📒 ReLU
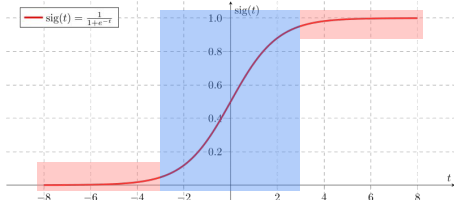
📝 Sigmoid의 단점
- Sigmoid는 양 끝 부분에서는 아주 작은 값이 나와 gradient가 소멸될 수 있다.
👉 이는 Layer가 쌓였을 때 앞 부분에서 gradient를 전파받을 수 없는 상황을 만든다.
📝 What is ReLU?
- f(x) = max(0, x) 의 간단한 점화식을 갖는다.
- 음수일 때 gradient는 0이고, 양수일 때 gradient는 1이다.

- pytorch에서는 torch.nn.relu(x)를 사용하면 된다.
📝 Optimizer
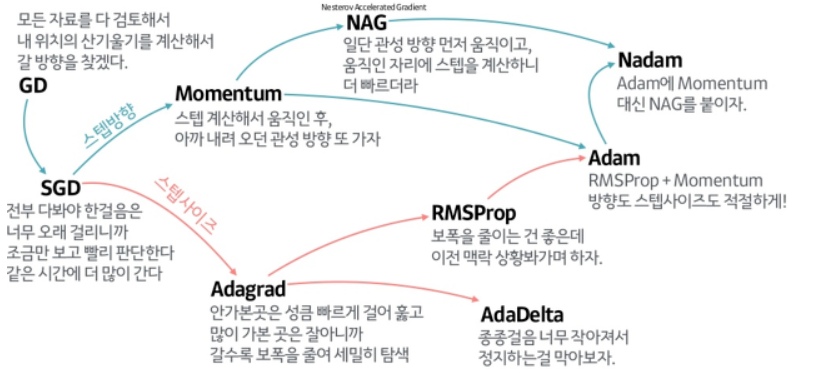
출처 : https://www.slideshare.net/yongho/ss-79607172
📒 Weight initialization
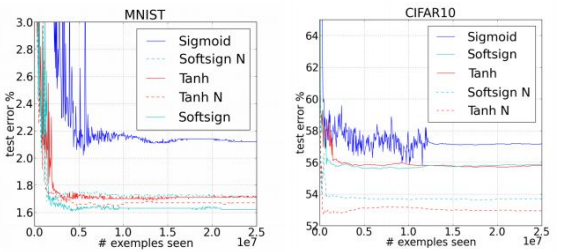
📝 Why?
- Weight initialization을 적용한 방식이 성능이 훨씬 뛰어나다.
📝 RBM / DBN
- RBM : Restricted Boltzmann Machine
- Restricted : 한 Layer 안에서의 노드끼리는 연결이 없다.
- 다른 Layer의 노드에는 모두 연결한다. (Full)
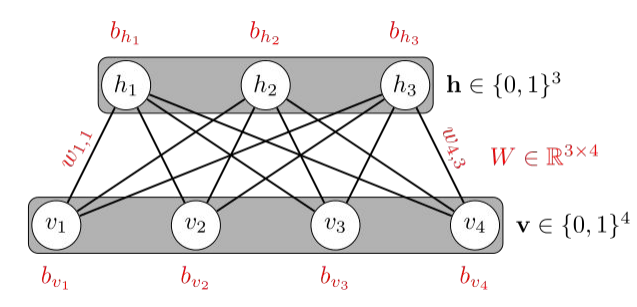
정확하게 이해를 못했다.. 이런 것이 있다는 것만 알아두고 넘어가야겠다.
📝 Xavier / He initialization
✏️ Xaview
- Normal initialization
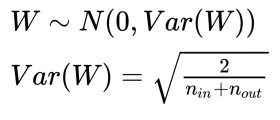
- Uniform initialization
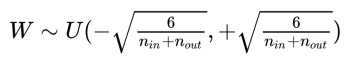
✏️ He
- Normal initialization
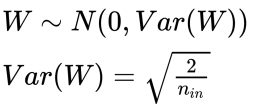
- Uniform initialization
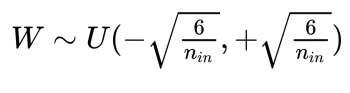
✏️ In PyTorch
linear = torch.nn.Linear(784, 256, bias=True)
torch.nn.init.xavier_uniform_(linear.weight)📒 Dropout & 배치 정규화
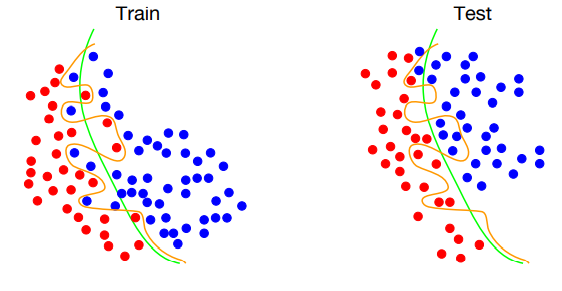
📝 Overfitting
- 너무 트레이닝 데이터에만 학습이 되어 있는 고차원의 모델

