Google Vertex AI 간단한 소개
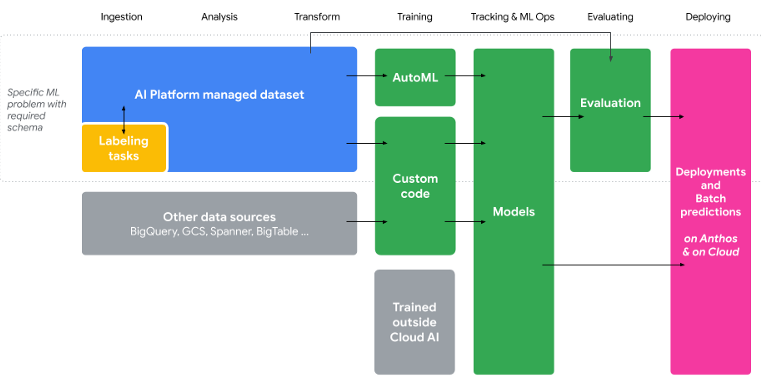
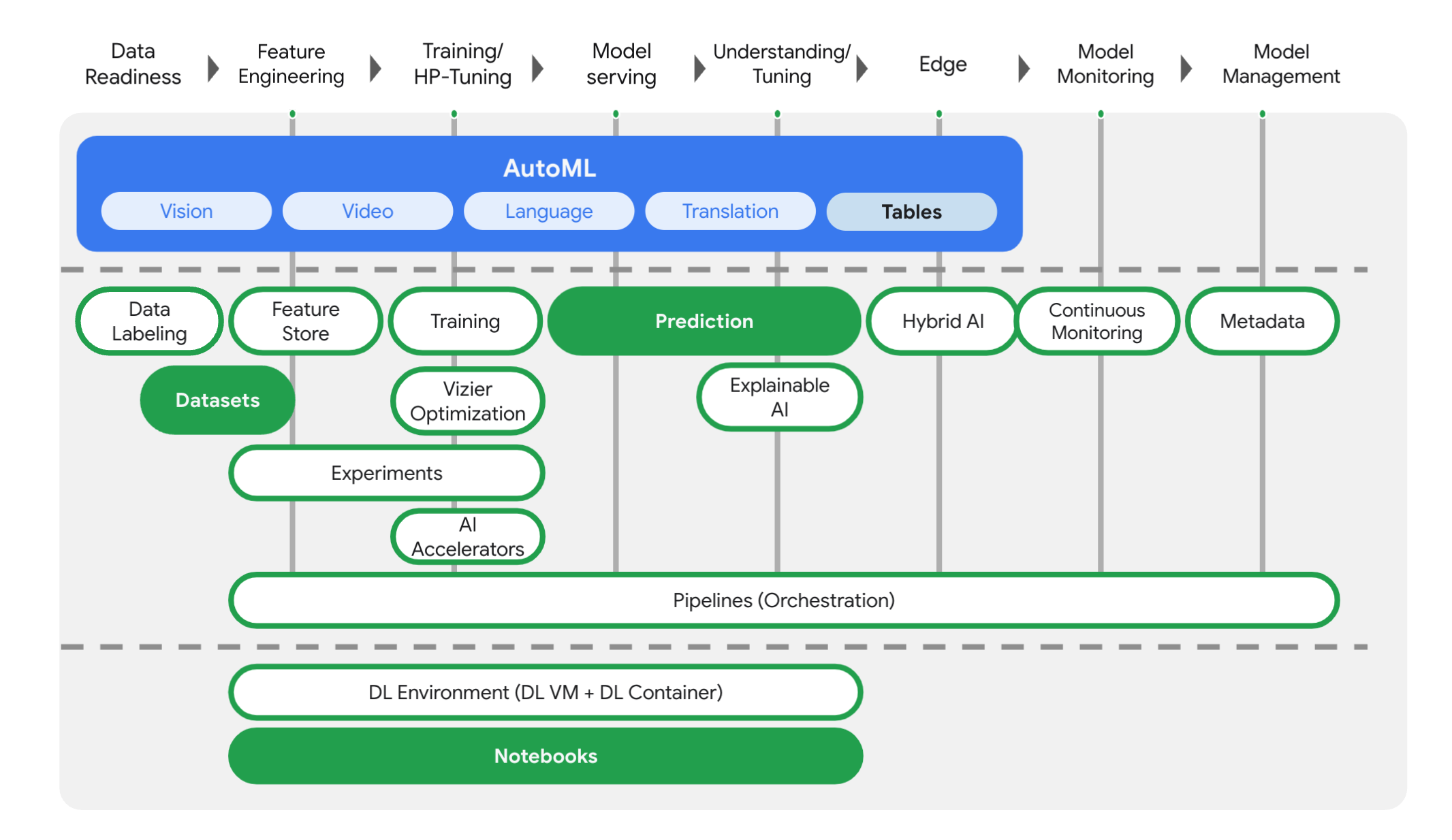
Google Cloud의 AI Platform, AutoML 등 다양한 머신러닝 서비스를 하나의 인터페이스(UI / API)에서 사용할 수 있도록 구성된 종합선물 과자세트 같은 서비스입니다.
