 정보 검색, 문서 분류 및 군집화를 구현하는 것이 목적이었다.
2. 1차 프로젝트
고객이 사업체에 대한 리뷰를 작성하는 가상의 사이트A를 가정한다. 사이트 고객(사용자)들은 자신이 이용한 여러 유형의 사업체에 대한 리뷰를 남기고 고객끼리 리뷰를 공유하며 교류할 수 있다. 이를 위해 다음과 같은 작업이 필요하다.
1. ER diagram을 도식화한다.
2. DB 스키마를 구현하고 직접 데이터를 입력한다.
3. ER diagram
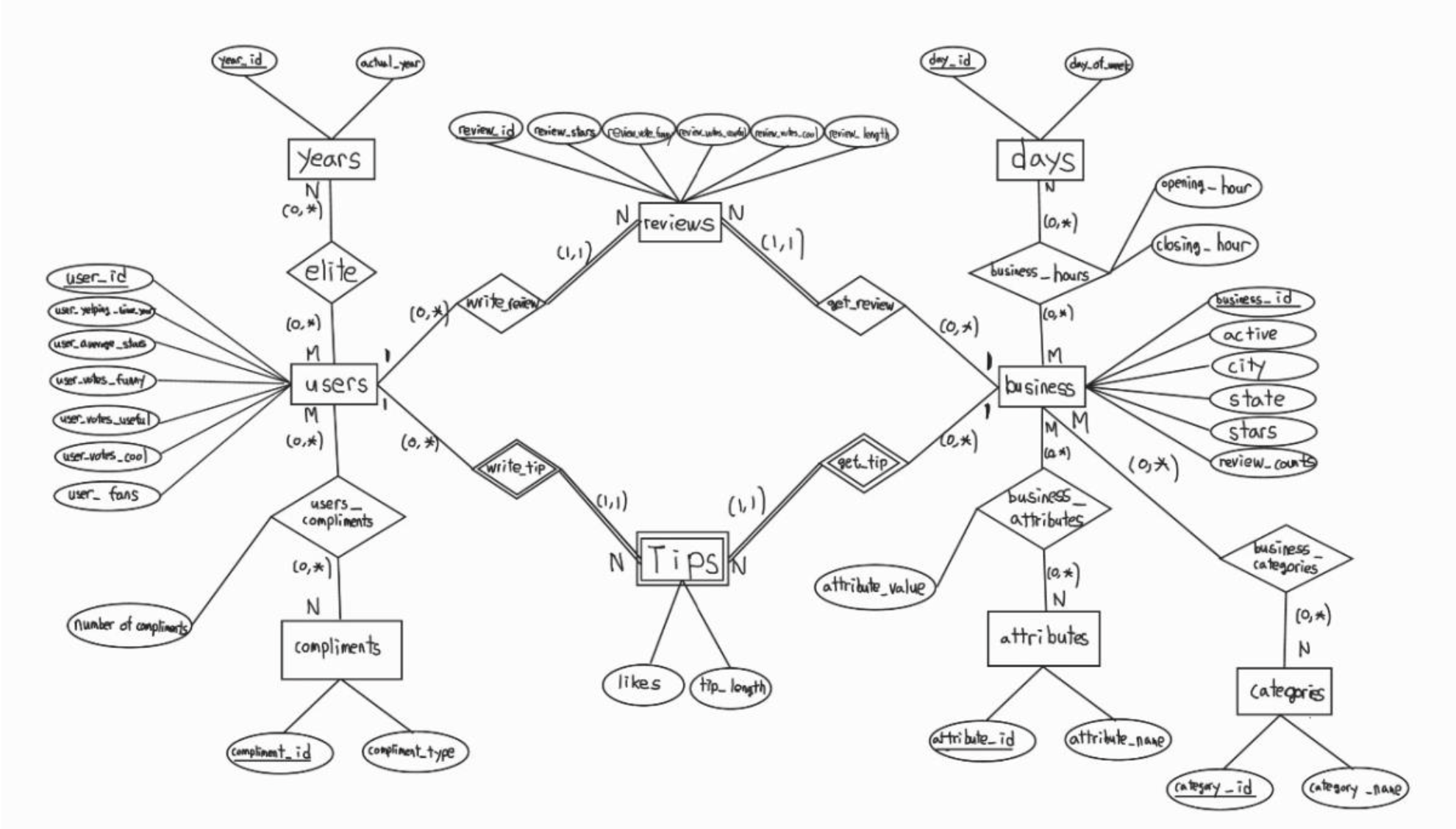 DB에 표현 되어야 하는 개체들과 그에 딸린 속성들을 모두 표현해주었다. 그 사이들은 관계로 표현하였다. tips는 특별히 약한 개체로 표현하였으며 관계 대응수의 최소 및 최댓값도 모두 표현해 주었다.
