
Real MySQL 8장 인덱스를 읽던 중 B-Tree 인덱스를 통한 데이터 읽기 전략들이 실제로 동작하는지 궁금했다. 그래서 실제로 데이터를 추가해 여러가지 테스트를 해봤다. MySQL 8.3.0 버전에서 테스트해봤다.
bash-4.4# mysql --version
mysql Ver 8.3.0 for Linux on aarch64 (MySQL Community Server - GPL)데이터 준비
CREATE DATABASE test;
use test;
CREATE TABLE USER (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
age INT,
created_date DATE,
created_time TIME
);test DB를 만든 후 위와 같은 테이블을 만들었다.
DELIMITER //
CREATE PROCEDURE InsertUsers()
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE random_num INT;
WHILE i <= 500000 DO
SET random_num = FLOOR(RAND() * 100000 + 1);
INSERT INTO USER (name, age, created_date, created_time)
VALUES (CONCAT('Person', random_num), FLOOR(RAND() * 100 + 1), CURDATE(), CURTIME());
SELECT COUNT(1) FROM USER;
SET i = i + 1;
END WHILE;
END //
DELIMITER ;
CALL InsertUsers();
SELECT * FROM USER;
-- 500000 rows in set (0.19 sec)다음과 같은 프로시저를 이용해 50만건의 데이터를 생성했다.
Index Range Scan
SELECT * FROM USER WHERE age < 5
다음과 같은 쿼리가 있다.
-- without index
SELECT * FROM USER WHERE age < 5;
-- 19841 rows in set (0.14 sec)
mysql> EXPLAIN ANALYZE SELECT * FROM USER WHERE age < 5;
-- +-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | EXPLAIN |
-- +-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | -> Filter: (`USER`.age < 5) (cost=50276 rows=166315) (actual time=0.143..156 rows=19841 loops=1)
-- -> Table scan on USER (cost=50276 rows=498996) (actual time=0.133..136 rows=500000 loops=1)
-- |
-- +-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
인덱스를 걸지 않고 나이가 5보다 작은 사용자를 조회했고 0.14초가 걸렸다. Table scan on USER 라는 문장이 보인다. 이 문장은 USER 테이블에 대해 풀 테이블 스캔이 일어났다는 의미다. 풀 테이블 스캔이 일어나면 테이블 전체를 순차 I/O로 읽는다. (인덱스를 이용 할 경우 랜덤 I/O로 읽는 경우가 있으니 비교하자) 그 후 모든 행이 WHERE 조건을 만족하는지 검사한다.
이제 age에 인덱스를 걸어 Index Range Scan이 일어나도록 유도해보자.
-- with index (age)
CREATE INDEX idx_age ON USER (age);
SELECT * FROM USER WHERE age < 5;
-- 19841 rows in set (0.07 sec)
mysql> EXPLAIN ANALYZE SELECT * FROM USER WHERE age < 5;
-- +---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | EXPLAIN |
-- +---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | -> Index range scan on USER using idx_age over (NULL < age < 5), with index condition: (`USER`.age < 5) (cost=17278 rows=38396) (actual time=0.0651..64.5 rows=19841 loops=1)
-- |
-- +---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
Index range scan on USER using idx_age over (NULL < age < 5) 에서 알 수 있듯, Index Range Scan이 일어났다. 시간은 훨신 단축된 0.07초가 걸렸다.
