회사에서 논문 리뷰 후 구현을 진행해야하는 SOLO 2를 읽기 전에, 먼저 SOLO를 읽었다. (🖤제니 솔로🖤 들으면서 글 쓰는중) 처음에 이름보고 YOLO처럼 이름 갖고 장난친건가? 했는데 컨셉중에도 YOLO와 비슷한게 조금 있었다. YOLO도 2까지만 읽고 3이랑 새로 나온 4는 아직 안 읽었는데 SOLO 2 읽으면 YOLO 4도 한번 읽어봐야겠다.
여기에서 사용하는 loss중에 focal loss랑 dice loss가 있었는데 focal loss는 읽었던건데 기억이 잘 안나고 dice loss는 이번에 처음 보는 내용이어서 얘네들도 차례차례 정리하려고 한다.
1. Introduction
보통 semantic segmentation 문제를 해결할 때 가장 직관적인 해결 방법은 이 문제를 dense pixel-wise classification problem로 해석하는 것이다. FCN에서 제시했던 network처럼 주어진 input image의 크기와 동일한 사이즈의 output을 pixel 단위로 class를 예측하는 것을 dense pixel-wise classification이라고 한다. 하지만 현실적으로 이런 방식을 선택하면 모든 instance를 곧바로 예측하기가 생각보다 좀 힘들다.
그래서 나온 절충안이 많이 얘기하는 two-stage model이다. two-stage model에는 주어진 이미지에서 RoI를 찾고 각각의 bounding box내에서 instance의 segment를 찾아내는 top-down 방식과 affinity relation을 이용해 각 픽셀의 embedding vector를 구하고, 그 vector들을 잘 묶어서 하나의 instance를 구하는 bottom-up 방식이 있다.
하지만 이런 단계들은 어쩔 수 없이 이미지에서 간접적으로 segment를 찾아내는 방식이기 때문에 두 모듈을 모두 최적화하기 힘들다는 한계가 있다. 그래서 이 논문에서는 주어진 이미지에서 직접적으로 바로 instance의 segment mask를 찾아내는 다른 방식을 찾는다.
이 논문에서 segmentation 문제를 해결하기 위해 집중했던 포인트는 이미지에서 object간의 근본적인 차이점이 뭐지? 라는 질문이었다.사실 사람이 이미지를 볼때면 직관적으로 object 들을 구별해낼 수 있지만 컴퓨터에게 이해시키기 위해서는 object간의 차이점을 명확하게 알고 아키텍쳐를 모델링할 필요가 있으니 말이다..
이 질문에 대한 답을 찾기위해 일반적으로 많이 사용하는 데이터셋(MS-COCO)을 확인했을 때, 이미지의 instance들은 서로 크기가 다르거나 위치가 다르거나 둘 중에 하나는 달랐다고 한다. 물론 어떻게 보면 되게 당연한 말이기는 한데, 개인적으로 pose estimation 졸업연구를 진행하면서 가장 잘 안됐던 케이스가 사람/instance가 겹쳐있을 때였어서 이런 케이스는 무시하고 진행하는 점이 좀 아쉬웠다.
2. SOLO
그래서 이 논문에서 제안하는 새로운 아키텍쳐 SOLO는 물체를 그 크기와 위치에 따라서 나누고 예측한다. 그렇기 때문에 box supervision이 필요없어서 end to end로 더 잘 최적화할 수 있다고 한다.
