07-1 인공 신경망
[키워드]
인공 신경망
: 생물학적 뉴런에서 영감을 받아 만든 머신러닝 알고리즘
- 이름이 신경망이지만 실제 우리 뇌를 모델링한 것은 아님
- 종종 딥러닝이라고 부름
텐서플로
: 구글이 만든 딥러닝 라이브러리로 매우 인기가 높음
- CPU와 GPU를 사용해 인공 신경망 모델을 효율적으로 훈련하며 모델 구축과 서비스에 필요한 다양한 도구 제공
- 텐서플로 2.0부터 신경망 모델 빠르게 구축할 수 있는 케라스(keras)가 핵심 API
- 케라스 이용시 간단한 모델에서 복잡한 모델까지 손쉽게 만들 수 o
밀집층
: 가장 간단한 인공 신경망의 층
- 인공 신경망에는 여러 종류의 층 존재
- 밀집층에서 뉴런들이 모두 연결되어 있기 때문에 완전 연결층이라고도 함
❗출력층에 밀집층을 이용시에는 분류하려는 클래스와 동일한 개수의 뉴런 사용
원-핫 인코딩
: 정수값을 배열에서 해당 정수 위치의 원소만 1이고 나머지는 모두 0으로 변환
- 이 변환의 이유는 다중 분류에서 출력층에서 만든 확률과 크로스 엔트로피 손실을 게산하기 위함
- 텐서플로에서는 'sparse_categorical_entropy'손실을 지정하면 변환 수행이 필요x
패션 MNIST
- 'MNIST' 데이터는 원래 손으로 쓴 0~9의 이미지인데, 이건 '패션 MNIST'라서
10종류의 패션 아이템(이미지)으로 구성
데이터 가져오기
- 케라스(keras)의
.load_data()함수는 훈련/테스트 세트 나눠서 데이터 불러옴
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()- 크기 확인
훈련세트 : 입력은 28x28픽셀 이미지 60,000개 / 타깃은 0~9의 숫자 60,000개
테스트세트 : 훈련세트와 동일한 조건의 이미지 10,000개 / 상응하는 타깃도 마찬가지
print(train_input.shape, train_target.shape)
print(test_input.shape, test_target.shape)
->
(60000, 28, 28) (60000,)
(10000, 28, 28) (10000,)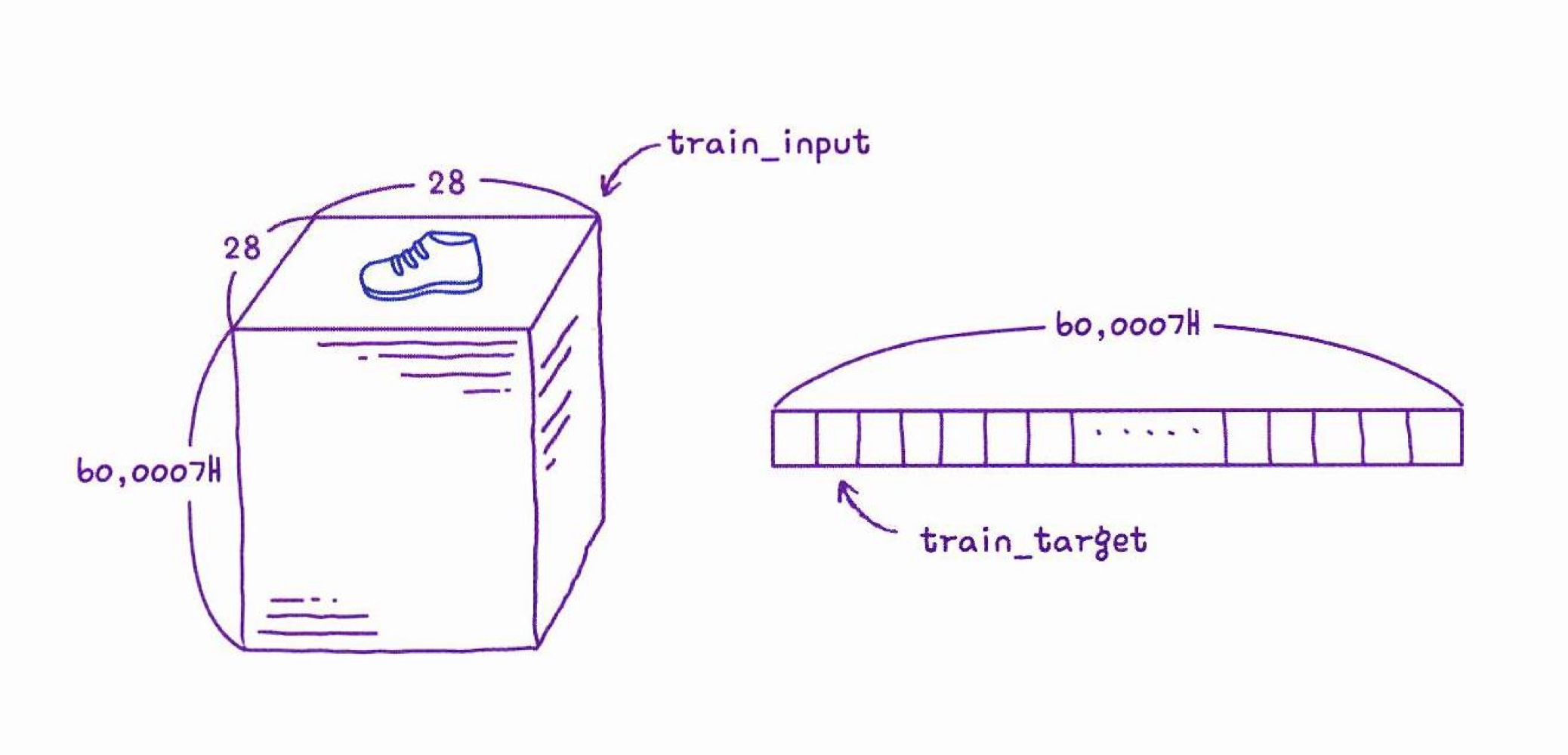
데이터 그려보기
- 패션 MNIST 출력
import matplotlib.pyplot as plt
fig, axs = plt.subplots(1, 10, figsize=(10,10))
for i in range(10):
axs[i].imshow(train_input[i], cmap='gray_r')
axs[i].axis('off')
plt.show()
- 샘플 타깃값 각각 확인
print([train_target[i] for i in range(10)])
->
[9, 0, 0, 3, 0, 2, 7, 2, 5, 5]*참고, 패션MNIST에 포함된 10개의 레이블

np.unique()로 레이블마다 몇 개씩 들어있는지 확인
# 0-9 정수로 이루어짐
import numpy as np
print(np.unique(train_target, return_counts=True))
->
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000]))로지스틱 회귀로 패션 아이템 분류하기
모델 선택 & 데이터 전처리
- 훈련 샘플 60,000개, 한 번에 다 사용하는 것보다 하나씩 꺼내서 훈련이 더 효율적
→ 확률적 경사 하강법, 손실함수를 로지스틱으로 한 SGD 사용 SGDClassifier→ 표준화 전처리 필요- 0 ~ 255사이 정수여서, 255로 나눠서 정규화 자주함(이미지 전처리 시 널리 쓰는 일종의 관례)
# 표준화 전처리 차원에서 0~ 255 사이의 픽셀값을 모두 255로 나눔
train_scaled = train_input / 255.0 # 정석은 아님, 간편해서 널리 사용
train_scaled = train_scaled.reshape(-1, 28*28) # SGD 쓰기 위해 각 샘플 1차원 배열로 변환
print(train_scaled.shape) # (28, 28) -> 784
->
(60000, 784)모델 훈련