데이터셋 구성부터 모델 생성, 학습, 테스트, 검증하고 애플리케이션에서 Endpoint로 사용할 수 있도록 배포까지 하나의 파이프라인으로 구성 가능합니다.
API를 이용하여 Jupyter Notebook에서 구성할 수도 있고, 클라우드 엔지니어가 직접 UI에서 AutoML을 이용하여 개발할 수도 있습니다.

Preface
Vertex AI를 사용하여 Tabular 데이터로 모델 훈련을 해봅시다.
- Vertex AI에 데이터셋 업로드
- AutoML 모델 학습
- 학습된 AutoML 모델을 엔드포인트에 배포 후, 엔드포인트 사용 예측
Pre Hands-On Requirements
- Google Cloud Platform 계정 (Google 계정으로 무료 크레딧을 받아봅시다!)
아주 약간의 머신러닝 지식- Imbalanced Data (불균형 데이터)
- Supervised Learning / Unsupervised Learning (지도학습/비지도학습)
- Classification (분류)
- Label
아주 약간의 컴퓨터 사이언스 지식아주 약간의 클라우드 컴퓨팅 지식
Hands-On
1. GCP Console 접속
Google Cloud Platform에 로그인하여 Vertex AI를 사용할 프로젝트를 선택합니다.
본 예시는 oreobox 프로젝트를 사용합니다.
2. Vertex AI 섹션으로 이동
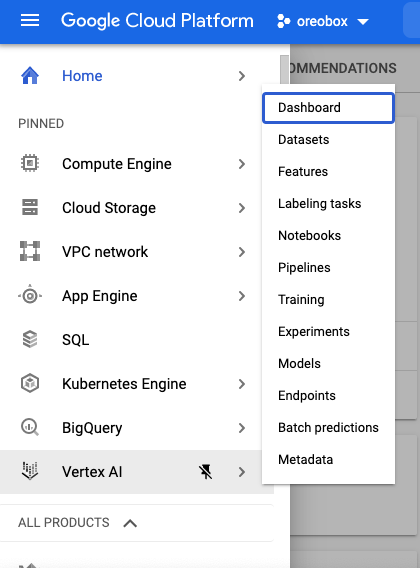
좌측 상단에 햄버거 메뉴를 선택하여 Vertex AI를 클릭합니다.
3. Notebooks 생성
Vertex AI 섹션에서 Notebooks를 클릭합니다.
처음 만든다면 아무것도 없을 거에요.
상단에 New Instance를 클릭하여 노트북을 만들어 봅시다.
