📌3/1 영상 강의 EDA CCTV3 ~ CCTV5
데이터 훑어보기
CCTV 데이터 훑어보기
1. 인구 현황 "소계" 컬럼을 기준으로 정렬하고 조회
CCTV_Seoul.sort_values(by="소계", ascending=False).head()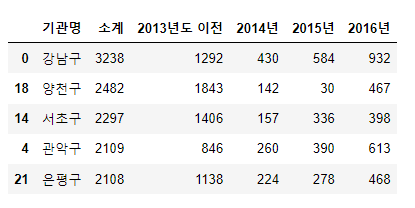
2. 최근 증가율 컬럼 추가 (기존 컬럼이 없으면 추가, 있으면 수정)
CCTV_Seoul["최근증가율"] = (
(CCTV_Seoul["2016년"] + CCTV_Seoul["2015년"] + CCTV_Seoul["2014년"] / CCTV_Seoul["2013년도 이전"] * 100)
)
CCTV_Seoul.head().sort_values(by="최근증가율", ascending=False).head()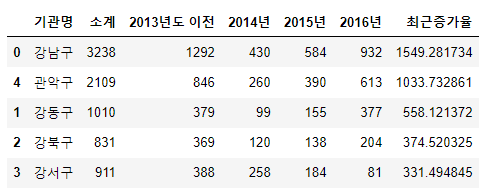
인구 현황 데이터 훑어보기
pop_Seoul.head()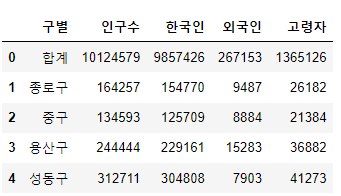
1. drop( ) 필요없는 부분 삭제
pop_Seoul.drop([0], axis=0, inplace=True)
pop_Seoul.head()
-> axis=0 가로, axis=1 세로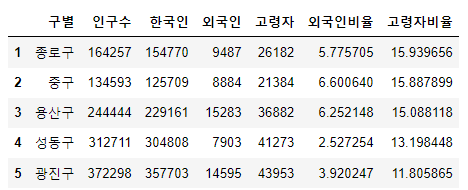
2. unique( ) 어떤 데이터들이 한번 이상 나타났는지 그 고유한 값을 나타내줌
pop_Seoul["구별"].unique()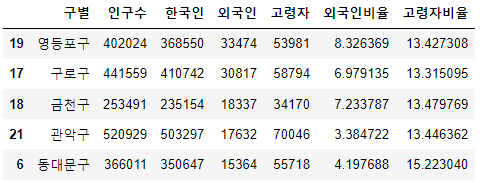
len(pop_Seoul["구별"].unique())
-> 25 출력
#len() 메서드로 "구별" 컬럼의 전체 데이터 길이 파악. 데이터 양이 많을때 사용하면 좋다. 3. 외국인 비율, 고령자 비율
