Object detection 공부하면서 진짜 많이 들어봤지만 막상 논문은 오늘 처음 읽어본 Feature Pyramid Networks for Object Detection의 paper 다.
작년에 읽어서 자세히는 기억 안나던 R-CNN, faster R-CNN이 계속 나와서 그쪽 내용도 뒤적거리고, 생각보다 related works에 나오는 논문들 중에서도 처음 봐보는게 많아서 약간 속상했지만 ㅠㅡㅠ ,, 더 열심히 공부해야겠다는 생각을 했다 !
개인적으로 네트워크가 복잡하게 다가오지는 않았지만 네트워크 구조 자체를 이해하는 것보다는 feature pyramid network가 rpn이나 Fast R-CNN에 어떤식으로 적용이 되고, 왜 이렇게 하면 성능이 향상되는지를 이해하는게 더 어려웠던 것 같다.
1. Introduction
Feature pyramid라는 개념은 딥러닝 이전에도 자주 쓰이던 개념이었다. 생각해보면 컴퓨터 비전 수업에서도 Harr like/HOG feature나 optical flow 배울 때 이미지 리사이즈 어쩌구 피라미드 어쩌구 하면서 배웠던 기억이 난다. 하지만 많은 object detector들이 딥러닝으로 넘어오게 되면서 feature pyramid라는 개념은 잘 쓰이지 않게 되었는데, 안 그래도 딥러닝 모델이 크다 보니까 cost도 너무 쎄고 메모리 소비도 너무 많기 때문이었다고 한다.
그래서 Feature Pyramid Networks for Object Detection paper에서는 FPN(Feature Pyramid Network)이라는 다양한 스케일에서도 semantic 정보를 잘 담고 있는 feature map을 marginal cost로 뽑아낼 수 있는 아키텍쳐를 제안한다.
Faster R-CNN에 이 네트워크를 붙여서 실험했을 때 SOTA의 성능이 나왔고, GPU 1개에서도 5fps 정도의 precessing time이 나오는, practical하고 accurate한 solution이라고 한! 다! (성능 관련된 내용은 아래에 있다.)
네트워크를 설명하기 전에 기존의 모델들이 어떻게 생겼는지에 대한 간단한 소개와 어떤 점에서 이러한 모델들이 한계를 가지는지 설명하려고 한다.

먼저 이거는 진짜 직관적으로 생각했을 때의 pyramid이다. 그냥 image 자체를 다양하게 resize하고, 이 resized image에서 각각 feature를 뽑아내서 prediction하는건데, 연산량이 굉장히 많다. 딥러닝으로 feature를 뽑아내는 방법 이전에 hand crafted feature 를 사용했을 때는 이 방법을 많이 사용했다고 한다. 근데 얘를 써서 딥러닝 모델을 학습시킨다는거는 정말정말 메모리도 많이 들고 cost도 너무 비싸서 사실 불가능에 가까운 얘기고, 사용한다고 하더라도 test time에서 inference할때만 사용한다고 한다. (이렇게 하면 train이랑 test가 inconsistent해서 안 좋다고 하는데 사실 왜 안 좋은지는 잘 이해가 안간다. inconsistent한 경우 되게 많지 않나ㅜㅜ)
 여기에서는 단일 이미지에서 연산을 쭉 해서 resolution이 낮은 feature를 뽑아내고, 그로부터 prediction을 수행한다. 방금 봤던 (a) 보다 연산량은 적겠지만, 문제는 아무리 다양한 스케일을 거쳐서 마지막 feature를 뽑지만 single scale에서 output이 나오기 때문에 좀 더 강한 scale robustness가 필요하다고 한다.
여기에서는 단일 이미지에서 연산을 쭉 해서 resolution이 낮은 feature를 뽑아내고, 그로부터 prediction을 수행한다. 방금 봤던 (a) 보다 연산량은 적겠지만, 문제는 아무리 다양한 스케일을 거쳐서 마지막 feature를 뽑지만 single scale에서 output이 나오기 때문에 좀 더 강한 scale robustness가 필요하다고 한다.
