 지금 MPII dataset 기준으로 multi-person pose estimation에서 SOTA를 찍고 있는 RMPE 네트워크이다. 어떻게 생겼길래 SOTA지? 하고 논문을 읽어봤는데 이러니까 소타지.. 하면서 논문 정리하는 중 ..
지금 MPII dataset 기준으로 multi-person pose estimation에서 SOTA를 찍고 있는 RMPE 네트워크이다. 어떻게 생겼길래 SOTA지? 하고 논문을 읽어봤는데 이러니까 소타지.. 하면서 논문 정리하는 중 ..
지금까지 읽어봤던 논문중에서 (deeplab 다음으로) 제일 어려웠다.. .
1. Introduction
주어진 영상/이미지에서 사람들을 찾아내고 그 사람들의 포즈를 찾아내는 일은 사실 쉬운 일이 아니다. 주어진 이미지에서 사람이 있는 부분을 찾아내는 object detection / localization 문제와 single person pose estimation 문제가 모두 어느정도 해결된다는 전제가 있어야 하기 때문이다.
하지만 object detection의 성능이 충분히 높게 올라왔음에도 어느정도의 localization error는 불가피했고, 이런 bbox 들의 작은 차이가 최종 multi-person pose estimation의 성능을 크게 좌우했다. (multi-person pose estimation에서 part-based approach와 two-step approach 중 후자 기준으로)
 기존의 연구(Faster R-CNN + Stacked Hourglass 조합)에서 inference 과정을 시각화해보면 bbox가 조금만 벗어나도 최종 pose를 잡아내지 못하는 것을 확인할 수 있다. 하지만 위의 사진에서 빨간색 bbox와 노란색 bbox는 IoU가 50% 이상이기 때문에 노란색 bbox도 맞는 bbox라고 인정되긴 하는데.. 이 bbox를 가지고 propagate한 결과는.. pose 추정에 그렇게 도움이 되지는 않아 보이는 게 문제이다.
기존의 연구(Faster R-CNN + Stacked Hourglass 조합)에서 inference 과정을 시각화해보면 bbox가 조금만 벗어나도 최종 pose를 잡아내지 못하는 것을 확인할 수 있다. 하지만 위의 사진에서 빨간색 bbox와 노란색 bbox는 IoU가 50% 이상이기 때문에 노란색 bbox도 맞는 bbox라고 인정되긴 하는데.. 이 bbox를 가지고 propagate한 결과는.. pose 추정에 그렇게 도움이 되지는 않아 보이는 게 문제이다.
그래서 이 논문에서는 부정확한 bbox에서도 정확하게 사람의 포즈를 추정할 수 있는 모델을 만드는 것을 최종 목표로 삼는다. 여기에서 제안하는 네트워크 RMPE(Regional Multi-Person Pose Estimation)는 크게 3가지의 큰 모듈을 가지고 있다. 먼저 single person pose estimator branch를 하나 옆에 붙인 Symmetric Spatial Transformer Network, 중복된 detection을 줄이기 위한 parametric pose NMS, 그리고 training sample을 늘리기 위한 Pose-guided Proposals Generator 등인데, 각 모듈에 대해서는 아래에서 자세하게 다루겠다.
그리고 detected bbox가 아닌 ground truth에서 pose estimate를 했을 때의 결과와 이 모델의 결과를 비교하며 이 RMPE가 충분히 multi human pose estimation의 upper bound에 도달했음을 주장한다.
