
👀 1. 들어가면서
지난 글에서는 조달청에서 개방하는 공공데이터로 B2G사업 참여 의사결정에 도움이 되는 대시보드를 개발 한 내용을 다뤘습니다. 비즈니스이기 때문에 빠르게 완성 하는 게 중요해서 시도해보지 못한 아쉬운 부분을, 퇴근 후 스터디해서 개선 한 경험을 소개합니다.
1.1. 문제 상황
동일한 사업이 매년 공고가 나오는 경우가 있습니다. 대시보드를 만들 때 요구사항 중 한가지가, 매년 발주되는 '연속 사업'을 확인하여 올해 예상되는 사업 리스트를 뽑은 뒤 미리 대응하는 것이었는데요. 예를들어 서울시에서 '카드 데이터 구매사업'이 20년, 21년, 22년 3년 연속 발주된다는 것을 파악한다면 23년에도 동일한 사업이 발주될 것을 예상할 수 있고 미리 대응할 수 있겠죠!
- '동일한 사업 일 경우 공고명이 같을 것이다'는 가정을 하고, '공고명'을 기준으로 GROUP BY해서 COUNT해준뒤, COUNT값이 2개 이상인 경우 '연속사업'으로 보고 연속사업이 몇 개인지 파악했습니다.
- 파악 한 결과, '연속사업' 비중이 매우 낮게 나왔습니다. '연속사업'으로 분류 된 '공고명'을 확인했는데, 제가 알고 있던 연속 사업 몇개가 누락돼 있었습니다. '동일한 사업이더라도 공고명이 다를 수 있겠다'는 생각에, 몇개 사업을 다시 확인해봤습니다.
- 그 결과, '띄어쓰기'가 다르거나 '연도' 등이 앞에 붙어서 실제로는 같은 사업이지만, 다른 사업으로 분류 되는 경우가 존재했습니다.
(ex. 2020년 카드 데이터구매, 2021년 카드 데이터 구매 → 실제로 같은 사업인데 연도와 띄어쓰기 때문에 동일하다고 분류 안됨)
1.2. 해결 방안
'동일한 사업이더라도 공고명이 다를 수 있다'는 문제를 해결하기 위해 두가지 방안을 실행했습니다. 그 결과, 전체 사업 중 '연속사업' 비중이 약 20%로 상승했습니다.
- ⓐ 띄어쓰기를 제거 한다.
- ⓑ 연도 등 공고명에 포함된 CASE들을 불용어 dictionary로 만들어, 제거해준다.
그런데 이 두가지 외에도 '동일한 사업이더라도 공고명이 다를 수 있게' 만드는 경우는 아래 예시 처럼 더 존재합니다.

