📒 Transformer
저번주에 Transformer를 처음 들었을 때 매우 막연하게 느껴졌었다.
오늘 강의 챕터가 Transformer인 것을 보고 어려울것 같아 겁났다.
하지만 주재걸 교수님께서 정말 로우하고 디테일하게 설명해주셔서 이해가 조금 됐다.
여러번 돌려보면서 애매하게 잡힌 개념들을 채워넣어야 될 것 같다.
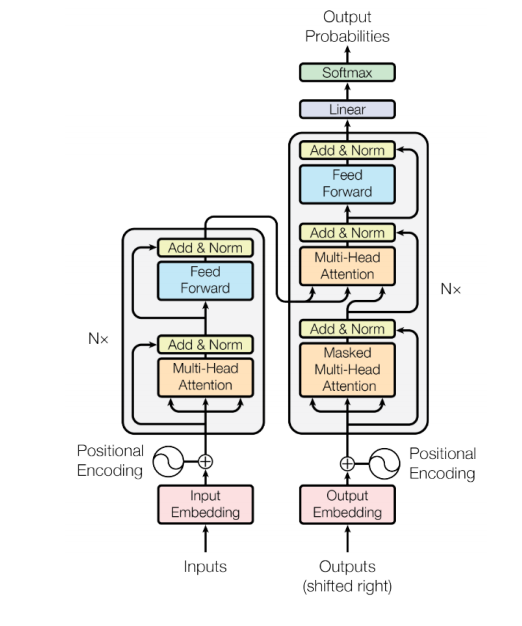
📝 Transformer
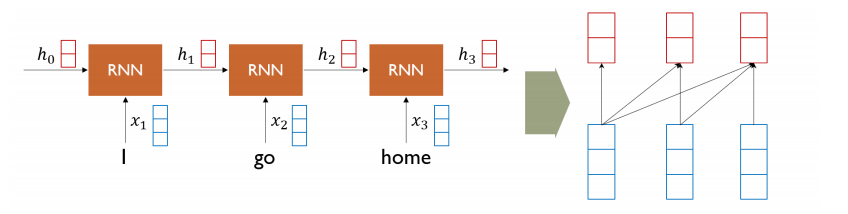
Add-on 모듈로만 사용되던 Attention을 사용해 RNN을 완전히 걷어내고 Sequence 구조를 입력받고 출력할 수 있는 모델이다.
📝 Self-Attention model
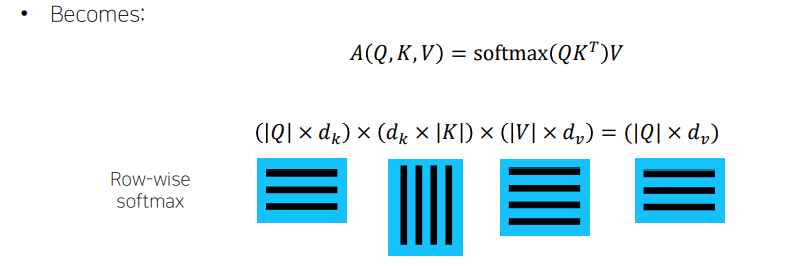
'I'라는 단어에 대한 encoding vector를 만들 때, 'I'에 대한 input vector가 seq2seq with attention의 decoder에서의 특정 time step에 hidden state vector와 같은 역할을 해서, 찾고자 하는 정보를 나타내고 있는 vector가 된다. 그 다음에 encoder에서 만들어진 hidden state vector들의 set가 주어졌을때, 각각의 vector와 내적을 해서 유사도를 구하고 softmax를 취해서 확률값으로 만들어준 후 다시 encoding vecotr에 가중치를 부여해서 가중평균을 내는 방식으로 최종적인 attention 모듈의 output vector를 계산한다.