pop_Seoul["외국인비율"] = pop_Seoul["외국인"] / pop_Seoul["인구수"] * 100
pop_Seoul["고령자비율"] = pop_Seoul["고령자"] / pop_Seoul["인구수"] * 100
pop_Seoul.head()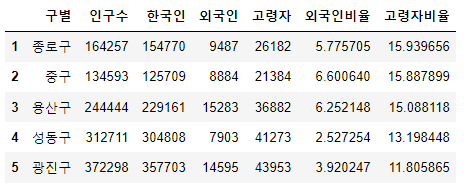
4. 원하는 기준으로 정렬
pop_Seoul.sort_values(by=["외국인"], ascending=False).head()
# by 생략가능, 오름차순일때 ascending=True 생략가능)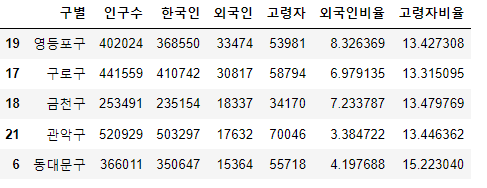
-> 차례대로 외국인 비율, 고령자, 고령자비율로 정렬 시켜본다
두 데이터 합치기
pd.concat( )
pd.merge( )
pd.join( )
pd.merge( left, right )
- 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
- 기준이 되는 컬럼이나 인덱스를 키값이라고 합니다
- 기준이 되는 키값은 두 데이터 프레임에 모두 포함되어 있어야 합니다
# 딕셔너리 안의 리스트 형태 -> 열 값으로 생성
left = pd.DataFrame({
"key": ["k0","k4","k2","k3"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"]
})
left

# 리스트 안의 딕셔너리 형태 -> 행 값으로 생성
right = pd.DataFrame([
{"key":"k0", "C":"C0", "D":"D0"},
{"key":"k1", "C":"C1", "D":"D1"},
{"key":"k2", "C":"C2", "D":"D2"},
{"key":"k3", "C":"C3", "D":"D3"}
