📒 Pandas I
Pandas를 수업에서 써보긴 했는데, 너~무 많은 기능을 한번에 배웠다.
모두 다 정확하게 외울 필요는 없겠지만 이런 것들이 있다 정도는 익혀야 될 것 같다.
여러번씩 읽어보고, 타이핑도 해보면 금방 익힐 수 있을 것 같다.
📝 pandas
- 구조화된 데이터의 처리를 지원하는 Python 라이브러리
- pandas는 panel data를 의미한다.
- numpy와 통합하여, 강력한 스프레드시트 처리 기능을 제공한다.
- 데이터 처리 및 통계 분석을 위해 사용한다.
.png)
conda create -n venv python=3.8 # 가상환경생성
activate venv # 가상환경실행
conda install pandas # pandas 설치✏️ 데이터 로딩
import pandas as pd # 라이브러리 호출
#csv 타입 데이터 로드, separate는 빈공간으로 지정하고, Column은 없음
df_data = pd.read_csv("data_url", sep='\s+', header=None)
df_data.head(n) # 처음 m 줄 출력 (default : 5)
df_data.columns = ["ID", "NAME", "AGE"] # 데이터 Column 입력📝 Basic data
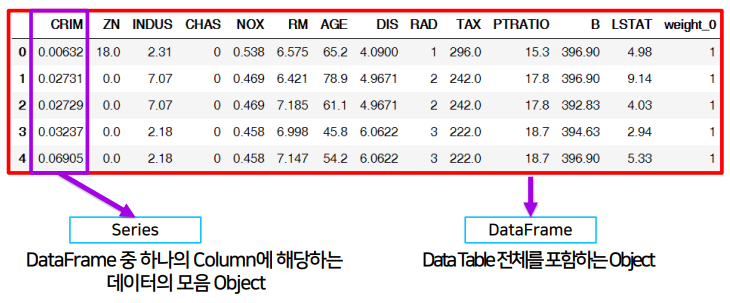
✏️ Series
- Column vector를 표현하는 object이다.
list_data = [1, 2, 3, 4, 5]
list_name = ['a', 'b', 'c', 'd', 'e']
example_obj = Series(data=list_data, index=list_name)
# index 값(모든 자료형 가능)을 갖는 data를 ndarray에 저장한다.
# dict type을 data에 넣어도 된다. 각 .index, .values로 접근- 기본적인 indexing을 지원한다. (접근, 할당)
- index가 기준이 되어, index에 없는 data는 NaN 값을 할당한다.
>>> dict_data = {'a':1, 'b':2, 'c':3}
>>> indexes = ['a', 'b', 'c', 'd', 'e']
>>> series_obj = Series(dict_data, index=indexes)
>>> series_obj
a 1.0
b 2.0
c 3.0
d NaN
e NaN
dtype: float64✏️ DataFrame
- Series를 모아서 만든 Data Table로, 기본이 2차원이다.
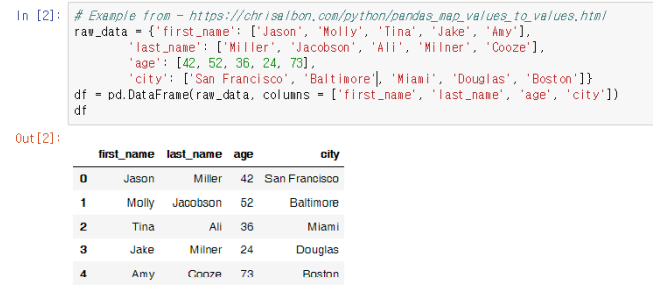
df = DataFrame(raw_data, columns =['age', 'city']) # column 선택
# 없는 column을 선택할 시, 새로운 column을 추가하며, data는 NaN으로 채운다.
df.age # == df['age'] / series를 추출한다.
