
지난번 레코드 헤더를 파싱은 정말 흥미로웠다.
1바이트 단위로 데이터를 뜯어보면서 해석하고 바로 눈에 보이게 테스트할 수 있었기 때문이다.
실험 → 관찰 → 추론 → 수정이 빠르게 반복되니까 몰입하기가 쉬웠다.
그러나 페이지 단위 이상의 구조부터는 전체적인 그림을 먼저 그리지 않으면, 파싱 코드를 짜는 것조차 쉽지 않았다.
테스트 역시 단위로는 확인이 어렵고, 결국 ‘전체 흐름을 타봐야’ 제대로 검증할 수 있었다.
그렇게 당장 눈에 보이는 결과가 없으니, 이전보다 훨씬 더 지루하고 느리게 느껴졌다.
방향을 잡기 위해 한동안은 공식 문서, 기술 블로그, 실제 서버 코드를 오가며 전체 구조를 머릿속에 그리는 데 집중했다.
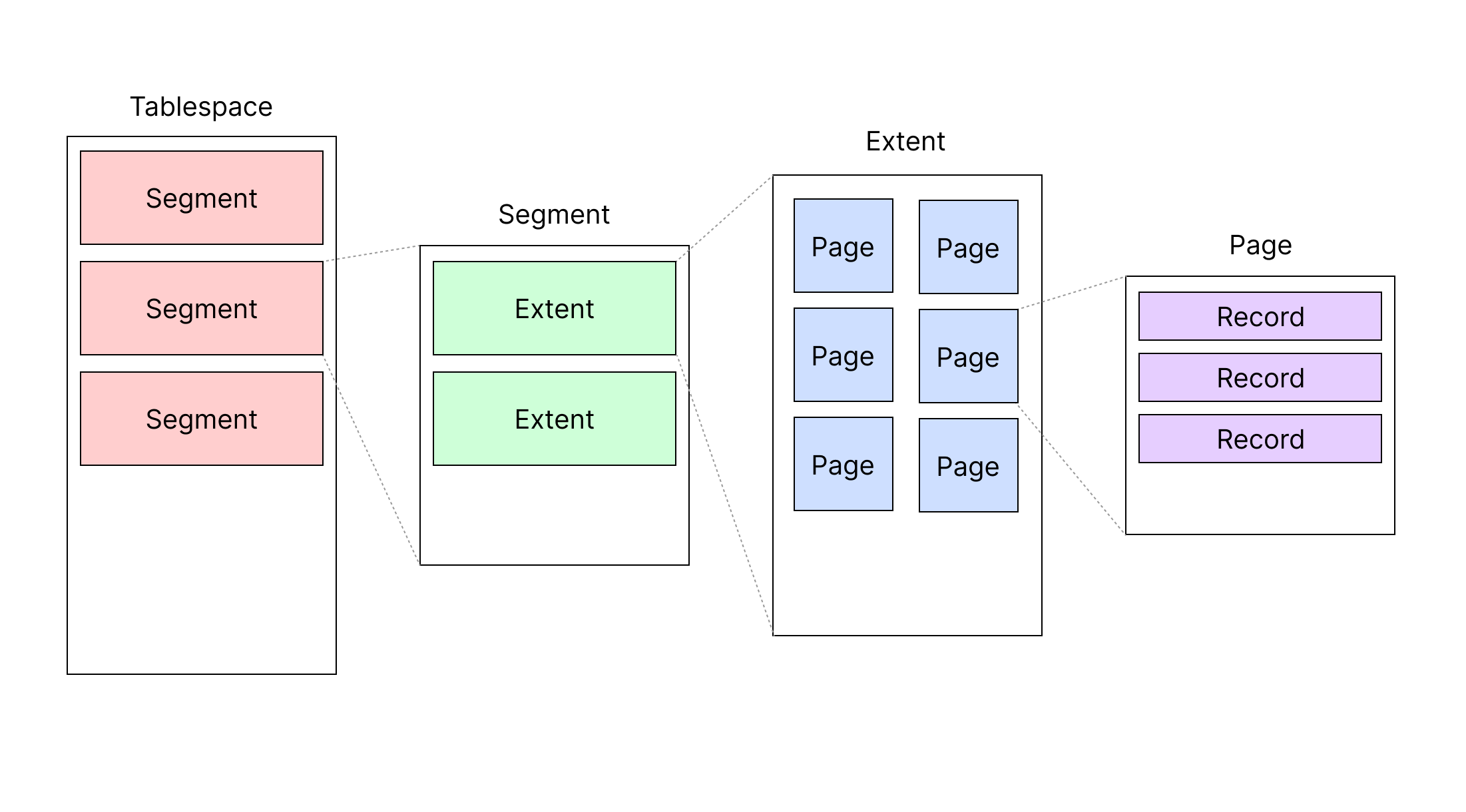
MySQL의 InnoDB는 Tablespace → Segment → Extent → Page로 이어지는 계층 구조로 데이터를 저장한다.
