Paper Review : Safeguarding Mobile GUI Agent via Logic-based Action Verification (VeriSafe Agent)
논문 리뷰
링크:
https://arxiv.org/abs/2503.18492
Introduction
대규모 파운데이션 모델들 (LFMs, ChatGPT나 Gemini 등을 생각하면 되겠다) 이 눈부신 발전을 함에 따라, 이를 모바일 GUI와 상호작용하는 데 활용해서 모바일 작업들을 자동화하려는 ‘Mobile GUI Agents’와 관련한 연구들이 등장하고 있다.
최근 Mobile GUI Agents 관련 연구들은 LFM을 활용해 자연어로 들어오는 user request를 해석하고, 이를 모바일 상에서의 UI interaction으로 ‘번역’하는 식으로 LFM의 자연어 처리 능력과 추론 능력을 활용하고 있다.
다만, 아무리 LFM이 발전했다 하더라도, 이를 기반으로 하는 Mobile GUI Agents에게는 근본적인 한계점이 있다: 바로 LFM의 근본적인 확률적인 특성으로 인해, 모바일 작업 자동화를 실제 애플리케이션에 적용하기에는 안전성, 신뢰성 이슈가 대두될 수밖에 없는 현실이다. 특히, 모바일 앱 상호작용이라는 것은 매우 모호하고, 맥락에 의존적이어서 많은 성능 향상이 이루어진 최근의 SOTA LFM들에게도 여전히 어려운 작업이다.
또 하나 중요한 문제는 mobile task들의 특성이다. 특히 비가역적이면서도 LFM이 만들어내는 에러가 정말 심각한 결과를 초래하는 경우가 많다는 것이다. 금융 거래나 메신저 등의 예시를 생각할 수 있는데, 이런 task들은 한 번 잘못 실행이 되어버리면 되돌릴 수 없다는 특성이 있다. 이런 작업들에서까지 Mobile GUI Agents를 활용하려면 그 전에 견고한 safeguard와 검증 메커니즘을 확보하는 것이 필수적이다.
Prior works
그렇다면, 기존의 연구들에서는 Mobile GUI Agents의 행동을 어떻게 ‘검증’을 시도했을까?
Reflection 기법이 대표적이다.
이는 primary GUI agent가 생성한 행동을 리뷰하기 위해 또 다른 LFM을 활용한 reflection agents를 두는 multi-agent 방식의 접근법이다.
Reflection 기반 기법은 크게 두 가지로 분류할 수 있는데, pre-action 검증과 post-action 검증이 있다:
- pre-action 검증은 특정 행동이 모바일 앱에서 실행되기 ‘전에’ 검증하는 기법이다. 앞서 말했던 금융 거래와 같은 비가역적인 행동을 검증하기 위해서는 pre-action 검증이 실행되어야 하겠다.
하지만, 이 방법은 행동의 결과를 ‘예측’해야 한다는 어려움이 있고, 따라서 검증 정확도가 떨어진다는 문제가 있다. - post-action 검증은 특정 행동이 실행된 ‘이후’ 그 결과인 애플리케이션 상태를 보고 올바른 행동인지 검증하는 기법이다.
이를 통해 검증 정확도를 크게 향상시킬 수 있었다. 다만, 앞서 말했던 비가역적인 action을 사전에 막을 수 없다는 치명적인 한계가 존재한다.
또한, Reflection은 본질적으로 LFM을 사용해서 검증이 이루어지는 것이기 때문에, 정확도를 높일 수는 있더라도 결국 이 방식으로는 AI의 확률적인 특성에서 벗어날 수 없다는 것도 이 기법의 한계점이다.
VeriSafe Agent (VSA)
앞서 말했던 기존 연구인 Reflection 기법의 한계를 보완하기 위해 이 논문에서는 VeriSafe Agent(VSA)를 제안한다.
이 Agent는 확률적인 추론 대신, 논리 기반의 신뢰성 있는 pre-action 검증을 제공한다.

