📒 그래프 기초
4학년 수업을 듣다가 신입생 수업을 듣는 기분이었다.
내용도 간단하고 아는 내용들이 많아서 오랜만에 편하게 강의를 봤다.
늘 오늘만 같았으면 좋겠지만, 지금이 태풍의 눈 속에 있는 것이 아닐까하는 생각이 든다.
몇 일 뒤 고생을 줄이기 위해 예습을 열심히 해야겠다.
📝 What?
그래프는 정점 집합과 간선 집합으로 이루어진 수학적 구조이다.
- 하나의 간선은 두 개의 정점을 연결한다.
- 모든 정점 쌍이 반드시 간선으로 직접 연결되는 것은 아니다.
- 그래프는 네트워크(Network)로도 불린다.
- 정점(Vertex)은 노드(Node), 간선은 엣지(Edge) 혹은 링크(Link)로도 불린다.
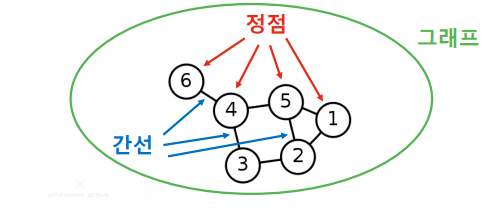
정점들의 집합을 V, 간선들의 집합을 E, 그래프를 G = (V, E)로 적는다.
정접의 이웃(Neighbor)은 그 정점과 연결된 다른 정점을 의미한다.
👉 정점 v의 이웃들의 집합을 N(v)로 적는다. N(1) = {2, 5}
방향성이 있는 그래프에서는 나가는 이웃과 들어오는 이웃을 in, out으로 구분한다.
📝 Why?
우리 주변에는 많은 복잡계(Complex System)가 있다.
- 사회, 통신 시스템, 정보와 지식, 뇌, 신체 등 다양하다.
- 복잡계는 구성 요소 간의 복잡한 상호작용을 갖고 있다.
👉 그래프로 복잡계를 효과적으로 표현하고 분석할 수 있다.
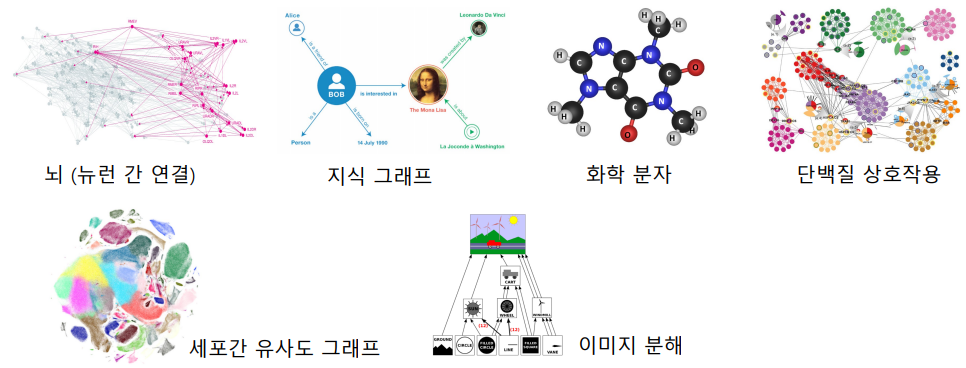
정점 분류(Node Classfication), 연결 예측(Link Prediction), 추천(recommendation), 군집 분석(Community Detection), 랭킹(Ranking), 정보 검색(Information Retrieval), 정보 전파(Information Cascading), 바이럴 마케팅(Viral Marketing) 등 다양한 문제에 적용시킬 수 있다.
📝 Kind
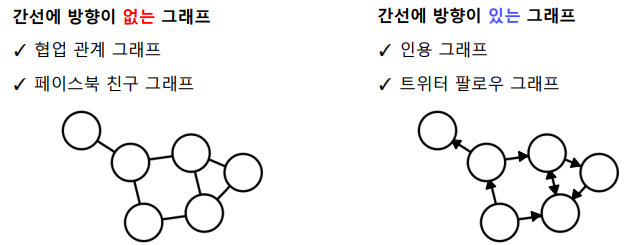
- 방향이 없는(양방향) Undirected Graph와 방향이 있는 Directed Graph로 나뉜다.