- 경사하강법을 활용한 로지스틱 회귀모델을,
cross_validate로 훈련 & 평가
from sklearn.model_selection import cross_validate
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log_loss', max_iter=5, random_state=42)
scores = cross_validate(sc, train_scaled, train_target, n_jobs=-1)
print(np.mean(scores['test_score']))
->
0.819600000000000107-2 심층 신경망
[키워드]
심층 신경망
: 2개 이상의 층을 포함한 신경망
렐루 함수
: 이미지 분류 모델의 은닉층에 많이 사용하는 활성화 함수
- 시그모이드 함수는 층이 많을수록 활성화 함수의 양쪽 끝에서 변화가 작기 때문에 학습니 어려워지지만 렐루는 이런 문제가 없고 계산이 간단함
옵티마이저(Optimizer)
: 신경망의 가중치와 절편을 학습하기 위한 알고리즘 또는 방법을 의미
- 케라스에는 다양한 경사 하강법 알고리즘이 구현되어 있음
- 대표적으로 SGD, 네스테로프 모멘텀, RMSprop, Adam 등이 존재
2개의 층
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
# .load_data() 로 데이터 준비, 알아서 훈련/테스트 세트 나눠서 반환
from sklearn.model_selection import train_test_split
train_scaled = train_input / 255.0 # 전처리
train_scaled = train_scaled.reshape(-1, 28*28) # SGD쓰기 위해 1차원으로 표현
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
# 검증세트 수동으로 덜어내기, 딥러닝은 교차 검증 잘 안함은닉층(Hidden layer)
: 입력층과 출력층 사이에 있는 모든 층(=밀집층)
- 다중분류이기 때문에 소프트맥스 함수 사용
- 은닉층은 출력층 뉴런 개수보다 많이 두는 것이 일반적임
- 출력층과 마찬가지로 활성화 함수가 적용됨
- 출력층보다는 쓸 수 있는 함수가 비교적 자유로움
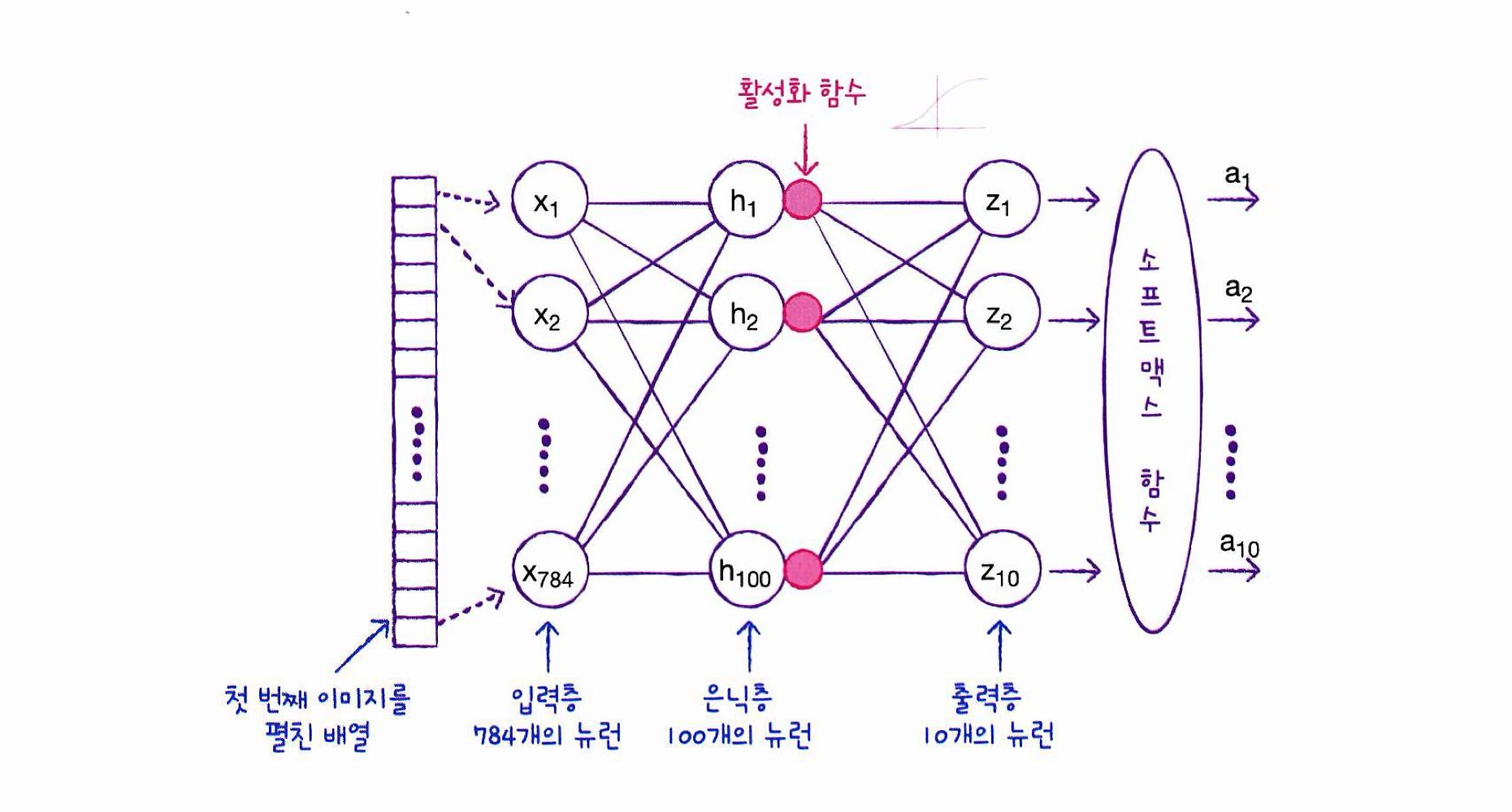
*활성화 함수
시그모이드 - 이진 분류 모델의 마지막 활성화 함수
소프트맥스 - 다중 분류 모델의 마지막 활성화 함수
ReLU - 기본적으로 은닉층에 사용하는 활성화 함수
+) 회귀를 위한 신경망의 출력층에서는 어떤 활성화 함수를 사용하나?
- 분류문제는 클래스에 대한 확률을 출력하기 위해 활성화 함수를 사용
- 회귀의 출력은 임의의 어떤 숫자이므로 활성화 함수를 적용할 필요 X
-> 출력층의 선형 방정식의 계산을 그대로 출력
심층 신경망 만들기(1)
- 밀집층 객체(Dense)를 만들고
Seauential()로 전달해서 만듦 - 은닉층
activation(활성함수)은 시그모이드로 설정
# 층 2개로!
dense1 = keras.layers.Dense(100, activation='sigmoid', input_shape=(784,)) # 첫번째 층엔 input_shape 해줌, 유닛 100개인 은닉층 만듦
dense2 = keras.layers.Dense(10, activation='softmax') # 유닛 10개인 출력층
# 만든 층 2개를 쌓아서 '심층 신경망' 모델 만들기, 순서대로 넣으면 됨
model = keras.Sequential([dense1, dense2])
# 모델에 대한 정보 확인
model.summary()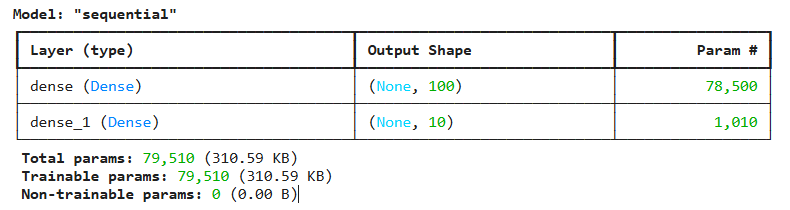
.summary(): 모델에 대한 정보 확인 가능
- 'Output Shape' : (경사하강법 배치크기, 출력 유닛 개수)를 보여줌. 훈련을 몇 개의 배치로 할지 모르니까, 유연하게 받을 수 있도록 None으로 되어있음.- 'Param' : 모델 파라미터, 즉 각 층의 가중치&절편의 개수를 보여줌.