df.loc[1] # index location, 인덱스의 이름
df['age'].iloc[1:] # index position, 인덱스의 번호
df.debt = df.age > 40 # 새로운 데이터를 boolean으로 할당 (다른 자료형도 가능)
df.T # transpose
df.to_csv() # csv로 변환
del df['debt'] # 메모리 주소 삭제
df.drop('debt', axis=1) # drop이 된 dataframe만 반환 (df는 안 바뀜)
df.drop(1, inplace=True) # index를 삭제시킨다.📝 Data Handling
✏️ Selection & Drop

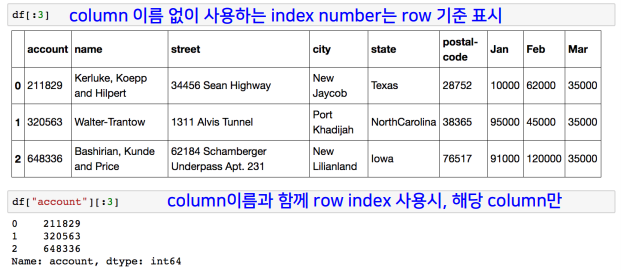
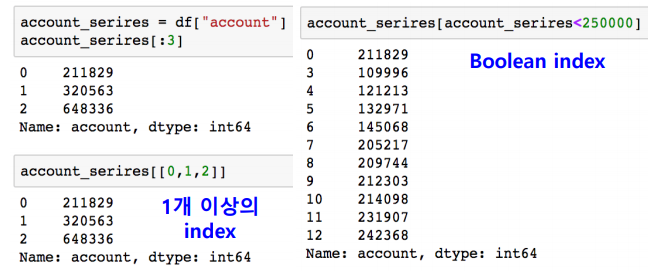
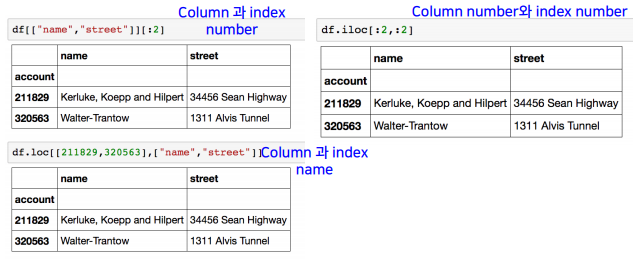

df.reset_index()를 해주면 기존의 0부터 인덱싱이 가능하다.
df.reset_index(drop=True)는 기존의 index를 없앤다.
df.reset_index(inplaece=True)는 df 자체를 변화시킬 수 있다.
✏️ Operation



📝 Pandas Function
✏️ lambda, map, apply
- series type의 데이터에도 map 함수가 사용 가능하다.
- function 대신 dict, sequence 형 자료등으로도 대체가 가능하다.
>>> s1 = Series(np.arange(10))
>>> s1.map(lambda x: x**2).head(5) # map, lambda
0 0
1 1
2 4
3 9
4 16
dtype: int64
>>> z = {1:'A', 2:'B', 3:'C'}
>>> s1.map(z).head(5)
0 NaN # dict type으로 데이터가 교체된다.
1 A # 없는 값은 NaN 상태로 만든다.
2 B
3 C
4 NaN
dtype: obejct
>>> s2 = Series(np.arange(10, 20))
>>> s1.map(s2).head(5)
0 10 # 같은 위치의 데이터를 s2로 전환한다.
1 11
2 12
3 13
4 14
dtype: int64
>>> df.sex.unique()
array(['male', 'female'], dtype=object)
>>> df['sex_code'] = df.sex.map({'male':0, 'female':1}) # 이런식으로도 사용 가능하다.- replace는 map 함수의 기능중 데이터 변환 기능만 담당한다.
>>> df.sex.replace({"male":0, "female":1}) # 데이터를 변환시켜준다.
>>> df.sex.replace(['male', 'female'], [0, 1]) # 상단 문법과 같다.- apply는 map과 달리 series 전체(column)에 해당 함수를 적용시킨다.
