📌3/15 영상 강의 인구분석 1,2
07. Population

1. 배경
- 목표`
- 인구 소멸 위기 지역 파악
- 인구 소멸 위기 지역의 지도 표현
- 지도 표현에 대한 카르토그램 표현
2. 데이터 읽고 인구 소멸 지역 계산하기
- fillna() : 데이터 프레임의 NaN값 채우기
- fillna(value = 1) : NaN값을 1로 채워줘
- fillna(method = "pad", axis=0) : NaN값을 이전 행의 값으로 채워줘
- 독스트링 - method : {'backfill', 'bfill', 'pad', 'ffill', None}, default None Method to use for filling holes in reindexed Series pad / ffill: propagate last valid observation forward to next valid backfill / bfill: use next valid observation to fill gap.
(1) 엑셀로 불러온 데이터 인덱스, 컬럼 정리
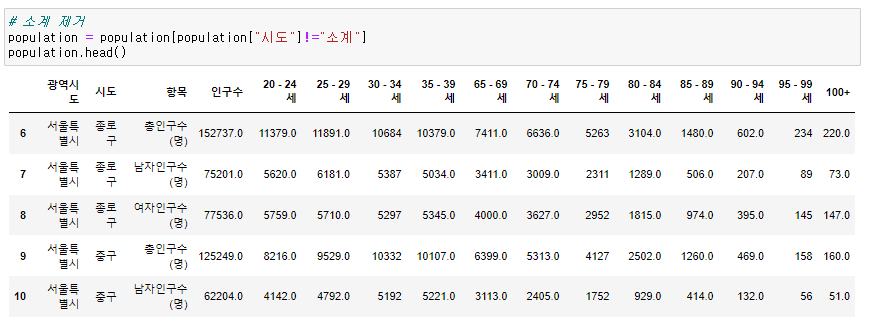
population.loc[population["구분"] == "총인구수 (명)", "구분"]="합계" # population.loc[행,열]
population.loc[population["구분"] == "남자인구수 (명)", "구분"]="남자"
population.loc[population["구분"] == "여자인구수 (명)", "구분"]="여자"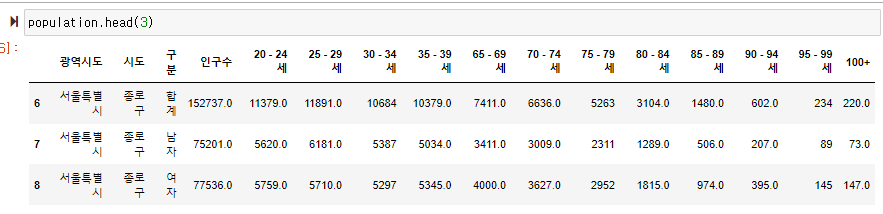
(2) 소멸지역을 조사하기 위한 데이터
population["20~39세"] = (
population["20 - 24세"] + population["25 - 29세"] + population["30 - 34세"] + population["35 - 39세"]
)
population["65세이상"] = (