위와 같은 경우도 잡아내서, '연속사업'비중을 더 높이면 사업실에서 대응 할 만한 사업이 더 늘어 날 거라고 생각했습니다. 어떻게 높일 수 있을까 고민하다가 이 과업과 전혀 관련 없는 회의에서 '문자열 유사성 알고리즘'에 대해 알게 됐습니다.
예를 들어, 주소가 같지만 네이버에는 'hgogetter 상점', 카카오 지도에는 'h-go-getter 마트'로 다르게 등록되어 있을 수 있잖아요. 이때 '문자열 유사성 알고리즘'를 보조적으로 사용한다고 합니다. '문자열 유사성 알고리즘'은 다른 가게를 이름 만으로 동일한 가게라고 할 수 있다는 한계가 존재하므로 다른 key도 같이 사용하는 등 극복하기 위한 방법도 꼭 사용해야합니다.
저도 동일한 사업을 '유사사업으로' 더 많이 분류하기 위해 '문자열 유사성 알고리즘'을 적용해보기로 했습니다.
1.3. 예상 독자
이 글은 제가 퇴근 후, (정상원, 정기창) 2020 문자열 유사도 알고리즘을 이용한 공종명 인식의 자연어처리 연구 등 논문도 읽고 해외 기술 블로그등을 참고하며 '문자열 유사성 알고리즘'을 공부하며 업무를 개선한 과정을 담고 있습니다. 이런 분들이 읽으시면 도움이 될 것 같아요!
- '문자열 유사성 알고리즘'이 궁금하거나 관심이 있는 사람
- '문자열 유사성 알고리즘'을 적용해보고 싶은 사람
🔎 2. 문자열 유사성 알고리즘
2.1. 문자열 유사성 알고리즘이란?
- 문자열 유사성은 두개의 서로 다른 문자열의 거리를 측정하는 작업입니다. 두 문자열의 거리는 낱말별 차이일 수도 있고, 의미론적 거리일 수도 있습니다.
- 검색엔진이나 오타 검사와 같은 생활과 밀접한 서비스 에서도 사용되는 기법인데, 검색하고자 하는 단어와 비슷한 개념을 도출해 내야 하는 검색엔진의 경우는 의미론적 거리가 중요해서 사용됩니다.
2.2. 문자열 유사성 알고리즘의 종류
- (1) N-Gram
- 설명
문자열을 N개로 이루어진 토큰으로 나누고, 두 문자열의 토큰들을 하나씩 비교하여 전체 문자열의 유사 성을 판단하는 방식 - 예시
“아스팔트 부수기”라는 문자를 2개로 이루어진 토큰으로 나눈다면 “아스”, “스팔”, “팔트”, “트 “, “ 부”, “부수”, “수기” 와 같이 총 7개의 토큰으로 나누어집니다. 이렇게 나눠진 토큰은 상대 언어의 토큰 배열에서 같은 위치에 있는 토큰과 비교되며, 틀리면 패널티를 줍니다.
- 설명
- (2) Hamming Distance
- 설명
두 문자열을 있는 그대로 비교하는 방법입니다. 이 방법은 두 개의 문자열 A와 B를 낱말 별로 1대 1로 비교 하는 방법으로, 만약 같은 위치에 있는 낱말이 다르다면 페널티를 주는 방식입니다. - 예시
“아스팔트”와 “아스콘” 두 단어를 놓고 보았을 때, “팔”과 “콘”이 틀리고, “트”와 대응하는 단어가 아스콘에는 없으므로 다르다고 취급합니다.
- 설명
- (3) Levenshtein Distance
- 설명
문자열 A가 문자열 B가 되기 위해서 몇 번의 편집을 해야 하는지를 측정하는 것으로
편집 거리를 산정하는 가장 기본적인 편집의 방법은 총 3가지입니다.
- ⓐ 삽입(Insertion) : 문자열 내 같은 자리에 새로운 낱말을 채워 넣는 편집
- ⓑ 제거(Deletion) : 문자열 내 같은 자리에 있는 낱말을 제거하는 연산
- ⓒ 대체(Substitution) : 문자 열 내 같은 자리에 있는 낱말을 다른 낱말로 바꾸는 연산 - 예시
“아스팔트”와 “아스콘”을 각각 A와 B라고 가정하고, A를B로 변환시키는 편집거리는 총 2개입니다.
- ⓐ “팔”을 “콘”으로 변화시키는 편집은 '대체'
- ⓑ “트”는 대응하는 낱말이 없으므로 제거 '연산'
- 설명
- (4) Jaro-Winkler Distance (2.3.1.에 더 자세하게 설명)
- 설명
Levenstein Distance와 마찬가지로 편집 거리의 개념을 사용하지만 위의 경우와 다르게 두 가지의 경우에 더욱 높은 관련도 점수를 할당합니다.
- ⓐ 같은 낱말이 문자열 내 특정한 거리 내에 있는 경우
(예시 : “부수기”와 “깨기”를 비교하였을 때, 낱말 “기” 는 각각 문자열의 3번째와 2번째에 자리 잡고 있지만, 그 거리가 가까우므로 같은 일치하는 것으로 계산)
- ⓑ 문자열의 시작점부터 A와 B의 문자열이 일치하기 시작하는 경우 이는 알고리즘에 방향성을 부여
(※방향성 : 문자열이 일치하는 방향이 같은 것을 중요시하는 것)
- 설명
- (5) Jaro Winkler similarity(2.3.2.에 더 자세하게 설명)
- 설명
Jaro similarity 와 비슷하지만, 두 문자열의 시작 부분에 있는 문자가 동일한 경우 높은 점수를 할당합니다.
- 설명
그 외로 코사인 유사도(Cosine Similarity),유클리드 거리(Euclidean distance) 등이 있습니다. '문자열 유사성 알고리즘'은 거리값을 출력합니다. 만약 출력한 거리값이 0이라면 전혀 다른 문자열이라는 것을 의미하고, 1이라면 완전히 같은 문자열이라는 것을 의미합니다.
2.3. Jaro Winkler similarity
Jaro Winkler similarity 사용했습니다.
- 이유 1)
Jaro-Winkler Distance알고리즘이 두 문자열의 유사도를 측정할 때 가장 너그러운 점수를 줬기 때문입니다. 제가 알고리즘 적용을 고민 한 이유는, 더 많은 동일한 사업을 찾아내고 싶어서 였는데요. 더 많은 동일한 사업을 찾아낼 수 있도록 가장 너그럽게 유사도를 측정하는 알고리즘을 고려했습니다. - 이유 2) 동일한 사업인 경우, '공고명'의 시작 부분에 있는 문자가 같거나 특정한 거리 내에 위치 했기 때문입니다. 문자열이 일치하는 방향이 같은 것을 중요하게 여기는 알고리즘을 고려했습니다.
2.3.1. Jaro-Winkler Distance 란?
- 설명
두 문자열 간의 유사성을 측정 한 것으로 결과는 0~1사이의 숫자이다. (1은 문자열이 같음을 의미, 0은 두 문자열 사이에 유사성이 없음을 의미) - 계산 방법

