Zookeepr 란?
- 분산 코디네이션 서비스를 위한 오픈소스 프로젝트
- 분산 처리 환경에서 사용 가능한 데이터 저장소
- 활용 분야
- 서버 간의 정보 공유 (설정 관리)
- 서버 투입|제거 시 이벤트 처리(클러스터 관리)
- 리더 선출
- 서버 모니터링
- 분산 락 처리
- 장애 상황 판단
Zookeeper 데이터 모델
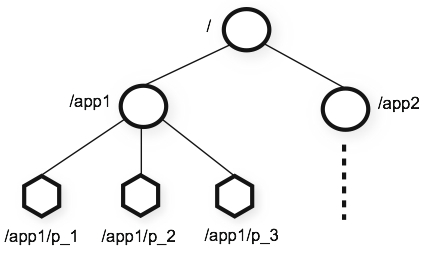
- 일반적인 파일 시스템과 비슷
- 각각의 디렉터리 노드를 znode라고 명명(변경X, 스페이스X)
- 노드는 영구(Persistent) / 임시(Ephemeral) 노드가 존재
- 영구(Persistent) 노드는 세션 종료 시 삭제되지 않고 데이터가 유지(명시적으로 삭제)
- 임시(Ephemeral) 노드는 세션이 유효한 동안 그 노드의 데이터가 유효
- 시퀀스(Sequential) 은 노드 생성 시 시퀀스 넘버가 자동으로 추가
znode의 특징
hierarchy
znode는 unix-like 시스템에서 쓰이는 file system 처럼 node 간에 hierarchy namespace를 가지고, 이를 /(slash)를 이용하여 구분한다.
일반적인 file system과 다른 부분이 있다.
ZooKeeper는 file과 directory의 구분이 없이 znode라는 것 하나만을 제공한다.
즉, directory에도 내용을 적을 수 있는 directory와 file 간의 구분이 없는 file system이다.
이는 znode의 큰 특징 중 하나이다.
namespace hierarchy를 가지기 때문에 관련 있는 일들을 눈에 보이는 하나의 묶음으로 관리할 수 있으면서, directory가 내용을 가질 수 있게 함으로써(혹은 file 간에 hierarchy를 가진다고 하기도 한다.) 불필요한 file을 생성해야 하는 것을 막을 수 있다.
size 제한
ZooKeeper는 모든 data를 메모리에 저장한다.
data를 메모리에 저장하기 때문에 jvm의 heap memory를 모든 znode를 올릴 수 있는 충분한 크기로 만들어야 한다.
심지어 The disk is death to ZooKeeper.라고 말하면서, JVM이 heap memory를 swap하여 하드에 저장하는 것을 피하도록 설정하는 것을 강요하고 있다.
data를 저장하는 보통의 파일 시스템이나 DBMS같은 경우 모든 data가 메모리에 올라갈 수 있는 크기로 제한된다는 제약조건은 말도 안 되는 조건이라고 할 것이다.
하지만 znode의 목적은 data를 저장하는 것이 아니라, 분산된 시스템 간의 조정을 하기 위함이다.
따라서 znode에는 조정에 필요한 meta data만을 저장하는 것이 기본적은 사용법이고, znode 자체도 크기가 작은 data를 저장할 것이라고 가정하고 구현되어 있기 때문에 각 znode의 크기는 1MB로 제한된다.
Recovery
ZooKeeper 설정파일을 봤으면 모든 data를 메모리에 올린다는 설명이 이상하게 느껴질 것이다. ZooKeeper 의 설정파일에는 dataDir을 설정할 수 있게 되어 있다.
그렇다면 dataDir은 무엇을 위한 것일까?
dataDir은 zookeeper의 recovery를 위해 사용된다.
ZooKeeper는 모든 data를 메모리에 들고 있기 때문에 서버가 종료되었다가 재 시작했을 때 자료를 보존할 수 없다.
이때 원래의 자료를 복구할 수 있는 것을 보장하기 위하여 ZooKeeper는 모든 transaction log를dataDir 에 저장한다. zookeeper를 재 시작하면 dataDir에서 transaction log를 읽어와서 모든 트랜잭션을 다시 실행하여 data를 복구한다.
하지만 언제나 transaction log만을 이용하여 자료를 복구한다면, 자료를 복구하는데 시간이 걸리기도 하고, 무엇보다도 로그가 쌓일수록 복구할 자료의 양에 비해서 로그의 크기가 커지는 문제가 생긴다.
