📒 Self-supervised
하루만에 감당할 수 있는 양이 아닌 것 같다.
일단 대충 정리해놨는데, 주말동안 중점적으로 공부해야 될 듯 하다.
실습 부분은 점점 어려워져서 해석하는데 너무 많은 시간이 걸린다.
선택과 집중이 필요할 것 같은데, 벌써 그래도 되나 싶다.
📝 GPT-1
Special token을 제안해서 NLP에서 많은 task들을 동시에 커버할 수 있는 통합된 모델을 제안했다. 주어진 Text에 Position Embedding을 더한 후, Self Attention Block을 총 12개 쌓은 모델이다.
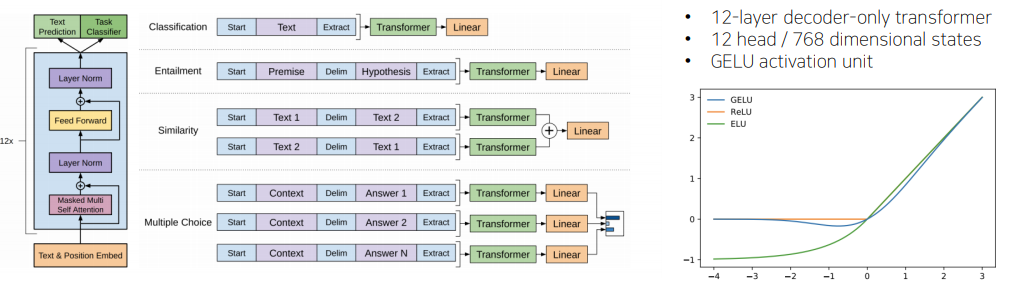
Classification 문제에서 주어진 문장이 있을 때, Transformer를 통해 word 별로 encoding을 한 후, EOS에 해당하는 Extract token만을 Linear Transformation을 통해서 다음 단어를 예측하는 task와 동시에 긍,부정에 대한 output을 예측하는 task로 사용한다.
📝 BERT
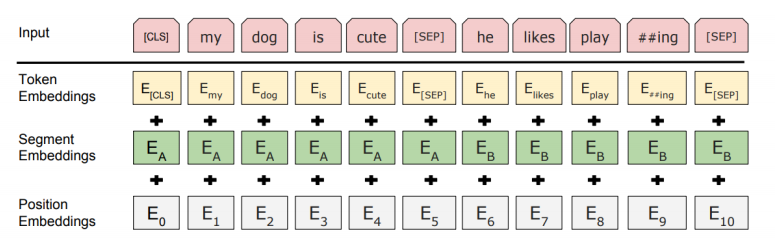
Masked Language Model을 사용하는데, 이는 각 단어를 MASK로 치환하고 MASK가 무엇인지 맞춘다. 대략 15% 정도를 MASK로 처리한다.

Subword level을 단위로 삼을 수 있는 WordPiece embedding을 사용하며, Positional Embedding도 학습에 의해 결정되게끔 두었다. CLS와 SEP token이 추가되었으며, Segment Embedding을 통해 문장 level의 index도 고려할 수 있게끔 했다.
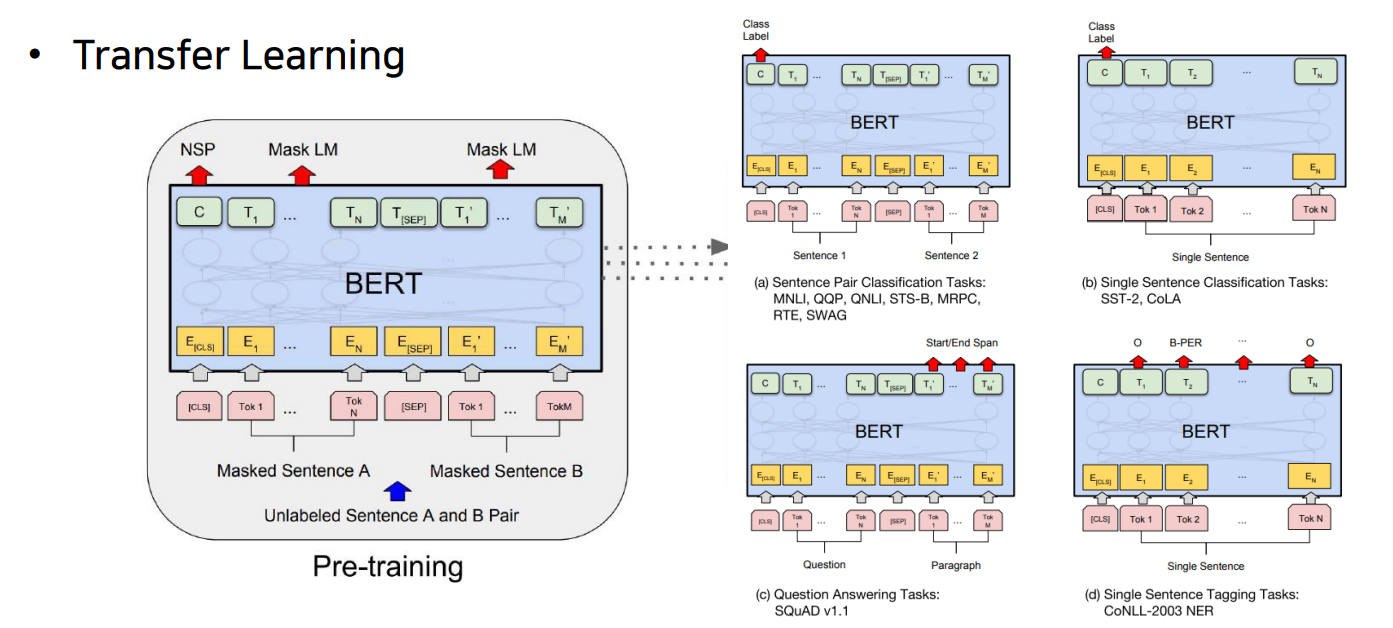
📝 GPT2, 3
다양한 task들을 자연어 생성을 통해 응답해준다. 질문에 대한 대답도 가능하며, 높은 수준의 글을 생성 가능하다. 많은 dataset을 기반으로 문장 생성을 가능하게 한다.
Subword level에서 word embedding을 도출해주고 해당 사전을 구축해줄 수 있는 Byte pair encoding를 사용했다. layer가 위로 갈수록 initialization 되는 값을 더 작은 값으로 만들어 선형 변환에 해당하는 값들이 0에 가까워지도록 하여 위쪽 layer가 하는 역할을 줄어들게끔 구성했다.
GPT3은 GPT2의 model size나 parameter의 수에 비해서 굉장히 많은 parameter를 가지도록 transformer의 self-attention block을 많이 쌓았다. 더 많은 데이터와 더 큰 batch size를 통해 성능을 증가시켰다.

📝 ALBERT
BERT 모델이 비대하다는 단점을 해결하고자 나왔다. 성능은 유지한 채 모델의 size를 낮추었다.

내일 마저 쓰겠음