- 계산 예시

- 각각 계산 한 결과
|s1|그리고|s2|우리가 비교하고 있는 두 문자열의 길이입니다(문자열 길이는 둘 다9)m일치하는 수로8

t는1= 2(e와l)/2
두 문자열에서 일치하지만 순서가 다른 문자 수는 e와 l

- 결과
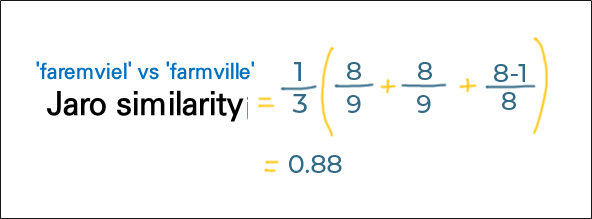
- 각각 계산 한 결과
2.3.2. Jaro Winkler similarity 란?
- 설명
Jaro similarity 와 비슷하지만, 두 문자열의 시작 부분에 있는 문자가 동일한 경우 점수를 높입니다. - Jaro similarity와 차이
문자열에 정의된 최대 길이 'L'까지 공통으로 시작 할 때 더 정확한 답을 제공하는 Scaling Factor 'P'를 사용 - 계산 방법 :

- 계산 예시 :

- 각각 계산 한 결과
-sj: Jaro 유사성(0.88)
-L: 문자열은 둘 다 로 시작far하므로3
-p: 일반적으로 많이 사용하는0.1 - 결과