2. Regional Multi-Person Pose Estimation (RMPE)
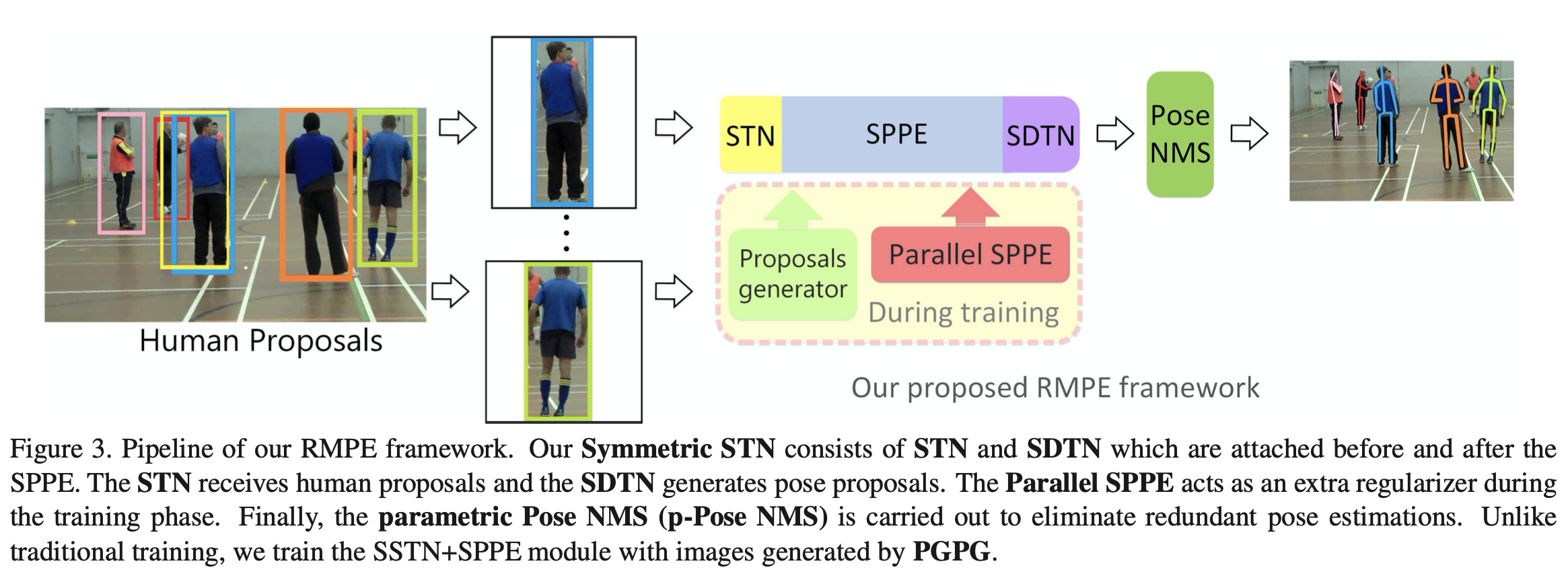
 RMPE framework의 대략적인 그림이다. 이미지에서 사람으로 추정되는 proposal들에 대해 각각 single-human pose estimate를 하는데 이때 좀 더 사람을 잘 찾을 수 있도록 spatial transformer network를 거친 결과를 propagate시키고, propagate 시킨 이후에는 다시 원래대로 돌려놓는 spatial de-transformer network를 거친 후, pose NMS로 중복을 제거하고 결과를 낸다. 이때 좀 더 학습이 잘 되게 하기 위해서 branch 하나를 따로 파 Parallel 하게 다른 single person pose estimator를 이용하고, 마지막으로 training data를 augment하기 위해서 pose guided proposals generator(PGPG)를 이용한다.
말로 설명을 하기가 너무 복잡한 거 같긴 하지만 각 모듈을 따로 떼서 보면 그나마 이해가 쉽다...
RMPE framework의 대략적인 그림이다. 이미지에서 사람으로 추정되는 proposal들에 대해 각각 single-human pose estimate를 하는데 이때 좀 더 사람을 잘 찾을 수 있도록 spatial transformer network를 거친 결과를 propagate시키고, propagate 시킨 이후에는 다시 원래대로 돌려놓는 spatial de-transformer network를 거친 후, pose NMS로 중복을 제거하고 결과를 낸다. 이때 좀 더 학습이 잘 되게 하기 위해서 branch 하나를 따로 파 Parallel 하게 다른 single person pose estimator를 이용하고, 마지막으로 training data를 augment하기 위해서 pose guided proposals generator(PGPG)를 이용한다.
말로 설명을 하기가 너무 복잡한 거 같긴 하지만 각 모듈을 따로 떼서 보면 그나마 이해가 쉽다...
1) Symmetric STN (Spatial Transformer Network) and Parallel SPPE (Single-Person Pose Estimator)
저기 introduction에서의 그림에서 봤듯이 single person pose estimator(이제 SPPE라고 하겠다!)는 하나의 이미지에 차있는 한 명의 사람에 대해서 학습이 되기 때문에 input이 되는 human proposal에 대해서 많이 예민하다.
