1. 2차 프로젝트
DB mining 및 Automated Recommendation System 구현을 목적으로 한다.
본 프로젝트는 크게 세 부분으로 나뉘며 Python과 MySQL을 사용하여 구현하여야 한다.1. 의사결정나무
2. 연관분석
3. 추천시스템
2. 의사결정나무
추가적으로 VIP 사용자들의 정보를 담고 있는 vip_list.csv를 불러와서 이 사이트의 VIP 선정 기준을 파악해보는 것이 목표였다.
의사결정나무 생성을 위한 적합한 테이블 생성
# TODO: Requirement 1-2. WRITE MYSQL QUERY AND EXECUTE. SAVE to .csv file
fopen = open('DMA_project2_team%02d_part1.csv' % team, 'w', encoding='utf-8')
cursor.execute('''
SELECT A.user_id, A.vip, A.user_yelping_since_year, IFNULL(user_review_counts_no_null.user_review_counts, 0) AS user_review_counts,
A.user_fans, A.user_votes_funny, A.user_votes_useful, A.user_votes_cool, A.user_average_stars, IFNULL(A.user_tip_counts, 0) AS user_tip_counts
FROM
(SELECT users.user_id, users.vip, users.user_yelping_since_year, users.user_fans, users.user_votes_funny, users.user_votes_useful, users.user_votes_cool, users.user_average_stars,
user_tip_counts_no_null.user_tip_counts
FROM DMA_team07.users
LEFT JOIN (SELECT users.user_id, COUNT(*) AS user_tip_counts
FROM DMA_team07.users
JOIN DMA_team07.tips
ON users.user_id = tips.user_id
GROUP BY users.user_id) AS user_tip_counts_no_null
ON users.user_id = user_tip_counts_no_null.user_id) AS A
LEFT JOIN (SELECT users.user_id, COUNT(*) AS user_review_counts
FROM DMA_team07.users
JOIN DMA_team07.reviews
ON users.user_id = reviews.user_id
GROUP BY users.user_id) AS user_review_counts_no_null
ON A.user_id = user_review_counts_no_null.user_id;
''')
fopen.write('user_id,vip_list,user_yelping_since_year,user_review_counts,user_fans,user_votes_funny,user_votes_useful,user_votes_cool,user_average_stars,user_tip_counts')
fopen.write('\n')
for row in cursor:
for j in range(len(row)):
fopen.write('{}'.format(row[j]))
if j != len(row)-1:
fopen.write(',')
fopen.write('\n')
fopen.close()
print('1-2 complete!')users테이블에 있는 user_id에 대하여, 이 user_id가 vip_list.csv에 나와있는 user_id에 속한다면 1의 값을 가지고, 그렇지 않으면 0의 값을 갖는 vip 어트리뷰트를 users테이블에 추가했다. 그 후 tips 와 reviews 테이블을 user_id를 기준으로 left join시킨다.
이로써 만들어진 테이블에 존재하는 어트리뷰트들은 다음과 같다.
- user_id: 고객의 id
- vip_list: 고객의 VIP 선정 여부
- user_yelping_since_year: 고객이 사이트 A를 시작한 해
- user_review_counts: 고객이 작성한 리뷰 개수
- user_fans: 고객을 좋아하는 다른 고객 수
- user_votes_funny: 고객이 재밌다고 투표한 개수
- user_votes_useful: 고객이 유용하다고 투표한 개수
- user_votes_cool: 고객이 멋지다고 투표한 개수
- user_average_stars: 고객이 준 별점의 평균
- user_tip_counts : 고객이 작성한 팁의 좋아요 개수 합
의사결정나무 생성
vip여부와 이와 관련있다고 여겨지는 여러 어트리뷰트들을 모두 한테이블로 정리 한 후 Tree.DecisionTreeClassifier함수를 통해 gini와 entropy를 기준으로 하는 의사결정나무를 만들었다.
