Data Analysis
Data preprocessing
: to prepare raw data in a suitable format in order to use for further analysis
1) Data Collection & Profiling - import data
2) Data check - to make a hypothesis, which data should be considered
3) Data cleansing - removing unnecessary fields , filling missing fields
Activity 1 - data correlation
hypothesis:
The rich passengers had a higher survival rate in the RMS Titanic.
- 'Fare' field is related to survival rate
- 'Pclass' field also is related to survival rate
Analyzing the data correlation
To validate the hypothesis using sample data
=> Visualize data -> create table & chart about the correlation between data
=> check 'Pclass' and 'Fare' fields to validate the hypothesis
(If the hypothesis is not correct, we should consider: what factors affected the survival of the RMS Titanic.)
@Note: only leave the reference field and remove other field to find the most influencial factor. The reference field would be survival rate('survived').
@Note: When assessing correlation, the higher the absolute value, the more effect on the result.
Positive num - As one factor increases, other factors also increase
Negative num - As one factor increases, other factors decrease
Analyzing result
When analyzing the data, it becomes evident that the 'Sex' factor is the most influential factor.
Based on the provided data, it is apparent that women had a higher survival rate compared to men. Additionally, it shows that the higher the fare paid and the purchase price for the seat, the greater the chance of survival. However, it's important to note that these factors are related to the survival rate but are not as high as gender.
! Hypothesis:
The rich passengers had a higher survival rate in the RMS Titanic.
- Fare field is related to survival rate (TRUE)
- Pclass field also is related to survival rate (TRUE)
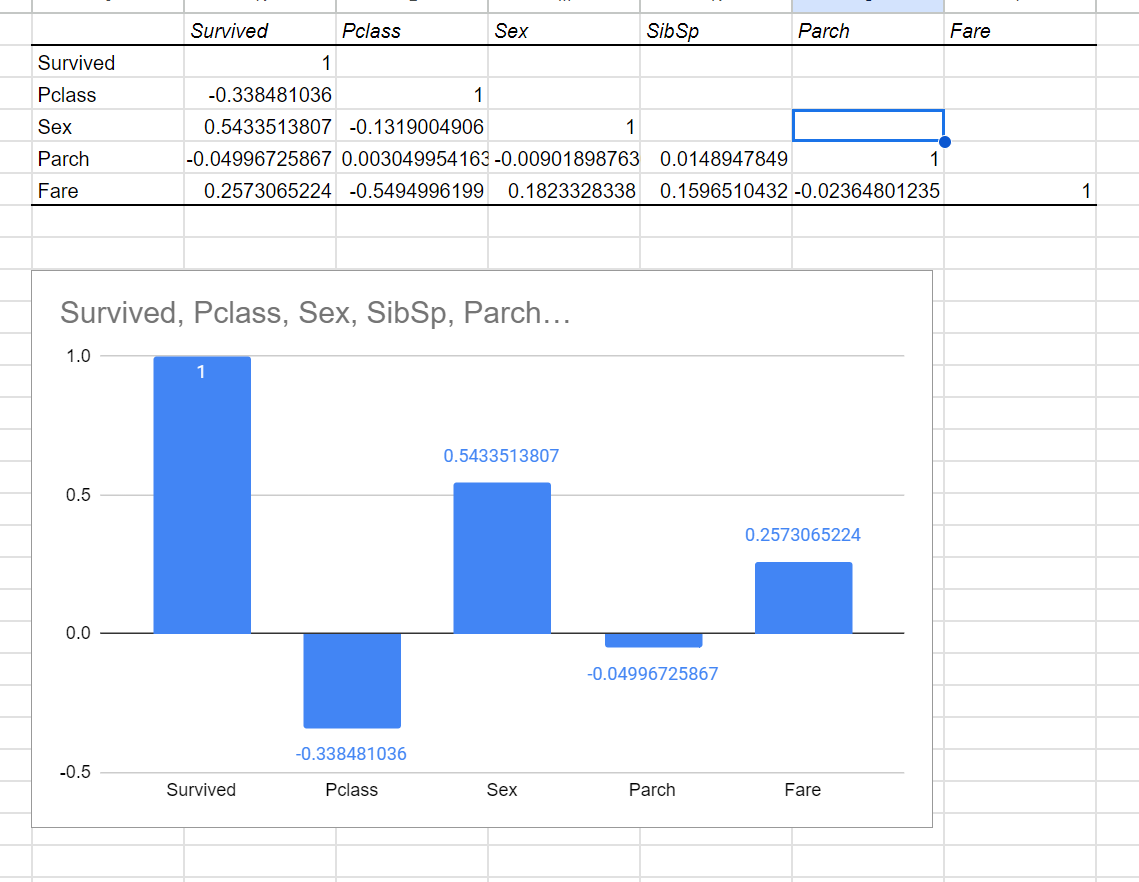 (the higher price, the lower seat class)
(the higher price, the lower seat class)
Python
-can quickly create and manage data structures
-enable to analyze complicated data set
-used for data analysis, data visualization
-some of python libraries: pandas, matplotlib
@Note:
Pandas
- can read data files with different format (ex) image, sound file...)
- can filter, cut and combine data
- can remove faulty data
Matplotlib
- can visualize data
Today I learned ,
-The concept of data preprocessing
-The process of representing data visually
-The basics of Python for data analysis
