사실 프로젝트는 꽤 오래 전부터 해보고 싶었다.
우테코를 하던 때부터 InnoDB를 직접 구현해보면 재밌겠다고 생각했는데, 당시에 시간이 부족해서 결국 제대로 시도하지 못했다.
6개월간 인턴 생활을 마친 뒤 다시 여유가 생겼고, 지금이 아니면 또 미룰 것 같아서 바로 시작했다.
이번 기회에 데이터베이스 구조를 조금 더 깊이 있게 이해하고 싶었고, 직접 만들어보는 것만큼 확실하게 배우는 방법도 없다고 생각했다.
공부 방법은 간단하다.
Jeremy Cole의 블로그 시리즈를 번역하면서 구조를 뜯어보는 거다.
처음에는 이 글을 보며 페이지 헤더부터 분석하려고 했는데,
레코드가 먼저 잡혀야 페이지가 뭔지 감이 잡히겠다는 생각이 들었다.
그래서 방향을 틀어서 8편 글인 "The physical structure of records in InnoDB"부터 보기 시작했다.
레코드 하나하나를 까보는 게 페이지 구조를 이해하는 데에도 훨씬 직관적이라는 판단이었다.
MySQL에는 Compact, Redundant, Compressed, Dynamic 등 다양한 포맷이 존재하는데,
이번 구현에서는 Compact 포맷만 먼저 다루기로 했다.
참고로 MySQL 8.0에서는 기본 포맷이 Dynamic이지만, Compact와 내부 구조는 대부분 유사하다.
Compact 포맷은 필드 길이, NULL 여부 등을 비트 단위로 압축해 저장한다.
따라서 공간 효율이 좋고 파싱 로직도 비교적 직관적이다.
대신 이후 다른 포맷들도 확장할 수 있도록 구조를 인터페이스화해서
헤더 파서 쪽은 나중에 포맷에 따라 유연하게 바꿀 수 있는 형태로 만들었다.
바이트 관찰하기
JCole의 블로그를 따라가면서 hexdump로 .ibd 파일(테이블의 데이터를 저장하는 파일)을 하나하나 찍어봤다.
파일 경로는 아래와 같다. 레코드 헤더 구조를 보기 위해 .ibd 파일을 hexdump로 실행시켜 직접 바이트단위로 관찰해봤다.
# /var/lib/mysql/{데이터베이스 이름}/{테이블 이름}.ibd
/var/lib/mysql/test_db/test_table.ibdibd 파일을 열어서 눈으로 보기 시작했는데, 문제는 어디가 레코드고 어디까지가 헤더인지 도무지 감이 안왔다.
그냥 바이트 나열만 한참 보다가, 중간쯤에 varchar 필드로 넣었던 이름 데이터("Alice", "Bob") 같은 문자열로 눈에 보였다.
‘아, 여기가 레코드 데이터고, 그 앞부분이 헤더겠구나’ 하는 막연한 추측이 들었다.