])
right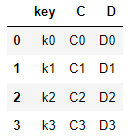
1. merge( )의 옵션들
-
pd.merge(left,right, on="key")
key값을 기준으로 공통된 부분만 나옴 , how="inner"가 디폴드값으로 되어있다(교집합) -
pd.merge(left,right, how="left", on="key")
left의 key값을 기준으로 병합해라 -> right에 없는 값은 NaN으로 표시된다 -
pd.merge(left,right, how="right", on="key")
right의 key값을 기준으로 병합해라 -> right에 없는 값은 NaN으로 표시된다 -
pd.merge(left,right, how="outer", on="key")
key값을 기준으로 두 데이터 합집합
2. 년도별 데이터 컬럼 삭제
년도별 데이터 컬럼 삭제
- del -> 원본에서도 삭제된다
- drop( ) -> 원본은 유지된다. inplace=True로 수정된 사항을 원본으로 저장하자
del data_result["2014년"]
data_result.drop(["2015년","2016년"], axis = 1, inplace=True)3. 인덱스 변경
- set_index()
선택한 컬럼을 데이터 프레임의 인덱스로 지정
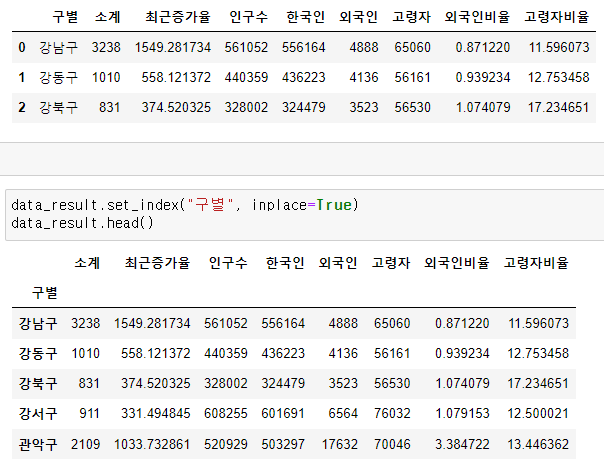
-> 맨 앞의 인덱스가 사라지고 구별 컬럼이 인덱스가 됐다
-> 데이터를 정리하는 과정에서 인덱스를 재지정할 때가 있다
4. 상관계수
- corr()
correlation - 상관계수가 0.2이상인 데이터를 비교하는 것은 의미가 있다 (비교를하는 최소한의 근거가 된다)
- info( )를 확인했을 때 데이터 타입에 문자열이 있다면 연산이 되지 않는다
