Index
- B-Tree 형태
- 테이블에서 한 개 이상의 속성을 이용하여 생성함
- 데이터를 쉽고 빠르게 찾을 수 있음
- 데이터의 수정, 삭제 등 변경이 발생하면 인덱스의 재구성이 필요함
- MySQL은 필요에 따라 각각의 인덱스를 사용해 효율적인 검색을 수행함
Index 생성시 고려 사항
- 조건절에 자주 사용되는 속성이어야 함
- 조인에 자주 사용되는 속성이어야 함
- 단일 테이블에 인덱스가 많아지면 속도가 느려짐 (테이블 당 4~5개 정도 권장)
- 속성이 가공되는 경우 사용하지 않음
- 속성의 모든 값이 다를 수록 유리함 (Unique 일수록)
- 업데이트가 잦은 열에 인덱스를 추가할 경우 성능에 부정적임
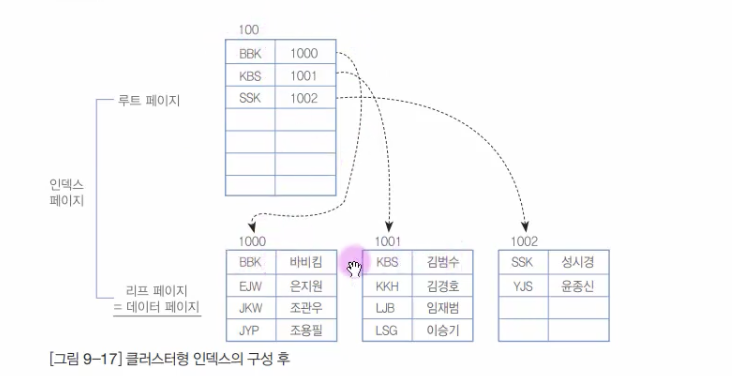
Cluster Index
- 각각의 PK가 루트 노드에 저장됨
- 리프 노드는 정렬된 상태의 저장된 테이블 자체
