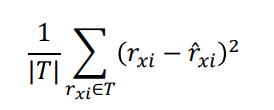📒 군집 탐색
다양한 군집 탐색 알고리즘을 배웠다.
대부분 브루트포스 느낌이라 구현이 크게 어렵지는 않을 것 같다.
networkX에서 굉장히 많은 함수를 지원하는 것 같다.
알아놓으면 언젠가는 쓸 일이 오지 않을까 싶다.
📝 군집
군집(Community)이란 다음 조건들을 만족하는 정점들의 집합이다.
- 집합에 속하는 정점 사이에는 많은 간선이 존재한다.
- 집합에 속하는 정점과 그렇지 않은 정점 사이에는 적은 수의 간선이 존재한다.
온라인 소셜 네트워크의 군집들은 사회적 무리(Social Circle)을 의미하는 경우가 많다.
📝 군집 탐색
그래프를 여러 군집으로 잘 나누는 문제를 군집 탐색(Community Detection) 문제라고 한다. 보통의 각 정점이 한 개의 군집에 속하도록 군집을 나눈다. 비지도 기계학습 문제인 클러스터링(Clustering)과 상당히 유사하다.
성공적인 군집 탐색을 정의하기 위해 배치 모형(Configuration Model)이 필요하다. 주어진 그래프에 대한 배치 모형은, 각 정점의 연결성을 보존한 상태에서 간선들을 무작위로 재배치하여 얻은 그래프를 의미한다. 배치 모형에서 임의의 두 정점 i와 j 사이에 간선이 존재할 확률은 두 정점의 연결성에 비례한다.
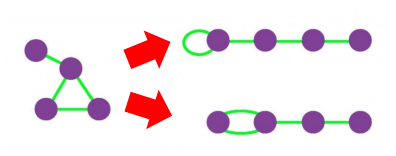
군집 탐색의 성공 여부를 판단하기 위해서, 군집성(Modularity)이 사용된다.

군집성은 무작위로 연결된 배치 모형과의 비교를 통해 통계적 유의성을 판단한다. 이는 -1과 +1 사이의 값을 갖는다. 보통 군집성이 0.3 ~ 0.7 정도의 값을 가질 때, 통계적으로 유의미한 군집들을 찾았다고 할 수 있다.
📝 군집 탐색 알고리즘
✏️ Girvan-Newman
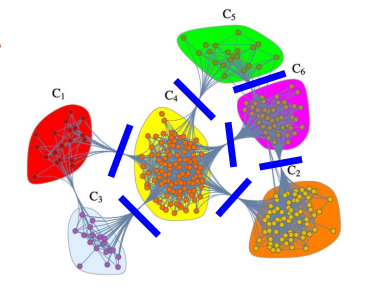
대표적인 Top-Down 군집 탐색 알고리즘이다. 이는 전체 그래프에서 탐색을 시작한다. 군집들이 서로 분리되도록, 서로 다른 군집을 연결하는 다리(Bridge) 역할의 간선을 순차적으로 제거한다.
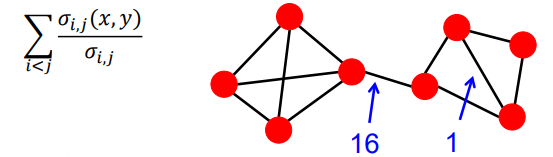
간선의 매개 중심성(Betweenness Centrality)을 사용하여 Bridge를 찾는다. 이는 해당 간선이 정점 간의 최단 경로에 놓이는 횟수를 의미한다.
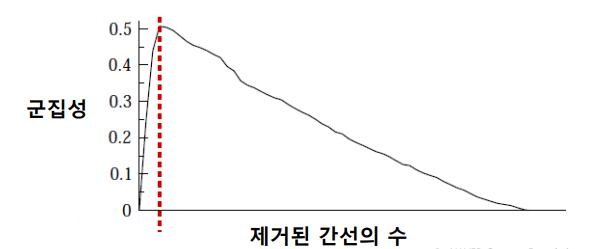
간선이 제거될 때마다, 매개 중심성을 다시 계산하여 갱신하고 높은 간선을 제거하는 과정을 반복한다. 이 때, 간선의 제거 정도에 따라서 다른 입도(Granularity)의 군집 구조가 나타난다.
군집성을 기준으로 제거하는 정도를 결정한다. 즉, 군집성이 최대가 되는 지점까지 간선을 제거한다. 단, 현재의 연결 요소들을 군집으로 가정하되, 입력 그래프에서 군집성을 계산한다.