Index Range Scan
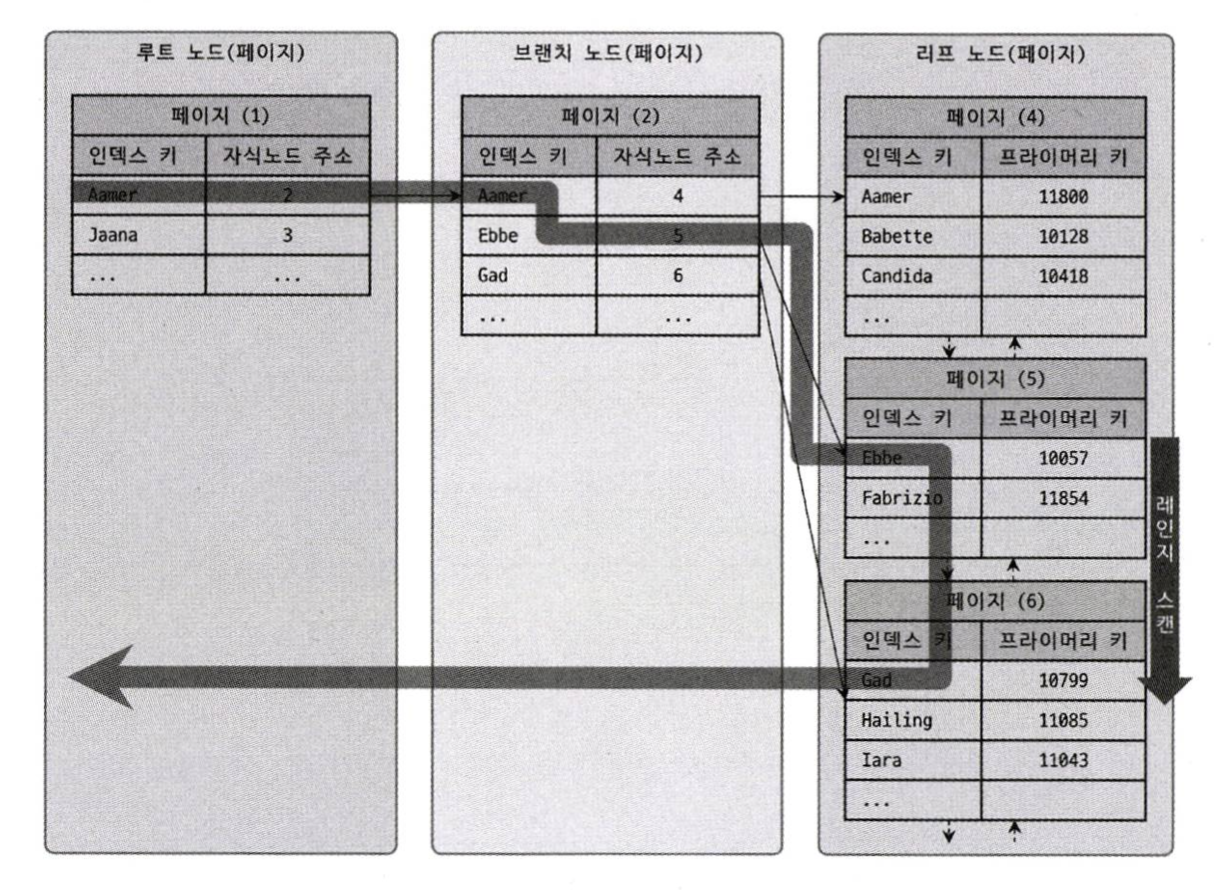
인덱스 레인지 스캔은 검색해야 할 인덱스의 범위가 결정됐을 때 사용된다. 우선 인덱스(idx_age)의 루트 노드부터 시작해 브랜치 노드를 거쳐 리프노드의 탐색 시작점을 찾는다. 지금 예제에서는 age = NULL, 테이블의 가장 앞부분이 탐색 시작점이다. 그 후 리프노드의 레코드를 순서대로 읽다가 age = 5 인 지점에서 빠져나온다.
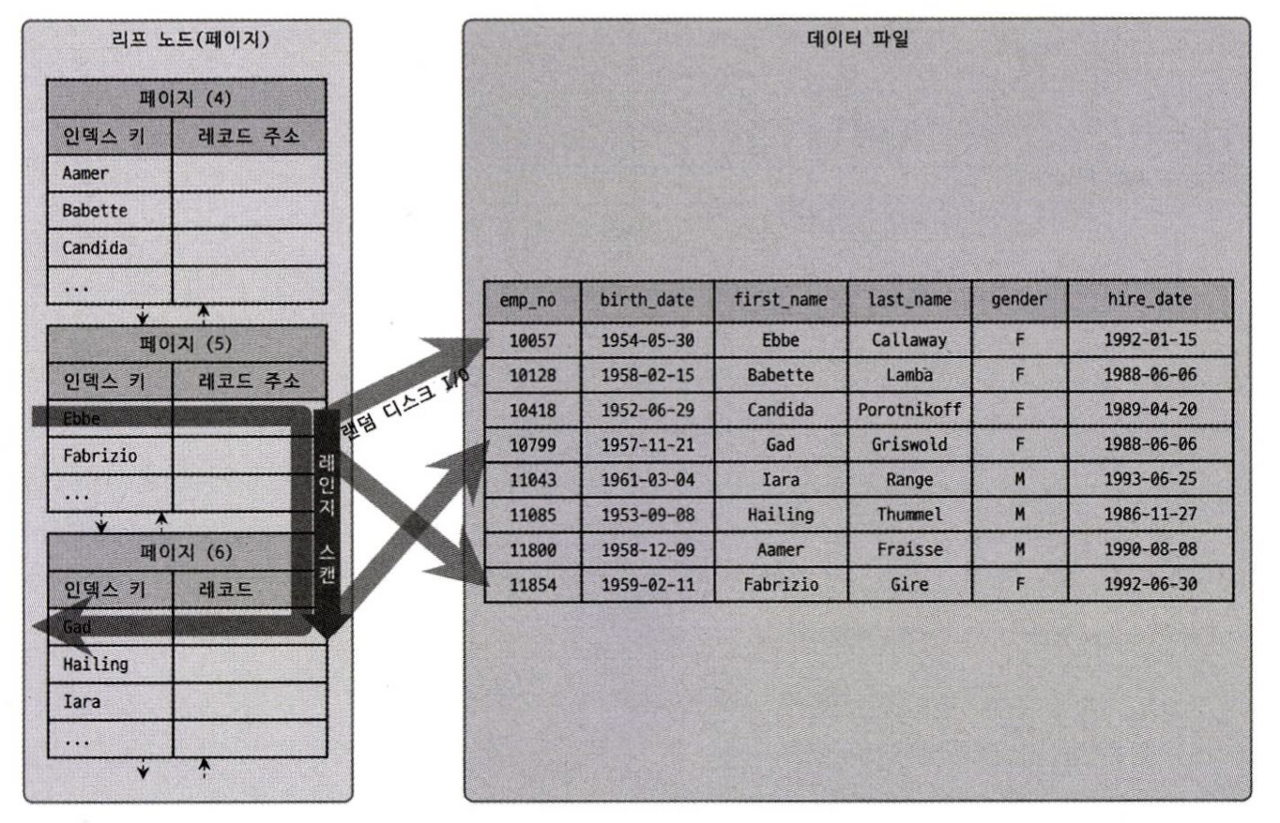
리프노드의 인덱스에는 인덱스 키(age)와 레코드 주소(프라이머리 키 = id) 정보 밖에 없다. 쿼리에서 * 을 이용해 모든 정보를 가져오라 했으니 name등 의 컬럼을 가져오기 위해 레코드 한줄당 한 건 한 건 디스크로 랜덤 I/O를 보낸다. 위의 예시에서는 19841건의 랜덤 I/O 가 나갔을 것이다.
SELECT * FROM USER WHERE age < 10
-- without index
SELECT * FROM USER WHERE age < 10;
-- 44916 rows in set (0.15 sec)
mysql> EXPLAIN ANALYZE SELECT * FROM USER WHERE age < 10;
-- +-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | EXPLAIN |
-- +-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | -> Filter: (`USER`.age < 10) (cost=50276 rows=166315) (actual time=0.25..136 rows=44916 loops=1)
-- -> Table scan on USER (cost=50276 rows=498996) (actual time=0.196..118 rows=500000 loops=1)
-- |
-- +-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- with index (age)
SELECT * FROM USER WHERE age < 10;
-- 44916 rows in set (0.11 sec)
mysql> EXPLAIN ANALYZE SELECT * FROM USER WHERE age < 10;
-- +-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | EXPLAIN |
-- +-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | -> Index range scan on USER using idx_age over (NULL < age < 10), with index condition: (`USER`.age < 10) (cost=39712 rows=88248) (actual time=0.0662..88.9 rows=44916 loops=1)