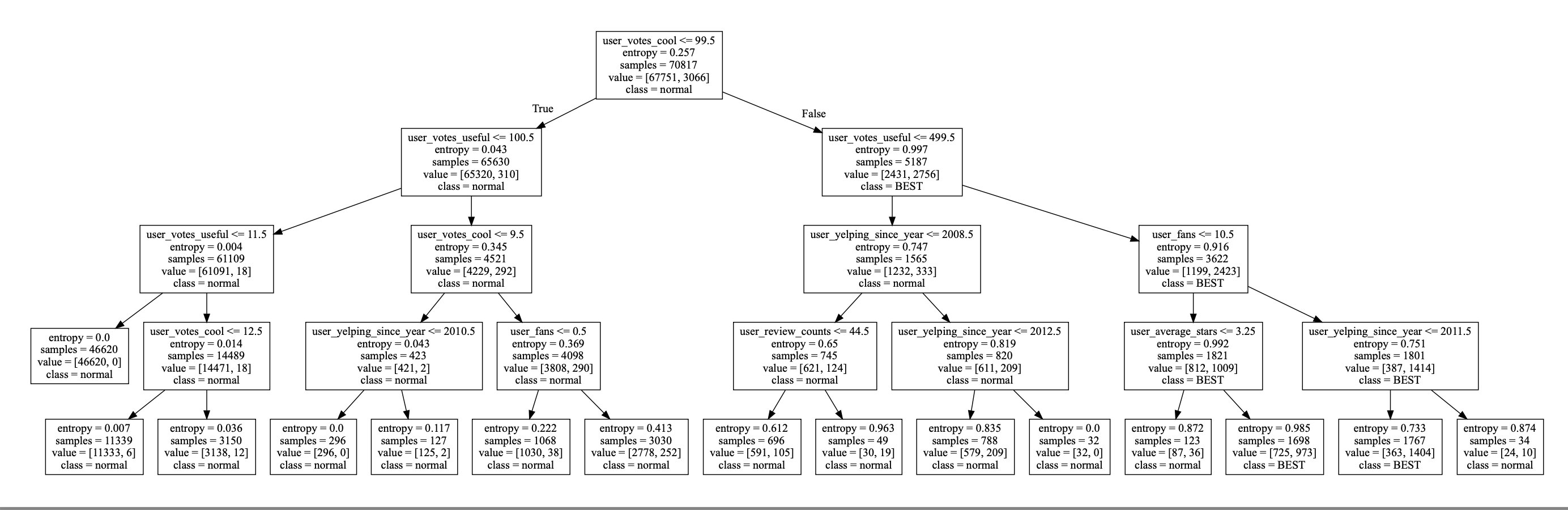
entropy를 기준으로 하는 의사결정나무
gini를 기준으로 하는 의사결정나무
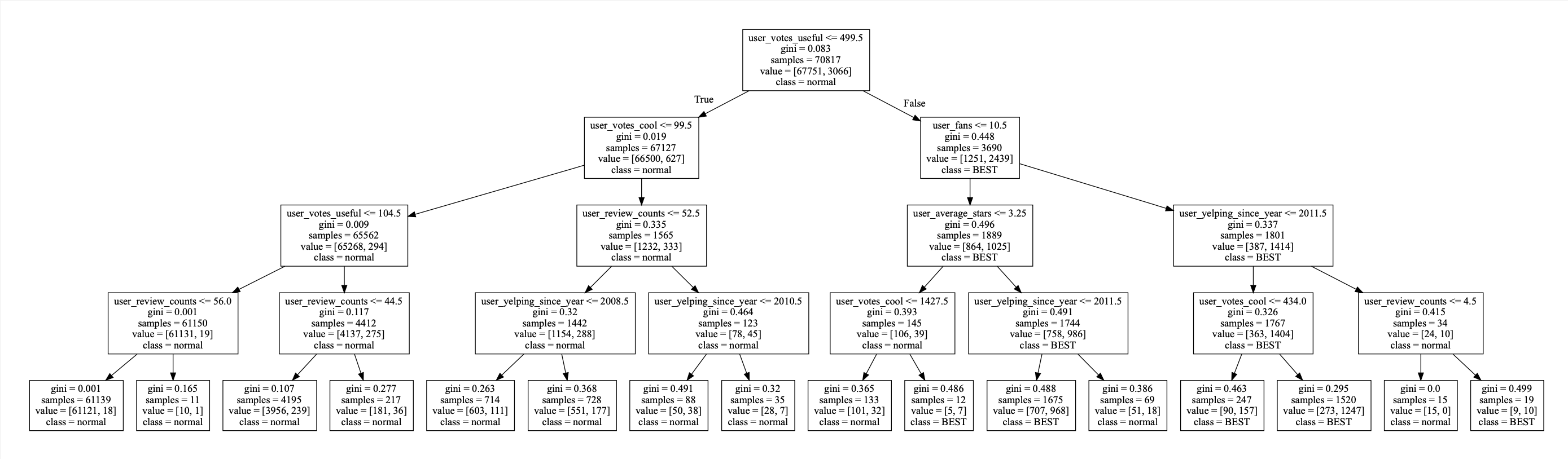
normal이 일반 user, best가 vip user이다.