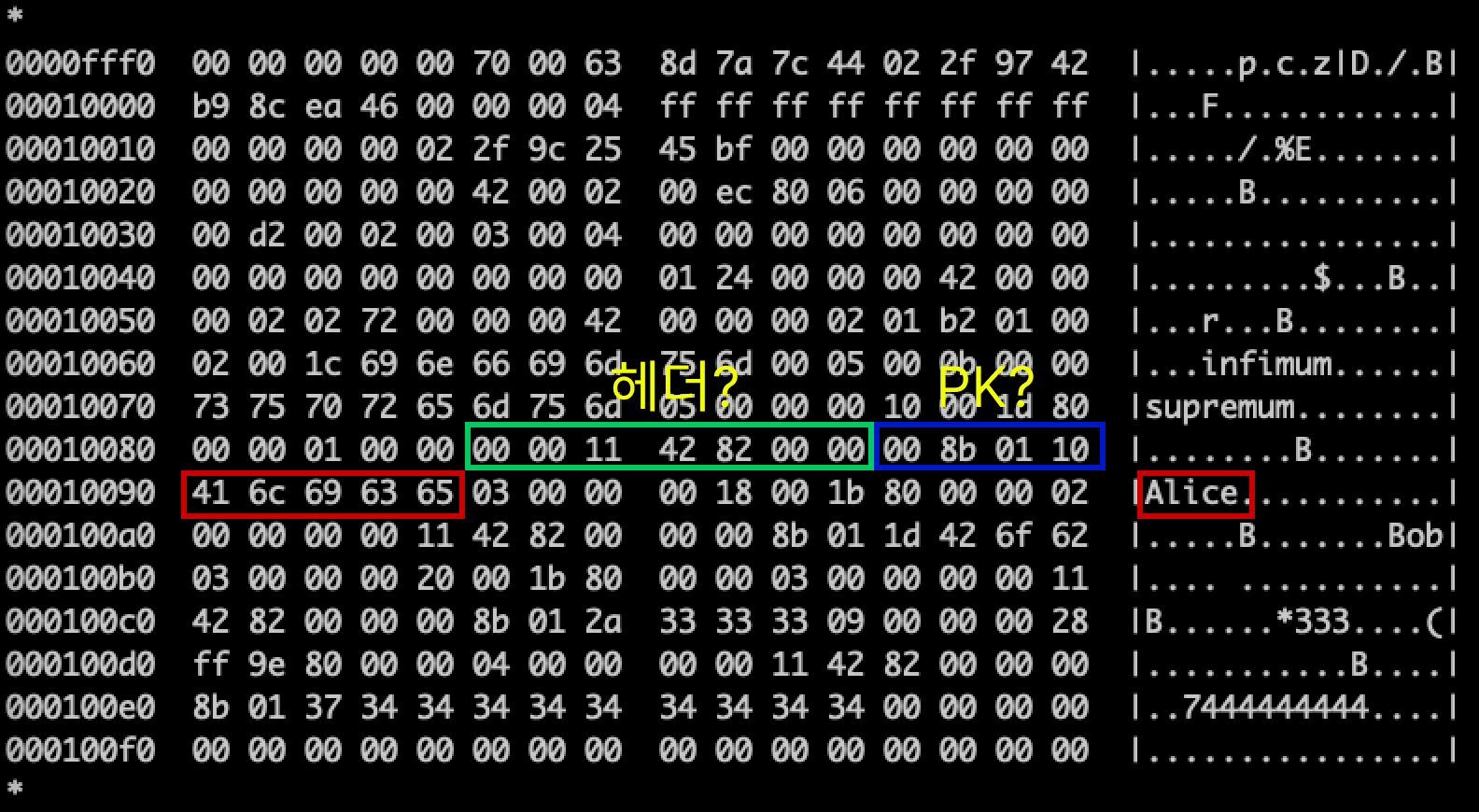
그래서 "Alice" 앞부분부터 몇 바이트를 거슬러 올라가봤다.
그런데 내가 예상했던 INT id 값 자리에 이상한 값들이 들어가 있는 거다.
분명히 id = 1이어야 하는데, 전혀 관련 없는 값들이 들어있었다.
처음에는 Jeremy Cole이 잘못 쓴 줄 알았다.
진지하게 "블로그가 틀렸나?" 하는 생각도 들었고, MySQL 버전이 달라서 그런 건가 싶기도 했다.
하지만 다시 천천히 뜯어보니까 내가 완전히 잘못 짚고 있었던 거였다.
블로그 글 아래쪽에 Clustered Indexes 부분을 다시 읽고 나서야 이해가 됐다.
이상한 값으로 보였던 건 사실 Transaction ID와 Roll Pointer였다. (이 값들은 MVCC 기능을 위해 필요한 값임)
내가 INT id라고 착각했던 영역은 실제 레코드의 숨겨진 시스템 필드였던 것이다.
InnoDB의 클러스터형 인덱스 특성상, 모든 레코드에는 이 두 필드가 기본적으로 붙는다.
이런 오해와 삽질은 앞으로도 계속 나올 예정이다.