-- |
-- +-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+WHERE age < 10 쿼리는 WHERE age < 5 쿼리 보다 결과가 2배로 늘었다. 인덱스가 없는 경우 이번 역시 풀 테이블 스캔을 했다. 따라서 쿼리의 실행 시간이 비슷하다.
age에 인덱스를 걸은 경우 수행 시간이 0.11 초로 늘어났다. 이는 앞에서 설명한 랜덤 I/O가 더 많이 발생했기 때문에 수행시간이 늘어났다고 유추할 수 있다.
SELECT * FROM USER WHERE age < 15
-- without index
SELECT * FROM USER WHERE age < 15;
-- 70261 rows in set (0.15 sec)
mysql> EXPLAIN ANALYZE SELECT * FROM USER WHERE age < 15;
-- +------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | EXPLAIN |
-- +------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | -> Filter: (`USER`.age < 15) (cost=50276 rows=166315) (actual time=0.209..155 rows=70261 loops=1)
-- -> Table scan on USER (cost=50276 rows=498996) (actual time=0.198..134 rows=500000 loops=1)
-- |
-- +------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- with index (age)
SELECT * FROM USER WHERE age < 15;
-- 70261 rows in set (0.14 sec)
mysql> EXPLAIN ANALYZE SELECT * FROM USER WHERE age < 15;
-- +------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | EXPLAIN |
-- +------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | -> Filter: (`USER`.age < 15) (cost=50276 rows=146630) (actual time=0.175..154 rows=70261 loops=1)
-- -> Table scan on USER (cost=50276 rows=498996) (actual time=0.164..133 rows=500000 loops=1)
-- |
-- +------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+WHERE age < 15 인 쿼리를 살펴보자. 인덱스가 없는 경우 이전 경우와 비슷한 0.15 초가 걸렸다.