min_samples_leaf는 8, max_depth는 4로 주었다.
mean accuracy는 0.9745가 나왔다.
3. 연관 분석
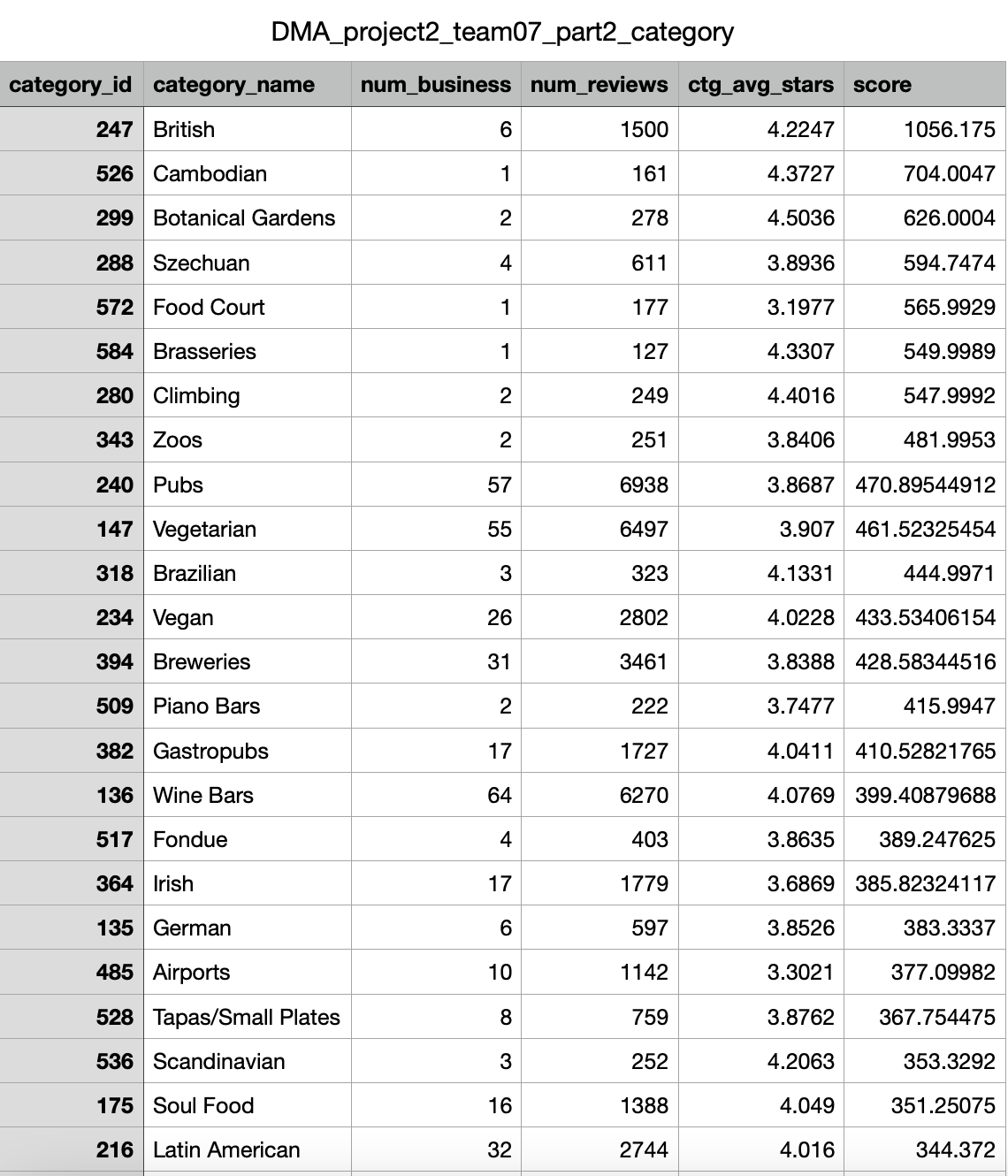
1) 영향력 있는 상위 30 category 선정
연관분석에서는 리뷰 수, 업체 수, 별점을 이용한 점수로 영향력 있는 상위 30개의 category 에 대해 진행한다. 이때 점수는 다음과 같은 기준을 도입한다.