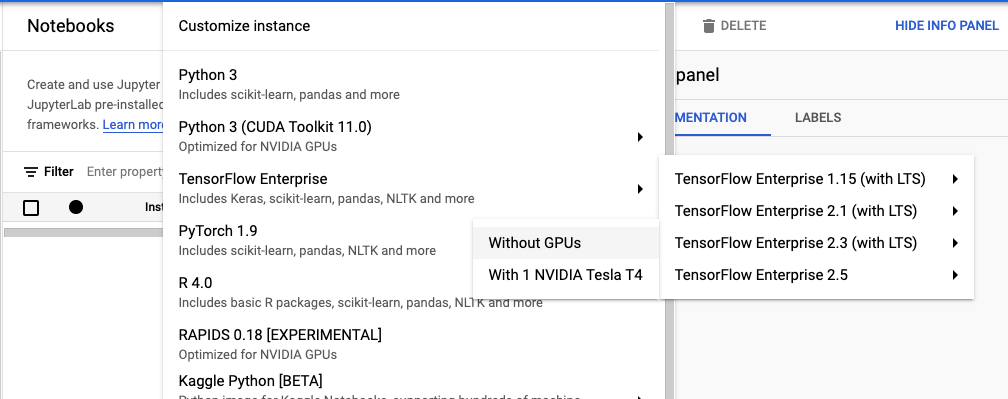
아래에 순서대로 들어가서 생성할 노트북 인스턴스를 클릭합니다.
TensorFlow Enterprise > TensorFlow Enterprise 2.3 (with LTS) > Without GPUs
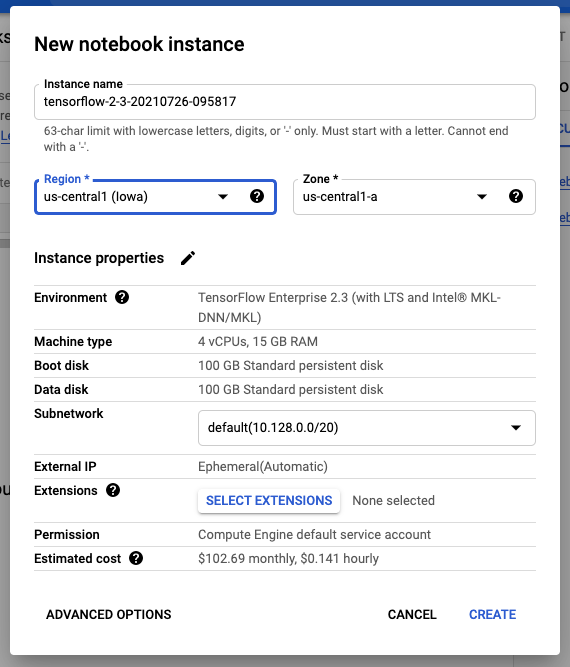
Instance name은 귀찮아서 그대로 두겠습니다. (변경하고 싶으시면 변경하세요!)
테스트이기 때문에 가장 저렴한 리전인 Iowa(us-central1)을 선택하도록 하겠습니다.
사족이지만 Seoul은 제법 비쌉니다. (크으 국뽕에 취한다)
Subnet은 default를 사용하고 CREATE 클릭.
4. 데이터셋 생성
모델 훈련에 사용할 데이터는 Kaggle의 신용카드 사기 탐지 데이터셋(Credit Card Fraud Detection)을 사용하겠습니다. 하지만 바로 가져와서 사용하지 않고 BigQuery에서 Public Dataset으로 제공되는 버전으로 사용하겠습니다.
많은 사기 탐지 및 이상 탐지 문제에서 일반적으로 데이터세트가 불균형(Imbalaced Dataset)합니다. 다행히(?) 우리가 사는 곳은 고담 시티가 아니기 때문에 정상적인 거래가 비정상적인 거래보다 훨씬 많기 때문입니다. 본 실습에서는 불균형 데이터 세트를 처리하기 위한 몇 가지 팁을 제공합니다.
Vertex AI 섹션에서 Datasets을 클릭합니다.
상단에 CREATE를 클릭합니다.

데이터셋 이름은 fraud_detection으로 입력하겠습니다.