주목 할만한 점은 인덱스가 있었음에도 인덱스를 이용하지 않고 풀 테이블 스캔이 일어났다는 것이다. 이는 조회 할 결과의 갯수가 늘어나 랜덤 I/O의 발생 횟수가 늘어날 것이기 때문에 옵티마이져가 인덱스를 통해 랜덤 I/O를 많이 발생시키는 것 보다 순차 I/O를 사용하는 풀 테이블 스캔을 하는것이 이득이라 판단한 것이다.
인덱스를 통해 데이터를 읽는 작업은 비용이 많이 드는 작업으로 분류된다.
인덱스를 통해 읽어야 할 데이터 레코드가 20~25%를 넘으면 인덱스를 통한 읽기보다 테이블의 데이터를 직접 읽는 것이 더 효율적인 처리 방식이 된다.
-Real Mysql
따라서 같은 구조의 테이블에 같은 쿼리를 날려도 인덱스를 통해 읽어야 할 데이터 레코드 수에 따라서 인덱스를 이용할지, 이용하지 않을지 옵티마이져의 전략이 달라질 수 있다는 것이다.
Covering index
Covering index는 Index Range Scan과 같은 선상에서 비교되는 방법이라기 보다는 인덱스를 효율적으로 이용하는 방식이다. Index Range Scan과 동시에 사용될 수 있다. 또한 뒤에 나오는 다른 방법과도 동시에 사용될 수 있다.
커버링 인덱스는 쿼리를 충족하는데 필요한 모든 데이터를 갖는 인덱스를 의미한다.
SELECT id, name FROM USER WHERE name BETWEEN 'Person95000' AND 'Person99999'
-- with index (name)
CREATE INDEX idx_name ON USER (name);
SELECT id, name FROM USER WHERE name BETWEEN 'Person95000' AND 'Person99999';
-- ...
-- ...
-- | 279511 | Person99997 |
-- | 340325 | Person99997 |
-- | 348346 | Person99997 |
-- | 357918 | Person99997 |
-- | 443735 | Person99997 |
-- | 169485 | Person99998 |
-- | 79333 | Person99999 |
-- | 103951 | Person99999 |
-- | 137287 | Person99999 |
-- | 161900 | Person99999 |
-- | 165194 | Person99999 |
-- +--------+-------------+
-- 27600 rows in set (0.03 sec)
mysql> EXPLAIN ANALYZE SELECT id, name FROM USER WHERE name BETWEEN 'Person95000' AND 'Person99999';
-- +-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | -> Filter: (`USER`.`name` between 'Person95000' and 'Person99999') (cost=12133 rows=53922) (actual time=0.0623..26.8 rows=27600 loops=1)
-- -> Covering index range scan on USER using idx_name over ('Person95000' <= name <= 'Person99999') (cost=12133 rows=53922) (actual time=0.0524..15.2 rows=27600 loops=1)
-- |
-- +-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+EXPLAIN ANALYZE에 Covering index range scan on USER 이라는 내용이 있다. Index Range Scan를 이용하는데 Covering Index를 이용했다는 것이다. 앞선 쿼리들 처럼 * 을 통해 모든 컬럼을 조회하는게 아니라 id, name만 조회하고 있다. 이 경우 인덱스에서 필요한 모든 정보가 들어있기 때문에 원본 테이블로 랜덤 I/O를 보낼 필요가 없다. 따라서 매우 빠르게 쿼리를 처리할 수 있다.
또 하나 주목할 만한 점은 프라이머리 키인 id를 기준으로 정렬되지 않고 인덱스 키인 name를 기준으로 정렬되어 있다는 점이다. 인덱스를 통해 가져온 쿼리의 결과들은 모두 인덱스 키에 대해 정렬되어 있다. 인덱스가 인덱스 키에 대해서 정렬되어 있기 때문에 너무나 당연하게 인덱스를 통해 읽은 결과는 별다른 처리 없이 인덱스 키에 대해 정렬된 순서로 나온다.