 그리고 얘는 (b)와 비슷해 보이지만 resolution을 줄여가면서 feature를 extracting 할때 제일 마지막에 뽑아낸 feature만을 이용하는게 아니라 줄여나가는 과정에서 나왔던 다양한 scale의 feature를 모두 사용해서 prediction을 수행한다는 의미이다. SSD에서 이런식으로 하니까 SSD 아키텍쳐 모양을 다시 생각해보면 될 것 같다.
그리고 얘는 (b)와 비슷해 보이지만 resolution을 줄여가면서 feature를 extracting 할때 제일 마지막에 뽑아낸 feature만을 이용하는게 아니라 줄여나가는 과정에서 나왔던 다양한 scale의 feature를 모두 사용해서 prediction을 수행한다는 의미이다. SSD에서 이런식으로 하니까 SSD 아키텍쳐 모양을 다시 생각해보면 될 것 같다.
근데 이렇게 하면 문제가 되는게 이전에 extract된 high resolution의 feature는 나중에 extract된 low resolution의 feature를 전혀 반영하지 못한다는거다. 나중에 뽑힌게 더 rich semantic information을 가지고 있을텐데도 말이다. ㅠㅠ 논문에서는 이걸 large segmantic gaps caused by different depth라고 표현한다.
그렇다면 pyramidal feature hierarchy 처럼 연산량도 적고, 또 sematically weak feature인 high resolution의 feature와 semantically strong feature인 low resolution의 feature를 어떻게 잘 연결해서 장점을 모두 취하는 아키텍처가 없을까 !? 그게 바로 이 논문에서 소개하는 Feature Pyramid Network 이ㄷㅏ ^___^
개인적으로 읽으면서 신기했던 부분은 이렇게 top-down 으로 내려오면서 skip connection으로 feature map으로 잇는 아이디어는 많은데, "다른 논문들은 정보를 잘 담고 있는 하나의 feature map을 만드는게 최종 목표고 우리는 각 레벨에서도 독립적으로 잘 예측하는 아키텍처를 만드는게 목표이다." 라고 선을 그어놓은 부분이었다. 아키텍처 자체만 보면 비슷한데 설정해놓은 최종목표가 완전히 다른게 신기했다 .. .
2. Feature Pyramid Network
1) Architecture
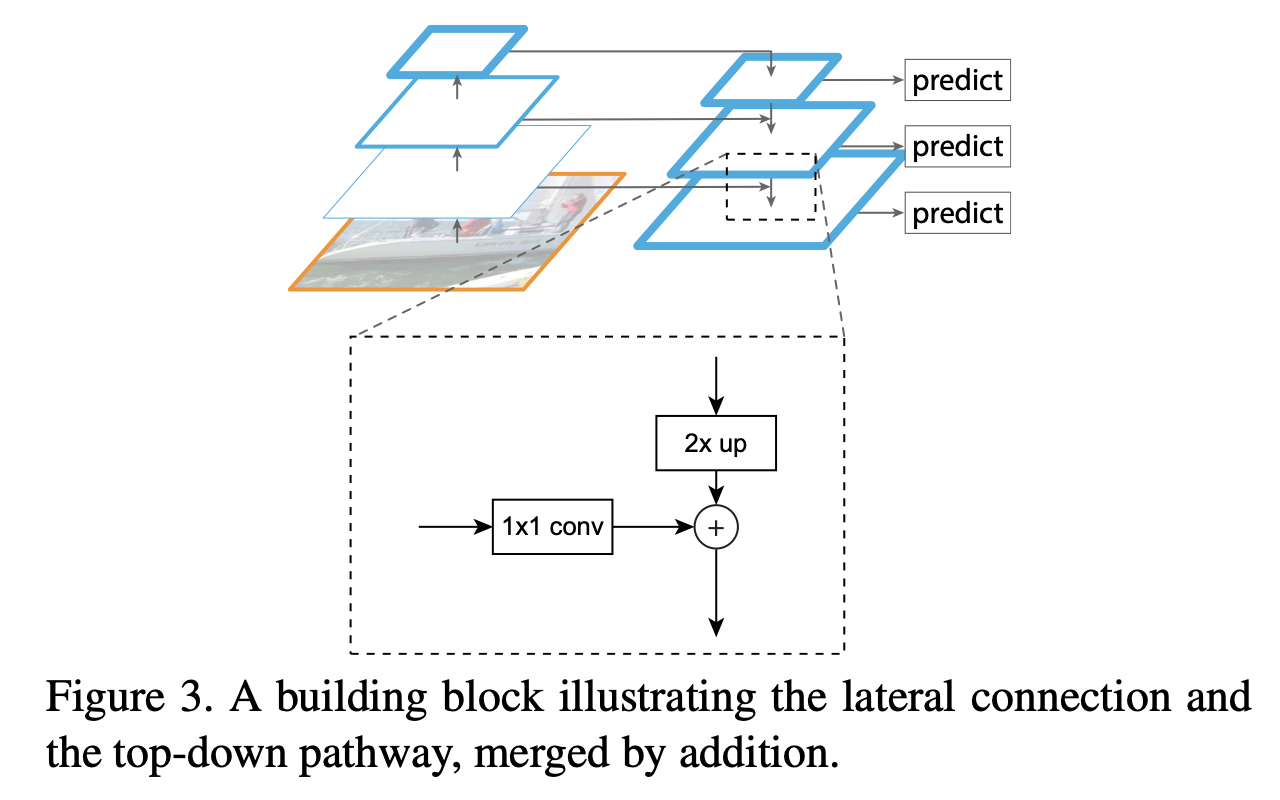
 FPN의 아키텍처를 자세히 보면 상단의 그림과 같다.