data_result.corr()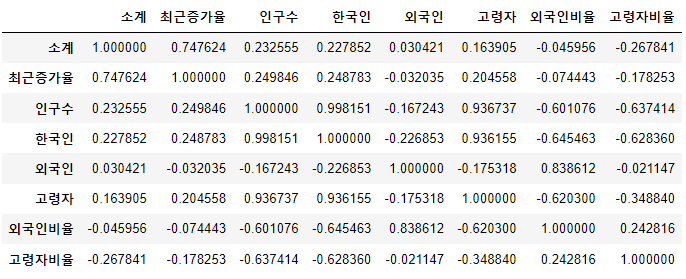
-> 1.0을 기준으로 상관계수가 나온다
matplotlib 기초
matplotlib 그래프 기본 형태
plt.figure(figsize=(10,6)) #도화지 크기
plt.plot(x, y)
plt.show()
# figure로 열고 show로 닫는다예제1. 그래프 기초 : 삼각함수 그리기
- np.arang(a,b,s) : a부터 b까지 s의 간격
- np.sin(value)
import numpy as npt = np.arange(0, 12, 0.01)
y = np.sin(t)plt.figure(figsize=(10,6))
plt.plot(t, np.sin(t))
plt.plot(t, np.cos(t))
plt.show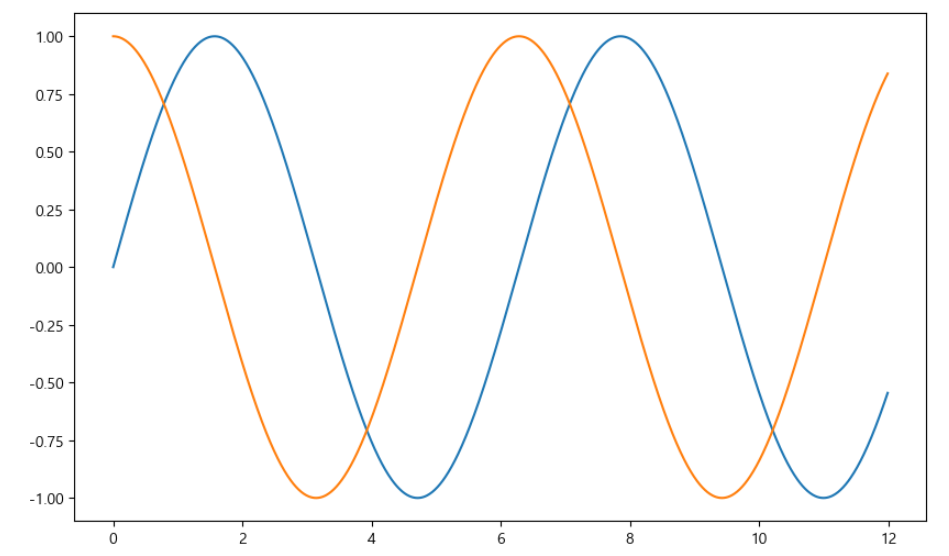
- 격자무늬 추가
- 그래프 제목 추가
- x축, y축 제목 추가
- 주황색, 파란색 선 데이터 의미 구분
def drawGraph():
plt.figure(figsize=(10,6))
plt.plot(t, np.sin(t), label="sin")
plt.plot(t, np.cos(t), label="cos")
plt.grid(True)
plt.legend(loc="upper left")# 범례 (빈 괄호일때 빈 공간중 적절한곳에 배치, 배치 지점 숫자로 설정 가능 loc=2 이런식으로)
plt.title("Example of sinewave")
plt.xlabel("time")
plt.ylabel("Amplitude") #진폭
plt.show
drawGraph()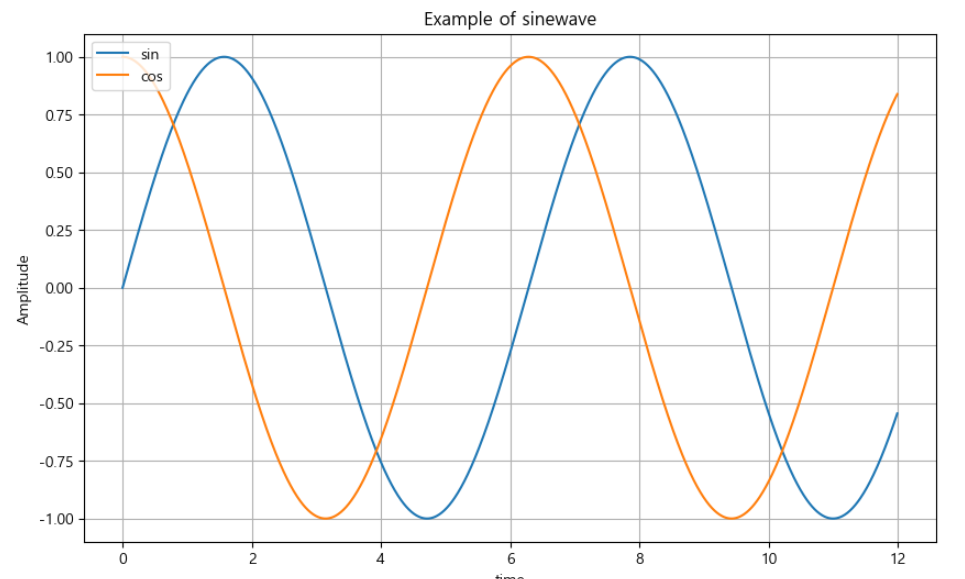
예제2. 그래프 커스텀