✏️ Louvain
대표적인 Bottom-Up 군집 탐색 알고리즘이다. 이는 개별 정점에서 시작해서 점점 큰 군집을 형성한다.
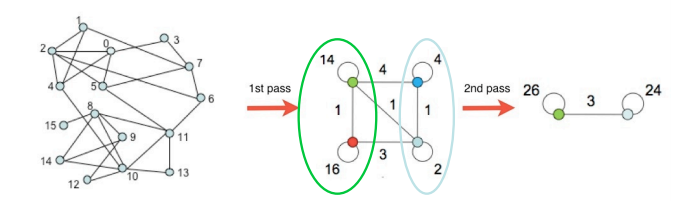
군집을 합칠때는, 군집성을 기준으로 한다. 동작 과정은 다음과 같다.
- 개별 정점으로 구성된 크기 1의 군집들로부터 시작한다.
- 각 정점 u를 군집성이 최대화되도록 기존 혹은 새로운 군집으로 이동한다.
- 더 이상 군집성이 증가하지 않을 때까지 2를 반복한다.
- 각 군집을 하나의 정점으로하는 군집 레벨의 그래프를 얻은 뒤 3을 수행한다.
- 한 개의 정점이 남을 때까지 4를 반복한다.
📝 중첩이 있는 군집 탐색
실제 그래프의 군집들은 중첩되어 있는 경우가 많다.
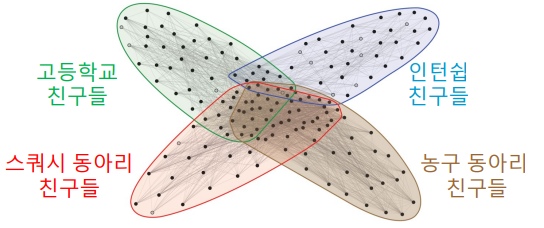
이를 위해 아래와 같은 중첩 군집 모형을 가정한다.
- 각 정점은 여러 개의 군집에 속할 수 있다.
- 각 군집 A에 대하여, 같은 군집에 속하는 두 정점은 PA 확률로 간선으로 직접 연결된다.
- 두 정점이 여러 군집에 동시에 속할 경우 간선 연결 확률은 독립적이다.
- 어느 군집에도 함께 속하지 않는 두 정점은 낮은 확률으로 직접 연결된다.
중첩 군집 모형이 주어지면, 주어진 그래프의 확률을 계산할 수 있다. 이는 두 확률의 곱이다.
- 그래프의 각 간선의 두 정점이 직접 연결될 확률
- 그래프에서 직접 연결되지 않은 각 정점 상이 직접 연결되지 않을 확률
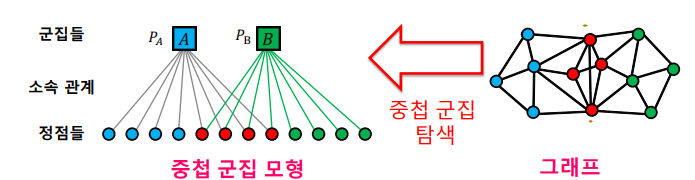
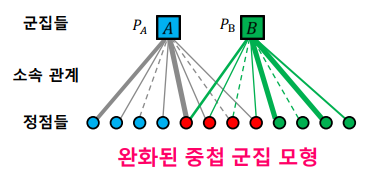
중첩 군집 탐색은 주어진 그래프의 확률을 최대화하는 중첩 군집 모형을 찾는 과정이다. 최우도 추정치(Maximum Likelihood Estimate)를 찾는 과정과 동일하다.
이를 용이하게 하기 위해 완화된 중첩 군집 모형을 사용한다. 여기서는 각 정점이 각 군집에 속해 있는 정도를 실숫값으로 표현한다. 즉, 기존 모형에서는 binary였는데 중간 상태를 표현할 수 있다. 최적화 도구를 사용하여 모형을 탐색할 수 있다는 장점을 갖는다.