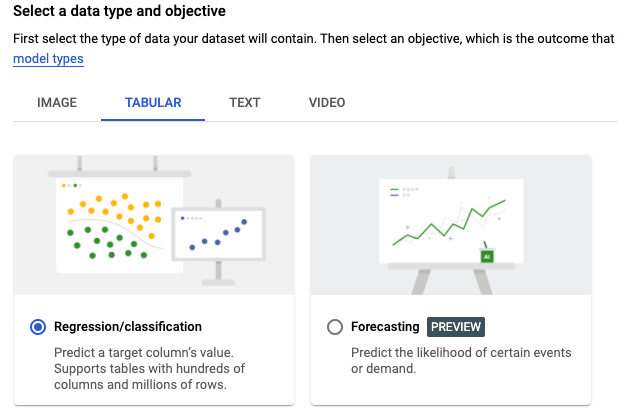
Tabular로 변경한 후에 Regression/Classification을 선택 후 생성합니다.
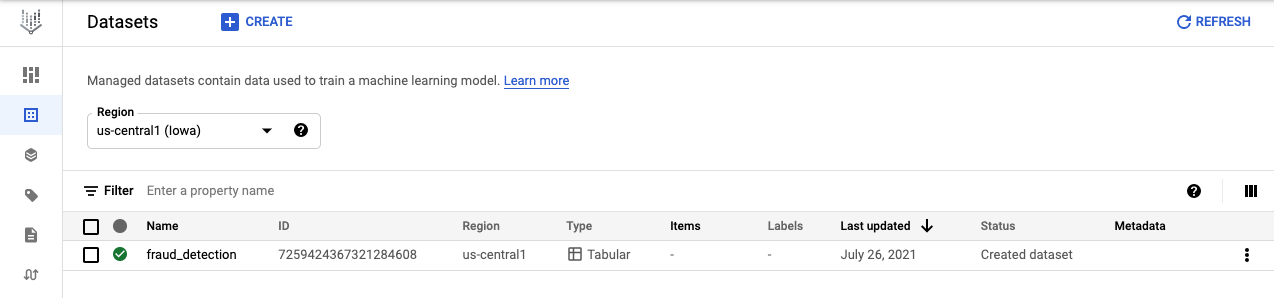
방금 만든 fraud_detection 데이터셋이 생성되었습니다.
빈 깡통이니까 데이터를 채워줍시다.
fraud_detection을 클릭합니다.
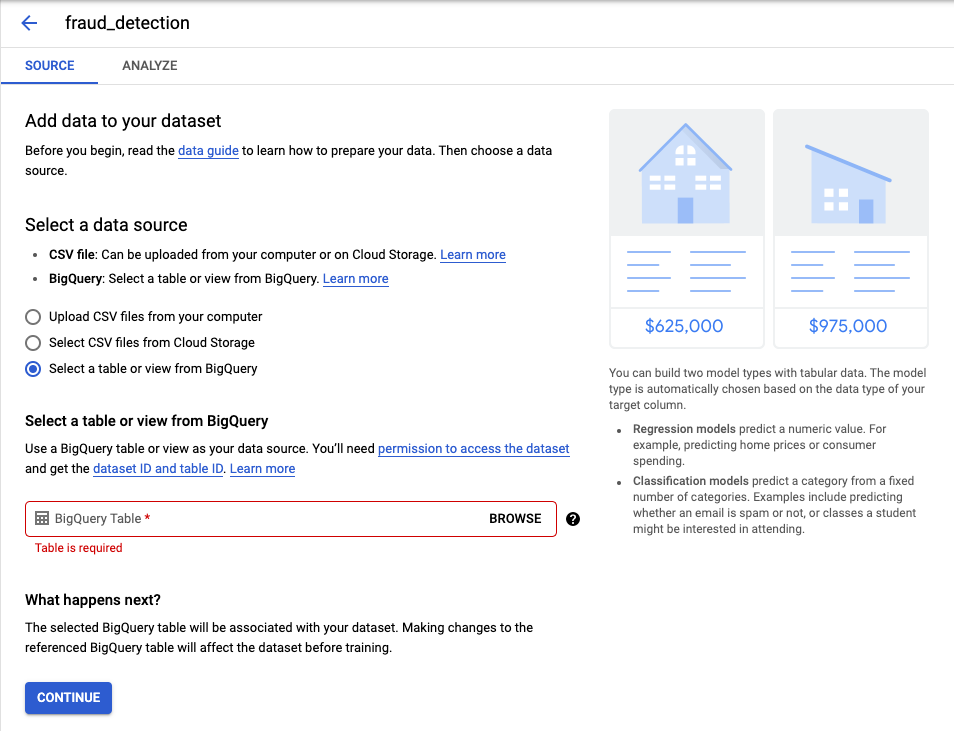
BigQuery에서 데이터셋을 가져오기로 했으니까 data source 옵션을 변경합니다.