Record Header 구조 파악하기 (With 삽질)
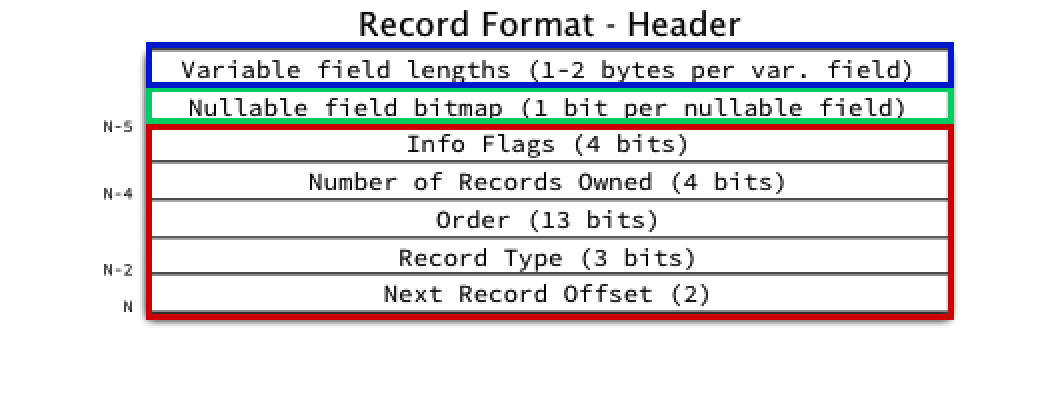
레코드 헤더는 크게 3가지로 나뉜다.
- 고정 길이 헤더 (Fixed Header) - 빨간색
- NULL 비트맵 (Nullable Bitmap) - 초록색
- 가변 길이 필드 길이 정보 (Variable Field Lengths) - 파란색
레코드 헤더는 역방향 (큰 바이트 -> 작은 바이트 방향) 으로 읽어야 한다.
위 그림 기준으로 아래쪽 (Next Record Offset) 에서 윗쪽(Variable field lengths) 으로 읽는다.
이때 읽기 시작하는 기준점을 Origin 이라 한다. Origin은 Record 본문의 시작 주소이고, 이 주소를 N으로 둔다.
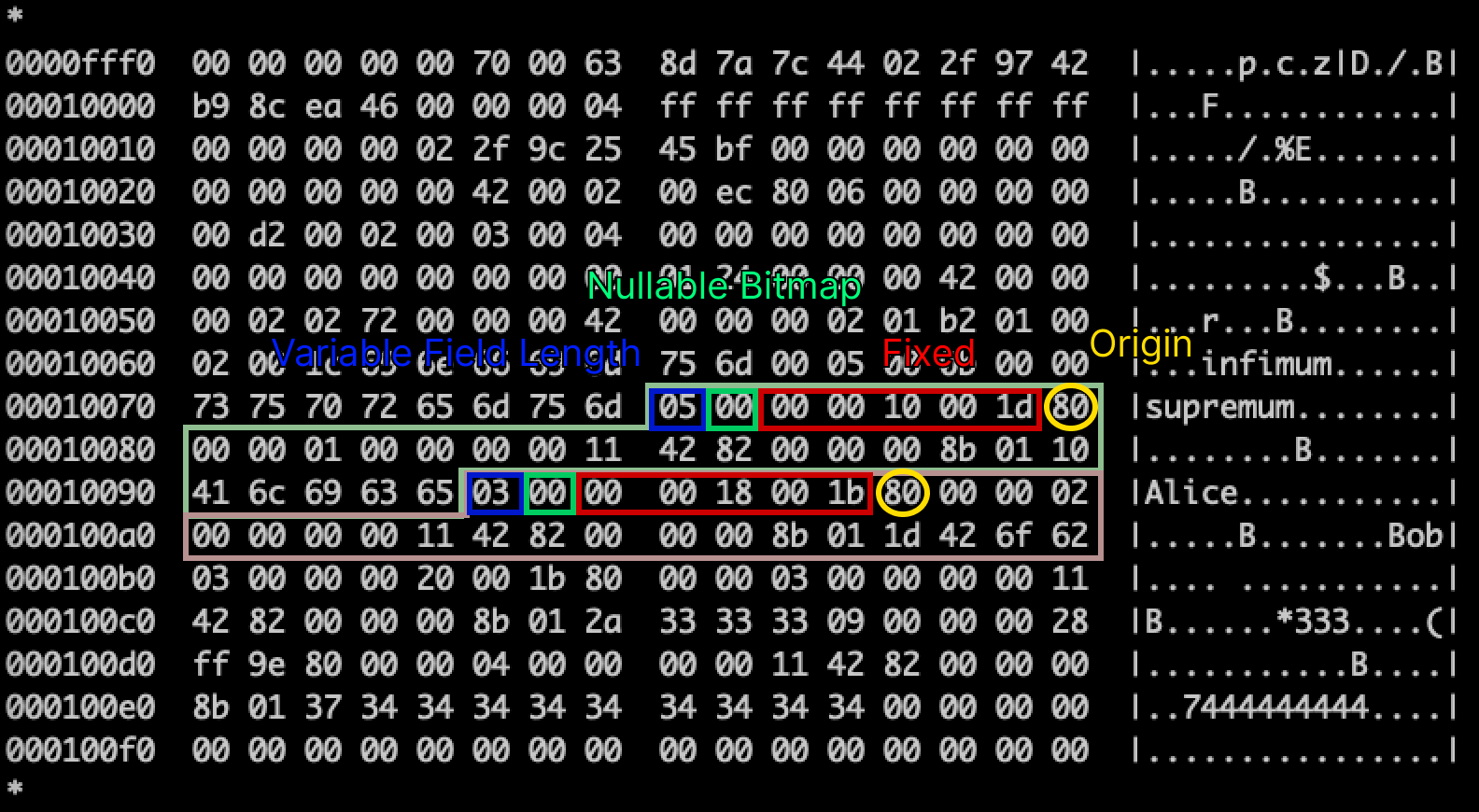
고정 Header 파싱
어떤 레코드든 필수적으로 아래 헤더정보들을 가지고 있다.
Next Record Offset (N-1 ~ N-2)
다음 레코드의 Origin 주소다. Origin에서 역방향으로 2바이트를 한번에 읽으면 된다. 위 사진의 0001007f 번 주소를 보면 첫번째 레코드의 Origin이 보인다. Origin의 이전 두 바이트(0x00 0x1d)가 Next Record Offset 이다. 