1st 층 = 784 100 (가중치) + 100(절편) = 78,500
2nd 층 = 100 10 (가중치) + 10(절편) = 1,010
- 'Param' : 모델 파라미터, 즉 각 층의 가중치&절편의 개수를 보여줌.
심층 신경망 만들기(2)
- 층을 여러 개 추가하는 다른 방법 존재
- 따로 층 객체 만들어서 전달 x ->
Dense()클래스를Sequential()안에서 만듦
# name으로 층 이름 설정 가능(영문만)
model = keras.Sequential([
keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden'),
keras.layers.Dense(10, activation='softmax', name='output')
], name='패션 MNIST 모델')
model.summary()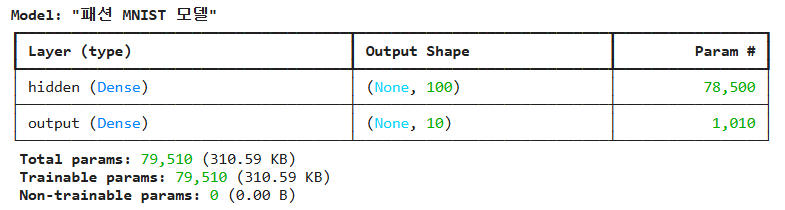
-> 층이 많아지면 한 문장이 너무 길어진다는 단점 존재
심층 신경망 만들기(3)
- 모델에
.add()로 원하는 만큼 층 추가하는 방법 add()속에서 if문 등을 활용해서 조건에 따라 층을 추가 가능- 실제로 가장 많이 쓰이는 방법
model = keras.Sequential()
model.add(keras.layers.Dense(100, activation='sigmoid', input_shape=(784,)))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()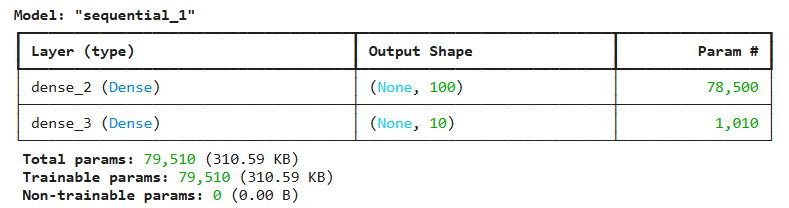
- 이후
.compile()로 설정하고.fit()으로 훈련되는 과정은 동일
model.compile(loss='sparse_categorical_crossentropy', metrics=['accuracy']) #설정해줌
model.fit(train_scaled, train_target, epochs=5) # 훈련, 층 추가하면서 성능 높아짐활성화 함수
*은닉층에 활성화 함수 적용하는 이유
: 2개의 선형 계산식이 연속된 형태로 있으면 중간 미지수가 사라지듯이, 신경망에서도 연속으로 쌓는 층이 선형적 계산으로만 구성되면 중간에 낀 은닉층들의 존재 의미가 사라짐

그래서 은닉층의 결과값을 비선형적으로 만들어주는 계산 필요

렐루 함수(RELU)
[시그모이드 함수의 단점]