이 구조를 모르면 어떤 페이지를 어떻게 읽어야 하는지도 결정할 수 없다.
이번 글에서는 InnoDB의 저장 계층 구조를 전체적으로 정리해보려 한다.
특히 각 계층이 어떤 개념으로 구성되고 어떤 역할을 수행하는지에 집중할 예정이며,
세부적인 내부 구조와 메타데이터 관리 방식은 다음 글에서 이어서 설명할 예정이다.
Tablespace(Space) : 가장 큰 저장 단위
InnoDB의 저장 구조는 Tablespace(테이블스페이스)라는 논리 단위로 시작된다.
실제로는 ibdata1, ibdata2처럼 여러 물리 파일로 나뉘지만, InnoDB는 이를 하나의 논리적인 공간으로 인식하고 관리한다.
예를들어 시스템 테이블스페이스는 ibdata1, ibdata2 등으로 나눠져서 저장되지만 InnDB는 이를 하나의 논리 공간으로 처리한다.
Tablespace의 종류
시스템 스페이스(System Tablespace)
트랜잭션 시스템, Undo 로그, 데이터 딕셔너리, Insert Buffer, Double Write Buffer 등 InnoDB 내부의 다양한 메타데이터와 부가 구조가 이곳에 저장된다.
또한 일부 시스템 페이지는 특정 페이지 번호에 고정적으로 위치한다는 특징이 있다.
테이블별 스페이스(Per-table Tablespace)
innodb_file_per_table 설정이 활성화된 경우, MySQL의 각 테이블은 .ibd 파일로 별도 분리 저장된다.
논리적으로는 독립된 스페이스이지만 대부분 하나의 테이블 데이터만 저장하는 용도로 사용된다.
이 .ibd 파일 내 대부분의 페이지는 INDEX 페이지 타입이다.
B+Tree 구조의 인덱스 페이지를 통해 테이블의 실제 레코드 데이터가 저장된다.
Tablespace의 크기 제한
InnoDB는 Tablespace 내의 각 페이지에 대해 32비트 크기의 페이지 번호(Page ID)를 사용한다.
페이지 하나의 크기는 기본적으로 16KB이므로 하나의 테이블스페이스는 2^32 * 16KB = 64TB까지 확장 가능하다.
Page : 가장 기본적인 저장 단위
InnoDB에서 디스크에 데이터를 저장하거나 읽어올 때 사용하는 최소 I/O 단위는 Page(페이지)다.
레코드가 논리적으로는 가장 작은 데이터 단위이지만, 물리적인 저장과 이동은 페이지 단위로 이루어진다.
InnoDB는 데이터를 16KB 단위의 페이지에 담아 저장하고 이 단위로 I/O를 수행한다.