🗺 Location
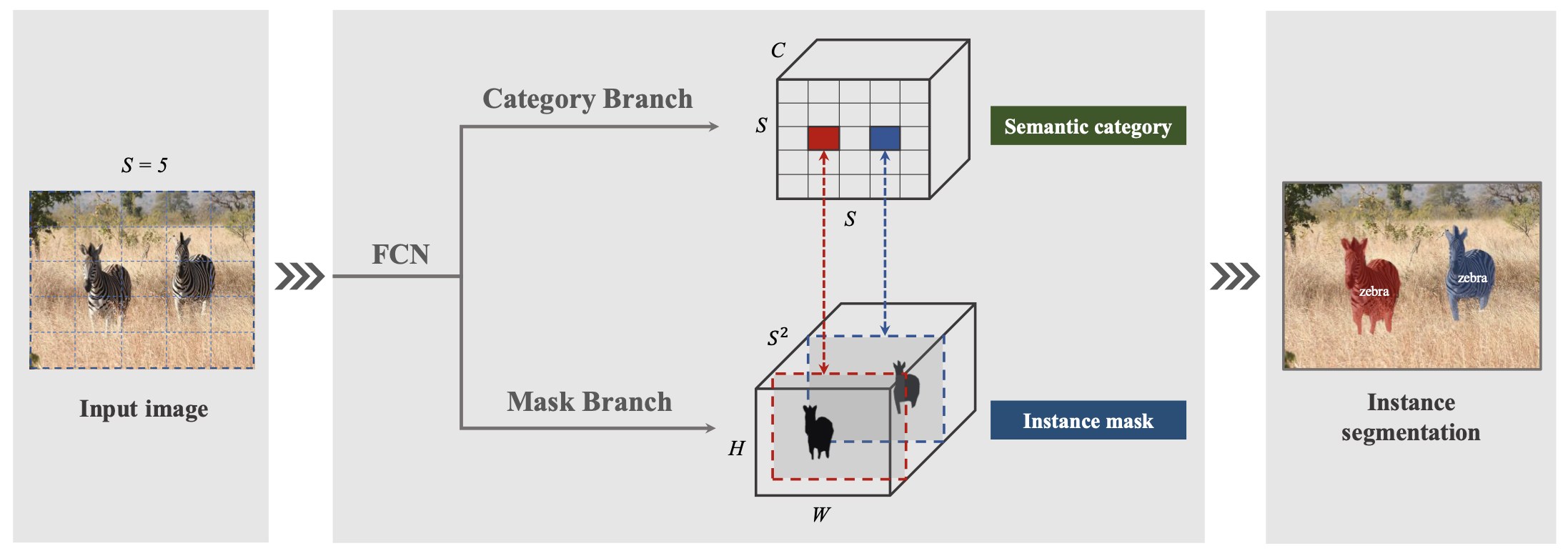
주어진 이미지를 x의 grid로 나누고, 예측해야하는 object의 중심이 특정 grid cell에 들어가면 그 grid cell은 해당 object의 segment를 예측할 의무가 생긴다. (YOLO에서 grid cell 나눠서 예측했던 그 내용이랑 거의 유사하다.)
채널축의 각각의 feature map들은 대응하는 grid cell이 반드시 잡아내야하는, 중점에 있는 object의 segment mask가 된다. (한국어 진짜 못한다 나..😰 아래 사진을 보자 ..)
여기에서 재밌는 점 하나는 object center를 찾을 때 regression 문제로 접근하는게 아니라 grid cell의 classification 문제로 접근한다는 점이었다. 몇개인지 알 수 없는 instance의 개수를 고정된 채널축(개)에 집어넣기 위해서 택한 방법이라고 한다.
➰ Size
그리고 현실세계의 데이터는 크기가 매우 다양하기 때문에 FPN을 사용해서 크고 작은 object도 "instance category"로 예측될 수 있도록 했다. 확실히 backbone으로 FPN을 사용하면 grid로 나눴을 때 YOLO의 단점(작은 object 못 잡음)을 어느정도 해결할 수 있을 것 같았다.