Index Full Scan
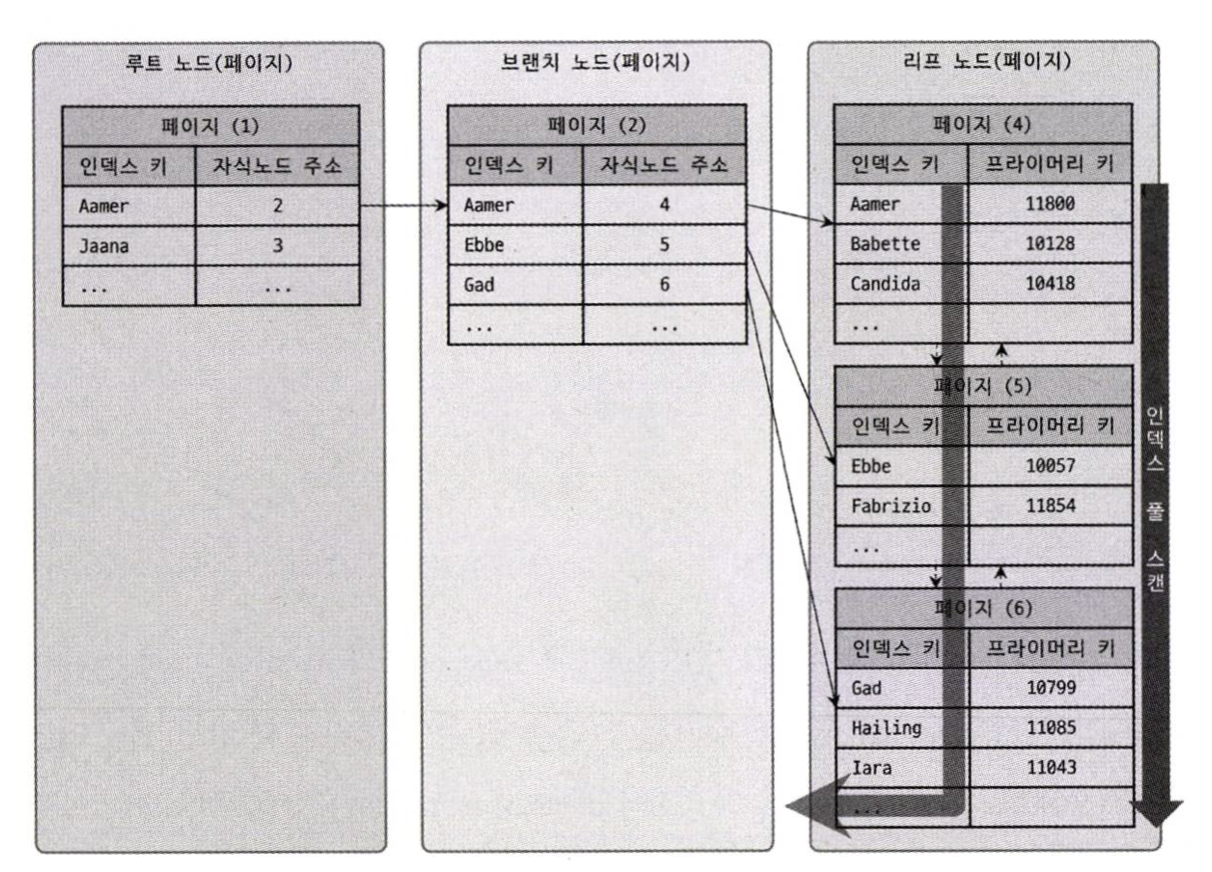
Index Full Scan은 인덱스 전체를 읽는 방식이다. Full 이라는 단어 때문에 풀 테이블 스캔과 혼동할 수 있다. 풀 테이블 스캔은 디스크에 순차 I/O를 통해 테이블 전체를 읽어오는 방식이고 Index Full Scan은 인덱스만 읽어오는 방식이다.
인덱스 리프 노드의 제일 앞 또는 제일 뒤로 이동한 뒤 해당 위치에서 리프 노드를 연결하는 링크드 리스트를 따라 처음부터 끝까지 스캔한다.
일반적으로 인덱스의 크기는 테이블의 크기보다 작기 때문에 직접 테이블을 처음부터 끝까지 읽는것 보다는 인덱스만 읽는것이 효율적이다. 쿼리가 인덱스에 명시된 정보만으로 처리될 수 있을 경우 이 방법이 사용된다. 그러나 인덱스 외에 원본 데이터 레코드에 있는 정보까지 필요하다면 이 방법이 절대 사용되지 않는다. 테이블 전체 레코드에 대해서 랜덤 I/O를 보내야 하기 때문이다. 따라서 Index Full Scan은 항상 Covering Index를 사용할 수 있는 상황에만 나타난다고 생각하면 된다.
SELECT id, name FROM USER
-- with index (name)
SELECT id, name FROM USER;
-- ...
-- ...
-- | 340325 | Person99997 |
-- | 348346 | Person99997 |
-- | 357918 | Person99997 |
-- | 443735 | Person99997 |
-- | 169485 | Person99998 |
-- | 79333 | Person99999 |
-- | 103951 | Person99999 |
-- | 137287 | Person99999 |
-- | 161900 | Person99999 |
-- | 165194 | Person99999 |
-- +--------+--------------+
-- 500000 rows in set (0.13 sec)
mysql> EXPLAIN ANALIZE SELECT id, name FROM USER;
-- mysql> EXPLAIN ANALYZE SELECT id, name FROM USER;
-- +------------------------------------------------------------------------------------------------------------------------+
-- | EXPLAIN |
-- +------------------------------------------------------------------------------------------------------------------------+
-- | -> Covering index scan on USER using idx_name (cost=50276 rows=498996) (actual time=0.103..87.1 rows=500000 loops=1)
-- |
-- +------------------------------------------------------------------------------------------------------------------------+Index Full Scan과 Covering index가 동시에 일어난 것을 확인할 수 있다.