Symmetric STN과 Parallel SPPE는 이러한 한계를 극복하기 위해서 제안되었는데, 일단 수학적으로 STN은 2D affine transformation을 수행한다. affine transformation이 뭐냐면 간단하게 2D 좌표계의 좌표들을 다른 2D 좌표로 보냈을 때 보내기 전에 평행이었던 애들은 보낸 후에도 평행인 transformation이다. 이미지를 빙글빙글 돌리고 평행사변형 모양으로 바꾸는 거를 생각해보면 될 것 같다!


STN은 수식 (1)과 같은 과정을 거쳐서 detector로부터 들어왔던 human proposal, 와 를 와 로 보낸다. 그리고 반대로 SDTN은 수식 (2)와 같은 과정을 거쳐서 estimator로 추정된 포즈들을 다시 원래 좌표계로 보내준다.
여기에서 Symmetric STN들은 SPPE와 함께 fine-tuned되는데, 이때 학습을 좀 더 잘되게 하기 위해서 SPPE branch를 하나 파서 같이 학습한다. 이 branch는 진짜 SPPE와 STN은 똑같은데, SDTN이 없다. 다시 말해서 이 branch에서의 label은 affine transformation이 된 상태에서 비교가 된다. 이 branche의 weight을 굳이 업데이트 하지는 않고, 얘를 둠으로써 STN(affine transformation 시키는 얘)까지 center-located pose error를 보내 STN을 좀 더 정교하게 학습할 수 있었다. 그리고 testing phase에서는 이 branch를 사용하지 않았다.
여기에서는 이 parallel SPPE를 일종의 regularizer로 해석했다. STN에게도 충분한 loss를 전달해 너무 얘가 이상한 곳으로 proposal들을 보내지 않고 되도록이면 가운데로 잘 보내도록 제한하는 것이다.
2) Parametric Pose NMS (Non Maximum Suppression)
그리고 기존 human detector의 또 다른 문제는 중북된 bbox를 만들어 낸다는 것이었다. 그래서 이 중복된 bbox들을 하나로 만들기 위해서 NMS를 사용했는데, 기존의 NMS는 그렇게 효과적이지도 않고 정확하지도 않았다고 한다.
그래서 이 논문에서는 새로운 parametric pose NMS를 제안한다. 먼저 pose NMS를 간단하게 소개하자면 pose NMS는 주어진 bbox 중에서 가장 confidence가 높은 bbox를 찾고, elimination 기준에 따라 얘가 삭제할만 하다 싶으면 삭제하는걸 unique한 bbox들만 남을때까지 반복한다.
이런 원래의 pose NMS에서 새로운 pose distance metric 을 추가해 elimination criterion을 재정의 했다.

만약에 이 보다 작으면 최종 output은 1이 되고, pose 는 pose 과 비슷하기 때문에 사라지게 된다.
하나 흥미로웠던거는 를 최적화할때 4D space에서 최적점을 찾는게 어려웠기 때문에 번갈아 가면서 2개 고정하고 2개 최적화하고, 다른 2개 고정하고 2개 최적화하는 과정을 반복하면서 학습을 진행해 파라미터를 수렴시킬 수 있었다고 한다.
3) Pose-guided Proposals Generator (PGPG)
애초에 introduction에서도 소개했듯이 이 모델의 최종 목적이 불완전한 bbox 에서도 정상적으로 작동하는 모델을 만들고 싶은 것이기 때문에, 충분한 양의 부정확한 human proposal을 만들어 내기 위해 training data augmentation이 필요했다.
하지만 human detector에서는 각 사람에 대해서 하나의 bbox밖에 만들어내지 못하기 때문에 인위적인 proposal generator를 이용해서 data augmentation을 할 수 있었다.
이 논문의 저자들은 gt bbox의 좌표와 predicted bbox의 좌표 차의 분포가 일정한 분포를 가진다는 사실을 발견했다. 다시 말해서 가 gt bbox와 predicted bbox의 좌표간의 차이이고, 가 사람의 gt pose라고 했을 때 분포 가 존재한다는 것이다.