- score: ctgavg_stars * (num_reviews / num business) 의 값
- num_business: 해당 카테고리에 해당하는 업체 수
- num_reviews: 해당 카테고리에 해당하는 업체의 리뷰 수 합
- ctg_avg_stars: 해당 카테고리에 해당하는 업체의 평균 별점
MySQL로score를 계산하기 위한 num_business, num_reviews, ctg_avg_stars를 기존의 테이블에서 계산해 내는 것이 관건이었다. 수많은 join과... group by를 사용하여 정확히 해당 카테고리의 업체수와 리뷰 수 합, 평균 별점을 계산해냈어야 했다.
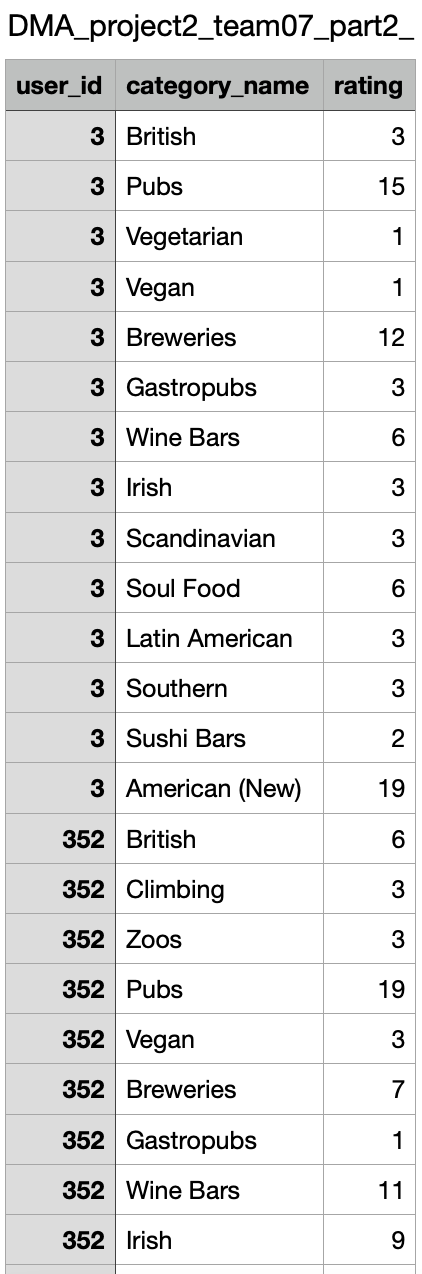
2) 각 user가 category에 대해 가지는 관심 정도를 rating으로 정의
다음과 같은 rating 기준을 설정하여 각 User가 category들에 대해서 얼마나 관심을 가지는지 비교하고자 하였다. rating을 전혀하지 않은 사업체만이 포함된 카테고리는 0점이 아닌 rating을 하지 않은 것으로 처리하였다.
Rating Equation
rating(user, category) = 2 * (user가 해당 category에 해당하는 사업체 중 4점 이상으로 리뷰한 업체 개수) + min(해당 user가 리뷰한 업체 중 해당 카테고리에 포함된 개수, 5)
예를 들어, a라는 사용자가 category_b에 해당하는 business 10개에 대해 이용 이력이 존재하고 해당 카테고리에 해당하는 사업체 중 사용자가 4점이상을 준 리뷰가 2건이라면 점이라면 rating(user_a, category_b) = 2 * 2 + min(10,5) 로 해당 category에 9이라는 관심 정도를 가진 것이다.