population["65 - 69세"] + population["70 - 74세"] + population["75 - 79세"] + population["80 - 84세"] + population["85 - 89세"] + population["90 - 94세"] + population["95 - 99세"] + population["100+"]
)
(3) 마법의 단어로 보기좋게
# pivot_table (인덱스만 지정해서 만들경우 valeu는 평균값이 들어간다)
pop = pd.pivot_table(
data=population,
index=["광역시도","시도"],
columns=["구분"],
values=["인구수", "20~39세", "65세이상"]
)
pop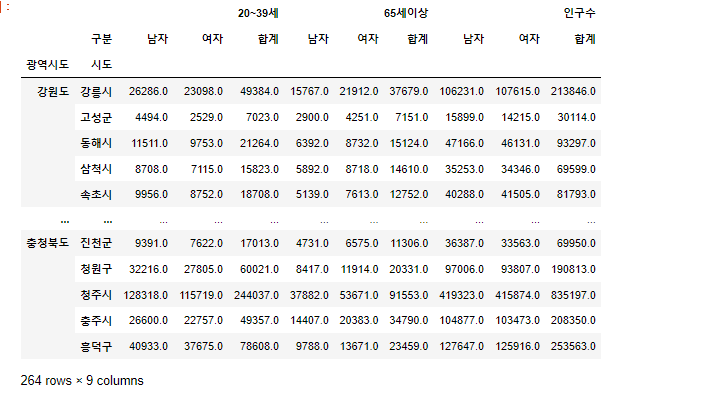
(4) 소멸비율 계산, 소멸위기지역 컬럼 생성
pop["소멸비율"]=pop["20~39세","여자"] / (pop["65세이상","합계"]/2)pop["소멸위기지역"] = pop["소멸비율"] < 1.0
pop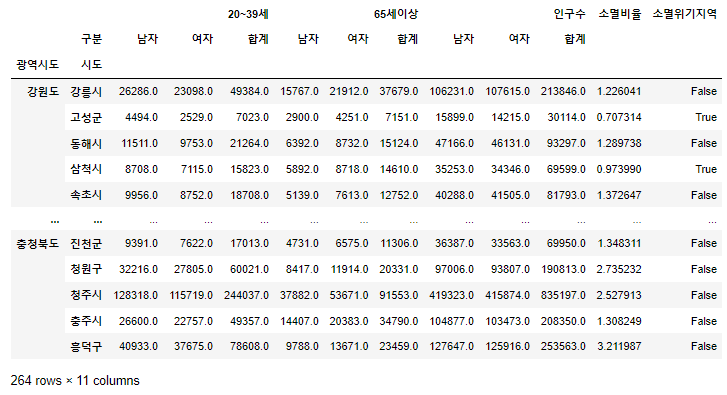
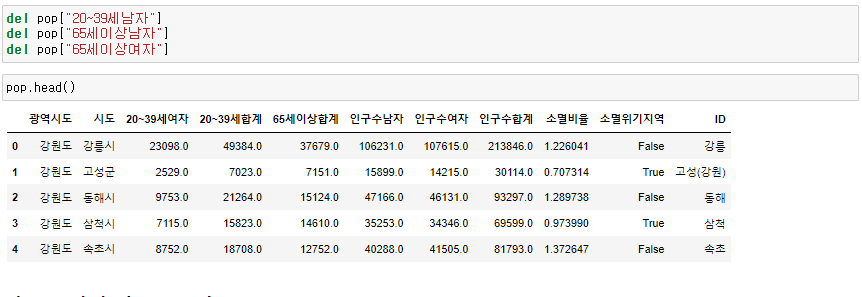
(5) 멀티인덱스 합치기
pop.reset_index(inplace=True)
tmp_columns = [
pop.columns.get_level_values(0)[n] + pop.columns.get_level_values(1)[n]
for n in range(0,len(pop.columns.get_level_values(0)))
]
pop.columns = tmp_columns
pop.head()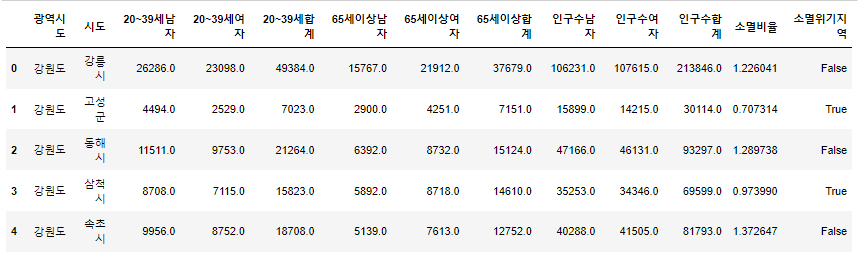
3. 지도 시각화를 위한 지역별 ID 만들기
- 만들고자 하는 ID의 형태
- 서울 중구
- 서울 서초
- 통영
- 남양주
- 포항 북구
- 인천 남동
- 인천 만안
- 안양 동안
- 안산 단원
...