- 트레이닝 데이터셋과 테스트 데이터셋에서의 오차가 발생한다.
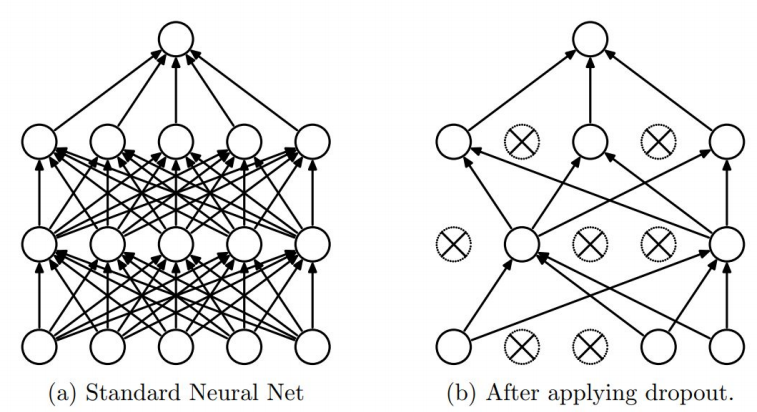
📝 Dropout
- 학습을 진행하면서 각 Layer에 존재하는 노드들을 무작위로 On / Off를 반복한다.
- 무작위로 선택된 노드들의 weight만 사용해서 다음 layer에서 전파된다.
- Overfitting을 방지할 수 있는 효과를 얻는다.
linear1 = torch.nn.Linear(784, 512, bias=True)
linear2 = torch.nn.Linear(512, 512, bias=True)
linear3 = torch.nn.Linear(512, 512, bias=True)
linear4 = torch.nn.Linear(512, 10, bias=True)
relu = torch.nn.ReLU()
dropout = torch.nn.Dropout(p=drop_prob) # p는 확률(몇 %를 drop할 지)
model = torch.nn.Sequential(linear1, relu, dropout,
linear2, relu, dropout,
linear3, relu, dropout,
linear4)
model.train() # dropout을 사용(학습)
model.eval() # dropout을 사용X(평가)📝 Batch Normalization
- Layer 간의 Internal Covariate Shift 문제를 해결하기 위해 고안되었다.
- 각 Layer들마다 Normalization을 해서 변형된 분포가 나오지 않게 작업하는 것이다.
- minibatch들마다 정규화를 실시한다.

linear1 = torch.nn.Lineare(784, 32, bias=True)
linear2 = torch.nn.Linear(32, 32, bias=True)
linear3 = torch.nn.Linear(32, 10, bias=True)
relu = torch.nn.ReLU()
bn1 = torch.nn.BatchNorm1d(32)
bn2 = torch.nn.Batchnorm1d(32)
bn_model = torch.nn.Sequential(linear1, bn1, relu,
linear2, bn2, relu,
linear3)
bn_model.train()
Beginner