: 출력값(z)이 너무 크거나 작을 땐 함수값의 차이가 너무 작음
→ 변화에 빠르게 대응하지 못함 → 층을 깊게 쌓기 힘듦
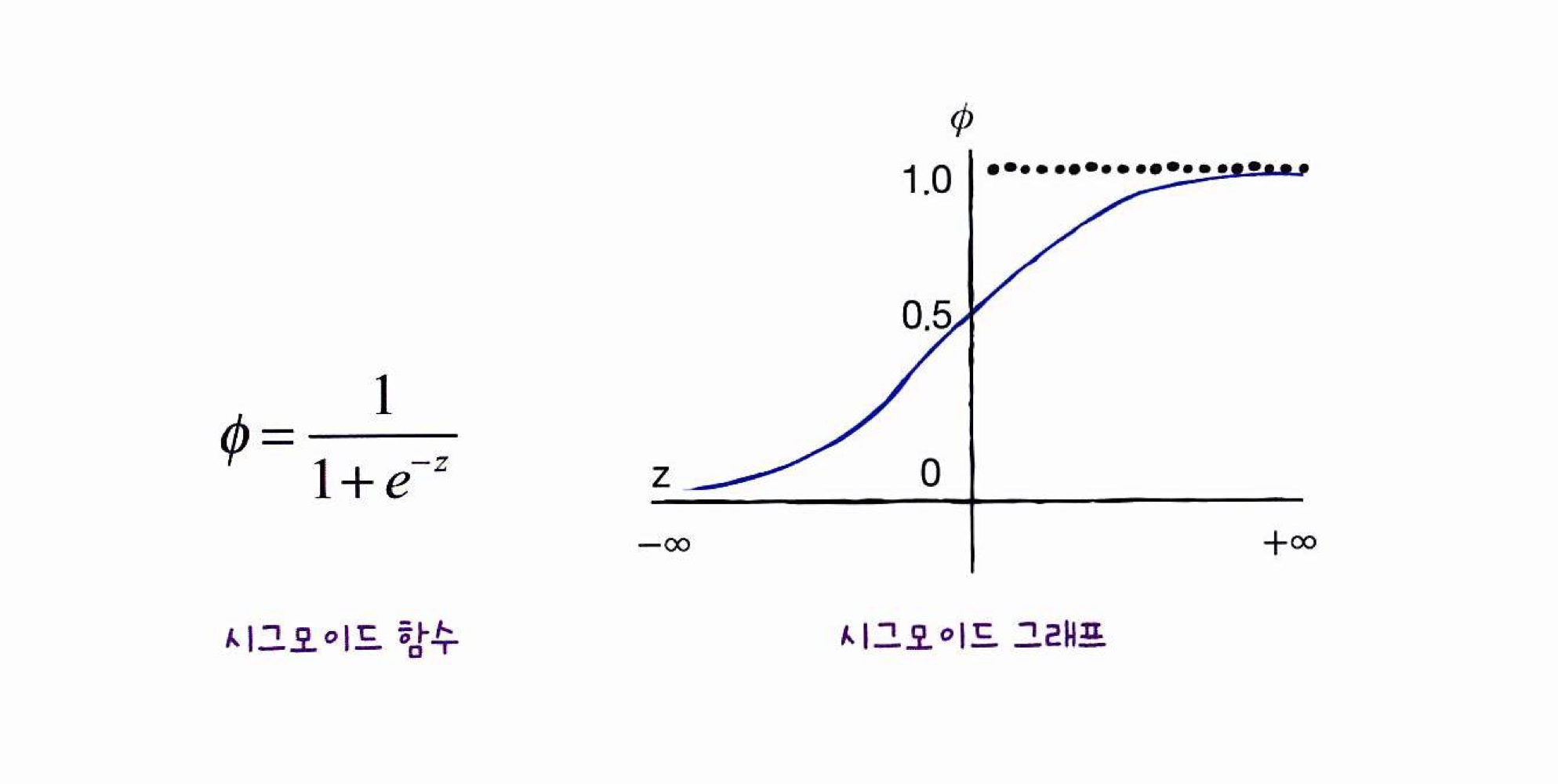
- 시그모이드 함수의 단점을 보완 -> 렐루 함수
: z<0이면 0으로 출력, z>0이면 그대로 z 출력
(이미지 처리에 좋은 성능을 냄)
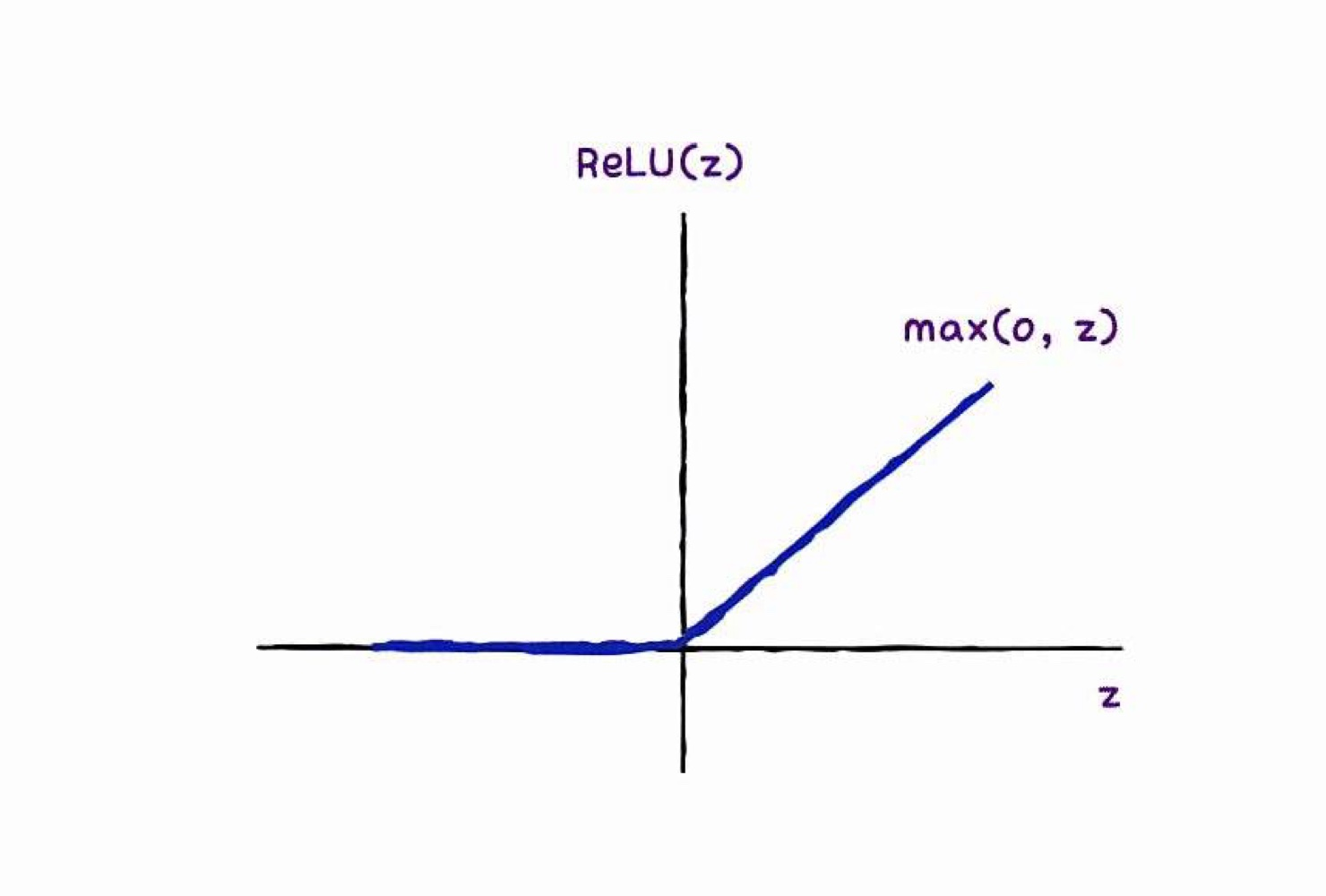
심층 신경망 만들기(4) - 렐루함수
Flatten(): 입력데이터를 1차원으로 표현해주는 유틸리티 층(편의를 위한 층)
→ summary 출력해보면 입력값의 개수 바로 알 수 있음
model = keras.Sequential()
# 입력 데이터 1차원으로 펼치는 층
model.add(keras.layers.Flatten(input_shape=(28, 28)))
# 활성화 함수 렐루로 설정
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()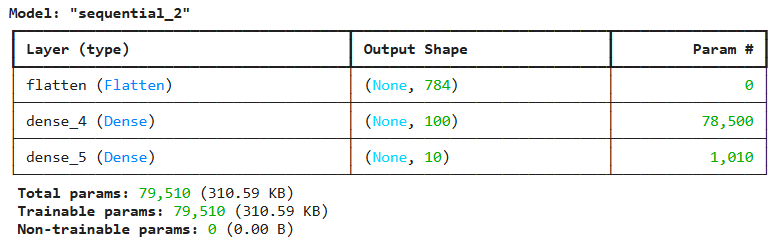
→ 모델의 입력값 784개의 1차원 배열이라는 것을 알 수 있음
- 이 모델 훈련 시킴 -> .reshape() 필요없어짐
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
# train_scaled = train_scaled.reshape(1-,28*28) 빠짐, flatten층 생겨서
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
model.compile(loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(train_scaled, train_target, epochs=5)
# 검증세트로 성능 확인 -> 출력층 하나일때 보다 좋아짐
model.evaluate(val_scaled, val_target)옵티마이저(Optimizer)
[옵티마이저란?]
딥러닝 학습시 최대한 틀리지 않는 방향으로 학습해야 한다,
얼마나 틀리는지(loss)를 알게 하는 함수가 loss function(손실함수)이다.
loss function 의 최솟값을 찾는 것을 학습 목표로 한다.
최소값을 찾아가는 것 최적화 = Optimization
이를 수행하는 알고리즘이 최적화 알고리즘 = Optimizer 이다.