1번 그래프
t = np.arange(0, 5, 0.5) #0부터 5까지 0.5간격으로plt.figure(figsize=(10,6))
plt.plot(t, t, "r--") #red dashed
plt.plot(t, t ** 2, "bs") # blue squre
plt.plot(t, t ** 3, "g^") # green 위로 향하는 화살표
plt.show()
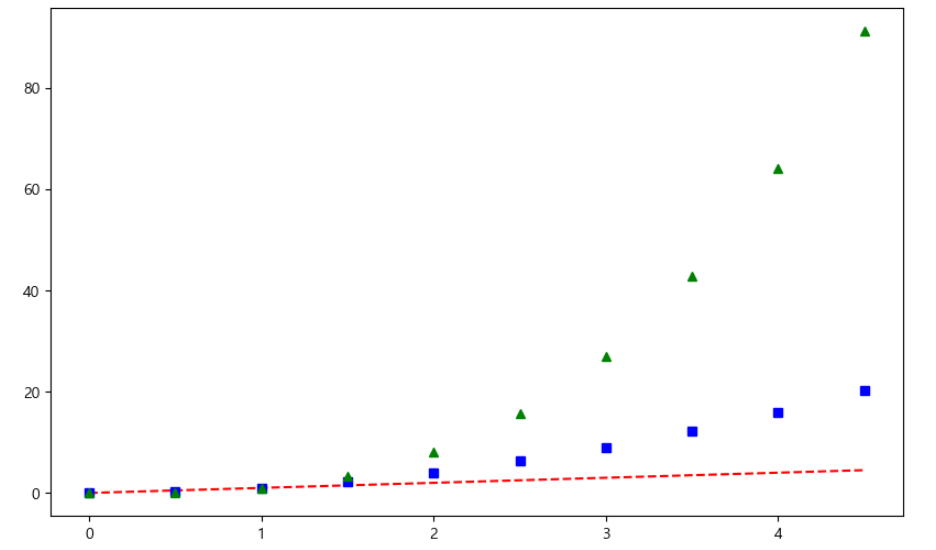
2번 그래프
# t = [0, 1, 2, 3, 4, 5, 6] : 아래와 같이 표시할 수 있다
t = list(range(0,7))
y = [1, 4, 5, 8, 9, 5, 3]
def drawGraph1():
plt.figure(figsize=(10,6))
plt.plot(
t,
y,
color="green",
linestyle="-",
marker="o",
markerfacecolor="blue",
markersize=12,
)
plt.grid(True)
plt.xlim([-0.5, 6.5])
plt.ylim([-0.5, 9.5])
plt.show()
drawGraph1()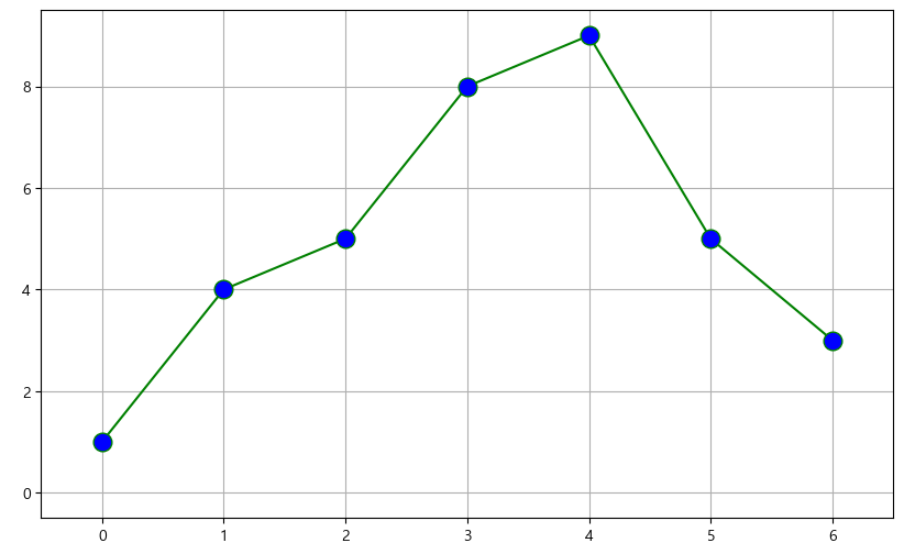
예제3. scatter plot
t = np.array(range(0,10))
y = np.array([9, 8, 7, 8, 3, 2, 4, 4, 2, 6]) def drawGraph():
plt.figure(figsize=(10,6))
plt.scatter(t,y)
plt.show()
drawGraph()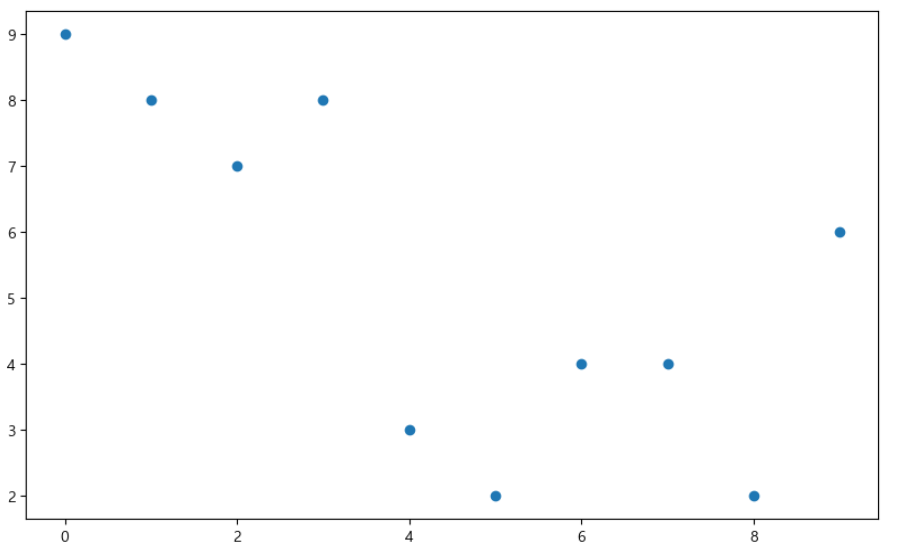
scatter plot 커스텀
colormap = t
def drawGraph():
plt.figure(figsize=(20,6))
