📌2/28 EDA CCTV 2
pandas 기초
데이터 프레임
Series와 DataFrame
- pd.Series()
= index, value - pd.DataFrame
= index, value, column
# 표준 정규 분포에서 샘플링한 난수 생성
data = np.random.randn(6,4)
data데이터 프레임 정보 탐색
-
df.head() : 상단부터 데이터 5개 출력
-
df.tail() : 하단부터 데이터 5개 출력
-
df.info() : 데이터 프레임의 기본정보 확인
-
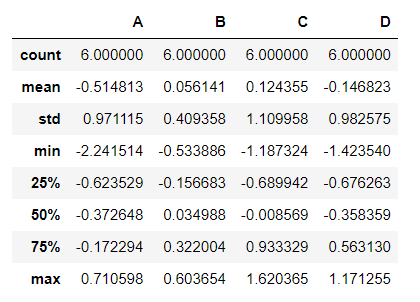
df.describe() : 데이터 프레임의 기술통계 정보 확인
(개수,평균,표준편차,최소값,최대값 확인)
- df.index : 인덱스 값을 리스트 형태로 반환하여 보여줌
- df.columns : 컬럼 값을 리스트 형태로 반환하여 보여줌
- df.values : 벨류 값을 리스트 형태로 반환하여 보여줌
데이터 정렬
- sort_values()
특정 컬럼(열)을 기준으로 데이터를 정렬합니다
df.sort_values(by = "기준컬럼명")
df.sort_values(by = "B", ascending = True, inplace = True)- ascending=Truc/False 오름차순/내림차순 정렬
- inplace=True 데이터 변경 사항을 원본에 바로 저장
데이터 선택
#한 개의 컬럼 선택
df["A"]
-> 시리즈 타입으로 출력된다, 숫자가 아닌 문자일때는 대괄호, 큰따옴표 생략 가능
# 두 개 이상 컬럼 선택
df[["A", "B"]]
-> 데이터프레임 타입으로 출력offset index
- [n:m] : n부터 m-1까지
- 인덱스나 컬럼의 이름으로 slice하는 경우는 끝을 포함합니다
loc : location
- index 이름으로 특정 행, 열을 선택합니다
df.loc[:,["A","B"]]
-> A, B컬럼의 모든 인덱스(모든 행) 보여줌
df.loc["20230202":"20230204","A":"C"]
-> 20230202 ~ 20230204 인덱스(행)의 A, c컬럼만 보여줌iloc : inter location
- 컴퓨터가 인식하는 인덱스 값으로 선택 (0부터 인덱스 시작)
df.iloc[3,2]
-> 3행 2열 보여줌
df.iloc[3:5, 0:2]
-> 3~4행 0~1열 보여줌
df.iloc[[1, 2, 4], [0, 2]]
-> 1,2,4행 0,2열 보여줌
df.iloc[:, 1:3]
->전체 행 1~2열 보여줌
조건으로 데이터 필터링 하는법
# A컬럼에서 0보다 큰 숫자(양수)만 선택 (T/F로 표시)
df["A"]>0
# 조건을 다시 대괄호에 씌운다-> 마스킹 한다
df[df["A"]>0]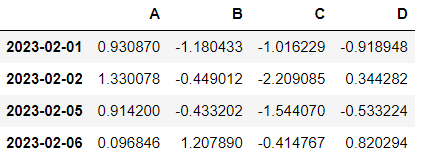
# -> A칼럼의 양수인 인덱스의 값들이 표시되는데 마스킹을 함으로써(전체라는 조건을 넣어서)
해당 인덱스의 다른 열들의 값도 표시된다컬럼 추가
- 기존 컬럼이 없으면 추가
- 기존 컬럼이 있으면 수정
df["E"] = ["one", "two", "one", "one", "five", "seven"]
-> "E" 컬럼 추가 , 인덱스(행)는 "one", "two", "one", "one", "five", "seven"
-> 인덱스(행) 갯수 맞춘다isin
특정 요소가 있는지
df["E"].isin(["two","five","seven"])
df[df["E"].isin(["two","five","seven"])]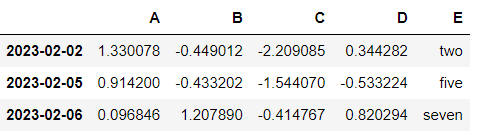
특정 컬럼 제거
- del
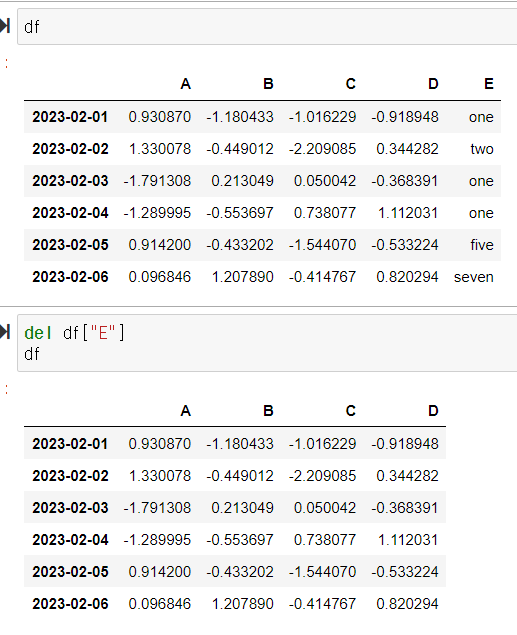
- drop( ) -> 컬럼 제거 이므로 axis=1을 꼭 넣어준다. 안그럼 오류남. 안적으면 0이 기본값이므로
apply() : 함수 기능을 적용해주는 메서드
df["A"].apply("sum")
-> A컬럼의 합계 출력
df[["A","B"]].apply("sum")
> A,B 컬럼의 합계 출력
# numpy 사용
df["A"].apply(np.sum)- 양수,음수 구분 함수 만들기
# 구분 함수만들기
def plusMinus(num):
return "plus" if num > 0 else "minus"
# 함수 적용하기
df["A"].apply(plusMinus)
# lambda 함수 이용하기
df["A"].apply(lambda num: "plus" if num > 0 else "minus")
마무리
pandas 기초 강의가 다른 강의들에 비해 유난히 길더니 따라서 해보는것도, 스터디 노트를 적는것도 너무너무 오래걸렸다. 왜 영상들이 10~15분 컷인지 알겠다. 한 호흡이 너무 기니까 금새 지루해지고 집중도가 뚝 떨어진다. 파이썬보다 재미있을줄 알았는데 .. 다음 강의부턴 다시 원래 길이니까 집중이 잘 되길 ..

study note