📒 추천 시스템
📝 내용 기반 추천 시스템
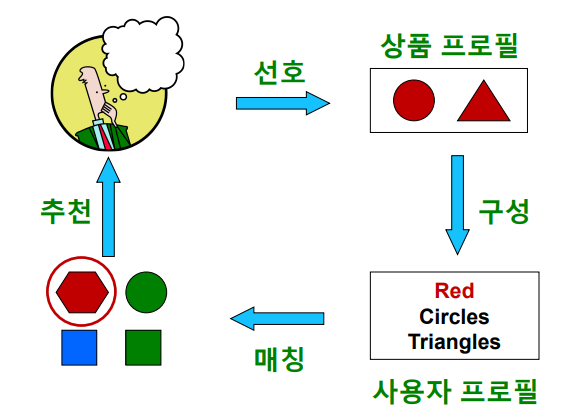
내용 기반(Content-based) 추천은 각 사용자가 구매/만족했던 상품과 유사한 것을 추천하는 방법이다.
첫 단계는 사용자가 선호했던 상품들의 상품 프로필(Item Profile)을 수집한다.
어떤 상품의 상품 프로필이란, 해당 상품의 특성을 나열한 벡터이다.
영화의 경우 감독, 장르, 배우 등의 one-hot encoding이 상품 프로필이 될 수 있다.
다음 단계는 사용자 프로필(User Profile)을 구성한다.
이는 사용자가 선호한 상품의 상품 프로필을 선호도를 사용하여 가중 평균하여 벡터로 계산한다.
마지막으로 사용자 프로필과 다른 상품들의 상품 프로필을 매칭한다.
사용자 프로필 벡터와 상품 프로필 벡터의 코사인 유사도가 높은 상품을 추천한다.
내용 기반 추천 시스템은 다음과 같은 장점을 갖는다.
- 다른 사용자의 구매 기록이 필요하지 않다.
- 독특한 취향의 사용자에게도 추천이 가능하다.
- 새 상품에 대해서도 추천이 가능하다.
- 추천의 이유를 제공할 수 있다.
반면 다음과 같은 단점을 갖는다.
- 상품에 대한 부가 정보가 없는 경우에는 사용할 수 없다.
- 구매 기록이 없는 사용자에게는 사용할 수 없다.
- Overfitting으로 지나치게 협소한 추천을 할 위험이 있다.
📝 협업 필터링
내용 기반 추천시스템의 단점을 보완한 사용자-사용자 협업 필터링은 다음 세 단계로 이루어진다.
- 추천의 대상 사용자를 x라고 하고, x와 유사한 취향의 사용자들을 찾는다.
- 유사한 취향의 사용자들이 선호한 상품을 찾는다.
- 이 상품들을 x에게 추천한다.
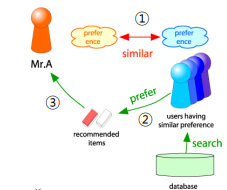
취향의 유사성은 상관 계수(Correlation Coefficient)를 통해 측정한다.

취향의 유사도를 가중치로 사용한 평점의 가중 평균을 통해 평점을 추정할 수 있다.

협업 필터링은 상품에 대한 부가 정보가 없는 경우에도 사용할 수 있다.
다만, 충분한 수의 평점 데이터가 누적되어야 효과적이며, 새 상품과 새 사용자에 대한 추천이 불가능하다. 그리고 독특한 취향을 갖는 사용자에게 추천이 어렵다.
📝 평가
우선, 주어진 데이터를 훈련 데이터와 평가 데이터로 분리한다. 그리고 평가 데이터는 주어지지 않았다고 가정한 뒤, 훈련 데이터를 이용해서 평가 데이터의 평점을 추정한다. 마지막으로 추정한 평점과 실제 평가 데이터를 비교하여 오차를 측정한다.
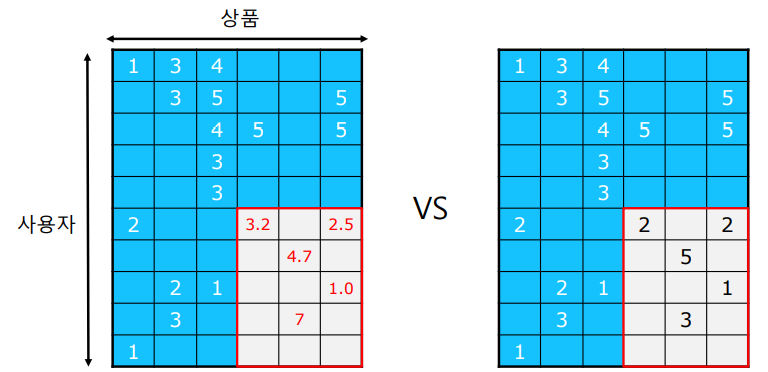
일반적으로 MSE를 사용하여 오차를 측정한다. (루트를 씌운 RMSE도 많이 사용된다.)