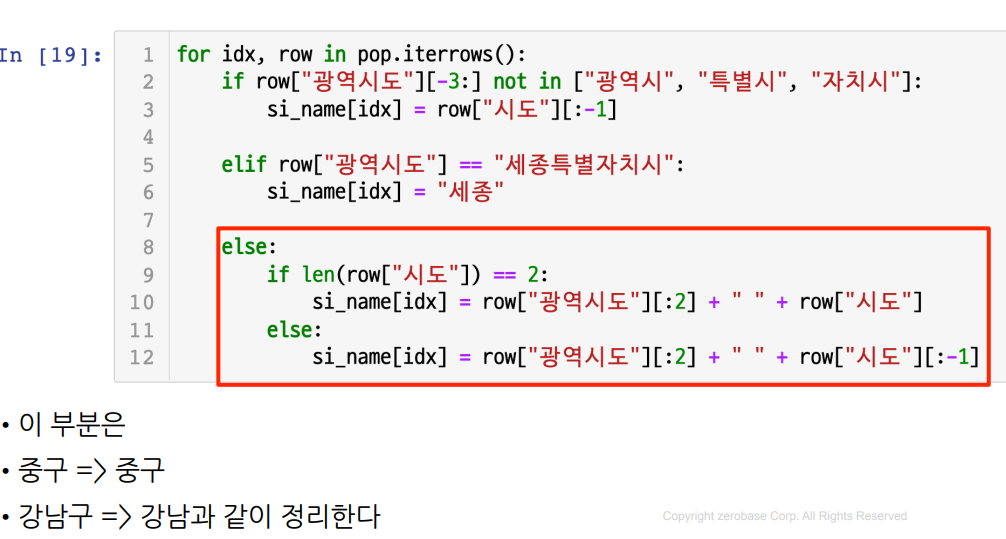
(1) 일반 시 이름과 세종시, 광역시도 일반 구 정리
for idx, row in pop.iterrows():
if row["광역시도"][-3:] not in ["광역시", "특별시", "자치시"]:
si_name[idx] = row["시도"][:-1]
elif row["광역시도"] == "세종특별자치시":
si_name[idx] = "세종" # 1개만 있으므로 특별관리
else:
if len(row["시도"]) == 2:
si_name[idx] = row["광역시도"][:2] + " " + row["시도"]
else:
si_name[idx] = row["광역시도"][:2] + " " + row["시도"][:-1] 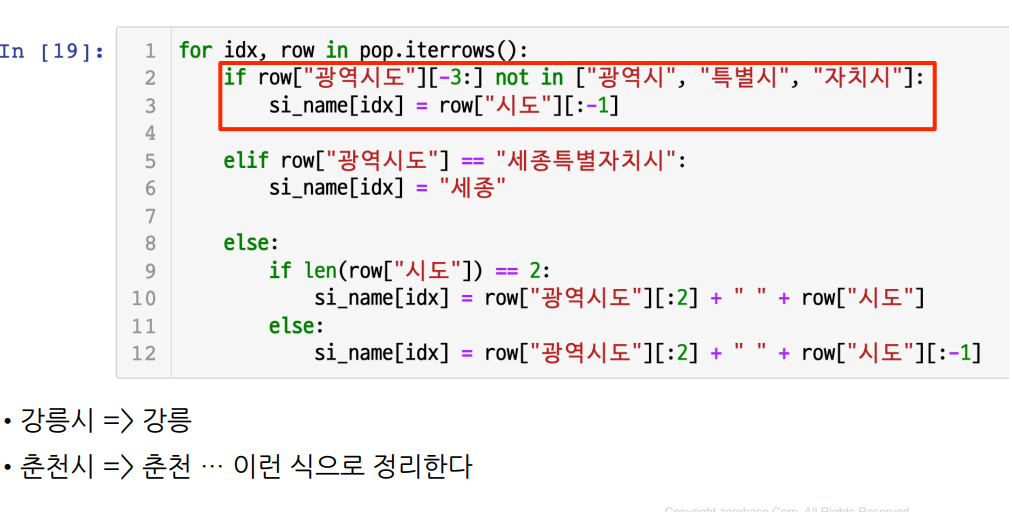
(2) 행정구
tmp_gu_dict = {
"수원":["장안구", "권선구", "팔달구", "영통구"],
"성남":["수정구", "중원구", "분당구"],
"안양":["만안구", "동안구"],
"안산":["상록구", "단원구"],
"고양":["덕양구", "일산동구", "일산서구"],
"용인":["처인구", "기흥구", "수지구"],
"청주":["상당구", "서원구", "흥덕구", "청원구"],
"천안":["동남구", "서북구"],
"전주":["완산구", "덕진구"],
"포항":["남구", "북구"],
"창원":["의창구", "성산구", "진해구", "마산합포구", "마산회원구"],
"부천":["오정구", "원미구", "소사구"]
}# 광역시나 특별시, 자치시가 아닌경우의 행정구만 적용