실제로 29(0x1d의 십진수 변환값)칸 뒤에 다음 레코드의 Origin 이 나온다. 이 값을 통해서 다음 레코드 값을 알 수 있다.
나는 처음에 앞 record header의 시작부터 뒤 record header의 간격인줄 알았다. 숫자가 안맞는다 생각해서 여러번 삽질을 했다.
heap_no와 record_type (N-3 ~ N-4)
이 두 필드는 2바이트에 묶여 있는데, 어떤 순서로 읽고 비트를 분해할지가 좀 헷갈린다.
결론부터 말하면 두 바이트(0x00 0x10)를 한번에 읽고, 이진수로 변환한다. 상위 13개의 비트는 heap_no, 하위 3개의 비트는 record_type이다.
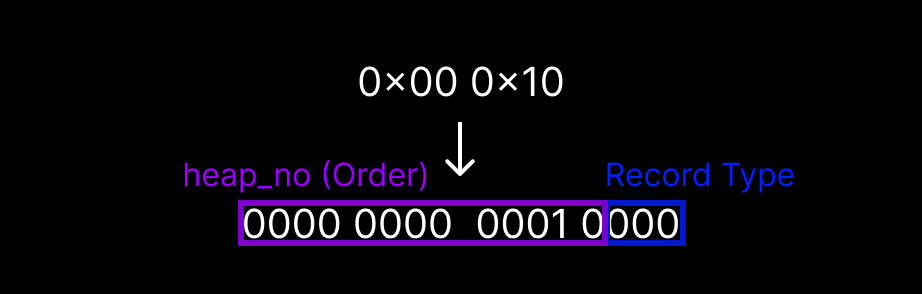
heap_no(Order)는 정렬 기준이 되는 번호다.
B-Tree 구조상 Page 내부에서 정렬된 순서를 보장하는 용도로 사용된다.
record_type은 레코드가 어떤 타입인지를 나타내는 필드다.
- 일반 레코드 : 0
- 삭제된 레코드 : 1
- infimum (최소 레코드) : 2
- supremum (최대 레코드) : 3
Info Flag + Number of Records Owned (N-5)
상위 4비트는 Info Flag다.