Loose Index Scan
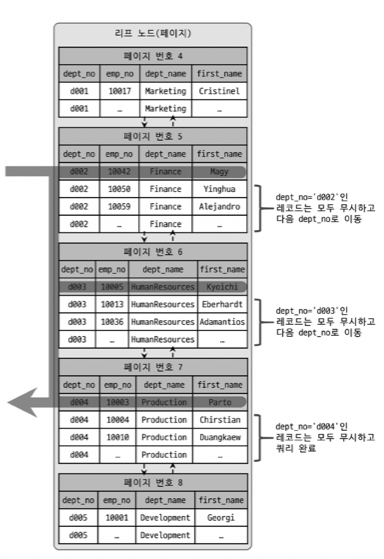
Loose Index Scan은 듬성듬성하게 인덱스를 읽는다는 뜻이다. Range Index Scan과 비슷하게 동작하지만 중간에 필요하지 않은 인덱스 키 값은 무시하고 다음으로 넘어간다.
SELECT age, MIN(name) FROM USER GROUP BY age
age를 기준으로 그룹을 나눈뒤 각 age별 사전순으로 가장 빠른 이름을 찾는 쿼리다.
-- without index
SELECT age, MIN(name) FROM USER GROUP BY age;
-- ...
-- ...
-- | 49 | Person1002 |
-- | 72 | Person10000 |
-- | 17 | Person10008 |
-- | 93 | Person10001 |
-- | 52 | Person1 |
-- | 41 | Person10009 |
-- | 57 | Person1003 |
-- +------+--------------+
-- 100 rows in set (0.18 sec)
mysql> EXPLAIN SELECT age, MIN(name) FROM USER GROUP BY age;
-- +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-----------------+
-- | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
-- +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-----------------+
-- | 1 | SIMPLE | USER | NULL | ALL | NULL | NULL | NULL | NULL | 498996 | 100.00 | Using temporary |
-- +----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-----------------+
mysql> EXPLAIN ANALYZE SELECT age, MIN(name) FROM USER GROUP BY age;
-- +---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | EXPLAIN |
-- +---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | -> Table scan on <temporary> (actual time=203..203 rows=100 loops=1)
-- -> Aggregate using temporary table (actual time=203..203 rows=100 loops=1)
-- -> Table scan on USER (cost=50276 rows=498996) (actual time=0.0991..90.2 rows=500000 loops=1)
-- |
-- +---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+인덱스 없이 쿼리가 실행되었을때를 살펴보자. EXPLAIN ANALYZE에 Aggregate using temporary table은 임시 테이블이 생성되었다는 내용이다. 이것을 Group By를 처리하기 위한 것이다. 시간은 0.18 초 정도가 걸렸다.
이제 age에 인덱스를 걸어보자.
-- with index (age)
CREATE INDEX idx_age ON USER (age);
SELECT age, MIN(name) FROM USER GROUP BY age;
-- ...
-- ...
-- | 95 | Person10050 |
-- | 96 | Person100 |
-- | 97 | Person10013 |
-- | 98 | Person10028 |
-- | 99 | Person10 |
-- | 100 | Person10022 |
-- +------+--------------+
-- 100 rows in set (0.34 sec)
mysql> EXPLAIN SELECT age, MIN(name) FROM USER GROUP BY age;
-- +----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-------+
-- | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
-- +----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-------+
-- | 1 | SIMPLE | USER | NULL | index | idx_age | idx_age | 5 | NULL | 498996 | 100.00 | NULL |
-- +----+-------------+-------+------------+-------+---------------+---------+---------+------+--------+----------+-------+
mysql> EXPLAIN ANALYZE SELECT age, MIN(name) FROM USER GROUP BY age;
-- +-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | EXPLAIN |
-- +-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | -> Group aggregate: min(`USER`.`name`) (cost=100176 rows=101) (actual time=24.4..378 rows=100 loops=1)
-- -> Index scan on USER using idx_age (cost=50276 rows=498996) (actual time=0.545..338 rows=500000 loops=1)
-- |
-- +-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+age에 인덱스를 걸어 같은 쿼리를 날렸을때 우선 가장 놀랐던 것은 시간이 0.34초로 인덱스를 이용하지 않았을 때보다 느리게 처리되었다는 점이다.
아직 정확히 이 쿼리가 실행되는 방식은 잘 모르겠지만 EXPLAIN ANALYZE에 Aggregate using temporary table 이라는 말이 보이지 않는다는 점에서 임시 테이블을 생성하지 않았고 인덱스를 이용한것 같다.