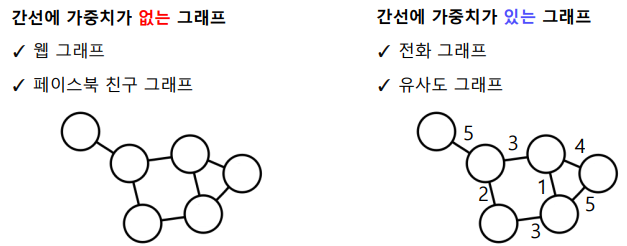
- 가중치가 없는 Unweighted Graph와 가중치가 있는 Weighted Graph로 나뉜다.
- 정점의 종류에 따라 Unpartite Graph와 Bipartite Graph로 나뉜다.
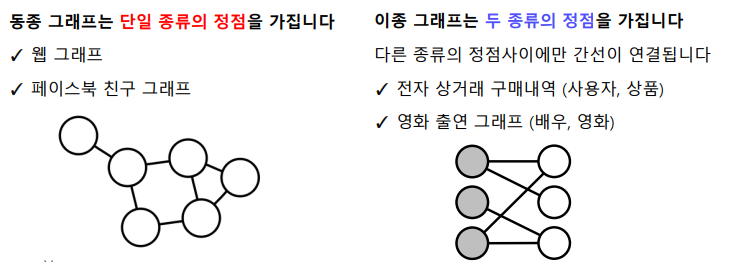
📝 NetworkX
파이썬의 라이브러리인 NetworkX를 이용하여 그래프를 생성, 변경, 시각화할 수 있다.
그래프의 구조와 변화 역시 살펴볼 수 있다.
- 간선 리스트(Edge List) : 그래프를 간선들의 리스트로 저장한다.
- 각 간선은 해당 간선이 연결하는 두 정점들의 순서쌍(Parir)으로 저장된다.
- 방향성이 있는 경우에는 (출발점, 도착점) 순서로 저장된다.
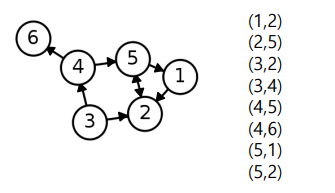
- 인접 리스트(Adjacency List) : 각 정점의 이웃들을 리스트로 저장한다.
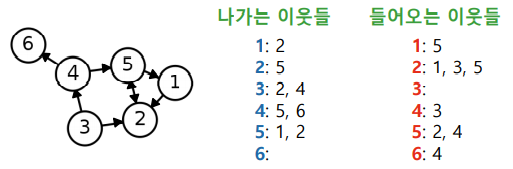
- 인접 행렬(Adjacency Matrix) : 정점 수 X 정점 수 크기의 행렬으로, i행 j열의 원소로 간선을 표기한다.
- 일반 행렬은 전체 원소를 저장하여 정점 수의 제곱에 비례하는 저장 공간을 사용한다.
- 희소 행렬은 0이 아닌 원소만을 저장하므로 간선의 수에 비례하는 저장 공간을 사용한다.
# 그래프를 인접 리스트로 저장
nx.to_dict_of_lists(G)
# 그래프를 간선 리스트로 저장
nx.to_edgelist(G)
# 그래프를 인접 행렬(일반 행렬)롤 저장
nx.to_numpy_array(G)
# 그래프를 인접 행렬(희소 행렬)로 저장
nx.to_scipy_sparse_matrix(G)📒 실제 그래프
한국어로 가득차 있어 개념의 이름을 들었을때는 모두 낯설었다.
하지만 내용 자체는 크게 어렵지 않았다.
각 정의들을 NetworkX에서 가져오는 법에 익숙해지는 것이 중요할 것 같다.
📝 실제 그래프 VS 랜덤 그래프
실제 그래프(Real Graph)란 다양한 복잡계로부터 얻어진 그래프를 의미한다.
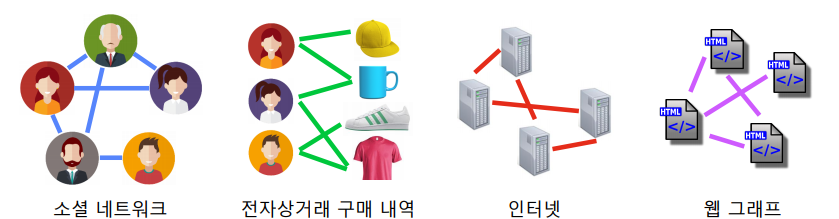
랜덤 그래프(Random Graph)는 확률적 과정을 통해 생성한 그래프를 의미한다.