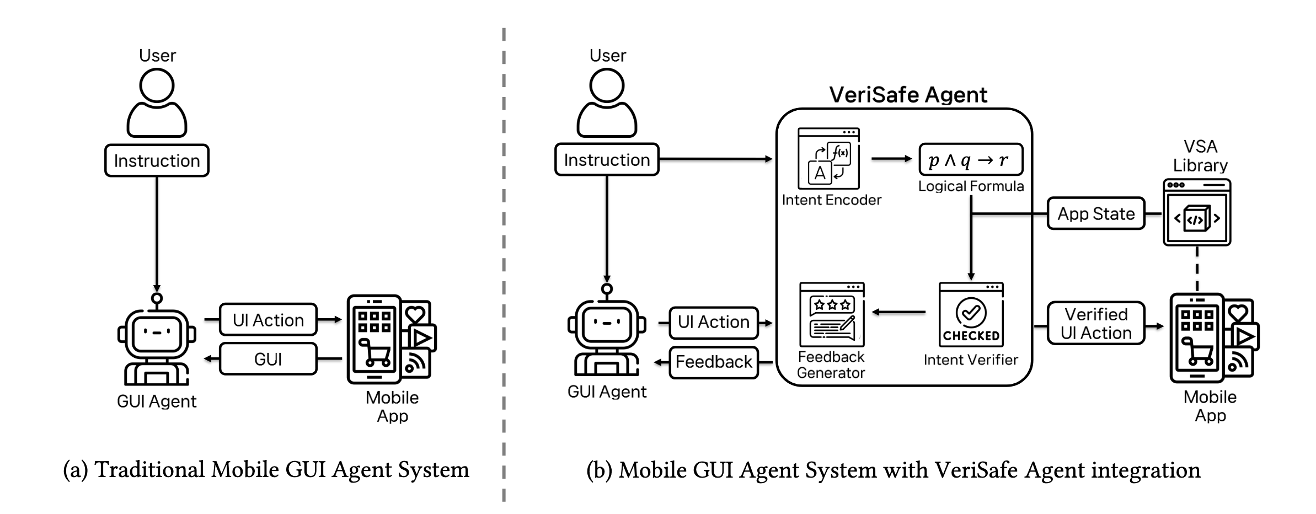
위 Figure의 우측을 보면, GUI agent의 UI action을 pre-action 단계에서 intercept하여, User Instruction과 Application State를 논리적인 formula로 형식화하여 올바른 action인지 검증을 수행한다.
즉, VSA는 사람이 natural language로 내리는 지시사항을 formal specification으로 자동 번역하는 Autoformalization이라는 concept을 활용한다.
또한, Figure를 보면 알 수 있듯이 VSA는 직접 행동을 수행하는 Mobile GUI Agent의 새로운 종류가 아니라, 기존 agent를 ‘검증’해 주는 시스템이다.
System Workflow
VSA의 system workflow는 아래 4가지 단계이다 :
- App Development Phase
- Intent Encoding
- Verification
- Feedback Generation
먼저, App Development Phase에서는 VSA를 위해 사전에 진행되어야 하는 단계로, 개발자가 직접 모바일 애플리케이션을 개발할 때 Predicates과 State transitions를 정의해 줘야 한다.

Intent Encoding 단계에서는 위 그림처럼 유저가 자연어로 내리는 지시사항을 구조화된 logical rules로 변환해 주는 작업이 실행된다.

Verification 단계에서는 기존 GUI Agent가 유저의 지시사항을 받고 실행한 UI Action에 대한 검증이 이루어지게 된다.
사전에 개발자가 개발해 둔 VSA developer library를 기반으로 해당 action을 수행했을 때 예상되는 state transition이 도출된다. Intent Verifier는 이 결과를 기반으로 logical rules에 따라 적절한 action인지를 검증하는 단계를 거친다.

마지막으로 Feedback Generation 단계에서는 앞선 검증 단계에서의 검증이 성공했는지, 실패했는지에 따라 VSA가 GUI Agent에게 적절한 피드백을 제공하게 되는 단계이다.
Challenges
논문에서는 VSA가 다루는 3가지 key challenges를 제시한다 :
- C1. How to formally express the user’s intent and the app’s execution flow in logically tractable representation?
- C2. How to accurately translate natural language user instructions into a formal representation and perform runtime verification against it?
- C3. How to effectively communicate verification results back to the GUI agent in an actionable, explainable manner?
이 각각의 challenges에 대해서 VSA는 각각의 solutions들을 매핑해서 보여주는데,
- C1에 대해서는 domain-specific language(DSL) 과 함께 관련된 developer library를 제시한다. (S1)
- C2에 대해서는 self-corrective encoding approach(in Intent Encoder)와 two-tiered verification strategy(in Intent Verifier)를 제시한다. (S2)
- C3에 대해서는 구조화된 feedback generation mechanism을 제시한다. (S3)
이 각각의 solution들을 하나하나 자세히 알아보도록 하자.
Domain-Specific Language (DSL) - for Solution 1
DSL은 특정 도메인에 특화된 computer language이다. 아래 위키백과 링크에서 더 자세한 내용을 확인할 수 있다.
https://en.wikipedia.org/wiki/Domain-specific_language
이 논문에서는 유저가 natural language로 내리는 instruction에 포함되어 있는 모바일 애플리케이션에서의 제약조건 / 실행 흐름 / 조건부 분기 등을 유연하게 표현하기 위해 DSL을 새롭게 설계한다.
Design of Domain-Specific Language

위 장표는 DSL의 구조를 시각화해 본 그래프이다.
유저의 지시사항 하나를 Specification이라 한다. 이것은 여러 가지의 Rule들로 구성되어 있다.
Rule은 Predicate(전제조건)들과 Objective(결론)으로, 다시 Predicate은 또 State Predicate들로 .. 이런 식으로 각각을 구성하는 요소들로 쪼개 나간다는 것을 알 수 있다.