➡️ 데이터 접근 시 인덱스를 따라 순차적으로 검색할 수 있어 성능이 향상됨
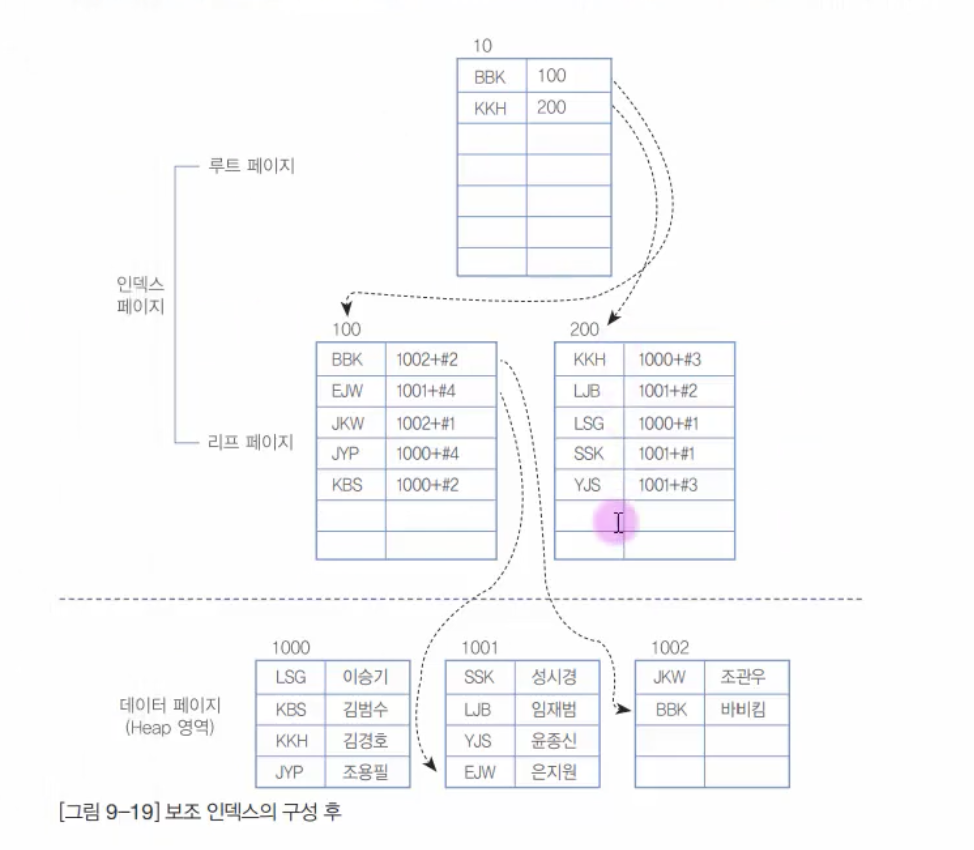
Secondary Index
- 클러스터 인덱스가 아닌 모든 인덱스는 세컨더리 인덱스
- 루트 노드는 및 중간 노드는 정렬된 키 값
- 리프 노드는 테이블의 실제 데이터와 별도로 저장됨
- 리프 노드는 테이블 상의 데이터 위치를 지정함
➡️ <블록 번호-블록 내의 row순번>
- 특정 키 값을 찾는 경우에는 성능 좋음
- 범위 검색은 데이터가 저장된 블록이 다를 수 있어서 성능이 안좋을 수 있음
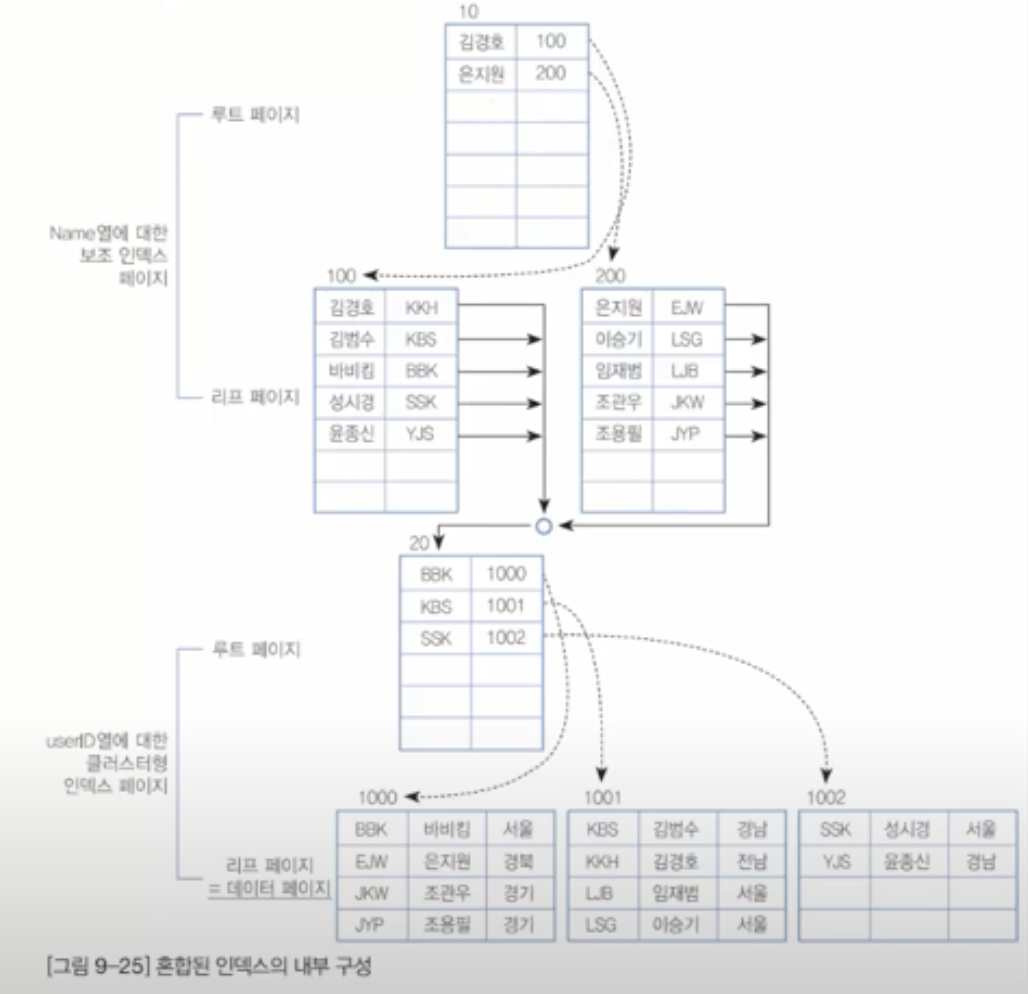
혼합 인덱스
- MySQL 의 인덱스
- 클러스터 인덱스와 세컨더리 인덱스의 혼합
- 세컨더리 인덱스에서 검색해 PK 를 찾고, 클러스터 인덱스에서 최종 데이터를 찾음