- Select a table or view from BigQuery

그 다음 가져올 BigQuery Table을 아래 내용을 복사하여 붙여넣습니다.
bigquery-public-data.ml_datasets.ulb_fraud_detection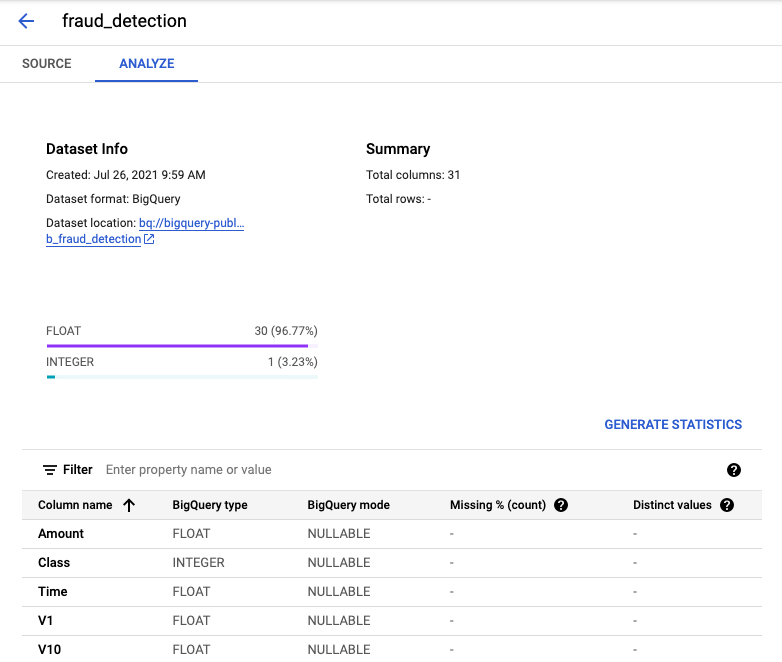
정상적으로 데이터셋을 가져왔다면 위와 같이 같이 표시되어야 합니다.
데이터셋은 실제 신용카드 거래 정보이기 때문에 피쳐 명칭은 V1, V2 등으로 불명확한 정보로 마스킹되어 있습니다.
5. 모델 생성하기
데이터셋이 준비되었으니 훈련을 시작해보겠습니다.
특정 거래가 사기인지 아닌지 예측하기 위해 Classification 훈련을 해보도록 하겠습니다. 모델 옵션은 두 가지를 제공합니다.
- AutoML : 코드 작성 없이 Vertex AI가 제시하는 Best Model을 사용하는 방법
- Custom Training : 내가 작성한 모델을 사용하는 방법
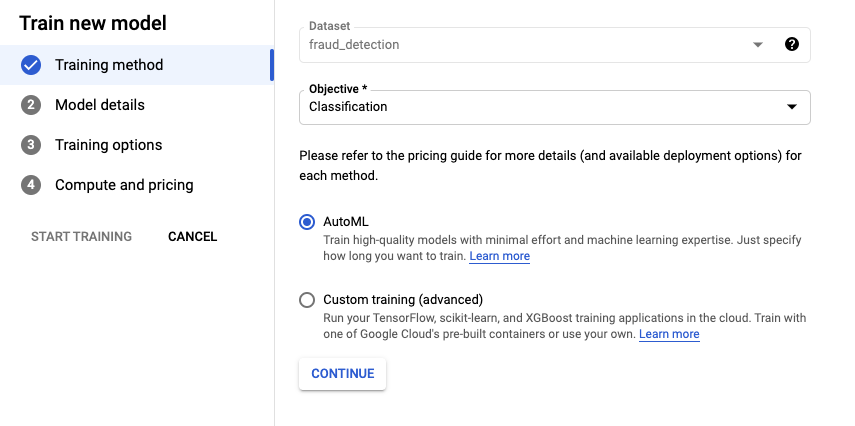
Train new model을 클릭하여 모델 생성을 해봅시다.