DB에 표현 되어야 하는 개체들과 그에 딸린 속성들을 모두 표현해주었다. 그 사이들은 관계로 표현하였다. tips는 특별히 약한 개체로 표현하였으며 관계 대응수의 최소 및 최댓값도 모두 표현해 주었다.
RDB schema
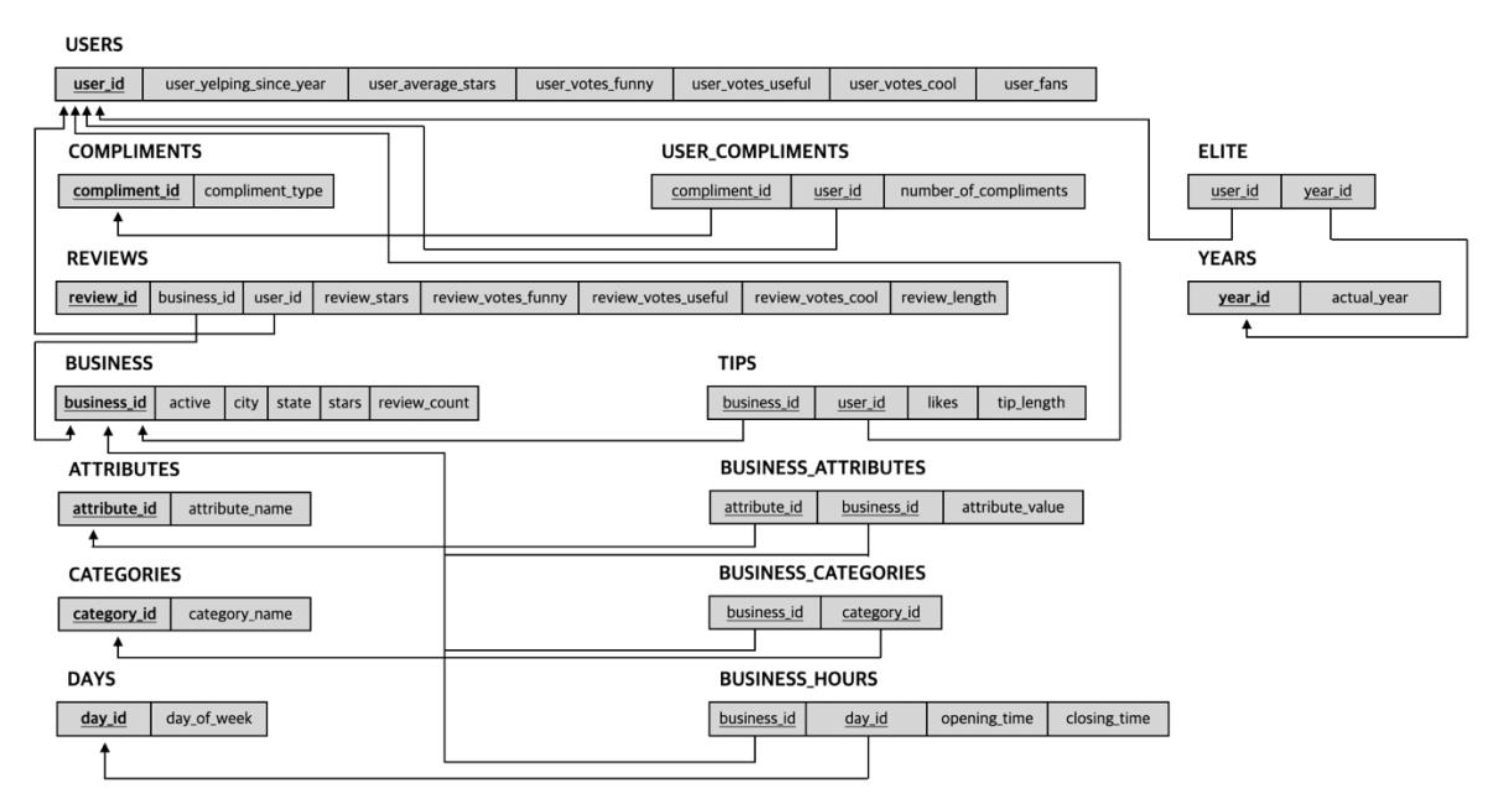 주어진 모든 table과 그것의 attribute들을 기본적으로 나타내었고 키는 밑줄로 표시하였다. 이들 사이에서 참조하는 관계는 화살표로 표시하였다.
