📌3/13 영상 강의 유가분석 3~5
셀레니움 기본
driver.quit(), driver.close() : 접근한 웹페이지 닫기
driver.maximize_window() : 화면 최대 크기 설정
driver.minimize_window() : 화면 최소 크기 설정
driver.set_window_size() : 화면 크기 설정
driver.refresh() : 새로고침
driver.back() : 뒤로가기
driver.forward() : 앞으로 가기
first_content = driver.find_element(By.CSS_SELECTOR,"#content > div.cover-masonry > div > ul > li:nth-child(1)")
first_content.click() : 클릭
driver.execute_script("window.open('https://www.naver.com')") : 새로운 탭 생성
driver.switch_to.window(driver.window_handles[0]) : 탭 이동
화면 스크롤
driver.execute_script("return document.body.scrollHeight") : 스크롤 가능한 높이(길이)
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);") : 화면 스크롤 하단 이동
driver.save_screenshot("./last_height.png") : 현재 보이는 화면 스크린샷 저장
driver.execute_script("window.scrollTo(0,0);") : 화면 스크롤 상단 이동
<특정 태그 지점까지 스크롤 이동>
from selenium.webdriver import ActionChains
some_tag = driver.find_element(By.CSS_SELECTOR,"#content > div.cover-masonry > div > ul > li:nth-child(5)")
action = ActionChains(driver)
action.move_to_element(some_tag).perform()
검색어 입력
- CSS_SELECTOR
- XPATH - beautifilsoup에서 사용못함
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(executable_path="../driver/chromedriver.exe ")
driver.get("https://pinkwink.kr")
# 1. 돋보기 버튼을 선택
from selenium.webdriver import ActionChains
search_tag = driver.find_element(By.CSS_SELECTOR, '#header > div.search')
action = ActionChains(driver)
action.click(search_tag)
action.perform()
# 2. 검색어를 입력
driver.find_element(By.CSS_SELECTOR,'#header > div.search.on > input[type=text]').send_keys("딥러닝")
# 3. 검색 버튼 클릭
driver.find_element(By.CSS_SELECTOR,'#header > div.search.on > button').click()'//' : 최상위
'*' : 자손 태그
'/' : 자식 태그
'div[1]' : div 중에서 1번째 태그
2. selenium + beautifulsoup
- 현재 화면의 html 코드 가져오기
driver.page_source
from bs4 import BeautifulSoup
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
soup.select(".post-item")
contents = soup.select(".post-item")
len(contents)
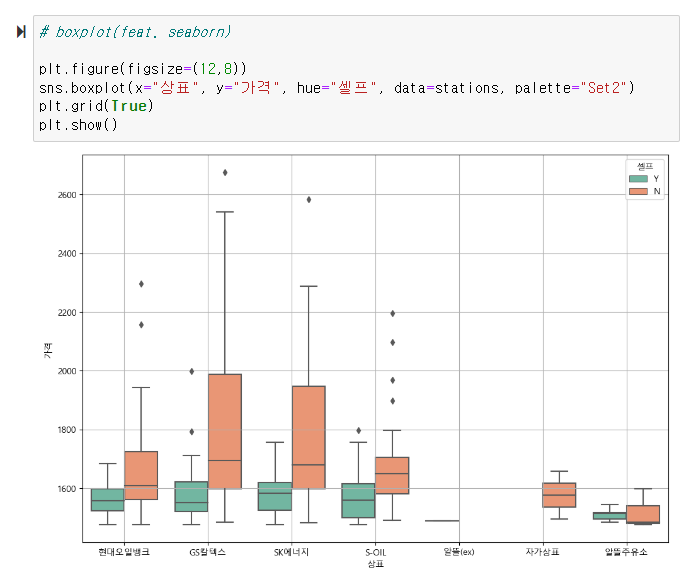
contents[2]셀프 주유소가 정말 저렴하나요?