논문을 다 읽은 지금도 크기가 비슷한 사람들이 같이 지나가서 그 중심이 하나의 grid cell에 들어갈때는 어떡하지? 라는 생각을 지울 수 없지만 말이다🙁 (캡스톤때 고생했어서 물체 겹치는거에 예민함)
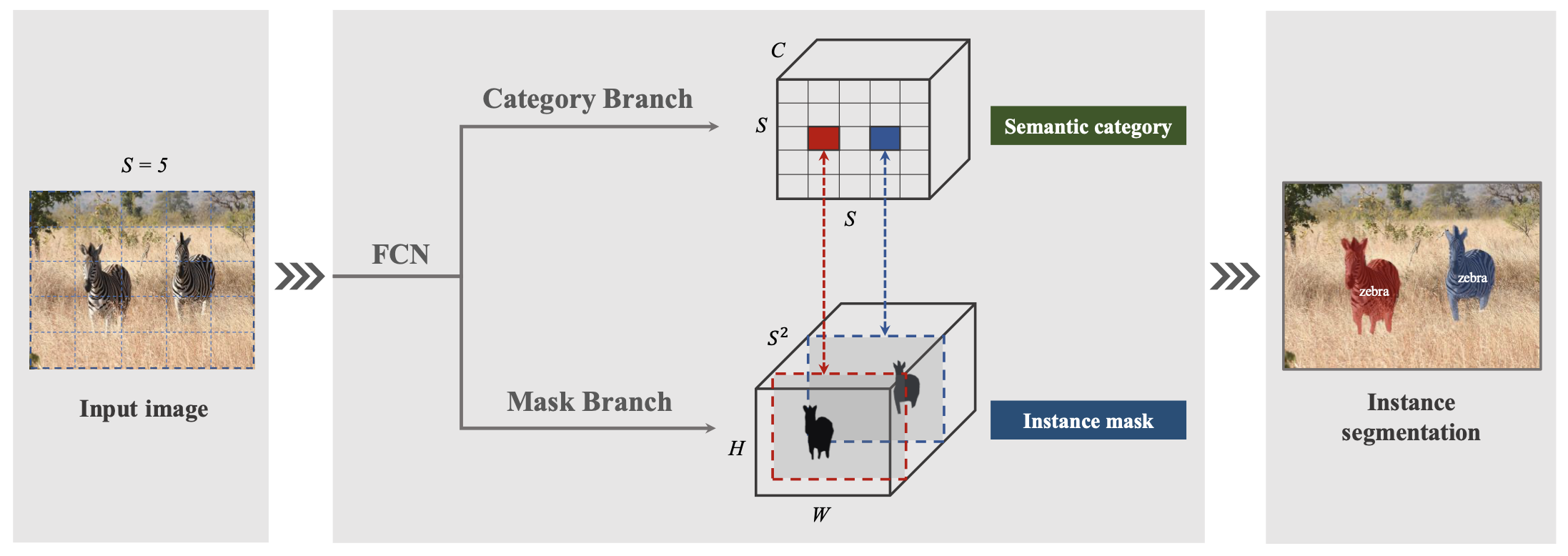
1) Segmenting Objects by Location
위에서도 계속 얘기했지만 SOLO에서 가장 중요한 아이디어는 instance segmentation 문제를 category prediction과 mask generation problem으로 나누어 해석했다는 점이다.
만약 한 object의 중심이 grid cell에 들어가게 되면, 그 cell은 해당 object의 category와 instance mask를 예측해야만 한다. Grid 관점에서 network를 보면 각각의 grid cell은 category branch에서 개의 category 확률을 예측하고, mask branch에서 그 object의 instance segment mask를 찾아낸다. Grid 의 mask는 채널에서 찾으면 된다.