*참고- 옵티마이저 종류
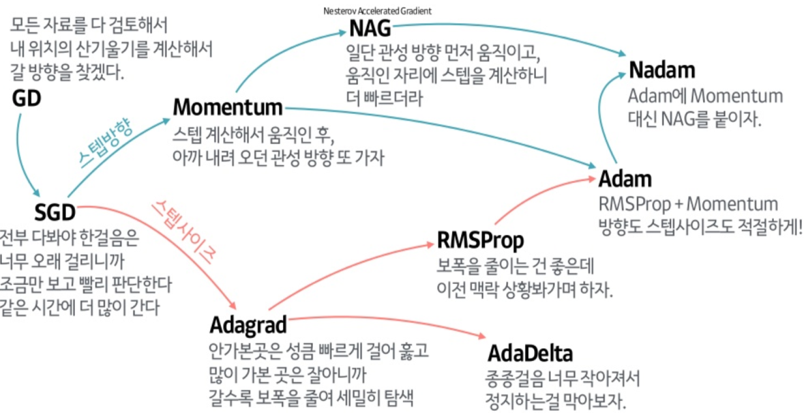
신경망의 하이퍼파라미터
- 신경망에 특히 하이퍼파라미터가 많음(지정하는 종류로)
ex) 은닉층 뉴런 개수 100, 활성화함수 activation, 층의 종류 Dense Flatten, 배치크기 batch_size, 반복횟수 epochs 등이 있음
옵티마이저 설정
- 옵티마이저도 하이퍼파라미터 중 하나, 경사하강법의 종류에 대한 설정이라 보면 됨
- 설정(compile) 단계에서
optimizer로 지정 가능, 문자열이나 객체로 만들어 놓고 호출 가능
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # 기본적인 확률적 경사하강법
sgd = keras.optimizers.SGD()
# 위 처럼 따로 옵티마이저 객체 만들기(학습률 등 세부설정 가능해짐)
model.compile(optimizer=sgd, loss='sparse_categorical_crossentropy', metrics=['accuracy'])- 적응적 학습률: 최적점에 가까워질 수록 학습률을 낮추는 효율적인 방식
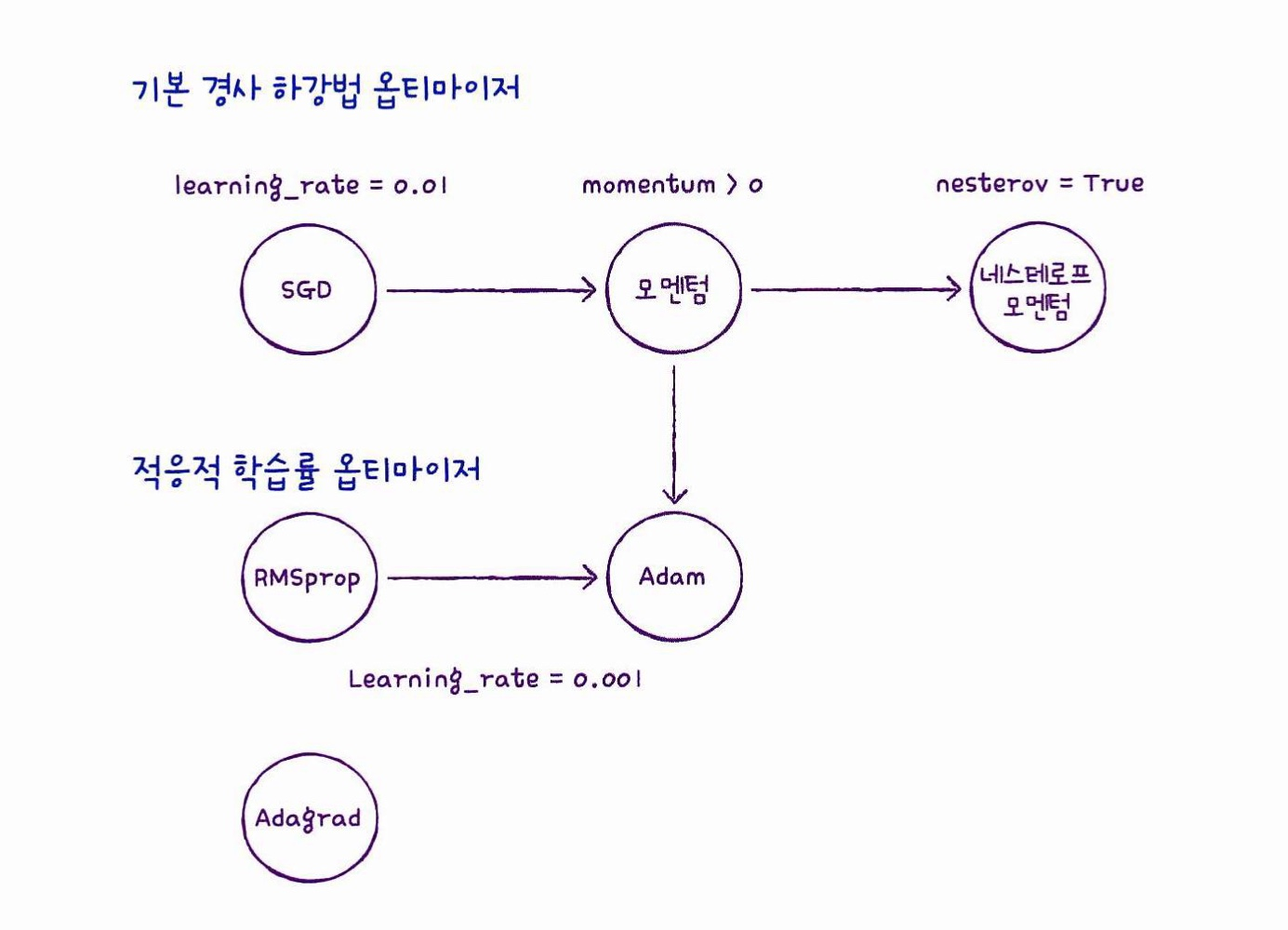
→ 경사를 처음엔 많이 내려가다가 가까워질수록 점점 조금씩 내려가는게 더 효율적임, 이렇게 점차 학습률이 변화하는 것이 '적응적 학습률'
sgd = keras.optimizers.SGD(momentum=0.9, nesterov=True) # '네스테로프 모멘텀' 하강법adagrad = keras.optimizers.Adagrad() #'아다그라드' 하강법(적응적 학습률)
model.compile(optimizer=adagrad, loss='sparse_categorical_crossentropy', metrics=['accuracy'])rmsprop = keras.optimizers.RMSprop() # 'RMSprop' 하강법 (적응적 학습률)
model.compile(optimizer=rmsprop, loss='sparse_categorical_crossentropy', metrics=['accuracy'])심층 신경망 만들기(5)
- Adam 옵티마이저를 사용한 모델로 만들어 봄
(Sequential & add → compile → fit → evaluate 순서)
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
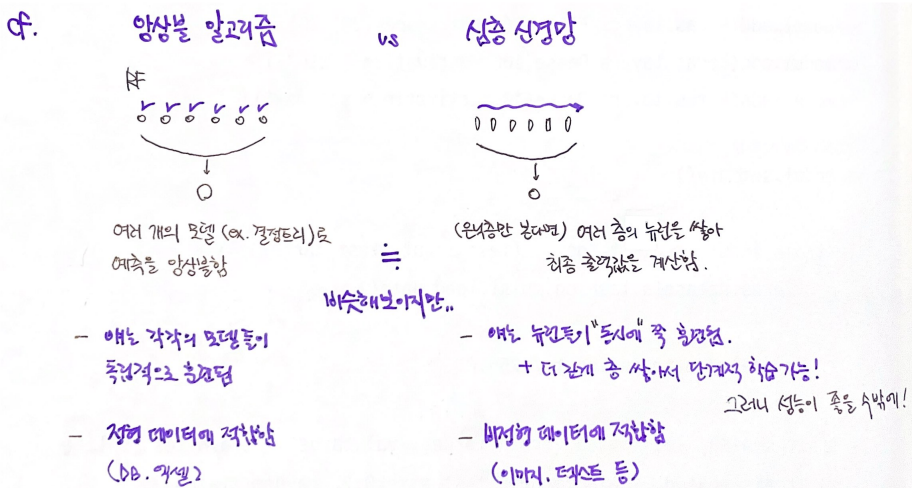
model.fit(train_scaled, train_target, epochs=5)*참고 - 앙상블 알고리즘 🆚 심층 신경망
- 여러 개를 모아서 하나의 최종 모델을 구성한다는 점에서 비슷해보이지만,
완전히 다른 방식으로 훈련
07-3 신경망 모델 훈련
[키워드]
드롭아웃
: 은닉층에 있는 뉴런의 출력을 랜덤하게 꺼서 과대적합을 막는 기법
- 훈련 중에 적용, 평가나 예측에서 적용하지 X (텐서플로는 자동으로 처리)
콜백
: 케라스 모델을 훈련하는 도중에 어떤 작업을 수행할 수 있도록 도와주는 도구
- 대표적으로 최상의 모델을 자동으로 저장해 주거나 검증 점수가 더 이상 향상되지 않으면 일찍 종료 가능
조기 종료
: 검증 점수가 더 이상 감소하지 않고 상승하여 과대적합이 일어나면 훈련을 계속 진행하지 않고 멈추는 기법
- 계산 비용과 시간 절약 가능
손실곡선
모델 만드는 함수 제작
from tensorflow import keras
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = \
keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