1. 데이터 확보 및 정리
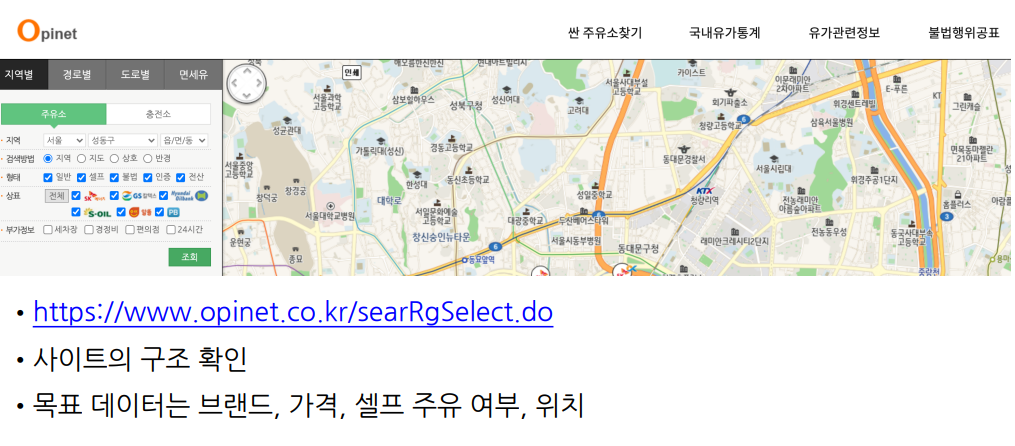
# 페이지 접근
url = "https://www.opinet.co.kr/searRgSelect.do"
driver = webdriver.Chrome("../data/chromedriver.exe")
driver.get(url)
# 팝업창 화면 전환 후 닫아주기 (한 코드로 정리), 팝업창 있다면 함수 호출
def main_get():
# 페이지 접근
url = "https://www.opinet.co.kr/searRgSelect.do"
driver = webdriver.Chrome("../data/chromedriver.exe")