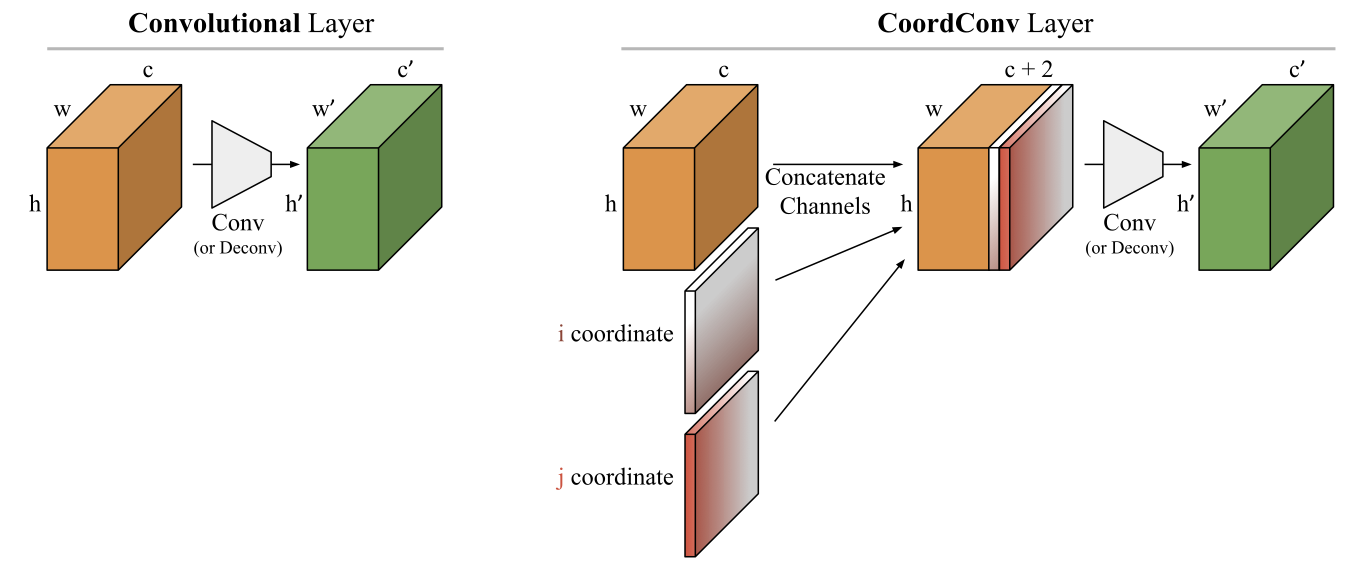
segmentation 문제에서 중요한 것중 하나는 위치에 민감하게 반응(spatially variant)해야한다는 것이다. 하지만 기존의 많은 CNN들은 spatially invariant하다. classification 문제를 생각해보면 이해가 쉬운데, 사람의 얼굴을 찍은 사진이던 다리를 찍은 사진이던 그 object가 사람이라면 CNN classifier는 사람을 예측해야한다. 하지만 segmentation 문제에서는 사람의 얼굴을 찍은 사진이면 그 얼굴에 맞는 mask를 찾아야 하고, 다리를 찍은 사진이면 그 다리의 mask를 찾아야 한다. spatially variant, position sensitive하게 문제를 해결해야 한다는 것이다.
Spatially variant한 특성을 더 살려주기 위해서 CoordConv operator를 사용했다. CoordConv operator는 An intriguing failing of convolutional neural networks and the CoordConv solution에서 제안하는 operator인데, original tensor 모양이 라고 하면, pixel의 위치를 로 normalize한 축을 2개 더 붙여서 의 tensor를 사용한다.
하단의 사진을 보면 직관적으로 CoordConv를 이해할 수 있기도 하고, 이 논문은 다음에 다른 포스팅으로 한번 더 정리를 할꺼기 때문에 여기에서 설명은 길게하지 않지 않으려고 한다.
마지막으로 Mask branch가 예측을 하면 여러개의 cell이 하나의 object를 예측할 수 있다. 이 경우에는 NMS를 이용해 하나의 instance 결과를 도출했다고 한다. NMS를 비롯한 post processing에서 더 특별하게 사용한 매커니즘은 없는 것 같다.