- series 데이터로 입력 받아 handling이 가능하다
- 내장 연산 함수인 sum, mean, std 등도 사용할 수 있다.
f = lambda x : x.max() - x.min()
df_info.apply(f)
# 각 column 별로 결과값을 반환한다.- series 값의 반환도 가능하다.
def f(x):
return Series([x.min(), x.max()], index=['min', 'max'])
df.apply(f)✏️ pandas built-in function
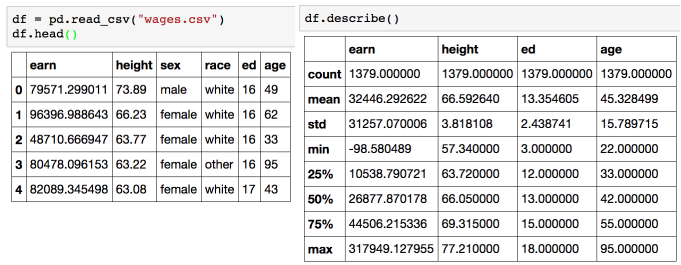
- describe : Numeric type 데이터의 요약 정보를 보여준다.
- unique : series data의 유일한 값을 list로 반환한다.

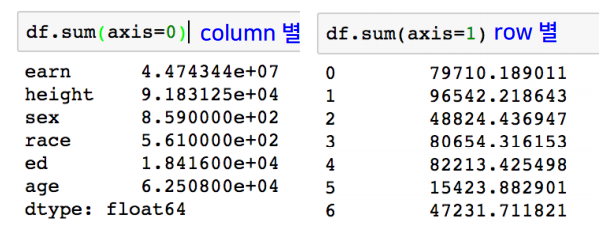
- sum : 기본적인 column 또는 row 값의 연산을 지원한다.
- sub, mean, min, max, count, median, mad, var 등 다양하다.
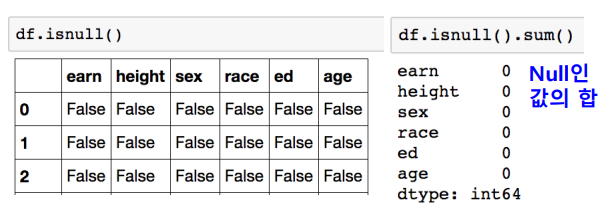
- isnull : column 또는 row 값의 NaN 값의 index를 반환한다.
- sort_values : column 값을 기준으로 데이터를 정렬한다.
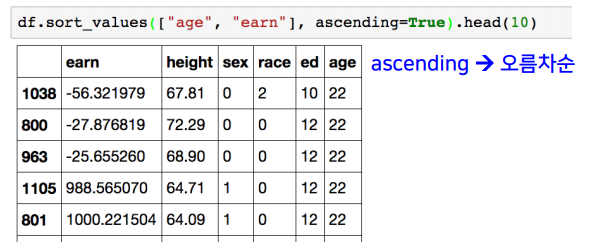
df.corr() # 모든 column간 값의 상관계수
df.col.corr(df.col2) # column 2개의 상관계수
df.col.cov(df.col2) # column 2개의 공분산
df.corrwith(df.col) # 전체 column과 특정 column의 상관계수📒 딥러닝 학습방법 이해하기
어렵단 말 밖에 할 수가 없다.
갑자기 너무 어렵고 전문적인 이론들이 쏟아져 나왔다.
대충 느낌만 이해하고 핵심적인 것들을 하나도 이해하지 못했다.
📝 신경망
- 분류 문제를 풀거나 복잡한 패턴을 가진 문제를 풀 때는 선형모델으로는 힘들다.
- Neural network(신경망)은 비선형모델이다.
- 신경망을 수식으로 분해를 하면 선형모델이 안에 숨겨져 있고, 비선형 함수들과의 결합으로 이루어져 있다.
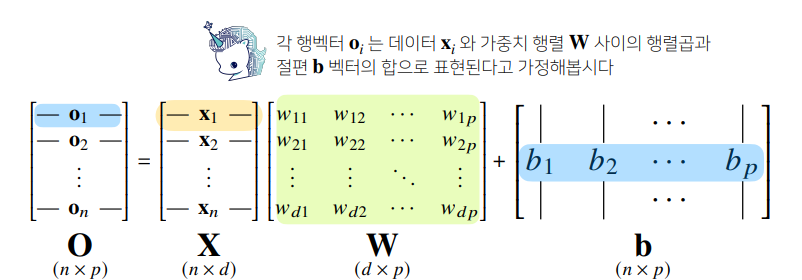
- b행렬은 y절편을 모든 행에 똑같이 복제한 벡터이다. (열은 다르다.)