driver.get(url)
time.sleep(3) # 화면이 다 로딩되야 다음 코드들이 실행되므로 시간을 준다
# 팝업창으로 전환
driver.switch_to_window(driver.windiow_handles[-1])
# 팝업창 닫아주기
driver.close()
time.sleep(2)
# 메인화면 창으로 전환
driver.switch_to_window(driver.windiow_handles[-1])
# 접근 URL 다시 요청
driver.get(url)
- 태그의 속성값 가져오기
sido_list[1].get_attribute("value")
- 파일 목록 한번에 가져오기
glob("../data/지역*.xls") #파일명에 지역*(모든글자)가 포함된 모든 파일
- 형식이 동일하고 연달아 붙이기만 하면 될 때는
pd.concat(tmp_raw)
- 데이터형 변환 object => float
stations["가격"] = stations["가격"].astype("float")
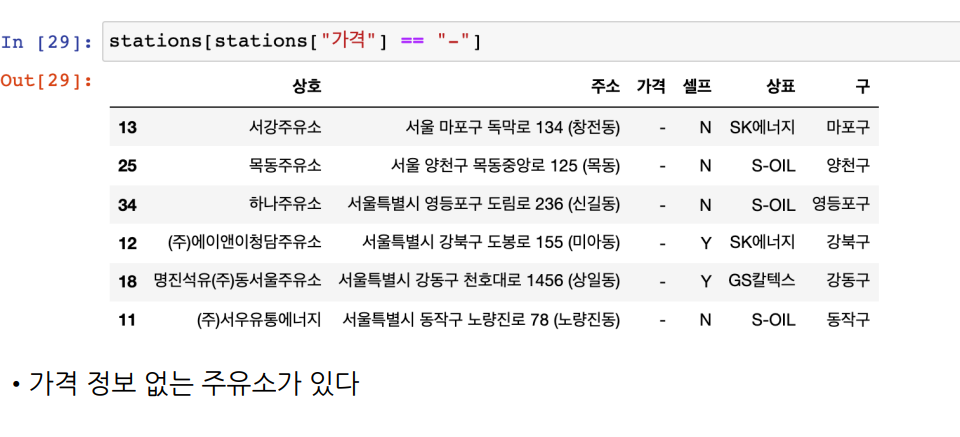
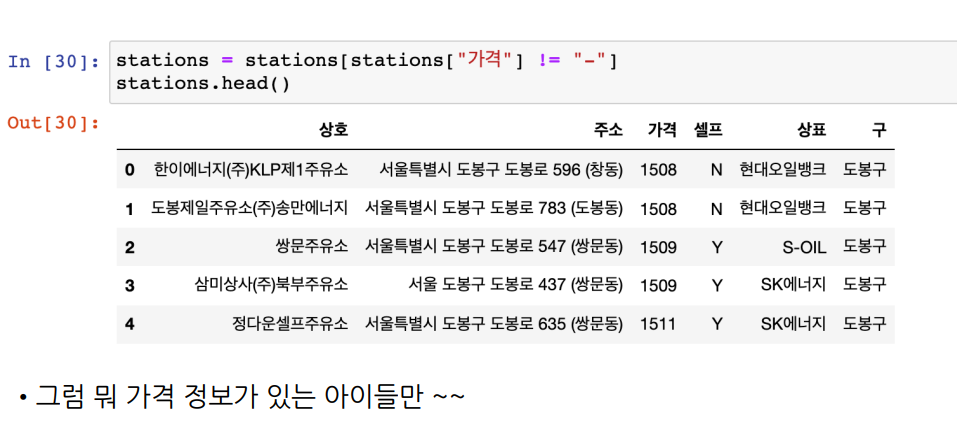
- 인덱스 재정렬
reset_index()
2. 주유 가격 정보 시각화
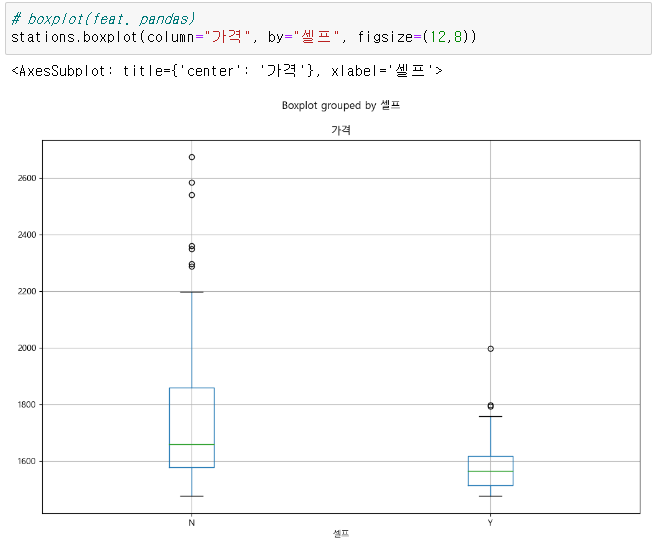
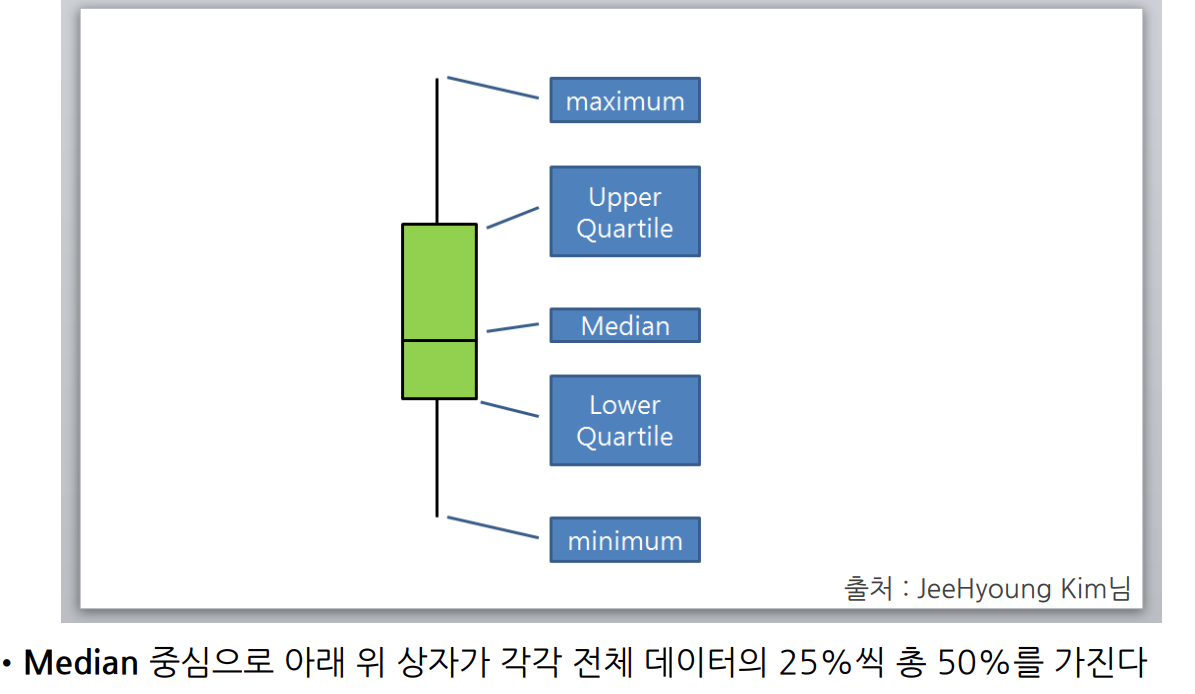