2) Network Architecture
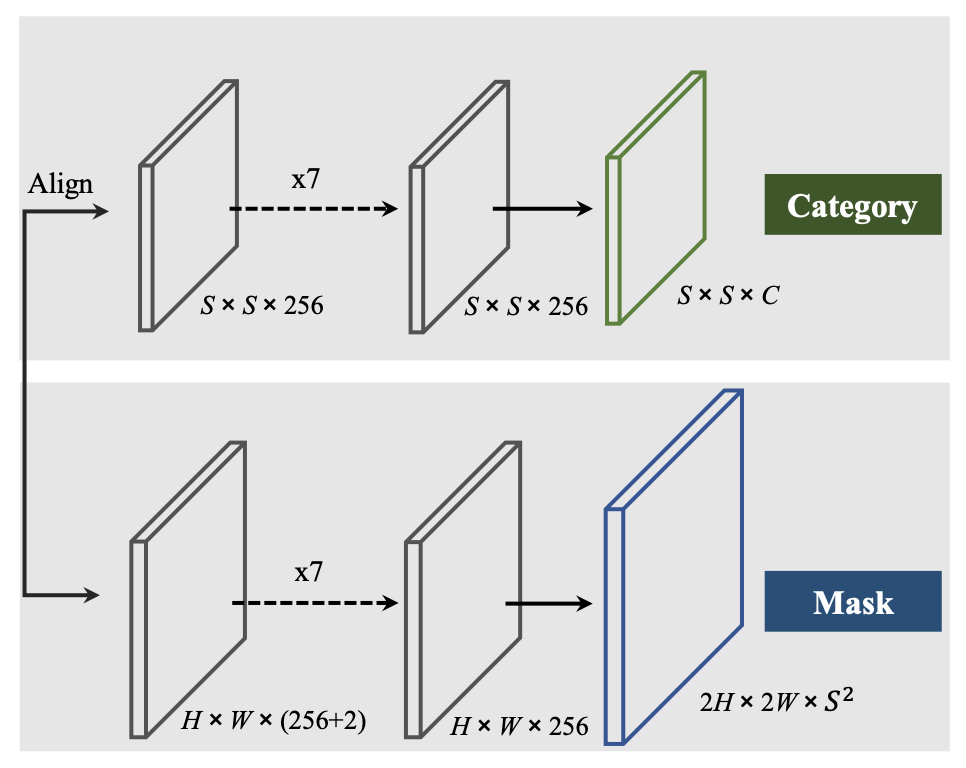
기본적으로 backbone을 FPN을 사용하기 때문에, 모든 feature level에 상단의 이미지와 같은 head가 모두 붙는다. 이 head를 바꿔서 decoupled head를 사용하는 내용을 뒤에서 설명하긴 하는데 SOLO2에서 다양한 head로 실험한 결과를 이야기하는 것 같아서 여기에서는 decoupled head 내용은 정리를 하지 않으려 한다.

이거는 FPN 사용했을 때 pyramid 깊이에 따라서 grid number 를 뭘로 설정했는지 정리한 표다.
〰️ Align
Category prediction에서 feature map을 grid로 나누기 위해서는 텐서 크기를 에서 로 바꾸어주어야 한다. 여기에서는 alignment 방법으로 interpolation, adaptive-pooling, 그리고 region-grid-interpolation 을 사용한다.
하지만 유의미한 AP 차이는 없기 때문에 자유롭게 아무거나 사용해도 된다. (왜 Mask R-CNN의 RoIAlign은 사용안해봤을까? region-grid-interpolation을 제대로 감 못 잡았는데 RoIAlign의 매커니즘을 이용한걸까..?)
3) SOLO Learning
✅ Label assignment
먼저 category classification의 경우에 object의 center가 grid cell 내부에 있는 경우는 positive sample, 그렇지 않으면 negative sample로 분류했다.
그리고 center가 이고 width , height 인 GT에 대해서 center region을 로 설정했다.
segmentation의 label같은 경우는 모든 positive sample은binary mask를 가지고 있어야 하기 때문에, output 개의 mask 중에서 positive sample의 경우만 제대로 annotation하면 된다.
❎ Loss function
일단 를 conventional focal loss라고 하고 를 mask prediction의 loss라고 할 때, 전체 loss 식은 하단과 같다.
그리고 는 다음 식으로 표현할 수 있다.
위 식에서 해당 cell이 positive sample이면 1, negative sample이면 0을 반환한다. 는 positive sample의 개수이고, 와 는 와 를 이용해 계산한 index 값이다.