레코드에 대한 추가적인 상태 정보를 담고 있는 4비트 필드다. Record Type과 중복된 정보가 아닌가 싶다.
- 일반 레코드 : 0
- 삭제된 레코드 : 1
- infimum : 2
- supremum : 3
하위 4비트는 Number of Records Owned이다.
해당 레코드가 Page Directory 상에서 몇 개의 레코드를 대표하는지 나타내는 필드다.
레코드 정렬과 검색 속도 최적화를 위한 구조적 힌트라고 한다. 나중에 Page Directory라는 개념을 학습하게 되면 공부해봐야겠다.
infimum이나 supremum 레코드는 이 값이 0이다.
Nullable 비트맵
Compact 포맷에서는 테이블에 nullable 필드가 하나라도 존재하면
레코드 헤더에 null 여부를 나타내는 비트맵(nullable bitmap) 이 추가된다.
비트맵은 각 nullable 필드의 NULL 여부를 1비트씩 표현하기 때문에 nullable 필드의 개수만큼 비트가 필요하다.
예를 들어 nullable 필드가 3개라면 3비트가 필요하고, 이를 위해 1바이트가 사용된다.
nullable 필드가 9개라면 9비트가 필요하므로 2바이트가 사용된다.
nullable 필드가 하나도 없는 테이블이라면, 이 nullable 비트맵 영역 자체가 생략된다.
(nullableColumnCount + 7) / 8)
비트 값이 1이면 해당 필드가 NULL이고, 0이면 NOT NULL이다.
비트 순서는 첫번째 nullable 필드부터 낮은 자릿수에 저장된다.
다음 예시를 보자.
CREATE TABLE test_nullable (
id INT PRIMARY KEY,
col1 VARCHAR(50) NULL,
col2 VARCHAR(50) NULL,
col3 VARCHAR(50) NULL,
col4 VARCHAR(50) NULL,
col5 VARCHAR(50) NULL,
col6 VARCHAR(50) NULL,
col7 VARCHAR(50) NULL,
col8 VARCHAR(50) NULL,
col9 VARCHAR(50) NULL,
col10 VARCHAR(50) NULL
) ROW_FORMAT=COMPACT;
INSERT INTO test_nullable (id, col1, col2, col3, col4, col5, col6, col7, col8, col9, col10)
VALUES (3, 'x', NULL, NULL, 'y', NULL, NULL, 'z', NULL, NULL, 'w');위 레코드의 헤더의 nullable bitmap을 분석해보자.
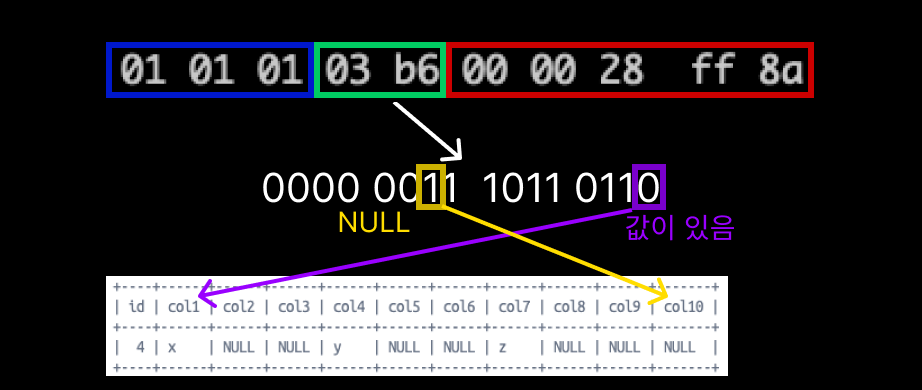
우선 PK 인 id는 nullable이 아니므로 정보에 포함되지 않는다.
낮은 비트부터 col1(0), col2(1), col3(1), col4(0), ... col10(1) 이다.
이 비트맵의 정보를 바탕으로 해당 필드를 건너뛸지 해석할지를 결정할 수 있다.
가변 길이 필드
Compact 포맷에서는 VARCHAR, TEXT 등의 가변 길이 필드가 존재할 경우,
레코드 헤더에 해당 필드들의 길이 정보가 가변적으로 추가된다.