아쉽게도 인프라쟁이가 만든 머신러닝 모델이 Google AutoML보다 뛰어날 거라 기대가 되지 않습니다….😭
AutoML을 클릭하여 최소한의 노력으로 모델을 생성해보겠습니다ㅋㅋ
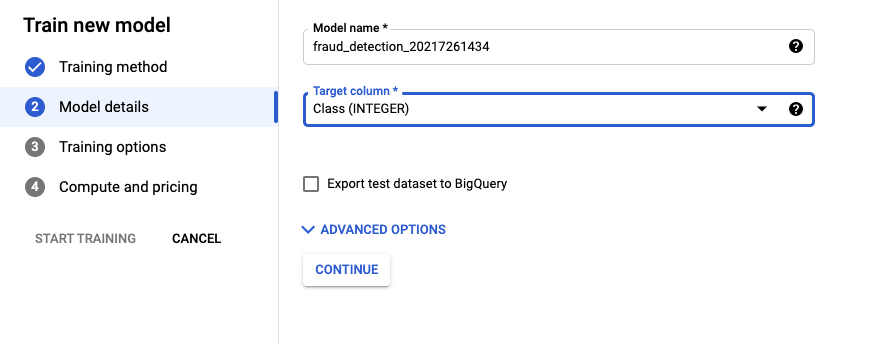
분류할 대상을 입력합니다.
- Class (INTEGER)
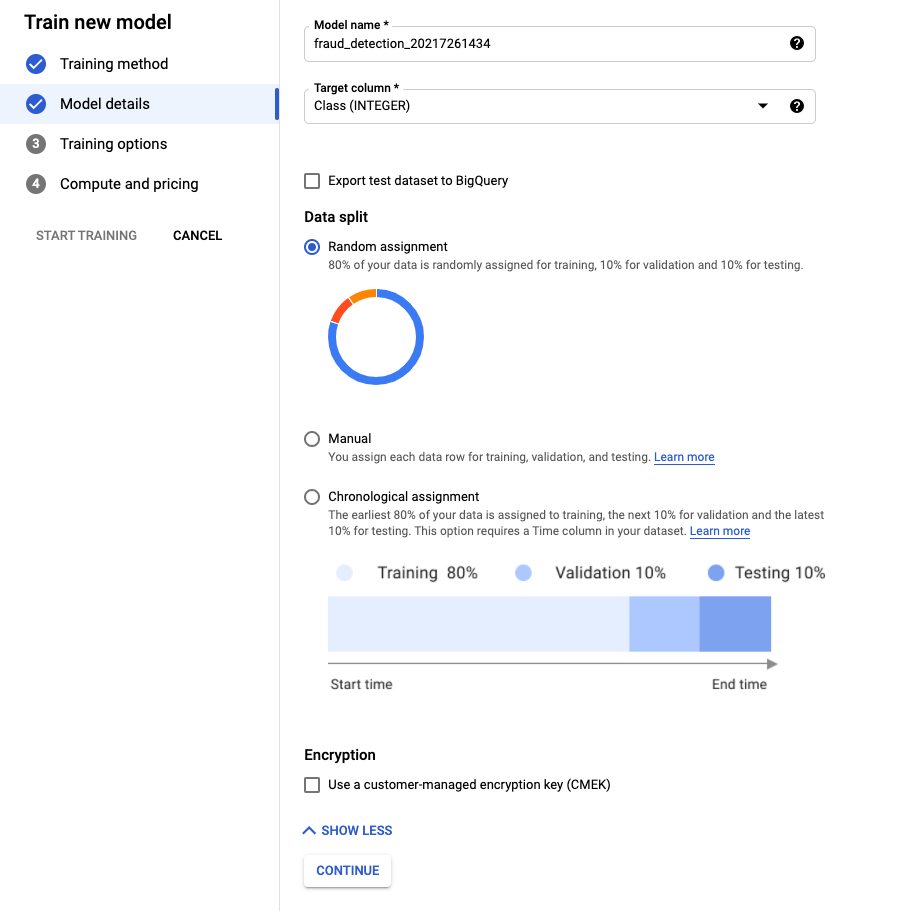
ADVANCED OPTIONS를 눌러보면 Data Split 옵션이 있습니다.