# 모델 함수화
def model_fn(a_layer=None):
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu'))
if a_layer: # 은닉층 뒤에 원하는 층 더 추가 가능하게 설정
model.add(a_layer)
model.add(keras.layers.Dense(10, activation='softmax'))
# 마지막은 전과 동일한 출력층
return model
model = model_fn()
model.summary()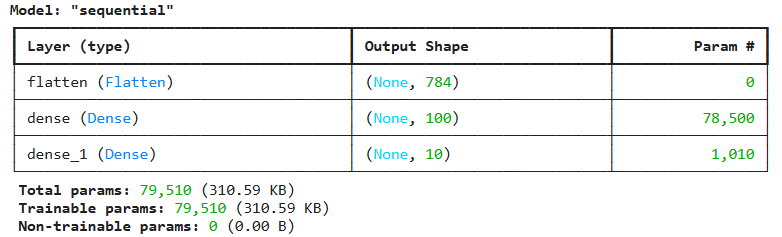
fit의 결과값 시각화
- keras의
.fit()메소드는 History 객체를 반환함
↪ 그 안에는 훈련측정값이 담긴 history 딕셔너리가 들어있음! ('accuracy'는 우리가 따로 metrics 넣어줬기 때문에 있는 거임 ㅇㅇ)
# 똑같이 fit하고 그 결과를 history에 담아봄
model.compile(loss='sparse_categorical_crossentropy', metrics=['accuracy'])
history = model.fit(train_scaled, train_target, epochs=5, verbose=0)
# 결과 담긴 history 객체에서 key 값 꺼내보면 => 손실 & 정확도
print(history.history.keys())-> dict_keys(['accuracy', 'loss'])
- 위 결과값들을 그래프로 그려봄
import matplotlib.pyplot as plt
plt.plot(history.history['loss']) # 인덱스 0부터, loss값까지
plt.xlabel('epoch') # 에포크가 0부터 시작하니까 인덱스와 같음
plt.ylabel('loss')
plt.show()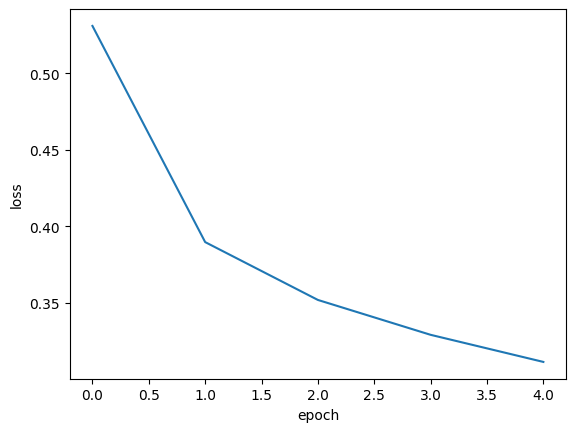
- 에포크가 늘어날수록 loss 감소, accuracy 늘어남
plt.plot(history.history['accuracy'])
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()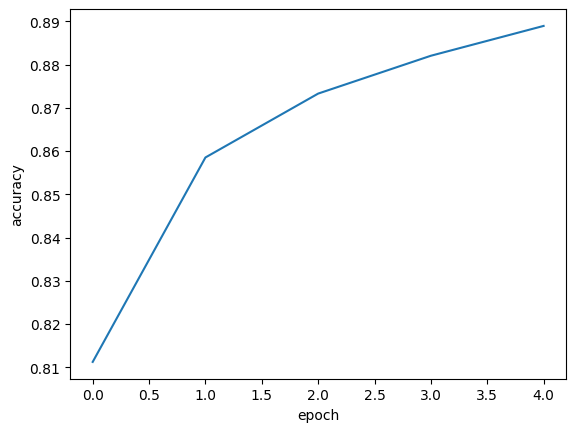
에포크 늘리기
- 에포크를 더 늘릴수록 손실이 더욱 감소하는 것을 확인
verbose: 훈련 과정 출력 조절, 기본값은 1 -> 에포크마다 진행 막대와 함께 손실 등의 지표 출력 / 2로 바꾸면 진행 막대 빼고 출력 / 0이면 훈련과정 안나타냄
model = model_fn() #기본 모델
model.compile(loss='sparse_categorical_crossentropy', metrics=['accuracy'])
history = model.fit(train_scaled, train_target, epochs=20, verbose=0)
# 에포크 20으로 늘려서
plt.plot(history.history['loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()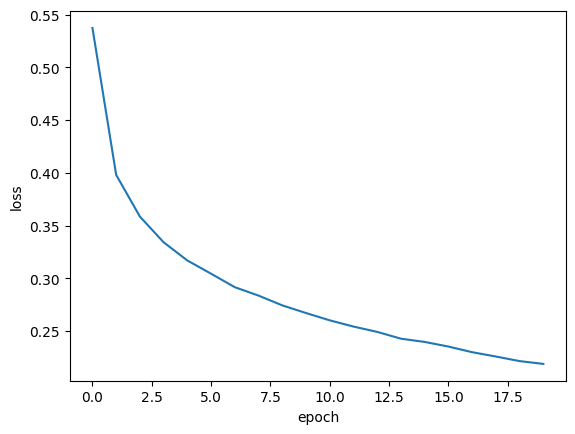
검증손실과 과대적합
-
검증세트의 손실도 확인해야 함
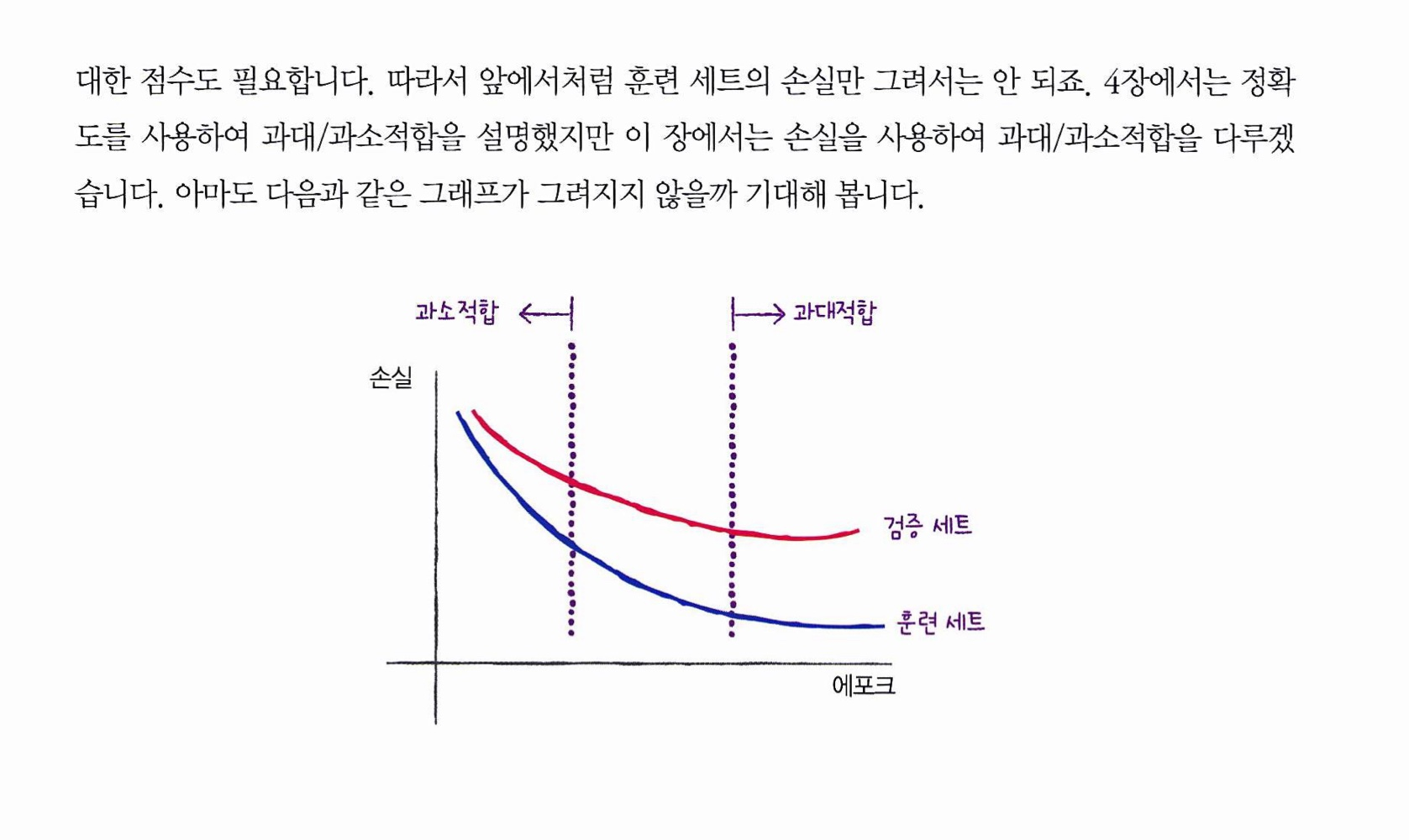
-
validation_data: fit의 매개변수, 검증세트의 결과도 반환하도록 설정 가능
model = model_fn()
model.compile(loss='sparse_categorical_crossentropy', metrics=['accuracy'])