운영체제의 디스크 I/O는 보통 4KB나 8KB 단위로 이뤄지지만,
InnoDB는 내부적으로 16KB 이상을 기본 단위로 묶어 관리함으로써 I/O 효율을 높인다. (디스크의 경우 랜덤 I/O 보다 순차 I/O가 효율적이기 때문에)
페이지의 구조
모든 페이지는 다음의 고정된 구조를 갖는다. 이 구조는 모든 페이지 타입에 공통적으로 적용된다.

FIL Header (38바이트)
- 페이지 타입, 스페이스 ID, 페이지 번호, 체크섬, LSN(Log Sequence Number), 앞/뒤 페이지 포인터 등 페이지의 메타데이터가 저장되는 영역이다.
본문 (Payload)
- 실제 데이터가 저장되는 부분이다. 페이지 타입에 따라 저장 내용이 달라진다. INDEX 타입 페이지라면 여기에 B+Tree 노드와 레코드가 저장된다.
FIL Trailer (8바이트)
- 페이지 끝에 위치한 체크섬 정보로, 데이터 손상을 감지하는 데 사용된다.
페이지 크기와 트레이드오프
I/O에 대한 이야기가 나온김에 페이지 크기에 대해서 이야기해보자.
기본 페이지 크기는 16KB지만 InnoDB는 설정에 따라 4KB, 8KB, 32KB, 64KB 등 다양한 크기를 지원한다.
| 페이지 크기 | 장점 | 단점 |
|---|---|---|
| 작을수록 | 메모리 낭비 적고, 랜덤 접근에 유리 | 디스크 I/O 횟수 증가, 압축 비효율 |
| 클수록 | 연속 I/O에 유리, 압축 효과 큼 | 소량 데이터일 때 공간 낭비, 수정 시 전체 페이지 쓰기 오버헤드 |
페이지 크기는 워크로드 특성에 따라 성능에 큰 영향을 준다. 작은 페이지는 세밀한 접근에 유리하고 메모리 낭비가 적지만, 랜덤 I/O가 많아져 성능이 떨어질 수 있다. 반면 큰 페이지는 연속된 데이터 접근에는 유리하지만, 소량의 데이터를 다룰 땐 오버헤드와 공간 낭비가 발생할 수 있다.
하지만 디스크 입장에서 16KB 단위의 랜덤 I/O는 여전히 비효율적일 수 있다.
그래서 InnoDB는 여러 페이지를 묶어 Extent라는 단위로 관리해 I/O 효율을 높인다.
Extent : 페이지를 묶어 효율적으로 관리하기
디스크 I/O는 랜덤 I/O보다 순차(sequential) I/O가 훨씬 효율적이다.
따라서 단순히 16KB씩 따로따로 읽고 쓰는 방식은 디스크의 물리적 특성과 맞지 않아 성능이 저하될 수 있다.
이 문제를 해결하기 위해 InnoDB는 여러 개의 페이지를 묶어 하나의 Extent(익스텐트)로 관리한다.
익스텐트란?
Extent는 연속된 64개의 페이지(= 1MB)를 묶은 단위이다.
이 단위를 통해 InnoDB는 페이지를 더 큰 블록 단위로 할당하고 관리할 수 있다.
단일 페이지 단위로 다루는 것이 아니라 64개씩 묶어서 처리함으로써, 디스크 I/O의 연속성과 효율성을 확보할 수 있다.
테이블에 많은 데이터를 삽입할 경우, InnoDB는 개별 페이지가 아닌 익스텐트 단위(1MB)로 공간을 할당한다.
익스텐트의 관리 방식
InnoDB는 테이블스페이스의 처음 몇 페이지(FSP_HDR, XDES 등)를 이용해 익스텐트들을 다음과 같이 추적한다.
- 어떤 익스텐트가 사용 중인지
- 그 익스텐트 내에서 어떤 페이지들이 사용 중인지
익스텐트 하나당 64개 페이지의 상태를 관리해야 하므로, 비트맵 구조를 활용해 공간을 아낀다.