그냥 내비둡시다!
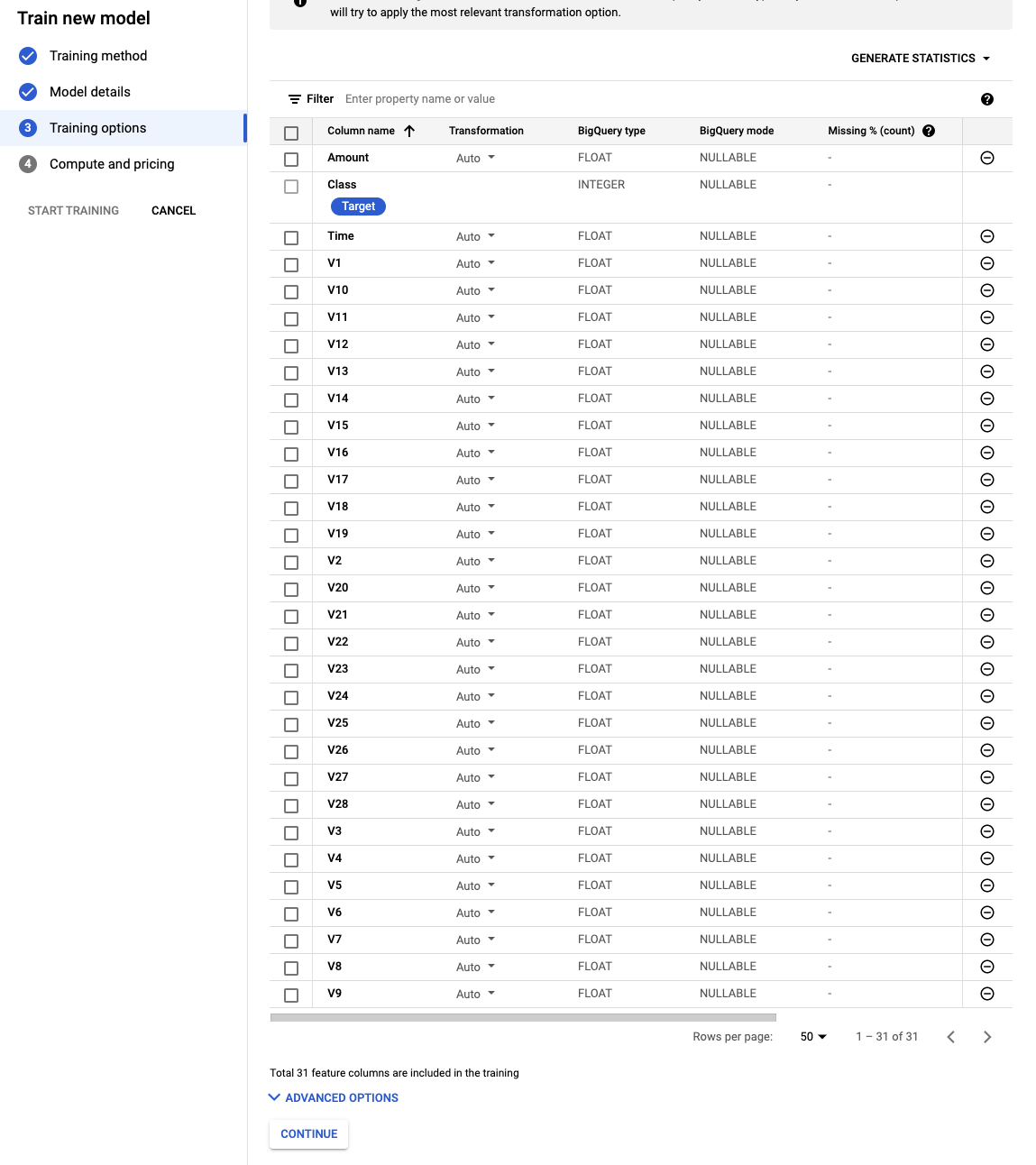
데이터셋의 모든 피쳐가 주르륵 출력이 됩니다.