1)에서 설정한 상위 30개의 카테고리에 대해서 user들의 category rating 점수를 view로 생성하였으며 그 중에서도 이런 rating을 10개 이상 갖고 있는 user들을 따로 모아 partial_user_category_rating view를 생성하였다.
3) 연관성 분석
각 user는 연관 분석의 transaction 역할을, 각 category는 연관분석의 item 역할을 하도록 vertical table 형태의 partial_user_category_rating을 horizontal table로 만든 결과를 pandas의 DataFrame으로 저장하였다.
그 후 다음의 조건을 만족하는 frequent itemset을 만들고 연관 분석을 수행하였다.
- Frequent itemset의 최소 support: 0.15
- 연관분석 metric:lift(lift>=3 인 것들을 출력)
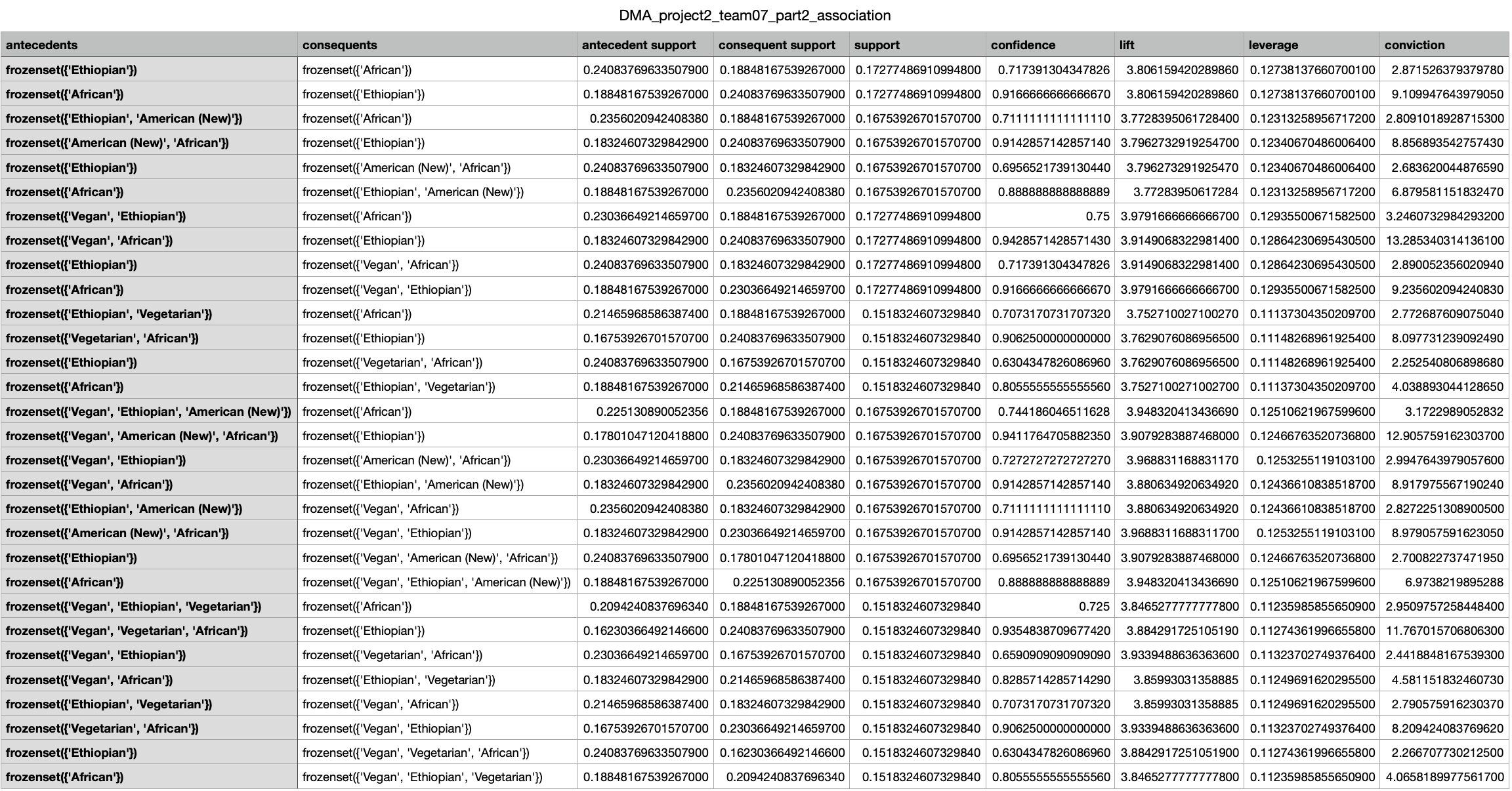
우선 African, Ethiopian, American, Vegetarian, Vegan이 계속적으로 등장한다. 이는 support의 최소값을 0.15로 다소 높은 값을 설정함으로써 일단 자주 등장하는 카테고리 여야 rule에 선정될 수 있기 때문이라고 해석된다. African과 Ethiopian / Vegetarian과 Vegan는 쉽게 이해할 수 있는 rule이다. lift와 support를 기준으로 선정하였기 때문에 단순히 순서만 바뀌어 있는 룰들이 많다. 다만 confidence가 대부분 다 높아 한 카테고 리가 다른 카테고리를 포함하는 상황은 적고 서로 긴밀하게 연결되어 있음을 알 수 있 다. 