✏️ 에르되스-레니 랜덤 그래프
임의의 두 정점 사이에 간선이 존재하는지 여부는 동일한 확률 분포에 의해 결정된다.
에르되스-레니 랜덤그래프 G(n, p)는 n개의 정점을 가지며, 두 정점 사이에 간점이 존재할 확률은 p이다. 이 때, 정점 간의 연결은 서로 독립적이다.
- G(3, 0.3) 그래프는 다음과 같은 확률을 갖는다.
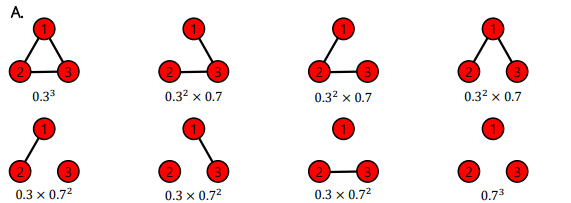
📝 작은 세상 효과
-
정점 u와 v 사이의 경로(Path)는 아래 조건을 만족하는 정점들의 순열이다.
- u에서 시작해서 v에서 끝나야 한다.
- 순열에서 연속된 정점은 간선으로 연결되어 있어야 한다.
-
경로의 길이는 해당 경로 상에 놓이는 간선의 수로 정의된다.
-
정점 u와 v 사이의 거리(Distance)는 u와 v 사이의 최단 경로의 길이이다.
-
그래프의 지름(Diameter)은 정점 간 거리의 최댓값이다.
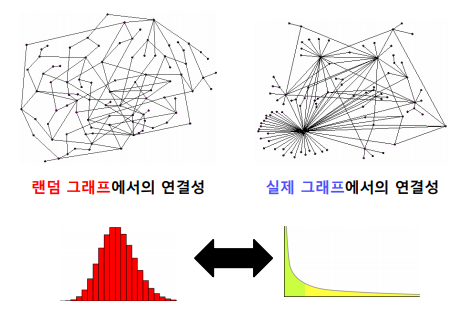
작은 세상 효과는 실제 그래프에서 임의의 두 정점 거리의 거리가 작음을 의미한다. 평균적으로 6번의 지인을 거치면 모든 사람과 연결될 수 있다는 의미이다. 이는 높은 확률로 랜덤 그래프에도 존재한다. 개인이 100명의 지인을 갖는다면, 5번 거치면 100^5인 100억명의 사람들과 연결될 수도 있다. 하지만 아래의 그래프의 모양을 갖는다면 작은 세상 효과는 성립하지 않는다.
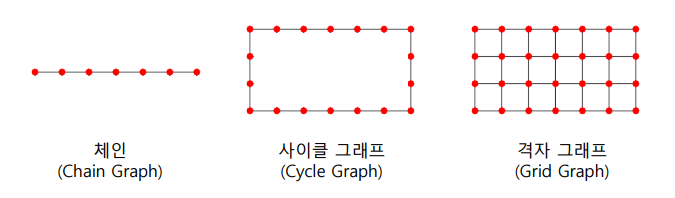
📝 연결성의 두꺼운 꼬리 분포
정점의 연결성(Degree)은 그 정점과 연결된 간선의 수를 의미한다. 즉, 정점 v의 연결성은 해당 정점의 이웃들의 수와 같다. 보통 정점 v의 연결성은 d(v) 혹은 | N(v) | 로 표기한다.
방향성이 있는 그래프는 나가는 연결성(Out Degree)와 들어오는 연결성(In Degree)로 구분한다.
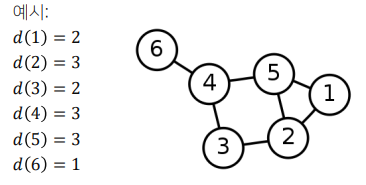
실제 그래프의 연결성 분포는 정규 분포가 아닌 두터운 꼬리(Heavy Tail)를 갖는다. 즉, 연결성이 매우 높은 허브(Hub) 정점이 존재함을 의미한다.
반면 랜덤 그래프의 연결성 분포는 높은 확률로 정규 분포와 유사하다. 연결성이 매우 높은 허브 정점이 존재할 가능성은 0에 가깝다. 예시로는 키의 분포가 있다.