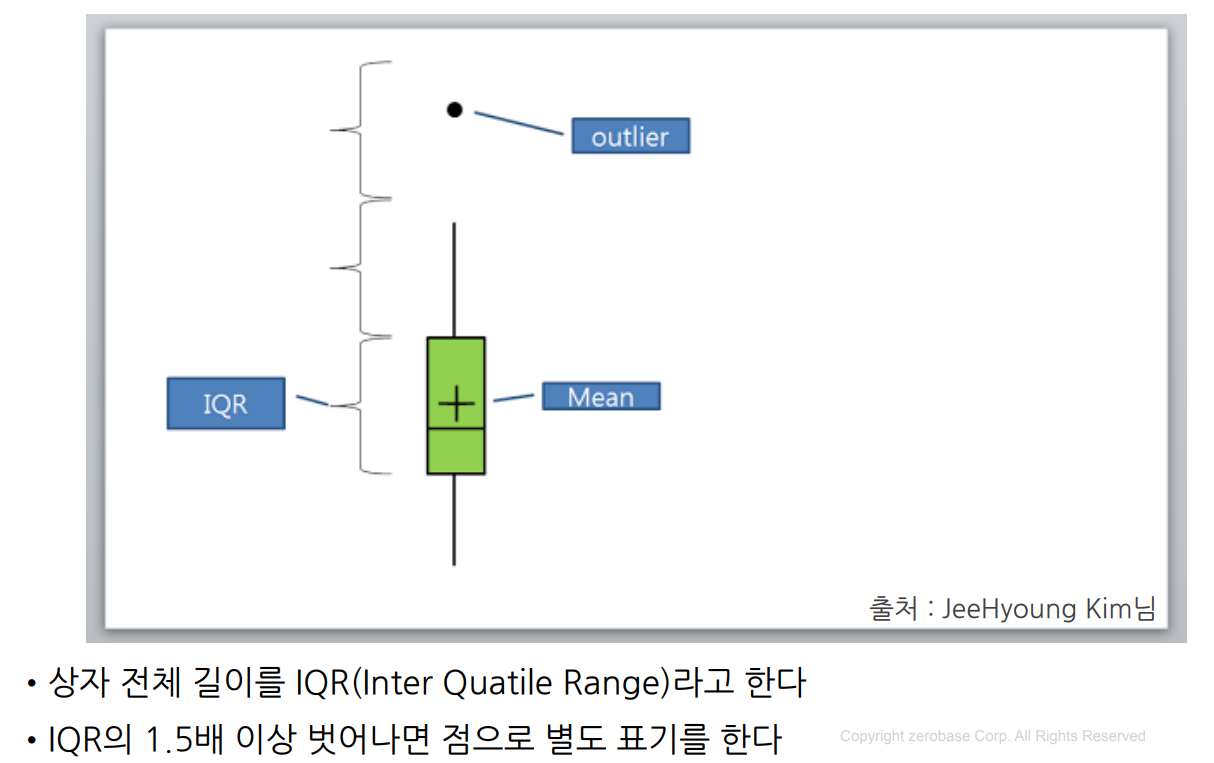
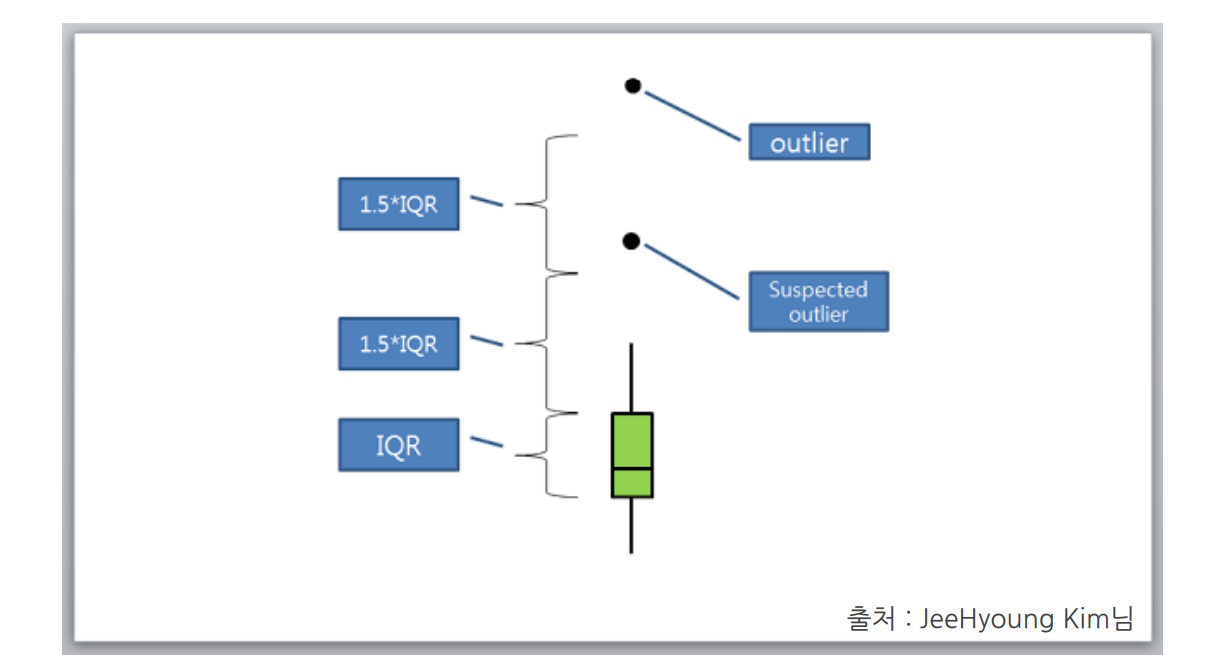
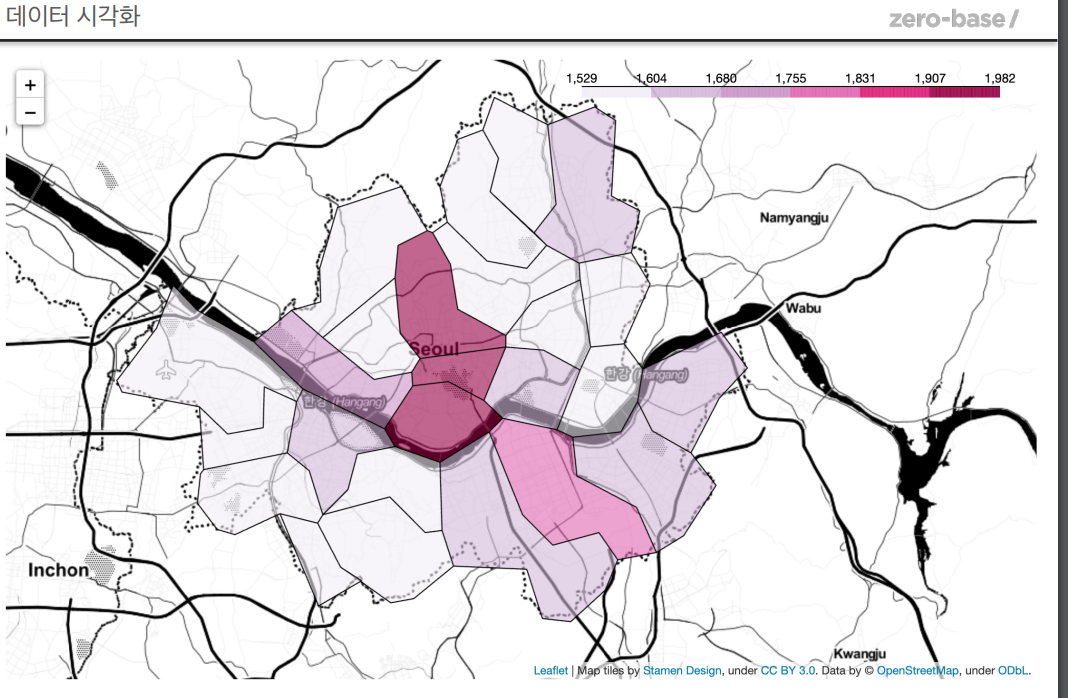
👍마무리
금,토,일 eda 테스트와 과제를 하느라 시간이 순삭됐다.. 이렇게 오래 걸릴줄은 몰랐는데 ..
아직 내가 강의를 다 못들어서 어려웠던 걸까
음 아무리 생각해도 어려웠어
과제 미제출한 동기들이 꽤 있는걸 보면 다들 비슷한 생각을 하는 것 같다
정말 비전공자가 할 수 있는 과정인가 하는 의문이 하루에도 백번씩 드는데..
긍정회로를 최대한 돌려본다

study note