이를 해결하기 위하여 ZooKeeper는 transaction log가 일정 이상이 되면, 지금까지 쌓인 transaction log로 만들 수 있는 data를 하드에 저장하고 transaction log를 지운다.
이 data를 snapshot이라고 하는데, 다음에 복구할 일이 생기면 snapshot에서부터 자료를 읽어온 뒤, 추가로 쌓인 transaction log만을 실행시켜 자료를 복구한다.
ZNode의 종류
znode를 생성할 때 2종류의 옵션을 줄 수 있다.
하나는 life cycle에 관한 option으로 persistent인지 ephemeral인지를 설정하는 것이고,
다른 하나는 znode의 uniqueness에 관한 option으로 sequential node인지 아닌지를 설정하는 것이다.
Persistent mode와 Ephemeral mode
Persistent mode와 Ephemeral mode는 znode의 life cycle에 관한 설정으로, 모든 znode는 persistent 하거나 ephemeral 하지만 동시에 둘 다일 수는 없다.
Persistent mode로 생성된 znode는 명시적으로 삭제될 때까지 지워지지 않는, 우리가 일반적으로 생각하는 file과 같다.
그렇다면 Ephemeral mode는 어떻게 동작할까?
Ephemeral mode로 생성된 znode는 ZooKeeper서버와 znode를 생성하도록 요청한 클라이언트 사이의 connection이 종료되면 자동으로 지워진다. ephemeral node의 이런 특성을 이용하여 lock이나 leader election을 구현하기도 한다.
Sequence mode
Sequence mode는 znode의 uniqueness를 보장하기 위한 것이다.
sequence mode로 만들어진 znode는 주어진 이름 뒤에 int 범위의 10개의 숫자가 postfix로 붙는다.
이 숫자는 atomic 하게 증가하여 같은 이름으로 만든 node라고 해도 서로 다른 이름의 znode로 만들어준다.1)
ephemeral mode와 persistent mode 둘 다 sequence node로 만들 수 있다.
하지만 ephemeral mode와 sequence mode를 동시에 사용하여 node를 생성하는 것은 문제가 생길 수 있다. ZooKeeper서버와 ZooKeeper클라이언트는 비동기적으로 동작할 뿐 아니라 둘 사이의 connection은 빈번하게 끊길 수 있다.
따라서 ephemeral + sequence node를 생성하라고 요청하였을 때 성공인지 실패인지 응답이 와야 하지만 실제로는 응답이 오지 않고 timeout이 발생할 수 있다.
이때 성공인지 실패인지 알기 위해서는 node가 생성되었는지 확인해야 하는데 생성된 znode의 이름을 서버에서 결정하기 때문에 클라이언트는 znode의 생성 여부를 알 방법이 없다.
ZooKeeper를 사용하기 쉽게 해주는 curator라는 라이브러리에서는 이를 위해 protect mode라는 것을 도입하였다.
ACL (Access Control List)
znode는 ACL(Access control list)을 이용하여 각각의 znode에 접근권한을 설정할 수 있다.
하지만 unix-like 파일시스템과 다르게 znode에는 user/group/others라는 개념이 존재하지 않는다.
이때 조심해야 하는 것이 있다. 각 znode의 ACL은 자기 자신의 ACL이고, 자식들에게 recursive 하게 적용되지 않는다는 것이다.
즉, /some-node에 권한을 설정하였다고 해도 /some-node/child에는 권한이 설정되지 않는다는 것이다.
ACL Permissions
ZooKeeper에서의 권한은 unix-like 파일시스템의 권한과 크게 다를 것은 없다.
특정 권한들에 대해 allow flag가 있어서 이것이 어떻게 설정되는가에 따라서 해당 권한을 실행시킬 수 있는지가 결정된다.
ZooKeeper에서 설정할 수 있는 ACL의 종류는 아래의 5가지이다.
1. CREATE : 해당 znode의 자식 node를 만들 수 있는 권한.
2. READ : 해당 znode에서 data를 읽고 와 그 자식들의 목록을 읽을 수 있는 권한.
3. WRITE : 해당 znode에 값을 쓸 수 있는 권한.
4. DELETE : 해당 znode의 자식들을 지울 수 있는 권한.
5. ADMIN : 해당 znode에 권한을 설정할 수 있는 권한.
unix-like file system과 다른 부분이 2가지 있다.