Figure 2와 Figure 3에서 DSL의 syntax와 이를 활용한 instruction의 Specification을 확인할 수 있다.
각 Rule은 하나의 Horn Cluase로 표현되고, 하나의 user instruction(i.e. Specification)을 여러 개의 Rule들로 쪼개서 표현하는 역할을 한다.
이 Rule은 또 전제조건에 해당하는 State Predicates들과 결론에 해당하는 Objective로 구성된다.
Figure 3의 예시를 보면 직관적으로 이해가 가능할 것이다. “R이라는 이름의 레스토랑에 19시 전으로 예약을 하고, 해당 시간대에 레스토랑이 이용 불가능하다면, 아무것도 하지 말아라” 라는 유저의 지시사항을 3개의 Rule로 표현하였다:
R1 : 레스토랑의 정보 (이름이 ‘R’인지) 와 예약 정보 (날짜가 오늘인지, 시간이 19시 이전인지, 예약이 가능한지) 가 true이면 → Reserve를 진행한다.
R2 : Reserve가 수행되고, 예약 결과가 성공이면 → Done(즉, action 마침)
R3 : 만약 해당 시간에 예약이 불가능하면 (예약 정보에서 available 속성이 false) → Done (즉, 예약하지 않고 action을 마침)
R1의 결론이 R2의 전제조건으로 쓰이는 것과 같은 예시로 DSL이 action의 선행관계를 표현해 낸다는 것을 알 수 있다.
이와 같은 DSL을 구조화하여, VSA는 자연어로 된 유저의 지시사항을 형식적인 표현으로 ‘번역’을 성공적으로 수행할 수 있다.
Developer Library
이렇게 개념적으로 구현한 DSL을 실제 모바일 어플리케이션과 Mobile GUI Agents의 행동을 검증하고 평가하는 데 활용하기 위해서는 개발자가 앱의 상태(state predicates), 그리고 그와 관련된 state transitions를 ‘직접’ 정의해 줘야 한다.
개발자가 앱의 모든 상태와 상태 전이를 추가적으로 정의해줘야 한다는 것은 개발자에게 부담이 될 수도 있겠지만, 이미 React Native, iOS’s SwiftUI 등의 프레임워크에서 앱의 state와 transition 관리라는 개념이 존재하는 만큼 이것과 align함으로써 개발자의 부담이 그렇게 크지 않다고 말한다.


위 그림들과 같이 앱의 상태 정보와 상태 업데이트 정보를 몇 줄의 추가적인 코드 작성으로 쉽게 추가할 수 있는 개발자 라이브러리를 제공한다.
Verification Engine - for Solution 2
유저의 지시사항을 앞서 정의한 논리적 표현으로 인코딩하고, 이를 런타임에 정확하게 검증하기 위해서 VSA는 Intent Encoder와 Intent Verifier를 내부 엔진으로 구축한다.
더 자세한 방법론에 대해 알아보자.
Intent Encoder (self-corrective encoding)
Intent Encoder를 구현할 때 LFM에만 의존하게 되면, 할루시네이션의 발생 가능성을 생각하지 않을 수 없다.
이 리스크를 완화하기 위해서, 논문에서는 self-corrective encoding이라는 기법을 적용한다. 이는 아래의 두 가지 단계로 구성된다.
- Rule-based Syntax Checking : 이 단계에서는 Encoder LLM이 natural language 유저 지시사항을 보고 생성한 Specifications를 검사한다. 앞서 정의한 DSL의 문법을 철저히 지키는지를 검사하게 된다.
- Decoding-based Semantics Checking : 이 단계에서는 Decoder LLM과 Checker LLM을 활용해 생성한 Specifications을 다시 natural language로 디코딩하고, 이를 기존 유저 지시사항과 비교하면서 Semantic 정보를 확인한다.
이렇게 syntax와 semantic을 확인하는 두 단계의 과정을 거치면서, Intent Encoder는 user instruction이 DSL Specification으로 정확하게 인코딩한다.
Intent Verifier (two levels of verification)
인코딩을 마치게 되면, 아래의 메커니즘에 의해 Verification 단계가 수행된다 :
Mobile GUI Agent가 UI action을 생성한다.
→ 사전에 정의된 develoepr library를 통해 예상되는 state update가 반환된다.
→ 이 값을 기반으로 state predicate들의 true/false 여부를 재평가한다.
검증은 Predicate-level과 Rule-level의 두 가지 단계에서 이루어진다.