- 데이터가 바뀌면 결과값도 바뀐다. 이 때 출력 벡터의 차원은 d에서 p로 바뀐다.
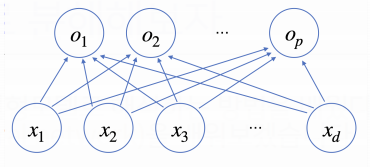
📝 소프트맥스
- 출력 벡터 o에 sofrtmax 함수를 합성하면 확률 벡터가 되므로 특정 클래스 k에 속할 확률로 해석할 수 있다.
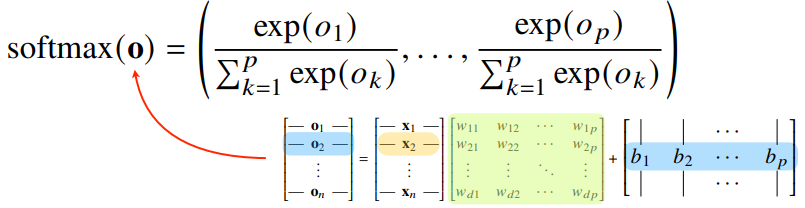
- 소프트맥스 함수는 모델의 출력을 확률로 해석할 수 있게 변환해주는 연산이다.
- 분류 문제를 풀 때 선형모델과 소프트맥수 함수를 결합하여 예측한다.
def softmax(vec):
denumerator = np.exp(vec - np.max(vec, axis=-1, keepdims=True)) # max는 오버플로우 방지
numerator = np.sum(denumerator, axis=-1, keepdims=True)
val = denumerator / numerator
return val✏️ 원-핫 벡터
- 추론을 할 때는 원-핫(one-hot) 벡터로 최대값을 가진 주소만 1로 출력하는 연산을 사용한다.
def one_hot(val, dim):
return [np.eye(dim)[_] for _ in val]
def one_hot_encodig(vec):
vec_dim = vec.shape[1]
vec_argmax = np.argmax(vec, axis=-1)
return one_hot(vec_argmax, vec_dim)📝 활성함수
- 활성함수는 오로지 해당 주소에 대한 출력값만을 계산해서 출력한다. (실수값 -> 실수값)
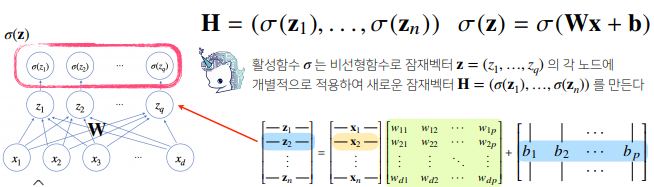
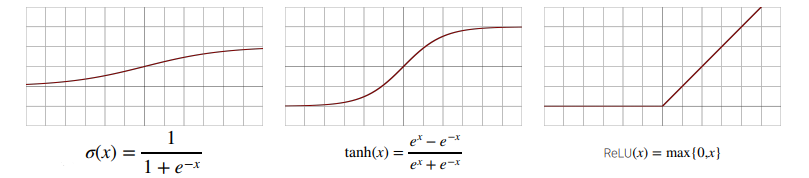
- 딥러닝에서는 시그모이드(sigmoid) 함수나 tanh 함수보다 ReLU 함수를 많이 쓰고 있다.
- 신경망은 선형모델과 활성함수(activation function)를 합성한 함수이다.
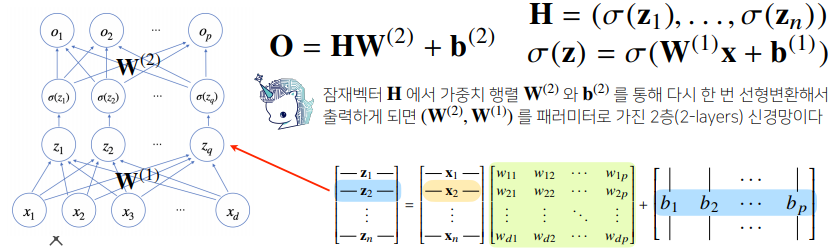
- 다층(multi-layer) 퍼셉트론(MLP)은 신경망이 여러층 합성된 함수이다.