뭐가 이리 많아!! 놀라지 마시고 아래 ADVANCED OPTIONS를 눌러줍니다.
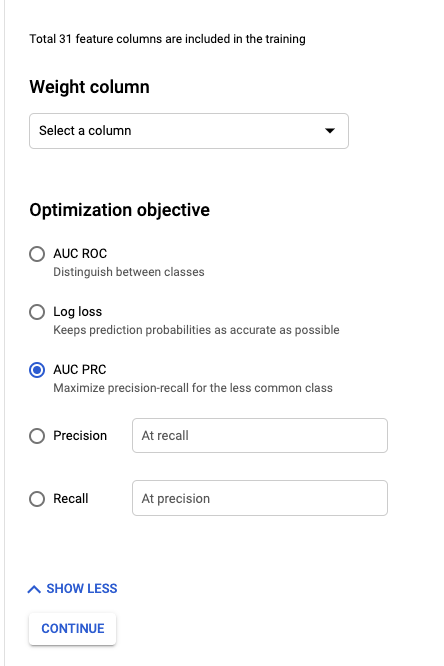
최적화 목표(Optimization objective)를 변경하겠습니다.
불균형 데이터셋이므로 이때 기가 막힌 검증 방법인 AUC PRC를 선택합니다.
불균형 데이터에 AUC-PR(Precision-Recall)을 이용할 때 더 좋은 결과를 얻었다는 논문들이 찾아보니 꽤 있습니다.
참고논문: Helen R. Sofaer, Jennifer A. Hoeting, Catherine S. Jarnevich, (17 December 2018). The area under the precision-recall curve as a performance metric for rare binary events
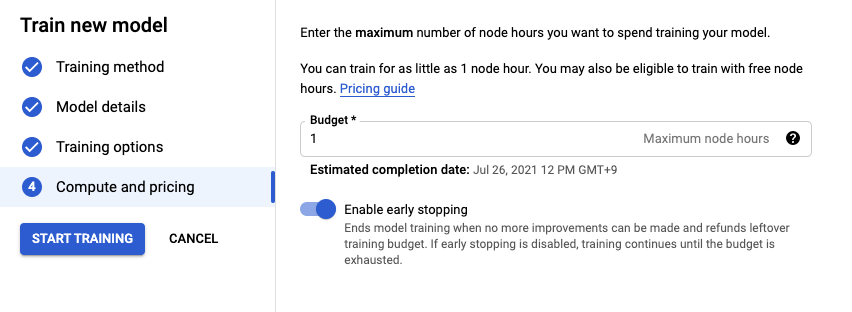
노드 시간 수는 1로 입력합니다.
AutoML 모델을 컴퓨팅 1시간 동안 학습시키는 것을 의미합니다.
저는 무료 크레딧으로 이 포스팅을 하고 있는 소시민이므로 크레딧을 아낍시다!
Budget은 최소값인 1로 입력합니다🙌
1시간 동안 기다려봅시다.
다음 내용은 2편에서…!
참고문서

안녕하세요 좋은 게시글 감사합니다!