history = model.fit(train_scaled, train_target, epochs=20, verbose=0,
validation_data=(val_scaled, val_target))
# 검증세트 결과도 반환해줘
print(history.history.keys()) # key 하나 더 추가됨-> dict_keys(['accuracy', 'loss', 'val_accuracy', 'val_loss'])
- 검증세트의 손실 같이 그래프로 그림
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()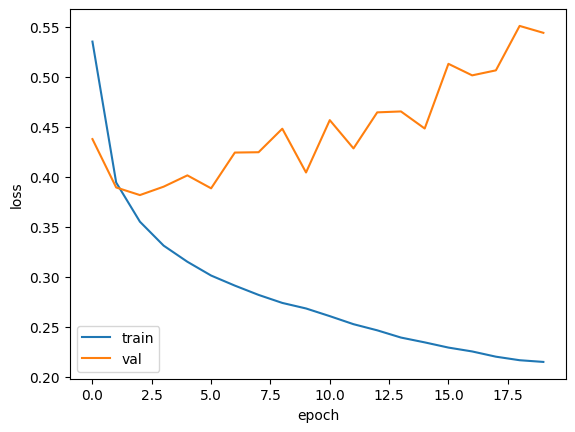
-> 훈련세트에만 너무 잘맞는 과대적합이였음을 확인 가능함
드롭아웃
-
신경망 모델에만 있는 규제 방법으로 딥러닝의 아버지 Geoffrey Hinton이 소개하심
-
층에 있는 유닛을 다 훈련X, 일부를 랜덤하게 off해서 훈련 성능 낮춤
ex) 1st 샘플에선 두번째 유닛 계산 안 하고, 2nd 샘플에선 첫번째 유닛 계산 안 하고,•••
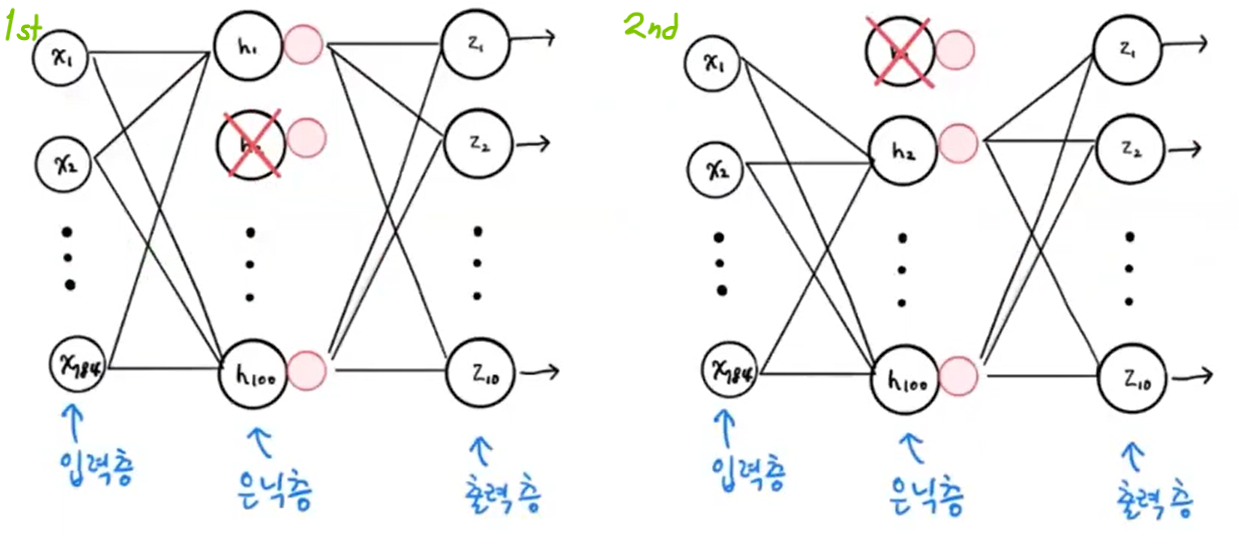
그림 출처 -
Dropout(): 드롭아웃 기능을 제공하는 클래스. 얼마나 drop할지 비율을 정해야 함
(*마치 케라스 층처럼 사용되지만, 학습되는 모델 파라미터는 없음)
# 드롭아웃으로 랜덤하게 유닛들 off하면서 훈련 = 훈련세트 성능 규제
model = model_fn(keras.layers.Dropout(0.3)) # 층처럼 쌓음
model.summary()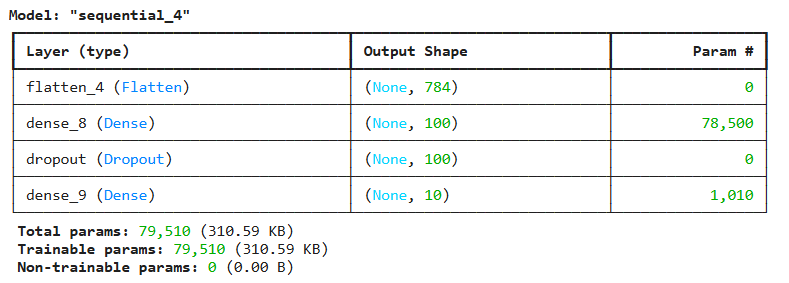
- 드롭아웃 처리한 모델의 검증손실을 출력하니 과대적합 완화됨
(따로 Dropout 층 안 빼줘도 알아서 평가&예측 시에는 드롭아웃 적용 안 함)
# 드롬아웃 처리한 걸로 다시 훈련
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(train_scaled, train_target, epochs=20, verbose=0,
validation_data=(val_scaled, val_target))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()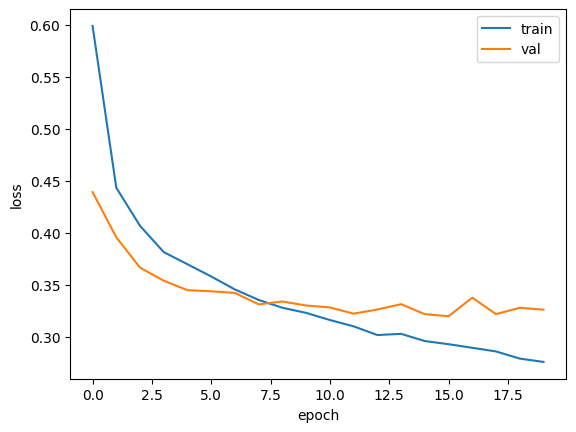
-> 최적의 에포크 10정도 되어 보임
모델 저장 & 복원
- 에포크 10으로 다시 훈련
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(train_scaled, train_target, epochs=10, verbose=0,
validation_data=(val_scaled, val_target))모델 저장
.save_weights(): 훈련된 모델의 가중치를 저장하는 메소드.save(): 훈련된 모델의 구조와 가중치를 통째로 저장하는 메소드
model.save('model-whole.keras') # 가중치랑 모델 구조까지 다 저장
model.save_weights('model.weights.h5') # 모델의 가중치만 저장
!ls -al model* # 잘 만들어졌나 셀 명령으로 확인
모델 복원
.load_weights(): 이전에 저장했던 모델의 가중치를 적재하는(불러오는) 메소드
(모델 구조가 정확히 같아야만 적재할 수 있음).load_model(): 이전에 저장했던 모델 전체를 불러오는 메소드
model = model_fn(keras.layers.Dropout(0.3)) # 새 모델 만들고
model.load_weights('model.weights.h5') # 만든 가중치 반영검증세트의 정확도 계산
복원_1 모델