- 층이 깊을수록 목적함수를 근사하는데 필요한 뉴런의 숫자가 훨씬 빨리 줄어들어
좀 더 효율적으로 학습이 가능하다.
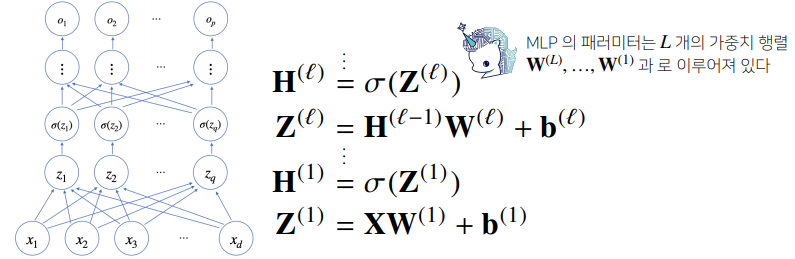
📝 역전파 알고리즘
- 딥러닝은 역전파(backpropagation) 알고리즘을 이용하여 각 층에 사용된 패러미터를 학습한다.
- 각 층 패러미터의 그레디언트 벡터는 윗층부터 역순으로 계산하게 된다.
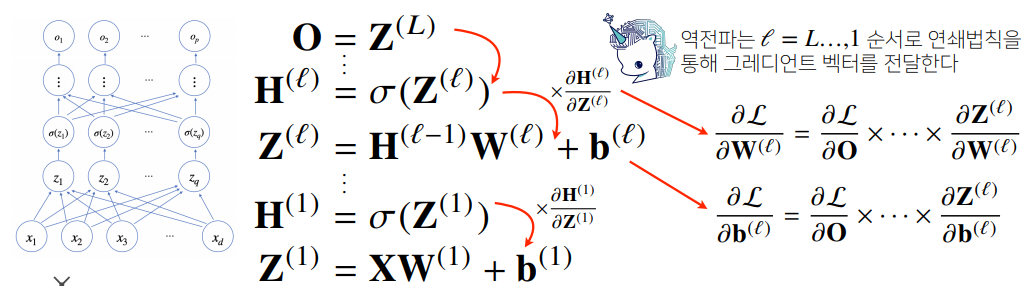
- 역전파 알고리즘은 합성함수 미분법인 연쇄법칙(chain-rule) 기반 자동미분을 사용한다.

📒 [퀴즈] 딥러닝 학습방법 이해하기- 1~5
5/5 Solve
📝 Q1
Q) ReLU(x) = max(0,x) 일 때, ReLU(-3.14) 의 값을 구하시오 (정수값으로 입력).
A) max(0, -3.14) = 0
📝 Q2
Q) tanh`(x) = d tanh(x) / dx 일 때, tanh`(0)의 값을 구하시오 (정수값으로 입력)
A) tanh`(x) = (1 + tanh(x))(1 - tanh(x)). tanh(0) = 0. -> 1
📝 Q3
Q) 다음 보기 중 역전파 (backpropagation) 알고리즘의 기반이 되는 것을 고르시오.
✔️연쇄 법칙 (chain rule)
대수의 법칙 (law of large numbers)
파레토 법칙 (Pareto principle)📝 Q4
Q) 다음 보기 중 신경망에서 활성함수가 필요한 가장 적절한 이유를 고르시오.
✔️비선형 근사를 하기 위해서.
계산복잡도를 줄이기 위해서.
수치 오차를 줄이기 위해서.📝 Q5
Q) z와 k가 다음과 같이 주어질 때, ∂z / ∂x의 값으로 올바른 것을 고르시오.
z = (k + 3)³
k = (x + y)²
✔️1. 6((x + y)² + 3)²(x + y)
2. 3((x + y)² + 3)²(x + y)
3. 6((x + y)²)²(x + y)
∂z / ∂x = (∂z / ∂k) * (∂k / ∂x) 이다.
(∂z / ∂k) = 3(k + 2)² = 3((x + y)² + 2)
(∂k / ∂x) = 2(x + y)
-> ∂z / ∂x = 6((x + y)² + 2)(x + y)
Beginner