이 내용에 대해서는 다음에 따로 정리해보겠다. 우선 인덱스를 적절하게 걸지 못했을때 오히려 쿼리가 느리게 처리되었다는 점이 신기했다.
-- with index (age, name)
-- loose index scan
CREATE INDEX idx_age_name ON USER (age, name);
SELECT age, MIN(name) FROM USER GROUP BY age;
-- ...
-- ...
-- | 95 | Person10050 |
-- | 96 | Person100 |
-- | 97 | Person10013 |
-- | 98 | Person10028 |
-- | 99 | Person10 |
-- | 100 | Person10022 |
-- +------+--------------+
-- 100 rows in set (0.00 sec)
mysql> EXPLAIN SELECT age, MIN(name) FROM USER GROUP BY age;
-- +----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
-- | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
-- +----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
-- | 1 | SIMPLE | USER | NULL | range | idx_age_name | idx_age_name | 208 | NULL | 96 | 100.00 | Using index for group-by |
-- +----+-------------+-------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
mysql> EXPLAIN ANALYZE SELECT age, MIN(name) FROM USER GROUP BY age;
-- +---------------------------------------------------------------------------------------------------------------------------------------+
-- | EXPLAIN |
-- +---------------------------------------------------------------------------------------------------------------------------------------+
-- | -> Covering index skip scan for grouping on USER using idx_age_name (cost=134 rows=96) (actual time=0.0824..0.882 rows=100 loops=1)
-- |
-- +---------------------------------------------------------------------------------------------------------------------------------------+(age, name) 복합 인덱스를 걸어주었다. 이렇게 되면 인덱스는 우선 age에 대해 정렬된 다음 같은 age에 대해서 name 순으로 정렬될 것이다. 따라서 각 age의 가장 처음 name만 읽고 나머지 인덱스 키들은 무시하고 넘어가는 Loose Index Scan을 이용한다.
시간은 0.00 초 가 기록되었다. 매우 효율적으로 인덱스가 이용된것이다.
루스 인덱스 스캔이 일어나면 EXPLAIN에 Using index for group-by 라는 말이 있다. EXPLAIN ANALYZE에도 Covering index skip scan이라는 말로 시작해 뒤에서 나올 Index Skip Scan과 혼동할 수 있지만 뒤에 for grouping 이라는 말을 추가로 확인하면 된다.
Loose Index Scan이 일어나기 위해서는 여러 조건이 필요하다. 주로 group by 후 MIN(), MAX()를 찾는 경우 사용된다.
https://dev.mysql.com/doc/refman/5.7/en/group-by-optimization.html#loose-index-scan
Index Skip Scan
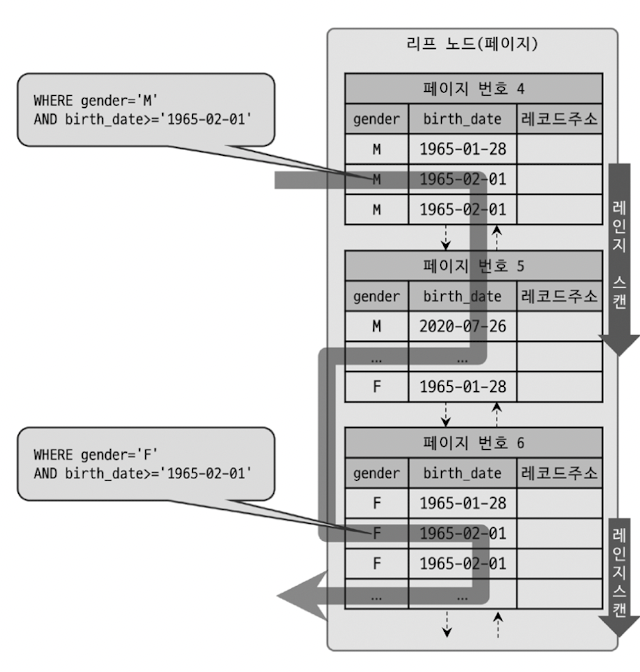
Index Skip Scan은 MySQL 8.0 버전에 추가된 최적화 기능으로 조건절에 첫 번째 인덱스가 없어도 두 번째 인덱스만으로 인덱스를 검색할 수 있게 해주는 기능이다.
이전 버전에서는 (gender, birth_date) 라는 인덱스가 있을때 WHERE gender = 'M' AND birth_date >= '1965-02-01' 같은 쿼리는 인덱스를 잘 사용하지만 WHERE birth_date >= '1965-02-01' 같이 인덱스의 앞 조건 없이 뒷 조건으로만 검색하면 인덱스를 이용하지 못했다.
