https://leetcode.com/problems/implement-trie-prefix-tree
개요
- Trie를 구현하기
- input 코드 예시
Trie trie = new Trie(); trie.insert("apple"); trie.search("apple"); // return True trie.search("app"); // return False trie.startsWith("app"); // return True trie.insert("app"); trie.search("app"); // return True search()startsWith()insert()메소드를 가진 트라이 구현- 모든 문자는 영문이며, 소문자로 주어진다.
Trie
Trie의 특징
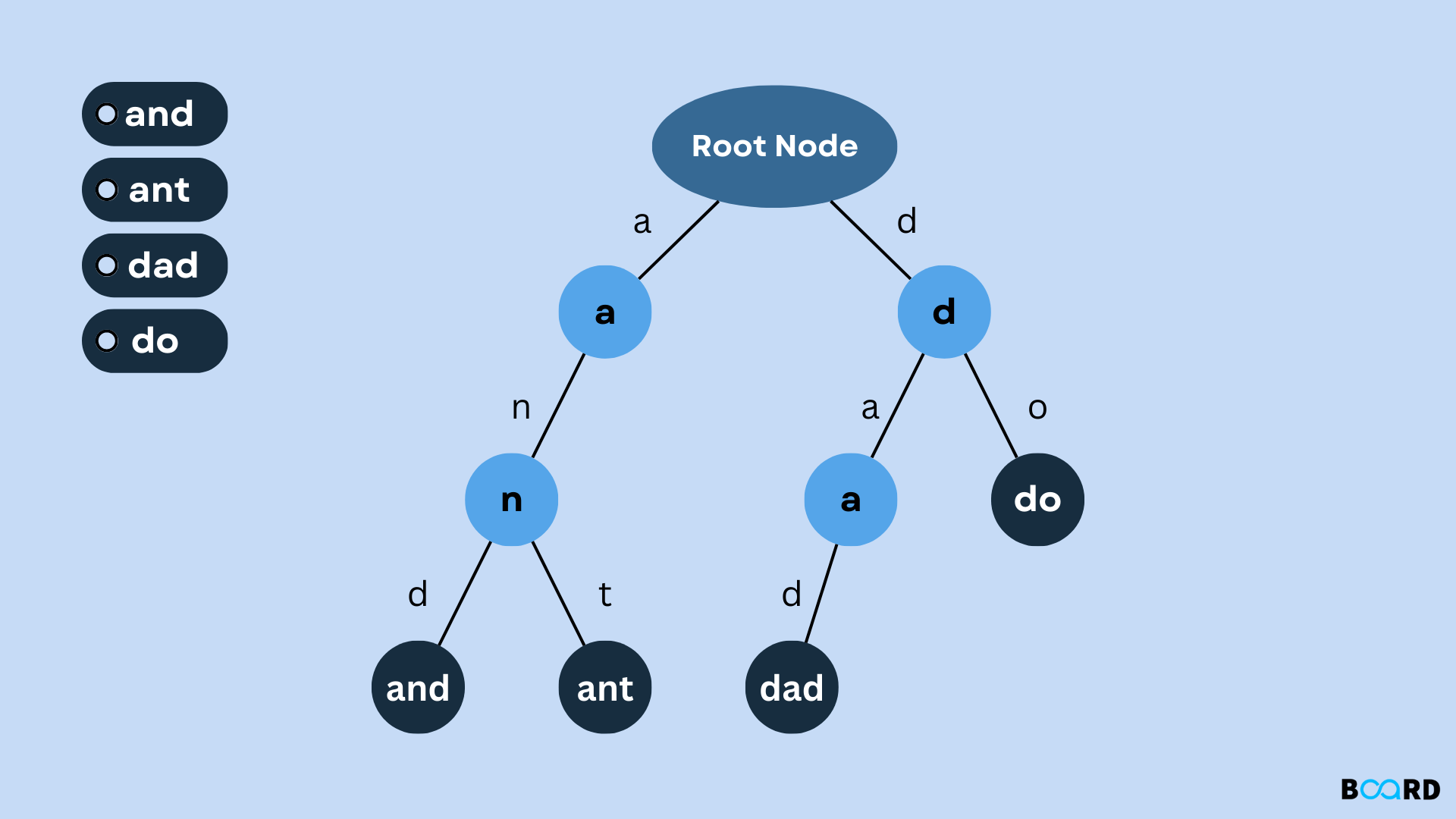
- 트라이는 트리의 일종이다.
- 문자열을 검색하기 위한 자료구조이다.
- 문자열의 키를 효율적으로 저장하고 이를 이용해 검색할 수 있다.
- 접두사 검색, 자동 완성, 사전 검색에 이용할 수 있다.