- 각각 계산 한 결과
2.3.3. Jaro Winkler similarity 적용해보기
Jaro-Winkler 유사성을 계산하는 라이브러리 jarowinkler를 사용했습니다.
-
라이브러리 사용 방법
pip install jarowinkler -
사용 예시
from jarowinkler import jarowinkler_similarity score = jarowinkler_similarity("신규데이터분석사업", "경기도신규데이터분석사업") print(score) #결과 값 : 0.9166666666666666
업무에 적용 한 프로세스입니다. '문자열 유사성 알고리즘' 만 사용해서 동일하다는 판단을 하는건 한계가 존재하므로 극복하기 위한 방법이 필요하다고 말씀드렸는데요. 저는 다른 key를 함께 사용해서 판단해줬습니다.
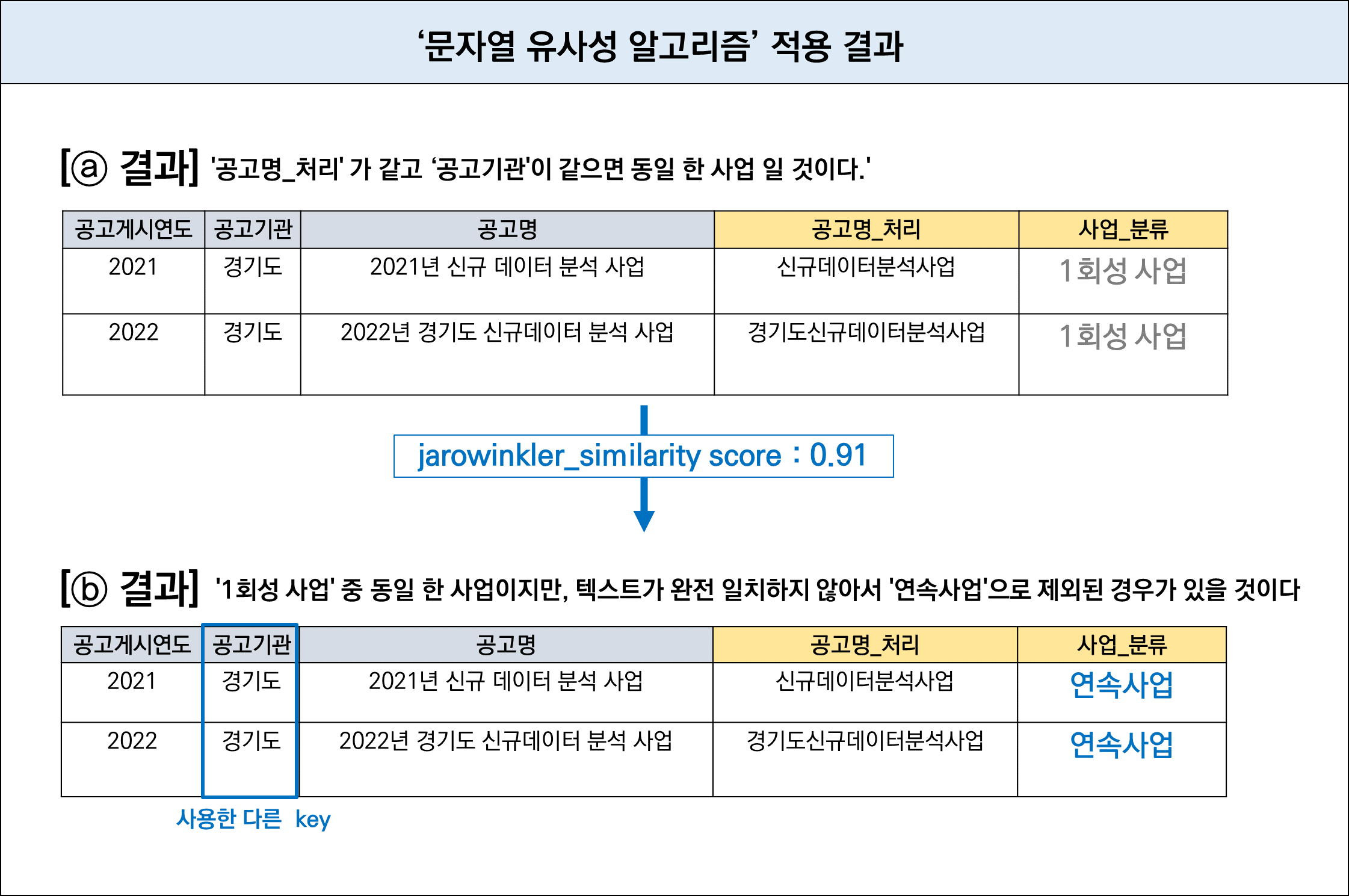
- ⓐ '공고명_처리' ('공고명'에서 띄어쓰기를 제거하고, 연도 등 불용어를 제거해준 컬럼) 가 같고 '공고기관'이 같으면 동일 한 사업 일 것이다.'
- 해당 기준으로 Group by해서 2개 이상인 경우 '연속사업', 1회 이하인 경우 '1회성 사업'
- ⓑ '1회성 사업' 중 동일 한 사업이지만, 텍스트가 완전 일치하지 않아서 '연속사업'으로 제외된 경우가 있을 것이다
- '공고기관'이 같은데 jaro_winkler_simularity score가 0.9이상인 경우 같은 그룹으로 지정
- 그룹별로 Group by해서 2개 이상인 경우 '연속사업' , 1회 이하인 경우 '1회성 사업'
유사도 알고리즘을 적용한 결과 '연속사업'이 약 40%로 상승했습니다. 저는 '1회성 사업'으로 분류된 사업에 대해, '공고기관'을 다른 key로 사용했기에 한계점을 극복할 수 있었는데요. 다른 조건이 없이 진행했을 경우, 완전 다른 사업을 동일하게 분류하는 등 위험 할 수 있었을 것 같습니다. 사용시 꼭 유의하시길 바랍니다.
🤗 3. 정리하며
비즈니스이기 때문에 빠르게 완성 하는 게 중요해서 시도해보지 못한 아쉬운 부분을, 퇴근 후 '문자열 유사도 알고리즘'을 스터디해서 약 20% → 약 40%로 상승시킬 수 있었는데요. 이 경험을 통해, 자기계발이 업무를 향해 있으면 성과로 연결 할 가능성을 열어준다는 걸 느꼈어요.
저는 1분기 회고 글에서 '시간 관리'파트를 회고하며 '다음 분기에 적용 할 것은 무엇인가?'라는 질문에 아래와 같이 답했는데요.
- 시간관리에서 나의 기준을 우선시하자! 나의 기준 중의 하나는 "성과와 밀접한 것"
- 직무에서 자기계발 목표 찾기, 요즘에 유행한다고 해서 우선순위를 뒤흔들면서 배우거나 습득하려고 하지말기
- 목적없는 자기계발을 지양하자. 집중해야할 것에만 집중하자. 무언가 새로운 걸 하고 싶을 때 질문을 3가지 던져보자
- 이 일이 내 성과에 도움이 되는가?
- 이 일이 집중해야 할 것과 관련이 있는가?
- 두가지에 부합하지 않지만 이걸 하지 않으면 평생 후회할 것 같은가?
1분기 회고를 통해 다짐한 것을 적용한 것 같아 뿌듯하기도하면서, 이 기준을 6월에도 적용해봐도 되겠다는 확신을 가지게 됐어요. 6월이 시작되면서 '앞으로 남은 2023년은 어떻게 보내야할지? 어떤 공부를 할지?' 계획도 많이 세우고 고민도 많이 하실텐데요. 업무나 성과와 연계된 공부를 해보시는 것은 어떨까요? 저도 재미나게 적용해보고 다른 글도 써보겠습니다!😁
📑 참고 자료

좋은 글 잘 읽고 갑니다 .S2