또한 African 혹은 Ethiopian카테고리를 이용하는 사람은 Vegan이거나 Vegetarian 카테고리를 이용할 가능성이 높으며, 이 반대도 성립한다. 그에 비해 American은 산발적 으로 rule에 나타나는 것처럼 보인다. American이 등장하는 rule을 보면 African이나 Ethiopian 카테고리를 이용하는 사람은 American 카테고리 또한 이용할 가능성이 높다 는 것을 알 수 있다. leverage는 모두 0.1보다 높고, conviction도 모두 1보다 높은 것으 로 보아 모든 rule이 상당히 독립적이지 않고 강한 rule들이라는 것을 알 수 있다.
4. 추천시스템
1) User based recommendation
특정 user에 대해서 다음의 알고리즘과 유사도 함수를 사용한 추천 결과를 도출해 보았다.
- 알고리즘 : KNNBasic 유사도: cosine
- 알고리즘 : KNNWithMeans 유사도: pearson
결과는 다음과 같다.
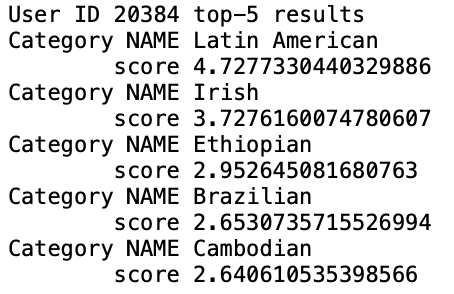
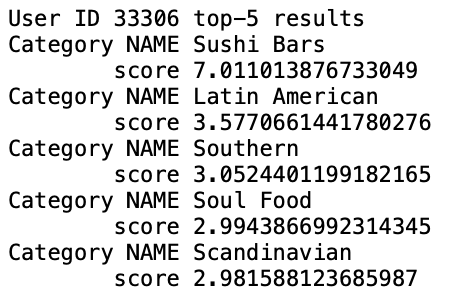
이후 다양한 알고리즘(KNNBasic, KNNWithMeans, KNNBaseline, KNNWithZScore)과 다양한 유사도 함수(cosine, pearson, pearson_baseline, msd) 중 가장 좋은 성능을 보이는 모델을 찾아보았다. 기준은 cross validation(k=5, random_state=0)로 하였다.
그 결과, 가장 좋은 성능을 나타내는 모델은 KNNBaseline 알고리즘에 pearson_baseline 유사도 함수를 사용한 모델이었다.