는 gt mask와 predicted mask 간의 차이를 말한다. 이때 이 거리는 binary cross entropy, focal loss, dice loss 3가지로 실험을 해봤는데, dice loss가 가장 효율적이고 안정적으로 학습할 수 있어서 이걸 선택했다고 한다. (휴리스틱하게 파라미터 조절만 잘 되면 focal loss 같은게 더 효과적일 수 있음)
4) Inference
SOLO의 inference 과정은 간단하다.
그냥 들어온 이미지를 FPN에 넣어서 다양한 resolution의 feature map을 얻고, 그 feature map들에 대해서 category score 와 개의 mask를 얻는다. 각각의 mask에 대해서 low confidence인 mask를 솎아내고(여기에서는 threshold 0.1 사용) 나머지는 NMS operation에 넣어서 final result를 찾는다.
3. Experiments
🏝 Grid number & Multi level prediction
하나의 grid cell에서 하나의 object만을 예측할 수 있는 SOLO의 구조 상 grid number를 얼마로 설정하느냐는 전체 성능에 매우 큰 영향을 미친다.
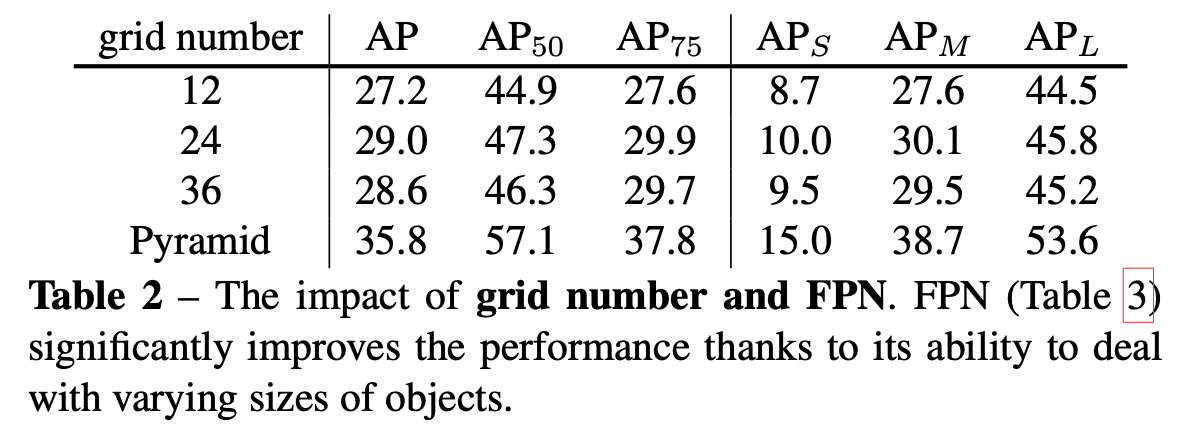
그리고 실험 결과 하나의 feature map에서 grid number를 fix해 나누는 것보다는 FPN 을 사용해 다양한 resolution의 feature pyramid에서 그에 맞는 grid number로 나누는게 multi-scale prediction에 훨씬 유리하다는 것을 알 수 있다.
🌃 SOLO visualization

visualization을 통해 일때 output mask map이 어떤 식으로 나오는지 확인할 수 있다.
4. Conclusion
이 논문에서는 추가적인 단계를 거치지 않고 바로 instance segmentation을 예측할 수 있는 프레임워크 SOLO를 소개한다.
- 기존의 instance segmentation method(i.e. Mask R-CNN) 비교해도 성능이 뒤지지 않음
- end to end로 학습할 수 있고, raw image to instance mask로 constant time에 inference할 수 있음
- box supervision이 필요없고 mask만 있으면 됨
등의 장점이 있다. 특히 Top-down approach에서 필요한 단계(box detection, roi operation)들이 많이 사라지고, box의 개수에 따라서 inference time이 달라지는게 아니라 constant time이 걸리니까 훨씬 안정적으로 사용 가능하다.
(+ 벨로그에서 수식 쓰니까 바로바로 확인할 수 있어서 너무 편하다 깃에서 쓰는것보다 훨씬 재밌게 쓰는중 😉😲)
Reference