주어진 모든 table과 그것의 attribute들을 기본적으로 나타내었고 키는 밑줄로 표시하였다. 이들 사이에서 참조하는 관계는 화살표로 표시하였다.
대략적인 관계는 위와 같으나 My SQL로 DB schema를 생성해주기 위해서는 data type과 key 조건을 넣어주어야 했다. 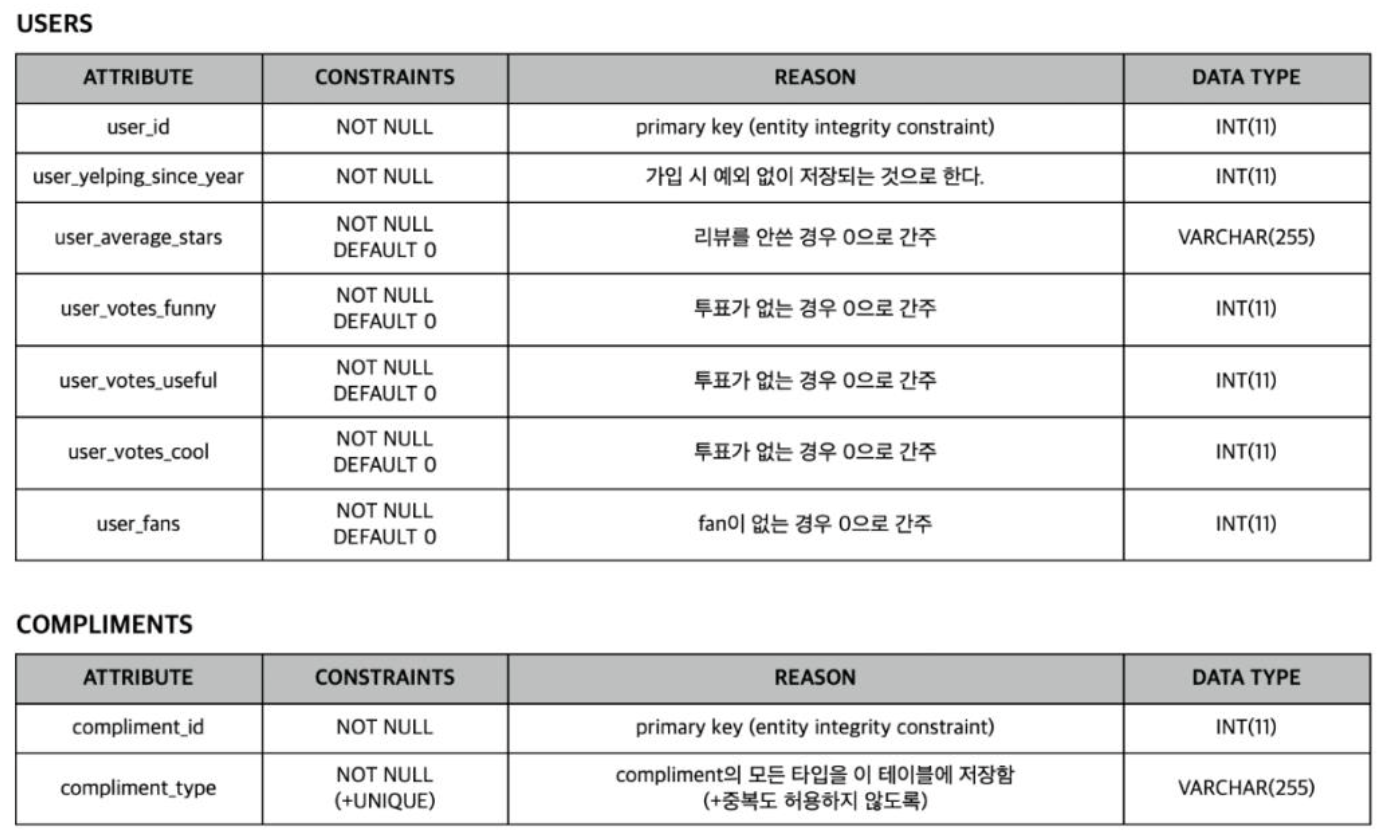
4. DB 구현 및 데이터 입력
앞서 만들었던 ER diagram과RDB schema를 참고하여 코드를 작성한다.