코드
def part3():
file_path = 'DMA_project2_team%02d_part2_UCR.csv' % team
reader = Reader(line_format='user item rating', sep=',', rating_scale=(1, 10), skip_lines=1)
data = Dataset.load_from_file(file_path, reader=reader)
trainset = data.build_full_trainset()
testset = trainset.build_anti_testset()
# TODO: Requirement 3-2. User-based Recommendation
uid_list = ['20384', '33306', '46833', '70628', '535']
# TODO: set algorithm for 3-2-1
sim_options = {'name' : 'cosine', 'user_based' : True}
algo = surprise.KNNBasic(sim_options = sim_options)
algo.fit(trainset)
results = get_top_n(algo, testset, uid_list, n=5, user_based=True)
with open('3-2-1.txt', 'w') as f:
for uid, ratings in sorted(results.items(), key=lambda x: x[0]):
f.write('User ID %s top-5 results\n' % uid)
for cname, score in ratings:
f.write('Category NAME %s\n\tscore %s\n' % (cname, str(score)))
f.write('\n')
print('3-2-1 complete!')
# TODO: set algorithm for 3-2-2
sim_options = {'name' : 'pearson', 'user_based' : True}
algo = surprise.KNNWithMeans(sim_options = sim_options)
algo.fit(trainset)
results = get_top_n(algo, testset, uid_list, n=5, user_based=True)
with open('3-2-2.txt', 'w') as f:
for uid, ratings in sorted(results.items(), key=lambda x: x[0]):
f.write('User ID %s top-5 results\n' % uid)
for cname, score in ratings:
f.write('Category NAME %s\n\tscore %s\n' % (cname, str(score)))
f.write('\n')
print('3-2-2 complete!')
# TODO: 3-2-3. Best Model
current_score = 1000
best_algo_ub = None
results = []
algo_list = [surprise.KNNBasic, surprise.KNNWithMeans, surprise.KNNBaseline, surprise.KNNWithZScore]
func_list = ['cosine', 'pearson', 'pearson_baseline', 'msd']
for algo_name in algo_list:
for func in func_list:
sim_options = {'name': func, 'user_based': True}
algo = algo_name(sim_options = sim_options)
kfold = KFold(n_splits = 5, random_state = 0)
result = surprise.model_selection.cross_validate(algo, data, measures=['RMSE'], cv = kfold, verbose =False)
results.append('algorithm : ' + str(algo) + ' function : ' + func + ' RMSE : ' + str(result['test_rmse'].mean()))
if result['test_rmse'].mean() < current_score :
current_score = result['test_rmse'].mean()
best_algo_ub = 'algorithm : ' + str(algo) + ' function : ' + func
best_score_ub = current_score
print(best_score_ub)
print(best_algo_ub)
print('3-2-3 complete!')2) Item-based Recommendation
카테고리를 기준으로 top-10 user를 출력하는 item-based 추천 모델을 만 들었다. 주어진 추천 알고리즘과 유사도 함수를 사용해서 모델을 만들었고 위와 마찬가지로 KNNBasic과 cosine 함수로 만든 모델, 그리고 KNNWithMeans와 pearson 함수를 이용해 만든 모델 두가지를 사용했다. 결과는 다음과 같은 형식으로 나왔다.
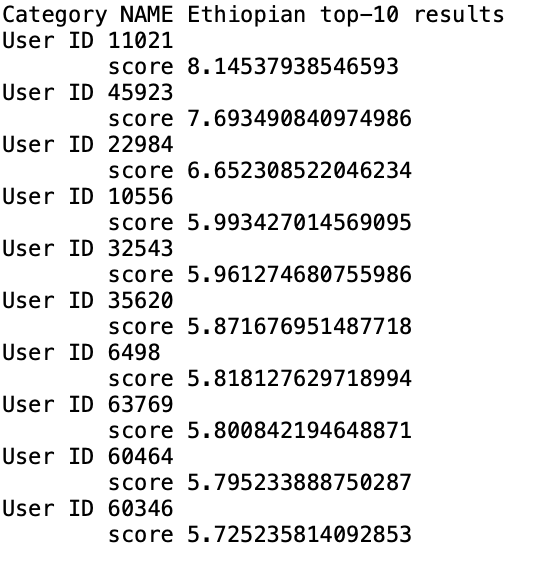
위와 마찬가지로 다양한 알고리즘(KNNBasic, KNNWithMeans, KNNBaseline, KNNWithZScore)과 다양한 유사도 함수(cosine, pearson, pearson_baseline, msd)를 적용하여 가장 성능이 좋은 모델을 찾았다.
KNNWithZscore 알고리즘에 pearson 유사도를 사용한 모델이 가장 성능이 좋았다.