구현
트라이를 직접 구현하기
구현체
- Tree
- Trie는 트리의 종류이므로,
TreeNode를 생성한다. - 자신의 하위 노드를 담은
children배열을 멤버로 갖는다.- 각각의
TreeNode하나의 문자열 당 하나의TreeNode를 가지므로, 아스키 코드가 인덱스로 활용될 수 있다.
- 각각의
- 자신이 문자열의 마지막인지 기록하는
isEndOfStr를 멤버로 갖는다. TreeNode생성시 배열이 초기화된다.
- Trie는 트리의 종류이므로,
class TreeNode {
TreeNode[] children;
boolean isEndOfStr = false;
public TreeNode() {
childNodes = new TreeNode['z' - 'a' + 1];
}
}- 초기화
- 멤버 변수로root를 갖는다.- 인스턴스 생성시
root또한 초기화된다.
- 인스턴스 생성시
class Trie {
TreeNode root;
public Trie() {
root = new TreeNode();
}
...
}- 삽입
String을 파라미터로 받는다.- 순차적으로 word의 각 문자가 root 노드에 존재하는지 살핀다.
- 문자가
TreeNode에 없다면, 해당 문자를 현재 노드에 추가한다. 또한 해당 노드로 이동한다. - 문자가
TreeNode에 있다면, 해당 노드로 이동한다.
- 문자가
- 모든 문자를 탐색했다면 마지막 노드의
isEndOfStr값을true로 변경한다.
class Trie {
...
public void insert(String word) {
TreeNode cur = root;
for (char c : word.toCharArray()) {
if (cur.children[c - 'a'] == null)
cur.children[c - 'a'] = new TreeNode();
cur = cur.children[c - 'a'];
}
cur.isEndOfStr = true;
}
...
}- 검색
String을 파라미터로 받는다.- 순차적으로 word의 각 문자가 root 노드에 존재하는지 살핀다.
- 문자가
TreeNode에 없다면,false를 반환한다. - 문자가
TreeNode에 있다면, 해당 노드로 이동한다.
- 문자가
- 모든 문자를 탐색했다면 마지막 노드의
isEndOfStr값이true인지 확인한다.true라면 해당 문자는 저장된 상태이다.false라면 해당 문자는 저장되지 않았다.
class Trie {
...
public boolean search(String word) {
TreeNode cur = root;
for (char c : word.toCharArray()) {
if (cur.children[c - 'a'] == null)
return false;
cur = cur.children[c - 'a'];
}
return cur.isEndOfStr;
}
...
}- 접두사 검색
String을 파라미터로 받는다.- 순차적으로 word의 각 문자가 root 노드에 존재하는지 살핀다.
- 문자가
TreeNode에 없다면,false를 반환한다. - 문자가
TreeNode에 있다면, 해당 노드로 이동한다.
- 문자가
- 모든 문자를 탐색했다면 해당 접두사로 시작하는 문자가 있음을 의미한다.
class Trie {
...
public boolean startsWith(String word) {
TreeNode cur = root;
for (char c : prefix.toCharArray()) {
if (cur.children[c - 'a'] == null)
return false;
cur = cur.children[c - 'a'];
}
return true;
}
...
}결과
class Trie {
Trie children[] = new Trie[26];
boolean eow = false;
public Trie() {
for(int i=0; i<26; i++) {
children[i] = null;
}
}
public void insert(String word) {
Trie curr = this;
for(int i=0; i<word.length(); i++) {
int idx = word.charAt(i)-'a';
if(curr.children[idx]==null) {
curr.children[idx] = new Trie();
}
curr = curr.children[idx];
}
curr.eow = true;
}
public boolean search(String word) {
Trie curr = this;
for(int i=0; i<word.length(); i++) {
int idx = word.charAt(i)-'a';
if(curr.children[idx]==null) {
return false;
}
curr = curr.children[idx];
}
return curr.eow;
}
public boolean startsWith(String prefix) {
Trie curr = this;
for(int i=0; i<prefix.length(); i++) {
int idx = prefix.charAt(i)-'a';
if(curr.children[idx]==null) {
return false;
}
curr = curr.children[idx];
}
return true;
}
}
얼마전에 elastic search에 대해 포스팅했는데, 트라이 자료 구조와 비슷한 부분이 있어서 흥미로웠다.
어떤 작은 단위로 나누고 그걸 포함한 풀 텍스트 or 도큐먼트를 참조하게 한다는 것이 비슷한 것 같다.
자료 구조를 공부한 덕분에 사용했지만 그냥 넘어갔던 인프라들의 원리들이 조금 더 흥미롭게 다가오는 것 같다.
사실 Map으로도 구현하고 배열로도 구별했는데, 트라이의 경우에는 배열의 공간복잡도가 확실히 더 좋은 것 같다.
다른 풀이 역시 대부분 Map과 배열을 이용한 것 같다.
하지만 배열의 경우 인덱스 처리와 null 처리에 항상 신경써야 할 것 같다...!
항상 간과하게 되는 부분인데, 이번 구현에서도 실수했다