plt.scatter(t, y, s=150, c=colormap, marker=">")
plt.colorbar()
plt.show()
drawGraph()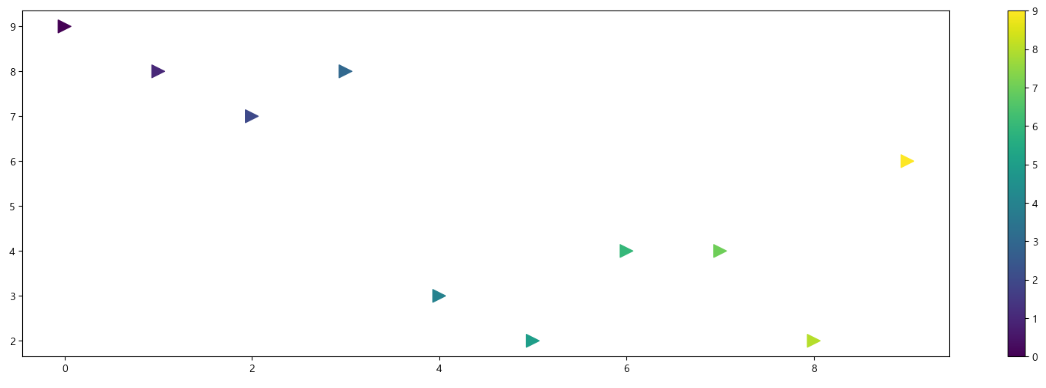
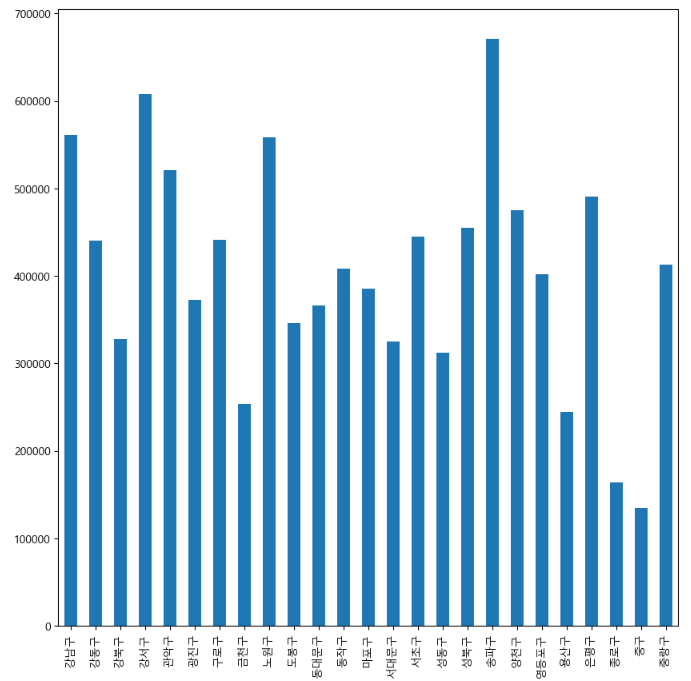
예제4. pandas에서 plot 그리기
- matplotlib 기능을 가져와서 사용합니다
data_result["인구수"].plot(kind="bar",figsize=(10,10))
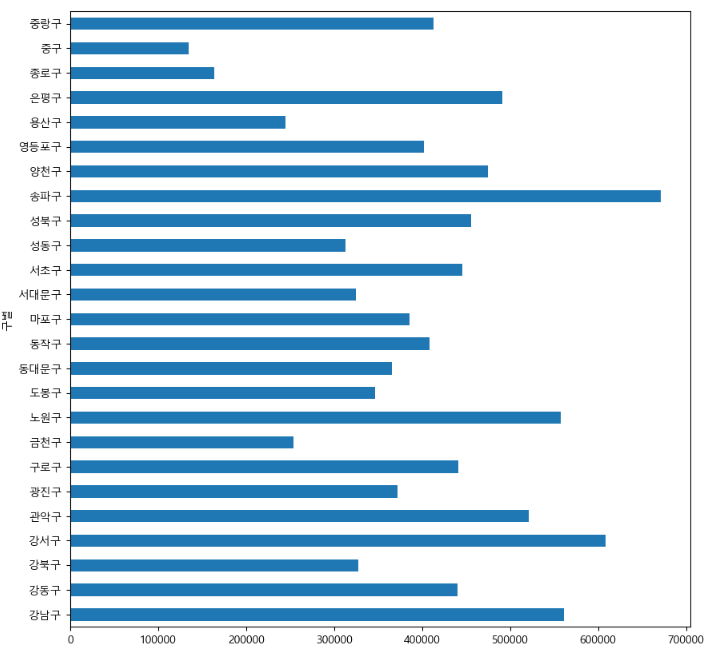
data_result["인구수"].plot(kind="barh",figsize=(10,10))
-> bar 뒤에 h넣으면 가로로 보여줌 (horizon 의 h)
5. 데이터 시각화
def drawGraph():
data_result["소계"].sort_values().plot(
kind="barh", grid=True, title="가장 CCTV가 많은 구", figsize=(10,10));
drawGraph()
# 소계를 기준으로 데이터를 내림차순으로 정리하여 그래프화 하기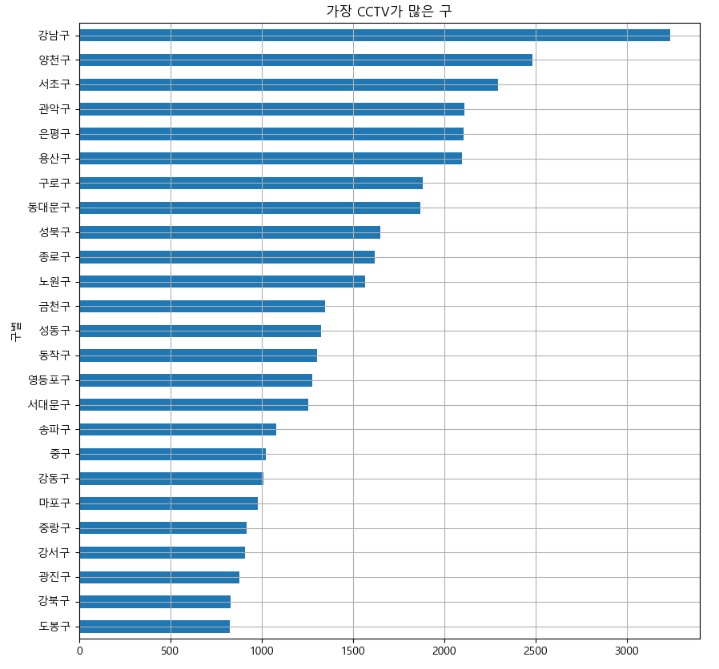
6. 데이터의 경향 표시
마무리
스터디 노트 적을게 너무 많아서 남은 챕터는 내일 적어야겠다.
이론 강의때와는 다르게 시각화 수업은 뭔가 어렵지만 재미있다. 파이썬도 어렵고 재미있었는데 재미가 차지하는 비중이 매우 작았달까.. 아주아주 가아끔 재미있었달까..
내일은 새로운 데이터로 실습하는데 기대된다.
그리고 팀 스터디가 있는데 채용 스크랩보다 심화된 내용을 정리해야해서 오전 시간에 스터디 준비를 해야할 것 같다. 오전에 볼 일이 있는데 호다닥 다녀와서 해야겠다