논문에서는 아키텍처를 크게 bottom-up pathway와 top-down pathway로 나누어서 설명한다. 그림에서도 직관적으로 볼 수 있듯이 bottom-up은 resolution을 줄여가며 feature를 얻는 forward 과정이고, top-down은 low resolution이지만 strong semantic을 가지고 있는 feature를 다시 원래 resolution으로 내려주면서 기존의 feature와 결합한다.
FPN의 아키텍처를 자세히 보면 상단의 그림과 같다.
논문에서는 아키텍처를 크게 bottom-up pathway와 top-down pathway로 나누어서 설명한다. 그림에서도 직관적으로 볼 수 있듯이 bottom-up은 resolution을 줄여가며 feature를 얻는 forward 과정이고, top-down은 low resolution이지만 strong semantic을 가지고 있는 feature를 다시 원래 resolution으로 내려주면서 기존의 feature와 결합한다.
Bottom-up Pathway
Bottom-up Pathway는 그냥 convolution network를 이용한 forward computing 부분인데 여기에서는 ResNet을 사용했다. 한 stage마다 스케일을 2씩 줄여주면서 convolution 연산을 수행한다.
Top-down Pathway
bottom-up 에서 올라왔던 feature들은 lower-level의 정보를 가지고 있지만, 일단 subsampling이 많이 되기 전이니까 위치 정보는 좀 더 정확하게 가지고 있다. 그리고 top-down에서 내려오는 feature들은 higher-level의 정보를 가지고 있지만 위치 정보는 많이 잃어버렸을 수 있기 때문에 두 feature를 합쳐서 서로의 장점을 가져온다.
생각보다 더하는건 단순했는데, 일단 아까 2배로 줄였으니까 다시 2배 upsampling을 해주고(이 때 그냥 간단하게 nearest neighbor upsampling을 쓴다.), 1x1 convolution으로 채널 수를 맞춰준 다음에 elementwise로 더해준다.
옛날에는 그냥 elementwise로 더해주는 것보다 channel 축으로 concat하는게 좀 더 각각의 정보를 잘 살릴 수 있지 않을까? 라고 생각했었는데 찾아보니까 그것도 아니라고 하더라 ...ㅎㅁㅎ;
아무튼 이렇게 최종적으로 마지막 feature map까지 왔으면 3x3 conv를 적용해서 마무리 해준다.