첫 번째는 보통의 file system에는 없는 CREATE와 DELETE라는 권한이 존재하여 자식 node를 생성하고 삭제할 수 있는 권한이 있다는 것이다.
unix-like file system에서 directory는 실제로는 자기 자식의 list를 가지고 있는 file이다.
그래서 자식을 만들고 지우는 것은 부모 directory에 내용을 변경하는 것이고, 부모 directory에 쓰기 권한이 있는지가 자식을 만들고 지우는 권한이 된다.
하지만 ZooKeeper에서는 모든 znode가 directory이기도 하고, file이기도 해서 자기 자신에 대한 쓰기 권한과 자식 node에 대한 생성/삭제 권한을 같이 쓸 수 없다.
Schemes
ZooKeeper는 unix-like 시스템과 다르게 각 znode에 user/group/others라는 개념이 존재하지 않는다. 대신 scheme이라는 것을 이용하여 권한을 구분하게 되어 있다.
built in으로 제공되는 설정할 수 있는 scheme은 아래와 같이 4가지가 있다.
- WORLD
- AUTH
- DIGEST
- IP
WORLD는 모든 요청에 대해 허락하는 것이고, AUTH는 authenticated된 session에서 들어오는 요청에 대해서만 허락하는 것이다.
DIGEST는 username과 password를 보내서 이를 이용하여 만든 MD5 hash값이 같은 요청에 대해서만 처리하는 것이고, IP는 해당 IP에서의 요청만을 처리하도록 하는 것이다.
Stat
ZNode는 node와 node의 data에 관한 여러 정보를 들고 있고, 이것을 stat이라고 부른다.
stat이 가지는 정보는 다음과 같다.
czxid : znode를 생성한 트랜잭션의 id
mzxid : znode를 마지막으로 수정 트랜잭션의 id
ctime : znode가 생성됐을 때의 시스템 시간
mtime : znode가 마지막으로 변경되었을 때의 시스템 시간
version : znode가 변경된 횟수
cversion : znode의 자식 node를 수정한 횟수
aversion : ACL 정책을 수정한 횟수
ephemeralOwner : 임시 노드인지에 대한 flag
dataLength : data의 길이
numChildren : 자식 node의 수
CreateMode.java
package org.apache.zookeeper;
...
@InterfaceAudience.Public
public enum CreateMode {
/**
* The znode will not be automatically deleted upon client's disconnect.
*/
PERSISTENT (0, false, false),
/**
* The znode will not be automatically deleted upon client's disconnect,
* and its name will be appended with a monotonically increasing number.
*/
PERSISTENT_SEQUENTIAL (2, false, true),
/**
* The znode will be deleted upon the client's disconnect.
*/
EPHEMERAL (1, true, false),
/**
* The znode will be deleted upon the client's disconnect, and its name
* will be appended with a monotonically increasing number.
*/
EPHEMERAL_SEQUENTIAL (3, true, true);
private static final Logger LOG = LoggerFactory.getLogger(CreateMode.class);
private boolean ephemeral;
private boolean sequential;
private int flag;
...
}Zookeeper 서버 구성도
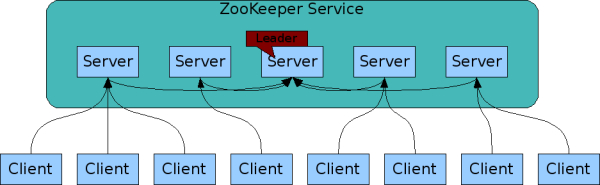
-
각각의 서버는 다른 서버의 정보를 가지고 있음
-
client는 하나의 서버랑 연결
커넥션을 유지 (sends requests, gets response, gets watch events, sends heart beats)
만약 서버와 연결이 끊어지면 다른 서버랑 통신 -
Zookeeper 서버는 Leader와 Follower로 구성
자동으로 Leader 선정 & 모든 데이터 저장을 주도
Client에서 Server(Follower)로 데이터 저장을 시도 할 때,
Server(Follower) -> Server(Leader) -> Server(Follower) 로 데이터 전달
=> 팔로어 중 과반수의 팔로어로 부터 쓸 수 있다는 응답을 받으면 쓰도록 지시 -
모든 서버에 동일한 데이터가 저장된 후 클라이언트에게 응답(동기 방식)
서버 간의 데이터 불일치가 발생하면 데이터 보정이 필요
=> 과반수의 룰을 적용하기 때문에 홀수로 구성하는 것이 데이터 정합성 측면에서 유리