다시 DSL 구조 시각화 자료를 보면 이해가 쉬울 것이다.
-
Predicate-level Verification : 이 단계의 검증은 ‘모든 상태 업데이트’마다 수행된다.
만약, 여기서 predicate가 false로 평가되어도, 이는 에러를 의미하는 것이 아니다. 그 이유는, 유저 지시사항을 중간 단계에서 업데이트가 진행되고 있는 중일 수도 있기 때문이다. (예시로, 사과 3개를 장바구니에 담는 경우 ‘+’ 버튼을 세 번 누르면서 사과의 개수가 1개, 2개로 업데이트되는 중간 상태를 떠올려 볼 수 있다.)
이때 VSA는 soft feedback을 agent에게 전달하게 된다.
-
Rule-level Verification : 이 단계의 검증은 ‘되돌릴 수 없거나 critical한 checkpoint’에서 수행된다.
이러한 체크포인트는 되돌릴 수 없는 critical한 action과 관련된 rule이 만족되지 않으면, 해당 action은 무효화되고 차단된다.
VSA는 hard feedback을 agent에게 제공한다.
Structured Feedback Generator - for Solution 3
VSA와 같은 검증 시스템은 Mobile GUI Agent의 action을 검증해 준다는 장점도 있지만, agent에게 피드백을 제공해줄 수 있다는 것 또한 굉장한 장점이다.
VSA는 앞선 검증 결과를 기반으로, 세 가지 종류의 구조화된 피드백을 제공하여 mobile task 자동화의 신뢰성과 안전성을 높인다.
- Roadmap Feedback : logical Specification을 기반으로, 전반적인 경로에 대한 가이드라인을 제공한다 (검증 결과와는 관계x)
- Predicate-level Soft Feedback : Predicate-level verification이 실패한 경우, agent에게 일종의 경고로써 soft feedback을 제공한다. 이는 행동을 엄격하게 차단하는 것이 아니므로, agent는 피드백을 참고하되 동일한 action을 다시 수행할 수 있다.
- Rule-level Hard Feedback : Rule-level verification이 실패한 경우, 이 경우는 critical actions에 대해서 rule-level에서 엄격한 금지와 피드백이 제공된다. 이때는 agent는 해당 rule을 구성하는 모든 state predicate들이 만족되기 전까지 동일한 행동을 수행하지 못한다.
Implementation & Evaluation
Implementation
- Python으로 구현되었고, Intent Encoder를 구현하기 위해 GPT-4o를 활용한다.
- Developer Library 구현에 대한 문서와 가이드라인을 제공하여 개발자가 효과적으로 State Predicates를 정의하고 활용할 수 있도록 한다.
- OpenAI의 text-embedding-3-small model을 사용하여 user instruction의 ‘구조적 일치(structural equivalence)’ 대신 ‘의미적 일치(semantic equivalence)’를 판단한다.
Dataset
- 300개의 user instruction에 대한 dataset을 활용해서 Evaluation을 진행한다. (150 correct + 150 wrong)
- 이들 중 125개의 correct와 125개의 wrong dataset은 널리 사용되고 있는 데이터셋인 LlamaTouch의 일부를 활용했다.
- 다만, LlamaTouch는 상대적으로 단순한 instruction들로 구성되어 있으므로 (avg. 5.67 steps), 연구진은 더 복잡한 (avg. 19.16 steps, max. 40 steps) 25개의 correct, 25개의 wrong instruction들로 이루어진 Challenge Dataset을 직접 구성하여 추가로 확보했다.
Evaluation

실험을 진행한 결과, VSA를 적용한 경우에 LlamaTouch Dataset과 Challenge Dataset에서 모두 Reflection 방법에 비해 더 높은 검증 정확도를 보이는 것을 확인할 수 있다.

특히 Challenge Dataset에 대해서 여러 번 반복시켰을 때 VSA의 검증 정확도가 크게 상승한다는 것을 확인할 수 있다. 이는 검증이 logical formula에 기반해서 이루어지기 때문이다.

피드백의 영향 또한 확인할 수 있다.
Challenge Dataset에서, 두 가지 Reflection의 경우 피드백을 거쳤더라도 실패했던 case를 다시 성공시키지 못했던 반면, VSA가 피드백을 적용한 이후 Agent는 기존에 실패했던 많은 instruction들을 성공시키는 효과를 보여주었다. 이는 구조화된 피드백의 강력한 영향력을 보여준다.