1) 스키마 생성
import mysql.connector
# TODO: REPLACE THE VALUE OF VARIABLE team (EX. TEAM 1 --> team = 1)
team = 6
# Requirement1: create schema ( name: DMA_team## )
def requirement1(host, user, password):
cnx = mysql.connector.connect(host=host, user=user, password=password)
cursor = cnx.cursor()
cursor.execute('SET Global innodb_buffer_pool_size=2*1024*1024*1024;')
# TODO: WRITE CODE HERE
#cursor.execute('DROP DATABASE IF EXISTS DMA_team%02d;' % team) #db가 변경되었다면 기존의 DATABASE를 삭제
cursor.execute('CREATE DATABASE IF NOT EXISTS DMA_team%02d;' % team)
# TODO: WRITE CODE HERE
cursor.close()2) table 생성
# Requierement2: create table
def requirement2(host, user, password):
cnx = mysql.connector.connect(host=host, user=user, password=password)
cursor = cnx.cursor()
cursor.execute('SET Global innodb_buffer_pool_size=2*1024*1024*1024;')
# TODO: WRITE CODE HERE
cursor.execute('USE DMA_team%02d;' % team)
# users
cursor.execute('''
CREATE TABLE IF NOT EXISTS users(
user_id INT(11) NOT NULL,
user_yelping_since_years INT(11) NOT NULL,
user_average_stars VARCHAR(255) NOT NULL DEFAULT 0,
user_votes_funny INT(11) NOT NULL DEFAULT 0,
user_votes_useful INT(11) NOT NULL DEFAULT 0,
user_votes_cool INT(11) NOT NULL DEFAULT 0,
user_fans INT(11) NOT NULL DEFAULT 0,
PRIMARY KEY (user_id)
);
''')
#다른 table에 대해서도 반복 ...
cursor.close()테이블을 생성하는 방법은 모든 테이블이 동일하기 때문에, 대표적으로 users 테이블 생성하는 방법을 살펴보면, cursor의 실행문 안에서, ‘CREATE TABLE IF NOT EXISTS users’를 통해 users라는 이름을 가진 테이블을 생성시켰고 괄호를 통해, 각 테이블 안의 어트리뷰트를 정의하였다. 또 각 테이블의 기본키를 설정하였다.
또, years 테이블의 actual_year처럼 unique속성을 갖고 있는 어트리뷰트는, 기본키를 정의한 다음, ‘UNIQUE’를 통해, unique속성을 설정하였다.
3) Inserting data
# Requirement3: insert data
def requirement3(host, user, password, directory):
cnx = mysql.connector.connect(host=host, user=user, password=password)
cursor = cnx.cursor()
cursor.execute('SET GLOBAL innodb_buffer_pool_size=2*1024*1024*1024;')
# TODO: WRITE CODE HERE
cursor.execute('USE DMA_team%02d;' % team)
# table list and file path
table_list = ['users', 'compliments', 'business', 'reviews', 'attributes', 'business_attributes', 'categories',
'business_categories','days', 'business_hours', 'years', 'elite', 'tips', 'users_compliments',]
filepath_list = ['{}{}.csv'.format(directory, table) for table in table_list]
# empty check in table
empty_check = 'SELECT COUNT(*) FROM {};'
# insert users data
cursor.execute(empty_check.format(table_list[0]))
for table in cursor:
if table[0] == 0:
with open(filepath_list[0], 'r', encoding='utf-8') as csv_data:
for row in csv_data.readlines()[1:]:
row = row.strip().replace('\"', '').split(',')
#print(row) #table에 들어가는 모든 row를 보기 위해
for idx, data in enumerate(row):
if data == '':
row[idx] = 'null'
print('changed')
if idx == 2:
row[idx] = str(data)
else:
row[idx] = int(data)
row = tuple(row)
query = 'INSERT INTO {} VALUES {};'.format(table_list[0], row)
query = query.replace("\'null\'", 'null')
cursor.execute(query)
cnx.commit()
else:
print("table '{}' is not empty".format(table_list[0]))users 테이블에 data를 삽입하는 코드이다. local에 저장되어 있는 csv 파일을 읽어와서 적당한 전처리를 한 후 DB에 INSERT 하였으며 데이터가 없는 경우는 특별히 null로 인식되도록 처리하였다.