📝 거대 연결 요소
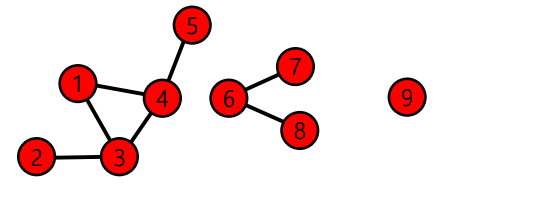
연결 요소(Connected Component)는 다음 조건들을 만족하는 정점들의 집합을 의미한다.
- 연결 요쇼에 속하는 정점들은 경로로 연결될 수 있다.
- 1의 조건을 만족하면서 정점을 추가할 수 없다.
다음 그래프에서는 {1, 2, 3, 4, 5}, {6, 7, 8}, {7, 8, 9} 3개의 연결 요소를 갖는다.
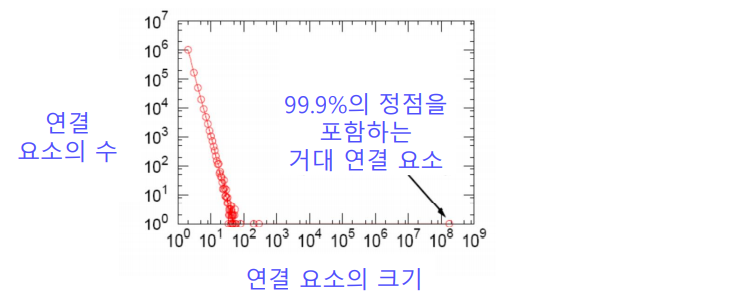
실제 그래프에서는 거대 연결 요소(Giant Connected Component)가 존재한다. 거대 연결 요소는 대다수의 정점을 포함하고 있다.
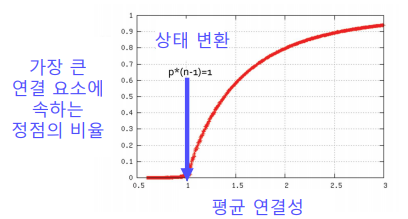
랜덤 그래프에도 높은 확률로 거대 연결 요소가 존재한다. 단, 정점들의 평균 연결성이 1보다 충분히 커야 한다.
📝 군집 구조
군집(Community)이란 다음 조건들을 만족하는 정점들의 집합이다.
- 집합에 속하는 정점 사이에는 많은 간선이 존재한다.
- 집합에 속하는 정점과 그렇지 않은 정점 사이에는 적은 수의 간선이 존재한다.
지역적 군집 계수(Local Clustering Coefficient)는 한 정점에서 군집의 형성 정도를 측정한다. 다만 연결성이 0인 정점에서는 지역접 군집 계쑤가 정의되지 않는다.
- 정점 i의 지역적 군집 계수는 정점 i의 이웃 쌍 중 간선으로 직접 연결된 것의 비율을 의미한다.
- 정점 i의 지역적 군집 계수를 Ci로 표현한다.
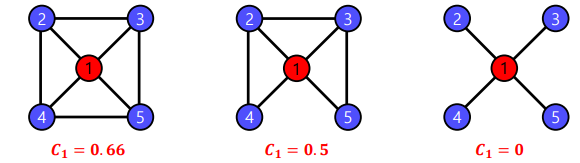
정점 i의 지역적 군집 계수가 매우 높으면 정점 i의 이웃들도 높은 확률로 서로 간선으로 직접 연결되어 있다. 즉, 정점 i와 그 이웃들은 높은 확률로 군집을 형성한다.
전역 군집 계수(Global Clustering Coefficient)는 전체 그래프에서 군집의 형성 정도를 측정한다. 그래프 G의 전역 군집 계수는 각 정점에서의 지역적 군집 계수의 평균이다. 단, 지역적 군집 계수가 정의되지 않는 정점은 제외한다.
실제 그래프에서는 군집 계수가 높다. 즉, 많은 군집이 존재한다. 이는 서로 유사한 정점끼리 간선으로 연결될 가능성이 높다는 동질성, 공통 이웃이 매개 역할을 해줄 수 있다는 전이성이 원인이 된다.
랜덤 그래프 G(n, p)에서의 군집 계수는 p이다.