Index Skip Scan이 일어나게 되면 WHERE birth_date >= '1965-02-01' 쿼리가 다음 두 쿼리를 수행하는 것 처럼 작동한다
SELECT * FROM USER WHERE gender = 'M' AND birth_date >= '1965-02-01'
SELECT * FROM USER WHERE gender = 'F' AND birth_date >= '1965-02-01'gender 컬럼 추가
ALTER TABLE USER ADD COLUMN gender CHAR(1);
UPDATE USER SET gender = CASE WHEN FLOOR(RAND() * 2) = 1 THEN 'M' ELSE 'F' END;
CREATE INDEX idx_gender_age ON USER (gender, age);실습을 위해 gender 컬럼을 추가하자. 그 후 (gender, age)에 인덱스를 걸었다.
SELECT * FROM USER WHERE age < 10
SET optimizer_switch='skip_scan=OFF' 을 이용해 index skip scan이 일어나지 않게 할 수 있다. index skip scan이 일어나지 않게 설정 후 쿼리를 날려보자
-- without index skip scan
SET optimizer_switch='skip_scan=OFF';
SELECT * FROM USER WHERE age < 10;
-- ...
-- ...
-- | 499911 | F | 1 |
-- | 499920 | F | 3 |
-- | 499925 | F | 7 |
-- | 499955 | M | 3 |
-- | 499969 | F | 6 |
-- | 499982 | M | 9 |
-- | 499987 | F | 6 |
-- +--------+--------+------+
-- 44916 rows in set (0.12 sec)
mysql> EXPLAIN SELECT id, gender, age FROM USER WHERE age < 10;
-- +----+-------------+-------+------------+-------+---------------+----------------+---------+------+--------+----------+--------------------------+
-- | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
-- +----+-------------+-------+------------+-------+---------------+----------------+---------+------+--------+----------+--------------------------+
-- | 1 | SIMPLE | USER | NULL | index | NULL | idx_gender_age | 10 | NULL | 498996 | 33.33 | Using where; Using index |
-- +----+-------------+-------+------------+-------+---------------+----------------+---------+------+--------+----------+--------------------------+
mysql> EXPLAIN ANALYZE SELECT id, gender, age FROM USER WHERE age < 10;
-- +------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | EXPLAIN |
-- +------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | -> Filter: (`USER`.age < 10) (cost=50276 rows=166315) (actual time=0.135..123 rows=44916 loops=1)
-- -> Covering index scan on USER using idx_gender_age (cost=50276 rows=498996) (actual time=0.131..100 rows=500000 loops=1)
-- |
-- +------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
index skip scan이 일어나지 않았다. 이 경우 index full scan이 일어난것으로 보인다. 그 후 인덱스 필터 조건을 이용해 결과를 보여준다.
이제 SET optimizer_switch='skip_scan=ON'을 이용해 index skip scan이 일어나도록 해보자.
-- with index skip scan
SET optimizer_switch='skip_scan=ON';
SELECT * FROM USER WHERE age < 10;
-- ...
-- ...
-- | 498712 | M | 9 |
-- | 498765 | M | 9 |
-- | 498954 | M | 9 |
-- | 499567 | M | 9 |
-- | 499789 | M | 9 |
-- | 499982 | M | 9 |
-- +--------+--------+------+
-- 44916 rows in set (0.03 sec)
mysql> EXPLAIN SELECT id, gender, age FROM USER WHERE age < 10;
-- +----+-------------+-------+------------+-------+----------------+----------------+---------+------+--------+----------+----------------------------------------+
-- | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
-- +----+-------------+-------+------------+-------+----------------+----------------+---------+------+--------+----------+----------------------------------------+
-- | 1 | SIMPLE | USER | NULL | range | idx_gender_age | idx_gender_age | 10 | NULL | 166315 | 100.00 | Using where; Using index for skip scan |
-- +----+-------------+-------+------------+-------+----------------+----------------+---------+------+--------+----------+----------------------------------------+
mysql> EXPLAIN ANALYZE SELECT id, gender, age FROM USER WHERE age < 10;
-- +-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | EXPLAIN |
-- +-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
-- | -> Filter: (`USER`.age < 10) (cost=0.252..41867 rows=166315) (actual time=0.0896..27 rows=44916 loops=1)
-- -> Covering index skip scan on USER using idx_gender_age over NULL < age < 10 (cost=0.252..41867 rows=166315) (actual time=0.0862..22.1 rows=44916 loops=1)
-- |
-- +-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+Covering index skip scan 이라는 말에서 알 수 있듯 index skip scan이 사용되었다. index full scan이 일어났을 때보다 훨신 빠른 0.03 초 안에 쿼리를 처리했다.
마무리
쿼리를 작성할 때 인덱스가 얼마나 중요한지 알게 되었다. 책에서 본 내용을 직접 데이터를 만들어서 눈으로 확인하는것도 좋은 경험이었다.