코드
# TODO: Requirement 3-3. Item-based Recommendation
cname_list = ['Irish',
'Ethiopian',
'Wine Bars',
'Vegetarian',
'Sushi Bars']
# TODO - set algorithm for 3-3-1
sim_options = {'name' : 'cosine', 'user_based' : False}
algo = surprise.KNNBasic(sim_options = sim_options)
algo.fit(trainset)
results = get_top_n(algo, testset, cname_list, n=10, user_based=False)
with open('3-3-1.txt', 'w') as f:
for cname, ratings in sorted(results.items(), key=lambda x: x[0]):
f.write('Category NAME %s top-10 results\n' % cname)
for uid, score in ratings:
f.write('User ID %s\n\tscore %s\n' % (uid, str(score)))
f.write('\n')
print('3-3-1 complete!')
# TODO: set algorithm for 3-3-2
sim_options = {'name' : 'pearson', 'user_based' : False}
algo = surprise.KNNWithMeans(sim_options = sim_options)
algo.fit(trainset)
results = get_top_n(algo, testset, cname_list, n=10, user_based=False)
with open('3-3-2.txt', 'w') as f:
for cname, ratings in sorted(results.items(), key=lambda x: x[0]):
f.write('Category NAME %s top-10 results\n' % cname)
for uid, score in ratings:
f.write('User ID %s\n\tscore %s\n' % (uid, str(score)))
f.write('\n')
print('3-3-2 complete!')
# TODO: 3-3-3. Best Model
current_score = 10000
best_algo_ib = None
results = []
algo_list = [surprise.KNNBasic, surprise.KNNWithMeans, surprise.KNNBaseline, surprise.KNNWithZScore]
func_list = ['cosine', 'pearson', 'pearson_baseline', 'msd']
for algo_name in algo_list:
for func in func_list:
sim_options = {'name' : func, 'user_based': False}
algo = algo_name(sim_options = sim_options)
kfold = KFold(n_splits = 5, random_state = 0)
result = surprise.model_selection.cross_validate(algo, data, measures=['RMSE'], cv = kfold, verbose =False)
results.append('algorithm : ' + str(algo) + ' function : ' + func + ' RMSE : ' + str(result['test_rmse'].mean()))
if result['test_rmse'].mean() < current_score :
current_score = result['test_rmse'].mean()
best_algo_ib = 'algorithm : ' + str(algo) + ' function : ' + func
best_score_ib = current_score
print(best_score_ib)
print(best_algo_ib)
print('3-3-3 complete!')5. 2차 프로젝트 마무리
수업 시간에 배운 다양한 머신러닝과 알고리즘을 직접 적용해보는 시간을 가졌다. 역시나 대부분의 노력은 mySQL을 통한 데이터 전처리에 들어갔다. 그에 비해 모델을 학습시키는 것은 알고리즘을 잘 알지 못해도 라이브러리로 충분히 가능하다는 생각이 들었다. 다만 학습을 시키는 것 자체는 코드만 쓸 줄 안다면 가능하지만 성능이 좋은 모델을 만들기 위해서는 데이터에 대한 정확한 분석과 알고리즘의 차이점들을 정확히 알고 있어야 한다는 생각이 들었다. 사실 머신러닝을 할 때마다 느끼는 점이지만, 어떤 모델을 사용해야 현 상황에 가장 좋은지 정확히 판단을 할 수 있는가에 대해서 의문을 갖게 된다. 한 알고리즘에 대해서 여러 파라미터를 결정해야 하는 순간도 똑같은 의문이 든다. 당장 간단한 의사결정나무에서도 min_samples_leaf, max_depth를 어떻게 설정해야 가장 좋은 나무가 나올지 잘 가늠이 되지 않고 그냥 여러번 학습을 시켜보면서 정확도를 높이는 방법밖에 없다. 또 그렇게 조금씩이라도 정확도가 올라가도록 계속 파라미터를 바꾸는 과정에서도 정말 이 정확도가 높은게 좋은 모델이 맞는 건지 의심도 들었다. 실제 현업에서는 이를 어떻게 받아들이고 좋은 모델을 향해 나아가는지 궁금했다.