이 분포를 직접적으로 학습하기가 매우 어려웠기 때문에 대신 를 학습했다. 여기애서 는 P의 atomic pose이다. atomic pose는 다양한 pose들의 대표 pose라고 생각하면 되는데, 하단의 사진을 보면 좀 더 잘 이해가 될 것 같다! (사실 나도 오늘 처음 들어본 말이어서 ,,)
 torso의 길이를 비슷하기 조절한 후, KNN을 이용해서 비슷한 pose들끼리 모은 후 cluster의 center로 atomic pose를 구성했다. 그리고 offset의 경우에는 gt bbox의 side length로 normalize했다고 한다. 이렇게 해서 추정된 atomic pose들에 따른 offset의 분포는 Gaussian mixture distribution을 이용해서 모델링 할 수 있었다. 하단은 그렇게 해서 모델링 된 포즈들의 offset 분포이다.
torso의 길이를 비슷하기 조절한 후, KNN을 이용해서 비슷한 pose들끼리 모은 후 cluster의 center로 atomic pose를 구성했다. 그리고 offset의 경우에는 gt bbox의 side length로 normalize했다고 한다. 이렇게 해서 추정된 atomic pose들에 따른 offset의 분포는 Gaussian mixture distribution을 이용해서 모델링 할 수 있었다. 하단은 그렇게 해서 모델링 된 포즈들의 offset 분포이다.
 얘네들을 학습할 때는 어떤 식으로 사용하냐면 먼저 training data에서 이 pose가 어떤 atomic pose의 범주에 포함되는지 확인하고, 그 atomic pose와 대응하는 distribution에서 추가적으로 offset을 샘플링해와서 새로운 augmented proposal을 만들어 내 학습한다고 한다.
얘네들을 학습할 때는 어떤 식으로 사용하냐면 먼저 training data에서 이 pose가 어떤 atomic pose의 범주에 포함되는지 확인하고, 그 atomic pose와 대응하는 distribution에서 추가적으로 offset을 샘플링해와서 새로운 augmented proposal을 만들어 내 학습한다고 한다.
3. Experimental

 이 정도로 했는데 당연한 얘기 같지만, MPII multi-person test set과 MSCOCO keypoint에 대해서 SOTA를 찍었다. 그리고 이 논문이 2018년 이전에 나온거 같은데 아직도 MPII에서는 SOTA였다..
이 정도로 했는데 당연한 얘기 같지만, MPII multi-person test set과 MSCOCO keypoint에 대해서 SOTA를 찍었다. 그리고 이 논문이 2018년 이전에 나온거 같은데 아직도 MPII에서는 SOTA였다..
그리고 여기에서 제안하는 각 모듈이 얼마나 최종 성능에 기여했는지를 비교해봤는데, 생각보다 PGPG가 없을 때 성능이 많이 떨어져서 좀 신기했다. multi-human pose estimation task 자체가 대규모의 데이터셋이 그렇게 많지 않아서인지 단순히 roi를 crop할때 offset을 조금 바꿔주는 것 만으로도 이렇게 성능이 변하는게 가능한가 보다.. 그리고 왜 굳이 KNN에 MOG에 atomic pose에 이런걸 할까.. 했는데 단순히 human proposal의 좌표를 jittering 하는 것만으로도 충분히 성능이 오르는 것 같아서 차라리 쓸꺼면 이 방법을 쓰는게 낫겠다라는 생각이 들었다.

4. Conclusion
이 논문에서는 기존의 two-step multi human pose estimation에서 가지고 있는 한계점 (human proposal의 부정확함, 중복 proposal 등)을 극복하고 기존의 성능에서 굉장히 향상된 성능을 보이는 모델 RMPE framework를 소개한다. 이 framework는 SSTN과 Parallel SPPE, Parametric Pose NMS, 그리고 Pose-guided Proposals Generator 등으로 구성되어 있다. 각각의 모듈들은 기존 연구의 한계점을 충분히 잘 극복하고 있고, 충분히 최적화 되어있기는 하지만, 이 다양한 모듈을 한번에 end to end로 optimize하는게 다음 future work라고 한다. 사실 지금은 굉장히 복잡해 보이고 학습이 잘 안될 것 같기는 하다.. . ..
Reference