4) Setting up foreign key
# Requirement4: add constraint (foreign key)
def requirement4(host, user, password):
cnx = mysql.connector.connect(host=host, user=user, password=password)
cursor = cnx.cursor()
cursor.execute('SET GLOBAL innodb_buffer_pool_size=2*1024*1024*1024;')
cursor.execute('USE DMA_team%02d;' % team)
cursor.execute('ALTER TABLE reviews ADD CONSTRAINT FOREIGN KEY (business_id) REFERENCES business(business_id);')
cursor.execute('ALTER TABLE reviews ADD CONSTRAINT FOREIGN KEY (user_id) REFERENCES users(user_id);')
cursor.execute('ALTER TABLE business_attributes ADD CONSTRAINT FOREIGN KEY (attribute_id) REFERENCES attributes(attribute_id);')
cursor.execute('ALTER TABLE business_attributes ADD CONSTRAINT FOREIGN KEY (business_id) REFERENCES business(business_id);')
cursor.execute('ALTER TABLE business_categories ADD CONSTRAINT FOREIGN KEY (business_id) REFERENCES business(business_id);')
cursor.execute('ALTER TABLE business_categories ADD CONSTRAINT FOREIGN KEY (category_id) REFERENCES categories(category_id);')
cursor.execute('ALTER TABLE business_hours ADD CONSTRAINT FOREIGN KEY (business_id) REFERENCES business(business_id);')
cursor.execute('ALTER TABLE business_hours ADD CONSTRAINT FOREIGN KEY (day_id) REFERENCES days(day_id);')
cursor.execute('ALTER TABLE elite ADD CONSTRAINT FOREIGN KEY (user_id) REFERENCES users(user_id);')
cursor.execute('ALTER TABLE elite ADD CONSTRAINT FOREIGN KEY (year_id) REFERENCES years(year_id);')
cursor.execute('ALTER TABLE tips ADD CONSTRAINT FOREIGN KEY (business_id) REFERENCES business(business_id);')
cursor.execute('ALTER TABLE tips ADD CONSTRAINT FOREIGN KEY (user_id) REFERENCES users(user_id);')
cursor.execute('ALTER TABLE users_compliments ADD CONSTRAINT FOREIGN KEY (compliment_id) REFERENCES compliments(compliment_id);')
cursor.execute('ALTER TABLE users_compliments ADD CONSTRAINT FOREIGN KEY (user_id) REFERENCES users(user_id);')
cursor.close()마지막으로 DB를 처음 생성할 때 삽입하지 않았던 외래키(foreign key) 조건을 삽입해 주었다.
5. 1차 프로젝트 마무리
실제 사이트에서 data를 어떻게 다루어야 하는지 알게 되었다. DB를 처음 배웠을 때, 교수님께서 DB schema를 처음부터 제대로 만드는 것이 중요하다는 말씀을 누누히 하셨지만 어떤 table을 만들고, 그 속에 어떤 attribute를 만들 것인가는 직관적으로 매우 쉬운 일이 아닌가 생각했었다. 하지만, 실제 사이트에서 만들어진 data들로 어떤 table들을 만들 것인지 결정(속성 결정 등)하는 것조차도 쉬운 일이 아니었다. 처음 쿼리를 작성해 보았음에도 불구하고 table을 결정하는 일보다 그 명령을 그대로 쿼리로 옮기는 과정이 더 쉬웠던 것 같다. 이외에도 python을 이용하여 DB를 직접 만들어보고 몇 만개의 데이터를 직접 삽입할 수 있는 좋은 경험이었다.
