TIL - 자료구조 Session 0918
자료구조
: 자료구조란 데이터에 편리하게 접근하고, 변경하기 위해서 데이터를 저장하거나 조직하는 방법을 말합니다.
모든 목적에 맞는 자료구조는 없습니다.
자료구조의 분류
자료구조는 현재 사진 속에 담긴 것 보다 종류가 훨씬 많다.
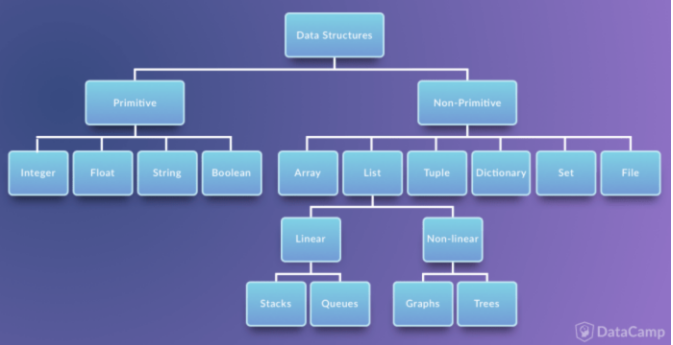
제일 많이 쓰는 자료구조의 종류
- 배열(List)
-
인덱스가 있기때문에 randam access가 가능 (아무거나 내가 순서잡아서 들어가서 자료 잡아 볼 수 있음)
-
cf. O(N) -> Big O Notation 왜 O임 ? 최악의 경우 n번째 까지 노테이션해야될 수 도 있음. 사이즈에 따라 속도가 linear하게 바뀐다. O(1) : 제일빨라 인덱스알고 들어가는 것 !
-
Muiti Dimentional Array
: 그리드나 매트릭스 표현할 때 해당 데이터를 활용 -
Array의 단점
:값을 하나 추가하면, 전체적으로 이동이 된다....순번이 전체이동 -
Array를 쓸 때는 임의공간을 확보해놓기. (밑단에서는 디폴트 사이즈가 있음, C 나 이런데서는 Array size를 미리 지정해야 함, 그래야지만 순차적으로 할 수 있음 & 중간에 공간을 확보를 안해놓으면, 느려짐.. -> 리사이징..)
: unit test로 찾기 힘든 문제임/ 메모리 예측이 되면, 메모리를 어느정도 미리 그만큼 확보해놓고 쓰는게 훨씬 안정적이다! -
비싼 operation
-
Array를 쓰면 좋을 때
- 순차적인 데이터를 저장할 때
- 어떠한 특정 요소를 빠르게 읽어야할 때
- 데이터의 사이즈가 급변하게 자주 변하지 않을 때
- 요소를 자주 삭제해야하지 않을 때
- Tuple(Phython에 있습니다 )
- 기본적으로는 list와 비슷
- tuple은 주로 한개부터 많게는 다섯개 정도 쓴다...많이는 안쓴다
- 수정불가
- 2개나 3개 정도의 소규모 데이터를 저장할 떄 씀
- 함수에서 리턴 값을 한개 이상 리턴하고 싶을 때 자주 씀
- 좌표값을 쓸 때 유용
- tuple 이 없으면 좌표와 같은 minor한 info를 줄 때, class를 굳이만들어야함
- 함수에서 2개 값을 리턴하고 싶을 때 tuple을 사용
Ex.def - tuple의 단점 : 불명확하다 (1,2) 면 우리는 (x, y) 라고 class 를 쓰면 알 수 있다. 그치만 tuple은 문맥상에서 알 수 있어야 됨 -> 파이썬에서는 그래서 named tuple을 사용
- set
- array나 list와 비슷한 순열 자료구조
- 순차적이지 않음 -> 순서가 없음
- 중복값이 안됩니다
EX.
(1,2,1) =>
{1,2,1} => {1, 2}** 원래있던 1이 중복되는 값이여서 뒤의 1번째는 나오지않음(맨 뒤에 들어온 1이 원래 있던 1을 치환함)
- 수정가능
- 왜 set는 중복값이 안되고, 순서가 없을까?