가변 길이 필드마다 1바이트 또는 2바이트가 할당된다.
길이가 128바이트 이상이면 2바이트로 저장된다.
또한 필드의 최대 길이가 255보다 커도 2바이트로 저장된다.
최대 길이가 255 이하이며 실제 값이 127바이트 이하일 경우에만 1바이트에 저장된다.
외부저장이 발생한 경우에도 2바이트가 할당된다.
외부저장이 발생하면 내부에 최대 768바이트만 저장되고 나머지는 외부페이지에 저장된다.
저장한 외부페이지의 20바이트 포인터를 내부에 저장한다.
따라서 이 경우 768 + 20 = 788바이트 길이로 가변 길이 필드가 기록된다.
또한 nullable bitmap 처럼 가변 길이 필드가 없는경우, 이 길이 정보 자체는 생성되지 않는다.
mysql 공식문서 - COMPRESSED Row Format
의문점들
사실 위에서 언급했던, 그리고 언급하지 않았던 삽질과 실험들은 내가 JCole의 글을 잘못 이해하거나 빠트려서 했던 삽질 이기도 하다.
하지만 가변 길이 필드의 경우는 블로그에 설명도 부족했다.
내가 의문이 생겼던 부분은 다음과 같다.
- 왜 CHAR 타입의 필드의 길이가 표시되는거지? CHAR은 고정 길이 타입 아닌가?
- 1바이트로 저장할때는 길이가 잘 저장되는거 같은데 2바이트로 저장되었을때 값이 이상한데?
- 가변 길이 필드가 1바이트로 저장되어 있는지 2바이트로 저장되어 있는지 어떻게 알 수 있을까?
어떤 질문은 공식문서나 다른 자료에도 답을 찾지 못했다. gpt나 gemini에게 질문해도 이상한 답변밖에 듣지 못했다.
사실 위에서 언급했던, 그리고 언급하지 않았던 삽질과 실험들은
대부분 내가 JCole의 글을 잘못 이해했거나, 중요한 디테일을 놓쳤기 때문에 생긴 문제들이었다.
하지만 가변 길이 필드에 대한 설명은 블로그 자체에도 정보가 부족했다.
당시에 내가 궁금했던 것들은 다음과 같다:
- 왜 CHAR 타입의 필드 길이 정보가 레코드 헤더에 붙는 걸까? CHAR은 고정 길이 아닌가?
- 1바이트로 저장될 때는 길이가 잘 해석되는데, 2바이트로 저장된 경우엔 값이 이상하게 해석된다.
그리고 가장어려웠던 질문
- 가변 길이 필드가 1바이트로 저장됐는지, 2바이트로 저장됐는지를 어떻게 알 수 있을까?
공식 문서나 블로그를 아무리 뒤져도 이 세 번째 질문에 대한 직접적인 답은 찾기 어려웠다.
GPT나 Gemini한테 물어봐도 전형적인 얘기만 반복하거나, 아예 틀린 얘기를 하기도 했다.
CHAR도 가변 길이다?
다음과 같은 테이블을 만들고 데이터를 넣어었다.
DROP TABLE IF EXISTS sample;
CREATE TABLE sample (
id INT NOT NULL AUTO_INCREMENT,
col CHAR(10) NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB;
INSERT INTO sample (col) VALUES ('test');처음에는 CHAR은 고정 길이니까 가변 길이 필드에 들어갈 리 없다고 생각했다.

하지만 hexdump 상에서 길이 정보가 들어가 있었다. 왜 고정된 길이를 저장하는거지?
다행이었던 건, CHAR에 대한 의문은 비교적 빠르게 해결할 수 있었다. 이건 문자셋의 특성 때문이었다.
utf8mb3 and utf8mb4 character sets can require up to three and four bytes per character, respectively
mysql 공식문서 - String Type Storage Requirements
알고 보니 utf8mb3 또는 utf8mb4처럼 다중 바이트 문자셋을 쓰면, 실제 저장되는 바이트 수가 고정되지 않기 때문에 CHAR도 가변길이처럼 처리될 수 있었다.