익스텐트의 상태 (유형)
각 익스텐트는 다음 중 하나의 상태를 가질 수 있다.
| 상태 | 설명 |
|---|---|
| FREE | 완전히 비어 있어 어떤 용도로든 새로 할당 가능한 상태 |
| FREE_FRAG | 일부 페이지만 사용 중이며, 나머지는 조각(Page) 단위로 할당 가능한 상태 |
| FULL_FRAG | 조각 할당된 페이지가 가득 차 더 이상 개별 할당이 불가능한 상태 |
| FSEG | 해당 익스텐트가 특정 파일 세그먼트(Fil Segment)에 할당되어 사용 중인 상태 |
이 상태 정보는 XDES Entry 라는 구조로 관리되며, 테이블이나 인덱스가 사용하는 페이지들을 논리적으로 연결하는 데 사용된다.
Segment : 인덱스를 구성하는 논리적 단위
앞서 살펴본 페이지(Page)와 익스텐트(Extent)는 물리적인 저장 단위였다면, 이번에 다룰 Segment(세그먼트)는 인덱스나 테이블이 데이터를 저장하고 관리하기 위한 논리적인 단위다.
특히 InnoDB의 인덱스 구조(B+Tree)와 깊게 연결되어 있으며, 레코드들이 어떤 페이지에, 어떤 방식으로 담길지를 좌우하는 핵심 구조다.
세그먼트란?
세그먼트는 InnoDB에서 조각 페이지(fragmented pages)와 익스텐트(full extents)를 묶어 관리하는 상위 논리 구조다.
다른말로 "이 인덱스가 사용할 페이지들은 여기 다 모여있다"는 집합 개념이다.
InnoDB는 하나의 인덱스당 두 개의 세그먼트를 갖는다.
| 세그먼트 종류 | 설명 |
|---|---|
| Leaf Segment | B+Tree 리프 노드 (실제 데이터 레코드가 저장됨) |
| Non-Leaf Segment | B+Tree 내부 노드 (포인터와 키만 저장됨) |
공간 할당 전략
세그먼트는 처음부터 익스텐트 단위로 큰 덩어리를 받지 않는다.
InnoDB는 다음과 같은 점진적 할당 전략을 사용한다.
- 초기에는 페이지 단위로 조각 할당 (FREE_FRAG 익스텐트에서 한 페이지씩)
- 데이터가 증가하면 익스텐트 단위로 할당 (64 페이지 = 1MB)
- 더 많아지면 한 번에 4개 익스텐트(=4MB)씩 할당
이러한 구조 덕분에 InnoDB는 작은 테이블에도 공간 낭비 없이 대응하면서, 큰 테이블에는 빠르게 확장 가능한 구조를 유지할 수 있다.
세그먼트는 어떻게 관리될까?
각 세그먼트는 INODE Entry라는 구조체에 의해 설명되며, 이는 테이블스페이스 내의 INODE 페이지(보통 페이지 번호 2)에 저장된다.
INODE Entry 내부에는 세그먼트가 사용하는 익스텐트들을 아래와 같이 나눠 관리한다.
| 리스트 | 설명 |
|---|---|
| FREE | 아직 사용되지 않은 익스텐트 |
| NOT_FULL | 일부만 사용된 익스텐트 (추가 할당 가능) |
| FULL | 이미 꽉 찬 익스텐트 (더 이상 할당 불가) |
하나의 INODE 페이지는 85개의 세그먼트(INODE Entry)를 저장할 수 있다.
마치며
이번 글에서는 InnoDB의 저장 계층 구조에 대해 큰그림을 살펴봤다.
단순히 용어를 외우는 것을 넘어, 각 계층이 어떤 목적과 역할을 갖고 있는지를 이해하면서
InnoDB라는 스토리지 엔진이 왜 이런 구조를 택했는지를 조금은 체감할 수 있었다.
다음 글에서는 여기서 소개한 구조들이 실제로 어떻게 구현되고 관리되는지,
즉 각 페이지 내부의 구체적인 메타데이터 구조와 관리 방식에 대해 더 깊이 파고들어보려고 한다.