- hash: 단방향 암호 / 숫자3333
set 1 이라고 하면, 1을 hash해요, 16진수로 표현되요, hash값에 해당하는 id를(hash로 주소를 찾아가지고간다, hash는 저장 안함, why? 이미 hash처리를 하면 동일한 값이 나옴, 동일문자에 대해서는 ) 가지고 있는 bucket같은 거에 1을 저장합니다. 이 hash값은 이 바구니고, 이렇게 연결되어있음.
- 어떻게 연결되는 건데? hash해서 나온 값이랑 메모리공간이랑 , set는 밑단에서 array를 사용 , 메모리공간을 미리 할당하고 있음 우리는 array를 사용
bucket size 로 hash를 나눈 후에... 나머지 값으로 index를 사용한다..
(이것도 나머지 값이 같으면 hash충돌난다, 많이 넣다보면 충돌이 있을 수 있다. 그치만 흔하지는 않다)
2를 저장하면, 이것도 hash 값 나옵니다. 이 hash값에 해당하는 바구니에다가 저장합니다
그래서 순서가 없음 -> index도 없ㅛ습니다..
그런데 1을 또 저장하면,, hash를 또합니다.. hash에 해당하는 bucket에다가 또 해당 값을 넣음
그러면 원래 있던 값을 치환합니다
왜 치환해?
그냥 안넣으면 되니깐
좌표 1,2가 좌표 1,2 냐 이게 맞냐
확실할 수 없으니깐
최신 값이 나다!라고 하는 것
* hash화 하는 것-> 속도가 아주아주 빠름
- 실제 활용하는 데이터 : 전화번호, 이메일 (lookup table 쓸 때, 중복값 찾을때 사용)
-> for loop쓰면은 진짜 여러번 돌아야 되는데 , set은 그냥 넣기만 하면 중복 값 찾아줌!
코드짧아지고 속도도 빠름
for loop은 있는지 없는지 찾아봄 list에서의 search는 ON
set은 한번만 그 값을 찾으면 됨 O1
lookup을 찾아가는 것..?- Dictionary
- key와 정보의 짝이다..object와 비슷
- 해당정보가 뭐인지에 대한 lable을 붙여야할 떄
- 중복된 key를 넣을 수 없음
- key도 hash 와 같이 치환되고 그다음에 값이 bucket에 저장이 되는 것
- stack
- pick 이랑 pop의 차이
(pop은 return 하면서 지우는 것이고 pick은 최상단에 있는 것만 볼 수 있음) - 그 다음것을 보게 되면 그때부터는 stack , queue 가 아님
- Queue
- private queue는 운영체제는 private queue를 많이쓴다..
(맛집 예약 시스템, OS 프로세스 스케줄링 시스템 ) - first in - first out
- Tree
-
나무형태로 데이터를 저장하는 것, 트리 데이터 종류 되게 많음
-
일반적인 것은 binary tree (갈래가 딱 2군데로만 갈라짐)
: 예를들어 값이 20인데 10이 들어오면 왼쪽 트리로 22가 들어오면 오른쪽 트리로
그 다음에 7이 들어오면 10 기준으로 binary tree 10 에서 왼쪽
그리고 13이 들어오면 10보다 크니깐 오른쪽
tree는 일반적으로 검색이 유용하기때문에 사용함
tree는 면접에 많이 나올 수 있음
- 예상 질문
1.tree를 제대로 이해하고 있는가? 2. tree를 가지고 코딩을 해봐라 -
트리랑 다른 자료구조 , 그래프 ! 최단 거리 찾는데 사용
: 트리를 뒤집어 놓은 모습으로 사용, 바둑판 그리드 n by n -> 그래프로 생각해서 접근 할 수 있음
ex. 페이스북 친구리스트
node에 연결된 데이터를 표현하고 싶을 때 그래프를 많이 씀
1촌 리스트, 지도에서 최단거리 찾는 것 , 페이스북 친구리스트를 쓸 때 사용하기 쉽고
참고
-
고급 자료구조로 갈 수록 본인이 직접 구현해야 함
-
list, set, dictionary를 가장 많이쓰고 tree는 거의 안씀.
-
각 자료구조를 어떻게 쓰는지 차이를 알아야 함
-
면접에서 가장 효과적인 것이 알고리즘과 자료구조 !
Ex. stack 이 뭐냐, queue가 뭐냐 stack 한번 만들어봐라~