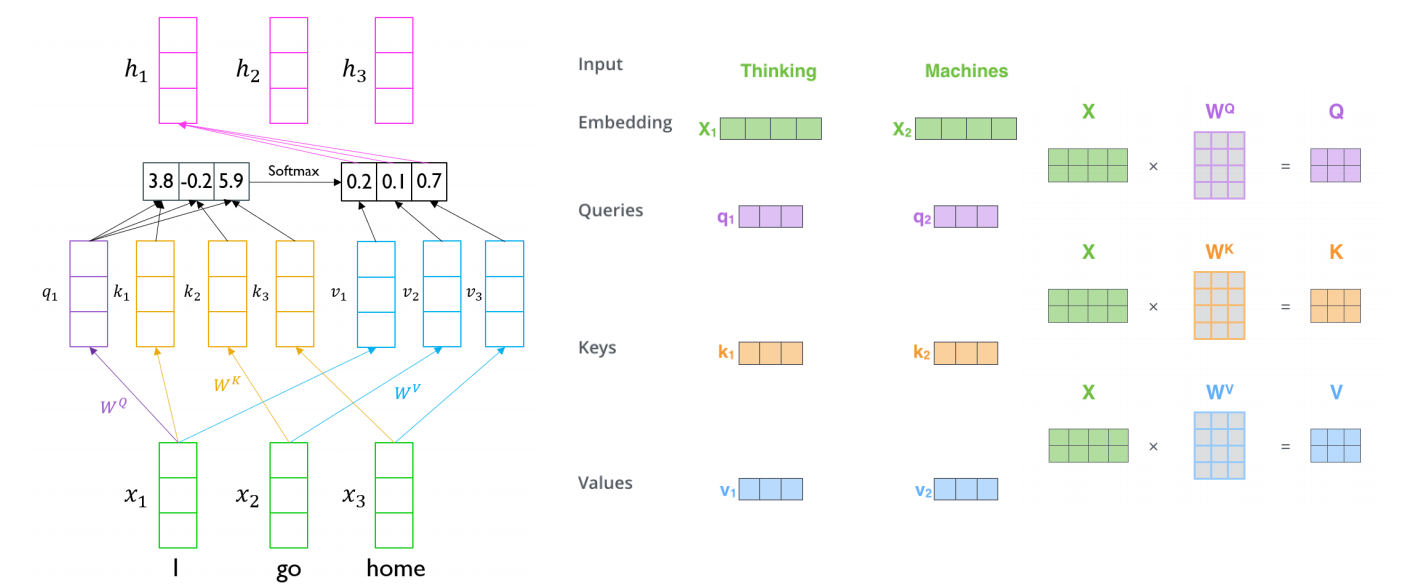
- Queries : 어느 vector를 선별적으로 가져올지에 대한 기준이 되는 vector
- Keys : 유사도가 계산되는 Queries와 내적이 되는 각각의 재료 vector
- Values : 유사도를 Softmax를 취한 후 가중 평균이 구해지는 재료 vector
'I'에 대한 word를 encoding 한다고 생각하면, 'I'는 WQ라는 matrix에 의해 q로 변환이 된다. 그리고 나머지 vector들은 WK matrix에 의해 key, WV matrix에 의해 value로 변환된다. query vecotr와 각각의 key vector를 내적하고 softmax를 취해서 가중치를 얻는다. 이는 각 value vector에 주어지는 가중치이다. 그래서 가중 평균 value vector가 나온다.

📝 Multi-Head Attention
V, K, Q를 구하기 위한 하나의 행렬 세트가 존재하는 것이 아니라, 여러 버전의 행렬들이 존재하고 여러개의 행렬을 써서 선형 변환을 한 후 Attention을 수행한 후 각 query vector에 대한 encoding vector들을 얻게 된다. 여러 개의 head들을 통해 나온 encoding vector들을 concat해서 최종 encoding vector를 얻을 수 있다.
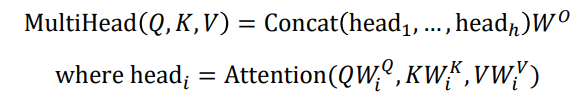
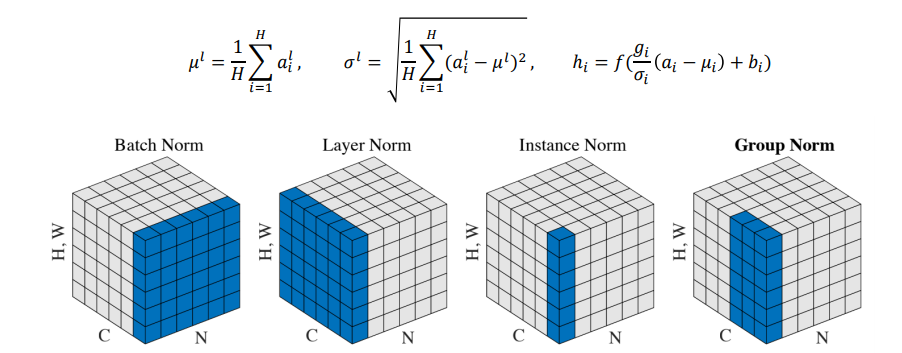
📝 Layer Normalization
딥러닝에서 다양한 Normalization이 존재한다. 기본적으로 Normalization은 주어진 다수의 sample들에 대해서 평균을 0, 분산을 1로 만들어준 후 원하는 평균과 분산을 주입할 수 있게끔 하는 선형변환으로 이루어진다.