즉, CHAR은 문자 수 기준으로는 고정일 수 있지만,
바이트 수 기준으로는 고정이 아니기 때문에 InnoDB는 이를 가변 길이 필드처럼 처리한다.
DBMS는 타입명(CHAR, VARCHAR)만 보고 판단하는 게 아니라,
저장될 수 있는 바이트의 유동성을 고려해서 실제 저장 방식을 결정한다는 걸 알 수 있었다.
이를 확인하기 위해 이번에는 문자셋을 latin1으로 바꿔서 테스트해봤다.
DROP TABLE IF EXISTS sample;
CREATE TABLE sample (
id INT NOT NULL AUTO_INCREMENT,
col CHAR(10) NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB
DEFAULT CHARSET = latin1;
INSERT INTO sample (col) VALUES ('test') ;
문자셋을 latin1으로 설정했더니 CHAR(10) 필드는 가변 길이 필드 정보에서 사라졌다.
latin1은 단일 바이트 문자셋이기 때문에, CHAR(10)은 실제로도 정확히 10바이트를 차지하고,
InnoDB 입장에서는 이를 고정 길이 필드로 안전하게 판단할 수 있게 된다.
2바이트로 저장될때 값이 이상하다
1바이트일 때는 가변 길이 필드의 길이가 명확하게 해석된다.
예를 들어 VARCHAR(255)에 "abc"를 넣으면, 헤더 상 길이 정보는 0x03으로 정상 표시된다.
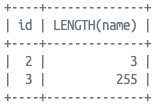
그런데 VARCHAR(255)에 정확히 255바이트 길이의 문자열을 넣었을 때는,
길이 정보가 0xFF 0x80으로 저장된다.
처음 봤을 땐 “길이가 0xFF80 = 65408…? 말이 안 되는데?” 싶었다.

값이 너무 이상해서 처음엔 인코딩 문제인가 싶었고,
내가 잘못 파싱한 줄 알고 코드도 여러 번 뜯어봤지만, 역시 아니었다.
이 문제를 고민하던 중, 관련해서 또 하나의 궁금증이 생겼다.
가변 길이 필드가 1바이트로 저장됐는지, 2바이트로 저장됐는지를 어떻게 알 수 있을까?
테이블의 스키마 정보를 보면 VARCHAR(255)라는 건 알 수 있다.
즉, 최대 길이는 알 수 있지만, 실제 저장된 데이터가 몇 바이트인지는 레코드를 직접 파싱하기 전에는 알 수 없다.
게다가 가변 길이 필드가 2바이트로 저장되는 조건은 단순히 "필드의 최대 길이가 255보다 크다" 뿐만 아니라,
"실제 값이 128바이트 이상"일 경우에도 2바이트로 저장된다.
즉, 레코드 내부를 실제로 까보지 않으면 1바이트인지 2바이트인지 알 수 없다.
검색도 해보고, GPT나 Gemini에게도 물어봤지만 마땅한 설명은 얻지 못했다.
결국 방법은 하나, 직접 실험해보는 것뿐이었다.
여러 케이스를 반복적으로 실험하면서 값을 관찰했고,
길이 정보를 나타내는 2바이트를 비트로 변환해서 분석해봤다.
앞 바이트(high)와 뒷 바이트(low)를 이어붙인 후,
맨 앞 비트를 제거(즉, 뒷 바이트의 최상위 비트 제거) 해보니,
그제야 정확한 길이 값이 나왔다.
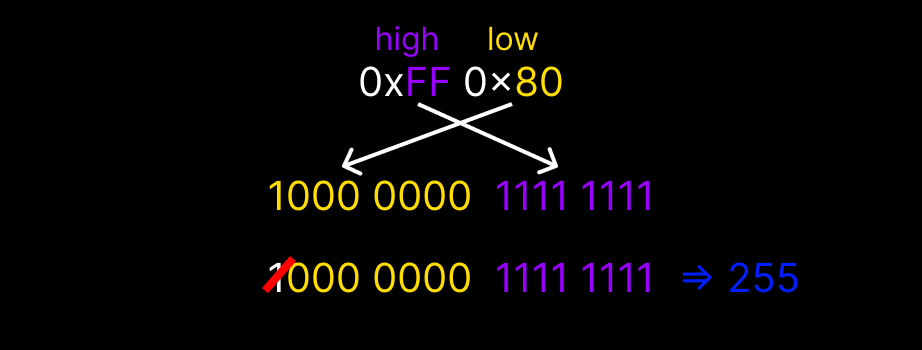
또한 대부분의 경우에서 뒷 바이트의 맨 앞 비트는 1이었다.