for idx, row in pop.iterrows():
if row["광역시도"][-3:] not in ["광역시", "특별시", "자치시"]:
for keys , values in tmp_gu_dict.items():
if row["시도"] in values:
if len(row["시도"]) == 2:
si_name[idx] = keys + " " + row["시도"]
elif row["시도"] in ["마산합포구", "마산회원구"]:
si_name[idx] = keys + " " + row["시도"][2:-1]
else:
si_name[idx] = keys + " " + row["시도"][:-1]

(3) 고성군 (강원,경남)
for idx, row in pop.iterrows():
if row["광역시도"][-3:] not in ["광역시", "특별시", "자치시"]:
if row["시도"][:-1] == "고성" and row["광역시도"] == "강원도":
si_name[idx] = "고성(강원)"
elif row["시도"][:-1] == "고성" and row["광역시도"] == "경상남도":
si_name[idx] = "고성(경남)"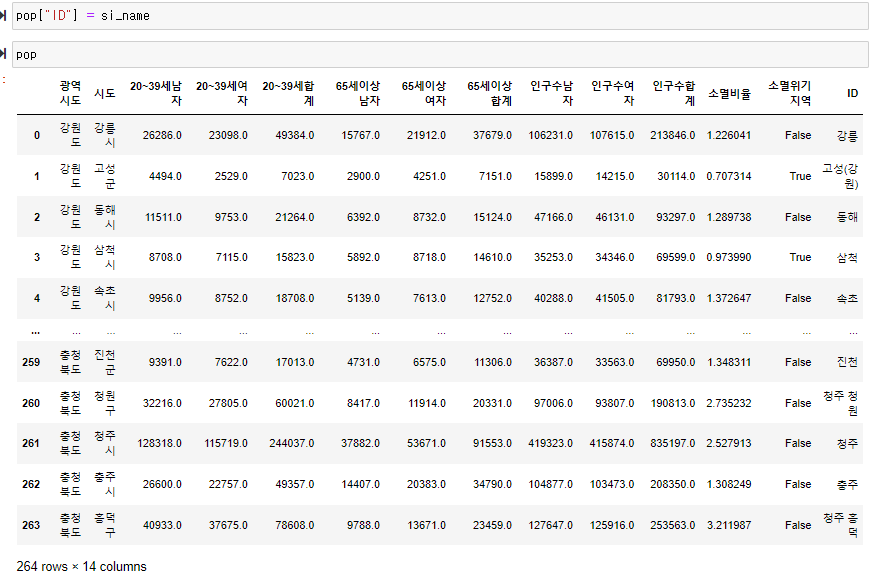
👍마무리
데이터 정리하는게 많은 시간을 할애해야 한다는 것을 깨달았다. 어떻게 정리하고 보기 좋게 만들고 삭제하고 필요한 부분을 추가하는 등.. 머리아프고 노가다성 작업이라 귀찮긴 한데 이게 약간 재미도있는거 같은 이상한 느낌이다 ㅎㅎ 가능하다면 eda 과정을 더 듣고싶다 (이걸 과제로 하겠지?) 쌤들과 함께 하고싶다구유..

study note