📝 Positional Encoding
Sequence의 순서를 보장하기 위해 사용하는 기법이다. input vector에 위치의 값을 알려줄 수 있게끔 처리한다. 각 순서를 규정할 수 있는 unique한 상수 vector를 input vector의 해당 위치에 더해주는 연산을 주로 취한다.
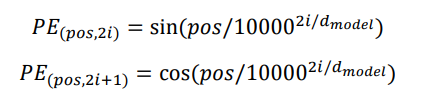
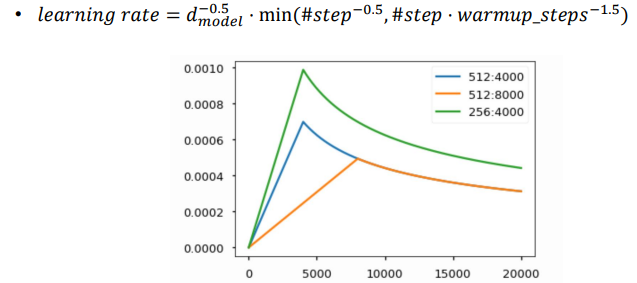
📝 Warm-up LR Scheduler
일반적인 gradient descent 과정에서 learning rate란 hyper parameter를 고정된 값으로 사용하는 것과 달리 Learning Rate Scheduler는 최종 수렴되는 함수의 목적을 높이기 위해서 learning rate를 가변적으로 변화시키는 방법이다.
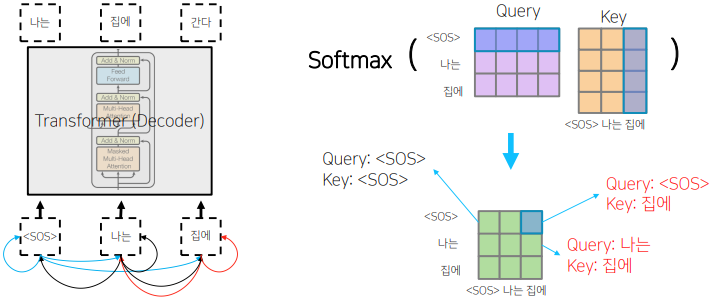
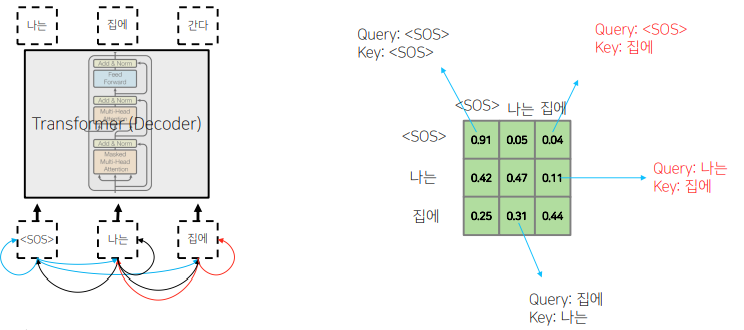
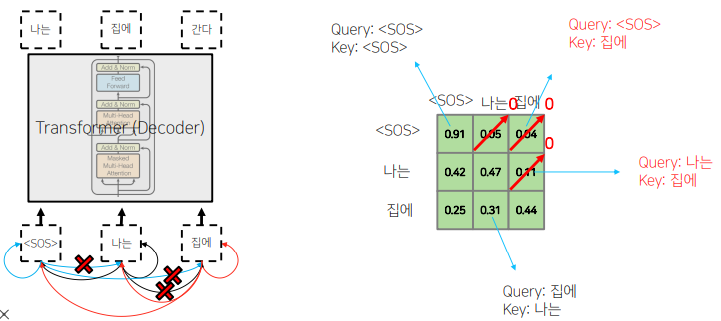
📝 Masked Self-Attention
Decoding 과정중에 입력에서 정보의 접근의 가능 여부와 관련된다. 뒤에 나오는 Attention의 가중치를 0으로 후처리하고, row의 합을 1로 만든다.