즉, 뒷 바이트가 1xxxxxxx 형태로 시작된다는 것을 확인할 수 있었다.
그때 내가 생각한 해석 로직은 다음과 같다:
((뒷바이트 & 0b01111111) << 8) | 앞바이트
하지만 이건 어디까지나 실험적으로 유도한 로직이었다.
확신이 없어서 결국 직접 MySQL 서버 소스코드를 까보기로 했다.
MySQL 서버 코드에서 확인한 공식 구현
InnoDB 내부에서 레코드의 가변 길이 필드를 파싱하는 로직은
다음 두 위치에 정의되어 있다:
다음은 해당 구현의 핵심 부분이다:
// data0type.h - 대용량 타입 여부를 확인하는 함수 정의
/* For checking if mtype is BLOB or GEOMETRY, since we use BLOB as
the underling datatype of GEOMETRY(not DATA_POINT) data. */
inline bool DATA_LARGE_MTYPE(ulint mtype) {
return mtype == DATA_BLOB || mtype == DATA_VAR_POINT ||
mtype == DATA_GEOMETRY;
}
/* For checking if data type is big length data type. */
inline bool DATA_BIG_LEN_MTYPE(ulint len, ulint mtype) {
return len > 255 || DATA_LARGE_MTYPE(mtype);
}
// rem0rec.cc - 실제 가변 길이 필드를 파싱하는 로직
if (!field->fixed_len || (temp && !col->get_fixed_size(temp))) {
/* Variable-length field: read the length */
len = *lens--; // 바이트 하나 읽기 (low byte)
/* If the maximum length of the field is up
to 255 bytes, the actual length is always
stored in one byte. If the maximum length is
more than 255 bytes, the actual length is
stored in one byte for 0..127. The length
will be encoded in two bytes when it is 128 or
more, or when the field is stored externally. */
if (DATA_BIG_COL(col)) {
if (len & 0x80) { // 맨 앞 비트가 1인가?
/* 1exxxxxxx xxxxxxxx */
len <<= 8;
len |= *lens--; // (low byte + high byte 결합)
offs += len & 0x3fff; // 실제 길이 계산 (하위 14개 비트만 사용 : 15비트 사용하는걸 예상했는데 틀렸음)
if (UNIV_UNLIKELY(len & 0x4000)) { // 14번째 비트 확인 (외부 저장 여부를 판단)
ut_ad(index->is_clustered());
any_ext = REC_OFFS_EXTERNAL;
len = offs | REC_OFFS_EXTERNAL;
} else {
len = offs;
}
goto resolved;
}
}
len = offs += len;
}정리하면 다음과 같다.
- 2바이트로 저장되는 경우에 첫 번째 바이트의 최상위 비트(0x80) 가 1이다.
- 이 비트가 2바이트 모드 진입 여부를 나타낸다.
- 이 경우 전체 길이는
len = ( (low_byte << 8) | high_byte ) & (0x3FFF)이다.
- 첫번째 바이트의 두번째 비트가 1이면 해당 필드는 외부 저장(overflow page) 으로 관리된다.
마치며
레코드 헤더 하나 제대로 파싱하는 데도 생각보다 많은 삽질이 필요했다.
처음에는 단순히 hexdump만 보면 쉽게 구조가 보일 줄 알았지만,
실제로는 공식 문서에도 안 나와 있는 디테일들이 많았고 결국엔 MySQL 서버 소스코드까지 뜯어보는 상황까지 왔다.
하지만 그만큼 얻는 것도 많았다.
단순히 "이 필드는 몇 바이트다" 수준이 아니라,
왜 이런 구조를 가졌는지,
어떤 조건에서 바이트 수가 달라지는지,
DBMS는 어떤 기준으로 판단하는지까지 체감할 수 있었다.