evaluate() 써도 되지만, 그렇게 계산하려면 복원한 모델에 또 다시 compile()을 실행해야 함. 여기에선 그냥 새로운 데이터에 대해 정확도만 계산하면 되는 상황이라고 가정
[계산 방법]
: 예측 클래스 직접 구하고 타겟이랑 비교해서 맞춘 비율로 계산
.predict(): 샘플마다 각 클래스일 확률을 반환해줌(사이킷런 predict_proba처럼)
- 사이킷런에서는 예측 클래스가 뭔지 바로 반환함, 여기서는 모든 클래스별로 확률을 반환하기 때문에 그 중에 제일 높은 걸 다시 선택하는 과정을 수동으로 해줘야 함
.argmax(): predict가 출력한 확률들 중에 가장 큰 값을 뽑기 위해 넘파이 활용
->axis=-1: 배열의 마지막 차원(여기서는 axis=1)을 따라 argmax를 수행- 그렇게 뽑은 최댓값의 인덱스
val_labels와val_target을 비교해서, 일치하는 비율이 곧 검증세트의 정확도가 됨
import numpy as np # 넘파이의 argmax 활용
val_labels = np.argmax(model.predict(val_scaled), axis=-1)
# 모델이 구한 예측 클래스와 실제 타겟값 비교해서 맞춘 비율 알아봄
print(np.mean(val_labels == val_target))복원_2 모델
이 경우는 모델의 구조와 옵티마이저까지 모두 그대로 복원했기 때문에 바로 evaluate()를 사용할 수 있음
.load_model(): 이전에 저장했던 모델 전체를 불러오는 메소드
# 모델 전체 저장했던 걸로 해봄
model = keras.models.load_model('model-whole.keras')
model.evaluate(val_scaled, val_target)콜백
- 매번 수동으로 다시 최적의 에포크 설정, 모델 훈련하는 번거로움 해결 => 콜백(callback)
- 훈련 과정 중간에 특정 작업을 수행하게 해주는 객체,
keras.callbacks패키지 아래에 다양한 클래스 존재
-> 콜백 객체 만들어두고, fit()할때 callbacks 매개변수로 전달
ModelCheckpoint 콜백
ModelCheckpoint(): 가장 자주 사용되는 콜백, 에포크마다 모델을 저장save_best_only=True: 손실이 가장 낮은 모델만 저장하도록 하는 설정
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-model.keras',
save_best_only=True)
model.fit(train_scaled, train_target, epochs=20, verbose=0,
validation_data=(val_scaled, val_target),
callbacks=[checkpoint_cb])

EarlyStopping 콜백
-
최적의 모델 찾을 때 에포크를 무작정 높게 설정해놓고 찾으면, 불필요하게 오랫동안 훈련을 계속함
-
EarlyStopping(): 과대적합이 시작되면 훈련을 알아서 조기종료 해주는 콜백 -
patience: 검증세트 성능이 좋아지지 않더라도 참고 기다릴 에포크 횟수 설정 -
restore_best_weights=True: 훈련동안 가장 손실 낮았던 최적 가중치로 돌리는 설정

-
fit()에서 epochs를 크게 설정해도 ㄱㅊ
-
.stopped_epoch: 몇 번째 에포크에서 조기종료 했는지 저장되어 있는 속성
→ patience 설정했던 것과 같이 생각해보면 최상의 에포크가 언제인지 나옴
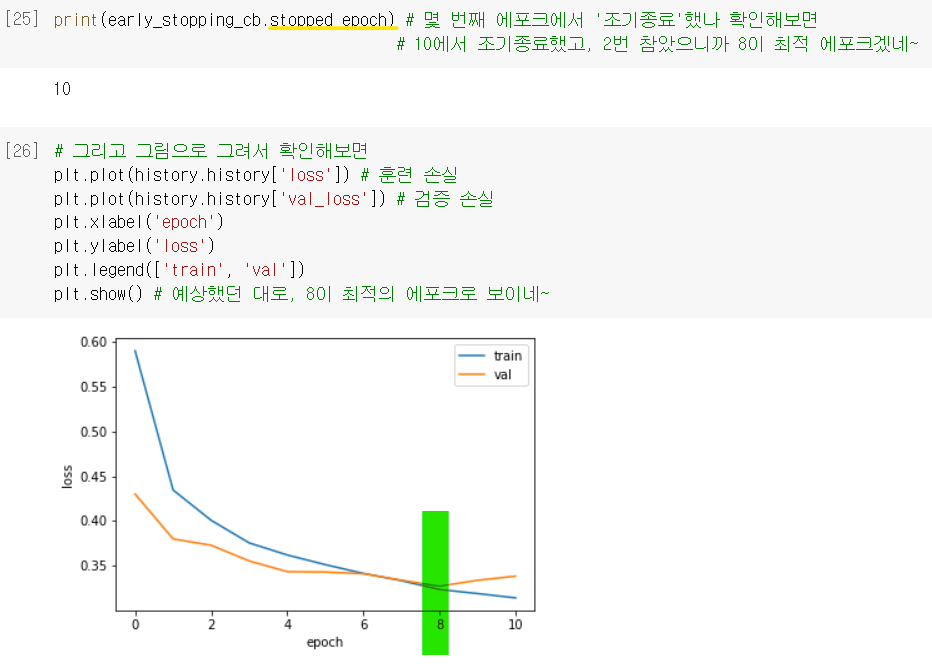
최종 모델
- ModelCheckpoint 콜백이랑 EarlyStopping 콜백을 함께 사용
→ 자동으로 최상의 모델 얻음
