📒 Seq2seq with Attention
직접 숫자를 예시로 넣어가면서 설명해주셔서 좋았다.
같은 내용을 반복해서 들으니 확실히 이해가 조금 더 잘 되는 것 같다.
이제 실습 코드를 여러번 읽어보면서 바닥에서부터 작성할수 있게끔 만들고싶다.
📝 Seq2seq
- 기본적으로 many to many의 구조를 갖는 모델이다. (sentence -> sentence)
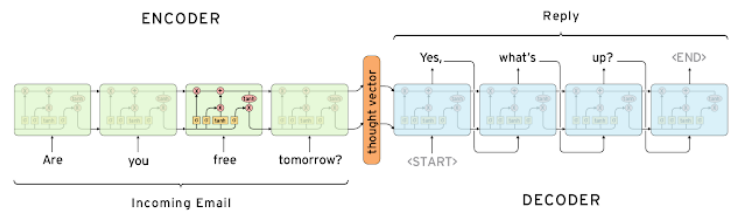
- Decoder에서는 SOS token부터 시작해서, EOS token이 나올때까지 진행한다.
📝 Attention
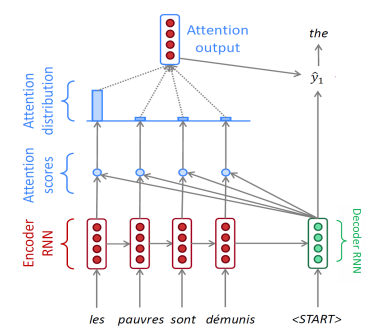
- 디코더가 인코더의 time step 별 hidden state를 필요한 곳에서 가져와서 쓴다.
- 디코더와 인코더의 hidden state의 내적에 의한 유사도를 softmax 함수에 넣어 각 state의 확률값을 이용한다.
- 각 가중치들의 가중 평균을 Attention output으로 구할 수 있다.
- 유사도를 내적뿐 아니라 다양한 방법으로 구할 수 있다.
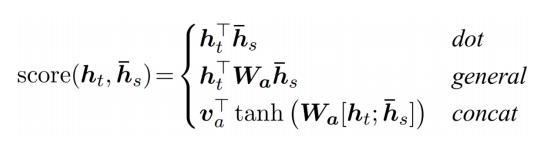
✏️ Teacher Forcing
- 디코더의 매 time step마다 예측된 값이 다음 step의 입력으로 들어가지 않게 하여 이상한 단어가 나오는걸 막아준다.
- 학습 과정에서 실제 ground truth를 입력으로 넣어준다.
📒 Beam Search and BLEU
오랜만에 강의를 보고 이해가 바로 다 됐다.
교수님이 설명을 low level에서부터 해주셔서 너무 좋았다.
연산 하나하나를 이해하고 넘어갈 수 있는 구조라 쉽게 느껴진 것 같다.
📝 Beam Search
- 자연어 생성 모델에서 test time에서 좋은 품질의 생성 결과를 얻을수 있게 하는 기법
- 하나의 단어를 잘못 생성하면 원래라면 고칠수 없다.

- 출력 문장 y에 대한 동시 사건의 확률 분포를 수식으로 쓸 수 있다.
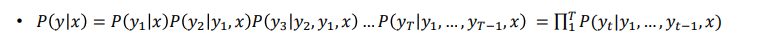
- 하지만 가능한 모든 문장의 확률을 구하는 것은 너무 비효율적이다.
👉 K개의 경우의 수를 유지하면서 구하는 것을 Beam Search라고 한다.
✏️ Flow
- Beam size k = 2 일때, 가장 확률값이 높은 두 단어를 뽑는다.
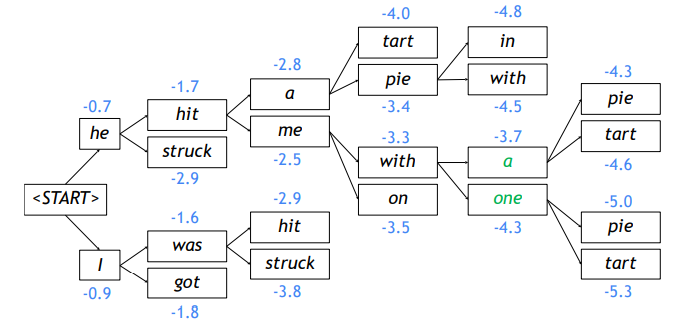
- 명시적인 EOS token 혹은 최대 timestep T 설정으로 중단할 수 있다.
- 문장이 길수록 score는 낮아지므로, 길이에 따라 정규화를 할 수 있다.
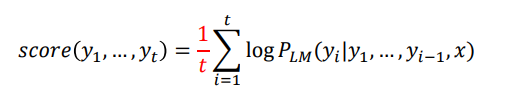
📝 BLEU score
- 자연어 생성 모델의 품질 또는 결과의 정확도를 평가하는 척도이다.

- 위 수식은 순서를 고려하지 않는 문제점이 발생한다.
👉 BLEU score는 N-gram이라 불리는 연속성을 계산하여 반영한다.
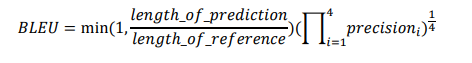

Beginner