2) Application
이 paper에서 목표로 삼는 최종 goal은 "leverage a ConvNet’s pyramidal feature hierarchy, which has semantics from low to high levels, and build a feature pyramid with high-level semantics through-out" 이다.
한글로 옮겨봤자 영어가 절반이고 한국어가 절반일 것 같아서 그대로 가져왔는데, rich semantic information을 잘 뽑아내는 네트워크를 만드는 게 목표이기 때문에 이 네트워크가 RPN(Region Proposal Network)나 Fast R-CNN, segmentaion proposal 등과 결합했을 때의 성능을 굉장히 자세하게 설명한다.
Feature Pyramid Networks for RPN
RPN은 sliding window 기반의 object detector이다. 여기에서는 RPN이 사용하는 single scale feature map 부분을 FPN으로 바꾸어서 실험했다.
그리고 head에는 shared parameter를 사용했는데, 이게 성능이 비슷하게 좋게 나왔다고 한다. shared parameter의 성능이 좋다는 건 FPN에서 각 pyramid stage가 비슷한 정도의 semantic level을 가지고 있다는 것을 의미한다고 한다.
Feature Pyramid Networks for Fast-RCNN
원래 Fast-RCNN에서는 ROI pooling을 이용해서 roi 영역을 잘라낸다. 여기에서 다양한 스케일의 feature를 모델 네트워크로 보내주기 위해서 roi의 크기를 보고 스케일이 비슷한 pyramid stage의 feature를 잘라서 네트워크로 보낸다. 개인적으로 여기가 되게 신기했다.
여기에서 는 ImageNet pretrained size이고, 은 를 만족하는 RoI들을 찾아내야하는 feature level이다. head는 파라미터를 공유한다. 아무래도 기존 네트워크와 비교했을 때 feature를 보내주는게 달라지다 보니까 마지막 conv 레이어를 2개의 fc 레이어로 붙였다고 한다.
3. Experiment
Region Proposal with RPN

baseline과 비교했을 때 확실히 더 나은 성능을 보이는 것을 확인할 수 있다. 추가적으로 inference time이나 메모리 소비(파라미터 크기) 비교와 관련된 내용을 찾고 싶었는데 못찾았다 ㅠㅡㅠ
feature map끼리 이리저리 결합하고 하니까 작은 것들도 잘 잡아내는 scale variance에 robust한 모델이 나올 수 있었던 것 같다.
Fast/Faster R-CNN

여기에서는 Running time에 대한 비교도 추가되어 있는데, Faster R-CNN에서 FPN을 사용했을 때 inference time도 꽤 유의미하게 감소했다. 논문에서는 마지막에 extra layer를 더하기는 했지만, 그래도 head가 더 가벼워졌기 때문이라고 설명한다.
마찬가지로 큰 크기의 object보다 작은 크기의 object에 대한 성능이 더 크게 상승했음을 확인할 수 있다.
저번에 Faster R-CNN 이용해서 프로젝트를 진행했던 적이 있었는데 그때 작은 object들을 너무 검출 못해서 성능에 실망했었던 기억이 난다 ,,, FPN을 써서 돌렸더라면 좀 더 나아졌을까 ,,
4. 궁금했던 점
- 추가적으로 extra layer에 non-lienarity는 없고, 실험해봤을 때 그렇게 유의미한 영향을 미치지 않았다고 했는데 거대한 네트워크에서 overfit문제는 없나 .. . ? 상관없나 .. ?
- simplicity를 위해서겠지만 upsamling downsampling할 때 다른 논문에서 local 정보를 살리기 위해서 사용했던 방법들을 사용해보는 것도 성능에 영향을 미칠 수 있을 것 같다! (computation이 너무 많이 차이나지 않는다는 전제하에서 ㅠㅠ)
(+ 이렇게 쓰다가는 방학 내내 글만 쓸 것 같아서 다음부터는 설명을 좀 줄여봐야겠다 ..)
Reference
